Samouczek: tworzenie rekomendatora filmu przy użyciu factoryzacji macierzy z ML.NET
W tym samouczku pokazano, jak utworzyć program polecający film za pomocą ML.NET w aplikacji konsolowej platformy .NET Core. Kroki są wykonywane przy użyciu języka C# i programu Visual Studio 2019.
Ten samouczek zawiera informacje na temat wykonywania następujących czynności:
- Wybieranie algorytmu uczenia maszynowego
- Przygotowywanie i ładowanie danych
- Kompilowanie i trenowanie modelu
- Ocena modelu
- Wdrażanie i używanie modelu
Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
Przepływ pracy uczenia maszynowego
Wykonaj następujące kroki, aby wykonać zadanie, a także inne ML.NET zadania:
Wymagania wstępne
Wybieranie odpowiedniego zadania uczenia maszynowego
Istnieje kilka sposobów podejścia do problemów z rekomendacjami, takich jak zalecanie listy filmów lub rekomendowanie listy powiązanych produktów, ale w tym przypadku można przewidzieć, jaka ocena (1–5) użytkownik da określony film i zaleci ten film, jeśli jest wyższy niż zdefiniowany próg (im wyższa ocena, tym większe prawdopodobieństwo, że użytkownik lubi określony film).
Tworzenie aplikacji konsolowej
Tworzenie projektu
Utwórz aplikację konsolową języka C# o nazwie "MovieRecommender". Kliknij przycisk Dalej.
Wybierz platformę .NET 6 jako platformę do użycia. Kliknij przycisk Utwórz.
Utwórz katalog o nazwie Dane w projekcie, aby przechowywać zestaw danych:
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Dodaj>nowy folder. Wpisz "Dane" i naciśnij klawisz Enter.
Zainstaluj pakiety NuGet Microsoft.ML i Microsoft.ML.Recommender :
Uwaga
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt i wybierz polecenie Zarządzaj pakietami NuGet. Wybierz pozycję "nuget.org" jako źródło pakietu, wybierz kartę Przeglądaj , wyszukaj Microsoft.ML, wybierz pakiet z listy i wybierz przycisk Zainstaluj . Wybierz przycisk OK w oknie dialogowym Podgląd zmian , a następnie wybierz przycisk Akceptuję w oknie dialogowym Akceptacja licencji , jeśli zgadzasz się z postanowieniami licencyjnymi dla wymienionych pakietów. Powtórz te kroki dla programu Microsoft.ML.Recommender.
Dodaj następujące
usinginstrukcje w górnej części pliku Program.cs :using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Pobierz swoje dane
Pobierz dwa zestawy danych i zapisz je w utworzonym wcześniej folderze Data :
Kliknij prawym przyciskiem myszy recommendation-ratings-train.csv i wybierz pozycję "Zapisz link (lub element docelowy) jako..."
Kliknij prawym przyciskiem myszy recommendation-ratings-test.csv i wybierz pozycję "Zapisz link (lub element docelowy) jako..."
Upewnij się, że zapiszesz pliki *.csv w folderze Dane lub po zapisaniu go w innym miejscu przenieś pliki *.csv do folderu Dane .
