Praca z danymi w aplikacjach ASP.NET Core
Napiwek
Ta zawartość jest fragmentem książki eBook, architekta nowoczesnych aplikacji internetowych z platformą ASP.NET Core i platformą Azure, dostępnym na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

"Dane są cenne i będą trwać dłużej niż same systemy".
Tim Berners-Lee
Dostęp do danych jest ważną częścią niemal każdej aplikacji programowej. ASP.NET Core obsługuje różne opcje dostępu do danych, w tym Entity Framework Core (i Entity Framework 6), a także mogą współpracować z dowolną strukturą dostępu do danych platformy .NET. Wybór platformy dostępu do danych do użycia zależy od potrzeb aplikacji. Abstrakcja tych opcji z projektów ApplicationCore i interfejsu użytkownika oraz hermetyzowanie szczegółów implementacji w infrastrukturze ułatwia tworzenie luźno powiązanego, testowalnego oprogramowania.
Entity Framework Core (dla relacyjnych baz danych)
Jeśli piszesz nową aplikację ASP.NET Core, która musi pracować z danymi relacyjnymi, zalecanym sposobem uzyskiwania dostępu do danych przez aplikację jest program Entity Framework Core (EF Core). EF Core to maper obiektowo-relacyjny (O/RM), który umożliwia deweloperom platformy .NET utrwalanie obiektów do i ze źródła danych. Eliminuje to konieczność pisania większości deweloperów kodu dostępu do danych. Podobnie jak ASP.NET Core, platforma EF Core została przepisana od podstaw, aby obsługiwać modułowe aplikacje międzyplatformowe. Należy dodać ją do aplikacji jako pakiet NuGet, skonfigurować go podczas uruchamiania aplikacji i zażądać jej za pomocą iniekcji zależności wszędzie tam, gdzie jest potrzebna.
Aby użyć programu EF Core z bazą danych programu SQL Server, uruchom następujące polecenie interfejsu wiersza polecenia dotnet:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Aby dodać obsługę źródła danych InMemory, na potrzeby testowania:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
The DbContext
Do pracy z programem EF Core potrzebna