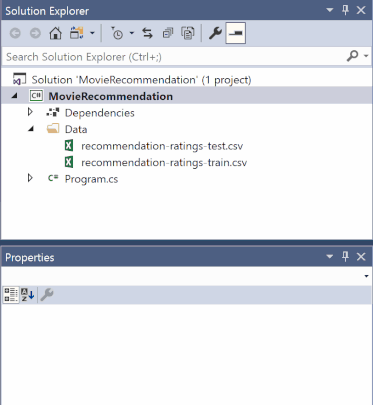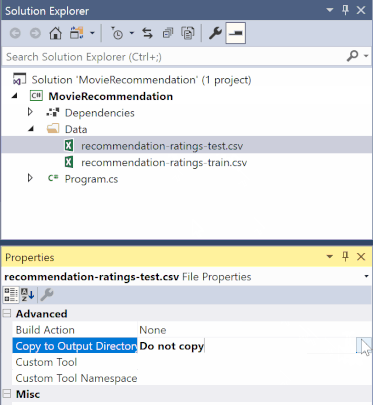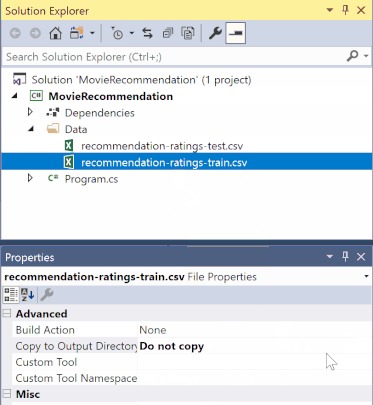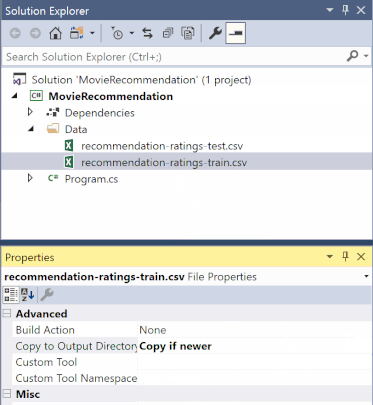
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy każdą z plików *.csv i wybierz polecenie Właściwości. W obszarze Zaawansowane zmień wartość opcji Kopiuj do katalogu wyjściowego , aby skopiować, jeśli jest nowsza.
Ładowanie danych
Pierwszym krokiem procesu ML.NET jest przygotowanie i załadowanie danych trenowania i testowania modelu.
Dane klasyfikacji rekomendacji są podzielone na Train zestawy danych i Test . Dane Train są używane do dopasowania modelu. Dane Test służą do prognozowania za pomocą wytrenowanego modelu i oceniania wydajności modelu. Często występuje podział 80/20 na Train dane i Test .
Poniżej przedstawiono podgląd danych z plików *.csv:
W plikach *.csv znajdują się cztery kolumny:
userIdmovieIdratingtimestamp
W uczeniu maszynowym kolumny używane do przewidywania są nazywane funkcjami, a kolumna z zwróconym przewidywaniem jest nazywana etykietą.
Chcesz przewidzieć oceny filmów, więc kolumna Labelklasyfikacji to . Pozostałe trzy kolumny, userId, movieIdi timestamp są Features używane do przewidywania wartości Label.
| Funkcje | Etykieta |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Do Ciebie należy zdecydować, które Features są używane do przewidywania .Label Możesz również użyć metod, takich jak znaczenie funkcji permutacji , aby pomóc w wybraniu najlepszego Featureselementu .
W takim przypadku należy wyeliminować kolumnę timestamp jako element Feature , ponieważ sygnatura czasowa nie ma wpływu na sposób, w jaki użytkownik ocenia dany film, a tym samym nie przyczyni się do dokładniejszego przewidywania:
| Funkcje | Etykieta |
|---|---|
userId |
rating |
movieId |
Następnie musisz zdefiniować strukturę danych dla klasy wejściowej.
Dodaj nową klasę do projektu:
W Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt, a następnie wybierz polecenie Dodaj > nowy element.
W oknie dialogowym Dodawanie nowego elementu wybierz pozycję Klasa i zmień pole Nazwa na MovieRatingData.cs. Następnie wybierz przycisk Dodaj .
Plik MovieRatingData.cs zostanie otwarty w edytorze kodu. Dodaj następującą using instrukcję na początku pliku MovieRatingData.cs:
using Microsoft.ML.Data;
Utwórz klasę o nazwie MovieRating , usuwając istniejącą definicję klasy i dodając następujący kod w pliku MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating określa klasę danych wejściowych. Atrybut LoadColumn określa, które kolumny (według indeksu kolumn) w zestawie danych powinny zostać załadowane. Kolumny userId i to Twoje Features (dane wejściowe, które dadzą modelowi do przewidywania Labelwartości ), a kolumna klasyfikacji jest Label przewidywana (movieIddane wyjściowe modelu).
Utwórz inną klasę , aby reprezentować przewidywane wyniki, MovieRatingPredictiondodając następujący kod po MovieRating klasie MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
W pliku Program.cs zastąp element Console.WriteLine("Hello World!") następującym kodem:
MLContext mlContext = new MLContext();
Klasa MLContext jest punktem wyjścia dla wszystkich operacji ML.NET, a inicjowanie mlContext tworzy nowe środowisko ML.NET, które można udostępnić w obiektach przepływu pracy tworzenia modelu. Jest ona podobna, koncepcyjnie, do DBContext w programie Entity Framework.
W dolnej części pliku utwórz metodę o nazwie LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Uwaga
Ta metoda spowoduje wyświetlenie błędu do momentu dodania instrukcji return w poniższych krokach.
Zainicjuj zmienne ścieżki danych, załaduj dane z plików *.csv i zwróć TrainTest dane jako IDataView obiekty, dodając następujący wiersz kodu w LoadData()pliku :
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Dane w ML.NET są reprezentowane jako interfejs IDataView.
IDataView jest elastycznym, wydajnym sposobem opisywania danych tabelarycznych (liczbowych i tekstowych). Dane można załadować z pliku tekstowego lub w czasie rzeczywistym (na przykład bazy danych SQL lub plików dziennika) do IDataView obiektu.
Element LoadFromTextFile() definiuje schemat danych i odczytuje go w pliku. Pobiera ona zmienne ścieżki danych i zwraca wartość IDataView. W takim przypadku należy podać ścieżkę dla plików Test i Train i wskazać zarówno nagłówek pliku tekstowego (aby mógł prawidłowo używać nazw kolumn) oraz separator danych znaków przecinka (separator domyślny jest kartą).
Dodaj następujący kod, aby wywołać LoadData() metodę i zwrócić Train dane i Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Kompilowanie i trenowanie modelu
Utwórz metodę BuildAndTrainModel() tuż po metodzie LoadData() , używając następującego kodu:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Uwaga
Ta metoda spowoduje wyświetlenie błędu do momentu dodania instrukcji return w poniższych krokach.
Zdefiniuj przekształcenia danych, dodając następujący kod do BuildAndTrainModel()elementu :
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Ponieważ userId i reprezentują użytkowników i movieId tytuły filmów, a nie rzeczywiste wartości, należy użyć metody MapValueToKey(), aby przekształcić każdy userId z nich movieId w kolumnę typu Feature klucza liczbowego (format akceptowany przez algorytmy rekomendacji) i dodać je jako nowe kolumny zestawu danych:
| userId | movieId | Etykieta | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Wybierz algorytm uczenia maszynowego i dołącz go do definicji przekształcania danych, dodając następujący wiersz kodu w BuildAndTrainModel()pliku :
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer to algorytm trenowania rekomendacji. Factoryzacja macierzy jest typowym podejściem do rekomendacji, gdy masz dane dotyczące sposobu oceniania produktów przez użytkowników w przeszłości, co jest w przypadku zestawów danych w tym samouczku. Istnieją inne algorytmy rekomendacji, jeśli masz dostępne różne dane (zobacz sekcję Inne algorytmy rekomendacji poniżej, aby dowiedzieć się więcej).
W tym przypadku Matrix Factorization algorytm używa metody o nazwie "filtrowanie zespołowe", która zakłada, że jeśli użytkownik 1 ma taką samą opinię jak użytkownik 2 w przypadku określonego problemu, wówczas użytkownik 1 jest bardziej skłonny do tego samego, co użytkownik 2 w przypadku innego problemu.
Jeśli na przykład użytkownicy 1 i Użytkownik 2 oceniają filmy w podobny sposób, użytkownik 2 jest bardziej skłonny do korzystania z filmu, który użytkownik 1 oglądał i oceniał wysoko:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Użytkownik 1 | Oglądany i lubiany film | Oglądany i lubiany film | Oglądany i lubiany film |
| Użytkownik 2 | Oglądany i lubiany film | Oglądany i lubiany film | Nie obejrzał - POLECAJ film |
Trener Matrix Factorization ma kilka opcji, o których można dowiedzieć się więcej w sekcji Hiperparametry algorytmu poniżej.
Dopasuj model do Train danych i zwróć wytrenowany model, dodając następujący wiersz kodu w metodzie BuildAndTrainModel() :
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Metoda Fit() trenuje model przy użyciu dostarczonego zestawu danych treningowych. Technicznie wykonuje Estimator definicje, przekształcając dane i stosując trenowanie, a następnie zwraca z powrotem wytrenowany model, czyli Transformer.
Aby uzyskać więcej informacji na temat przepływu pracy trenowania modelu w ML.NET, zobacz Co to jest ML.NET i jak działa?.
Dodaj następujący kod jako następny wiersz kodu poniżej wywołania LoadData() metody w celu wywołania BuildAndTrainModel() metody i zwrócenia wytrenowanego modelu:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Ocenianie modelu
Po wytrenowanym modelu użyj danych testowych, aby ocenić, jak działa model.
Utwórz metodę EvaluateModel() tuż po metodzie BuildAndTrainModel() przy użyciu następującego kodu:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Przekształć dane, Test dodając następujący kod do EvaluateModel()elementu :
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Metoda Transform() tworzy przewidywania dla wielu dostarczonych wierszy wejściowych zestawu danych testowych.
Oceń model, dodając następujący wiersz kodu w metodzie EvaluateModel() :
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Po utworzeniu zestawu przewidywania metoda Evaluate() ocenia model, który porównuje przewidywane wartości z wartościami rzeczywistymi Labels w zestawie danych testowych i zwraca metryki dotyczące sposobu działania modelu.
Wydrukuj metryki oceny w konsoli, dodając następujący wiersz kodu w metodzie EvaluateModel() :
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Dodaj następujący kod jako następny wiersz kodu poniżej wywołania BuildAndTrainModel() metody w celu wywołania EvaluateModel() metody :
EvaluateModel(mlContext, testDataView, model);
Dane wyjściowe do tej pory powinny wyglądać podobnie do następującego tekstu:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
W tych danych wyjściowych istnieje 20 iteracji. W każdej iteracji miara błędu zmniejsza się i zbliża się do 0.
( root of mean squared error RMS lub RMSE) służy do mierzenia różnic między wartościami przewidywanymi modelu a obserwowanymi wartościami zestawu danych testowych. Technicznie jest to pierwiastek kwadratowy średniej kwadratów błędów. Im niższa jest, tym lepiej jest model.
R Squared wskazuje, jak dobrze dane pasują do modelu. Zakresy od 0 do 1. Wartość 0 oznacza, że dane są losowe lub w przeciwnym razie nie można dopasować ich do modelu. Wartość 1 oznacza, że model dokładnie odpowiada danym. Chcesz, aby wynik R Squared był jak najbardziej zbliżony do 1.
Tworzenie udanych modeli jest procesem iteracyjnym. Ten model ma początkową niższą jakość, ponieważ w samouczku używane są małe zestawy danych w celu zapewnienia szybkiego trenowania modelu. Jeśli nie jesteś zadowolony z jakości modelu, możesz spróbować go ulepszyć, udostępniając większe zestawy danych szkoleniowych lub wybierając różne algorytmy trenowania z różnymi hiperparatami dla każdego algorytmu. Aby uzyskać więcej informacji, zapoznaj się z sekcją Ulepszanie modelu poniżej.
Korzystanie z modelu
Teraz możesz użyć wytrenowanego modelu, aby przewidywać nowe dane.
Utwórz metodę UseModelForSinglePrediction() tuż po metodzie EvaluateModel() przy użyciu następującego kodu:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Użyj elementu , PredictionEngine aby przewidzieć ocenę, dodając następujący kod do UseModelForSinglePrediction()elementu :
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine to wygodny interfejs API, który umożliwia przewidywanie pojedynczego wystąpienia danych.
PredictionEngine nie jest bezpieczny wątkowo. Dopuszczalne jest użycie w środowiskach jednowątkowych lub prototypowych. Aby zwiększyć wydajność i bezpieczeństwo wątków w środowiskach produkcyjnych, użyj PredictionEnginePool usługi , która tworzy ObjectPoolPredictionEngine obiekty do użycia w całej aplikacji. Zapoznaj się z tym przewodnikiem dotyczącym sposobu używania PredictionEnginePool w internetowym interfejsie API ASP.NET Core.
Uwaga
PredictionEnginePool Rozszerzenie usługi jest obecnie dostępne w wersji zapoznawczej.
Utwórz wystąpienie MovieRating o nazwie testInput i przekaż je do aparatu przewidywania, dodając następujące wiersze kodu w metodzie UseModelForSinglePrediction() :
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Funkcja Predict() tworzy przewidywanie dla pojedynczej kolumny danych.
Następnie możesz użyć Scorewartości , lub przewidywanej oceny, aby określić, czy chcesz polecić film z identyfikatorem movieId 10 do użytkownika 6. Im wyższa Scorewartość , tym większe prawdopodobieństwo, że użytkownik lubi określony film. W tym przypadku załóżmy, że zalecamy filmy z przewidywaną oceną > 3,5.
Aby wydrukować wyniki, dodaj następujące wiersze kodu w metodzie UseModelForSinglePrediction() :
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Dodaj następujący kod jako następny wiersz kodu po wywołaniu EvaluateModel() metody w celu wywołania UseModelForSinglePrediction() metody :
UseModelForSinglePrediction(mlContext, model);
Dane wyjściowe tej metody powinny wyglądać podobnie do następującego tekstu:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Zapisywanie modelu
Aby używać modelu do przewidywania w aplikacjach użytkowników końcowych, musisz najpierw zapisać model.
Utwórz metodę SaveModel() tuż po metodzie UseModelForSinglePrediction() przy użyciu następującego kodu:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Zapisz wytrenowany model, dodając następujący kod w metodzie SaveModel() :
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Ta metoda zapisuje wytrenowany model w pliku .zip (w folderze "Dane"), który może być następnie używany w innych aplikacjach platformy .NET do przewidywania.
Dodaj następujący kod jako następny wiersz kodu po wywołaniu UseModelForSinglePrediction() metody w celu wywołania SaveModel() metody :
SaveModel(mlContext, trainingDataView.Schema, model);
Korzystanie z zapisanego modelu
Po zapisaniu wytrenowanego modelu możesz korzystać z modelu w różnych środowiskach. Zobacz Zapisywanie i ładowanie wytrenowanych modeli , aby dowiedzieć się, jak operacjonalizować wytrenowany model uczenia maszynowego w aplikacjach.
Wyniki
Po wykonaniu powyższych kroków uruchom aplikację konsolową (Ctrl + F5). Wyniki z powyższego pojedynczego przewidywania powinny być podobne do poniższych. Mogą pojawić się ostrzeżenia lub przetwarzanie komunikatów, ale te komunikaty zostały usunięte z poniższych wyników w celu zapewnienia przejrzystości.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Gratulacje! Udało Ci się utworzyć model uczenia maszynowego do rekomendowania filmów. Kod źródłowy tego samouczka można znaleźć w repozytorium dotnet/samples .
Ulepszanie modelu
Istnieje kilka sposobów poprawy wydajności modelu, dzięki czemu można uzyskać dokładniejsze przewidywania.
Dane
Dodanie większej liczby danych szkoleniowych, które mają wystarczającą liczbę próbek dla każdego użytkownika i identyfikatora filmu, może pomóc poprawić jakość modelu rekomendacji.
Krzyżowa walidacja to technika obliczania modeli, które losowo dzieli dane na podzestawy (zamiast wyodrębniania danych testowych z zestawu danych, tak jak w tym samouczku) i przyjmuje niektóre grupy jako dane treningowe i niektóre grupy jako dane testowe. Ta metoda przewyższa podział testów pociągu pod względem jakości modelu.
Funkcje
W tym samouczku używasz tylko trzech Features elementów (user id, movie id, i rating), które są udostępniane przez zestaw danych.
Chociaż jest to dobry początek, w rzeczywistości możesz dodać inne atrybuty lub Features (na przykład wiek, płeć, lokalizacja geograficzna itp.), jeśli są one uwzględnione w zestawie danych. Dodanie bardziej istotne Features może pomóc zwiększyć wydajność modelu rekomendacji.
Jeśli nie masz pewności, co Features może być najbardziej istotne dla zadania uczenia maszynowego, możesz również skorzystać z obliczeń udziału funkcji (FCC) i znaczenia funkcji permutacji, które ML.NET zapewnia, aby odkryć najbardziej wpływowe Features.
Hiperparametry algorytmu
Chociaż ML.NET zapewnia dobre domyślne algorytmy trenowania, można jeszcze bardziej dostosować wydajność, zmieniając hiperparametry algorytmu.
W przypadku Matrix Factorizationprogramu można eksperymentować z hiperparametrami, takimi jak NumberOfIterations i ApproximationRank , aby sprawdzić, czy daje to lepsze wyniki.
Na przykład w tym samouczku dostępne są następujące opcje algorytmu:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Inne algorytmy rekomendacji
Algorytm factoryzacji macierzy z filtrowaniem współpracy jest tylko jednym podejściem do wykonywania zaleceń dotyczących filmów. W wielu przypadkach dane klasyfikacji mogą nie być dostępne i mają dostępną tylko historię filmów od użytkowników. W innych przypadkach może istnieć więcej niż tylko dane oceny użytkownika.
| Algorytm | Scenariusz | Przykład |
|---|---|---|
| Factoryzacja jednej macierzy klas | Użyj tej opcji, gdy masz tylko identyfikator userId i movieId. Ten styl rekomendacji opiera się na scenariuszu wspólnej zakupu lub często kupowanych produktach, co oznacza, że zaleca klientom zestaw produktów na podstawie własnej historii zamówień zakupu. | >Czas to wypróbować |
| Maszyny factoryzacji z rozpoznawaniem pól | Użyj tego polecenia, aby wprowadzić zalecenia, gdy masz więcej funkcji poza identyfikatorem userId, identyfikatorem produktu i oceną (na przykład opis produktu lub cena produktu). Ta metoda używa również podejścia do wspólnego filtrowania. | >Czas to wypróbować |
Nowy scenariusz użytkownika
Jednym z typowych problemów związanych z filtrowaniem współpracy jest problem z zimnym startem, który polega na tym, że nowy użytkownik nie ma żadnych poprzednich danych do wnioskowania. Ten problem jest często rozwiązywany przez prośbę nowych użytkowników o utworzenie profilu, a na przykład oceń filmy, które widzieli w przeszłości. Chociaż ta metoda wywiera pewne obciążenie dla użytkownika, zapewnia pewne dane początkowe dla nowych użytkowników bez historii klasyfikacji.
Zasoby
Dane używane w tym samouczku pochodzą z zestawu danych MovieLens.
Następne kroki
W niniejszym samouczku zawarto informacje na temat wykonywania następujących czynności:
- Wybieranie algorytmu uczenia maszynowego
- Przygotowywanie i ładowanie danych
- Kompilowanie i trenowanie modelu
- Ocena modelu
- Wdrażanie i używanie modelu
Przejdź do następnego samouczka, aby dowiedzieć się więcej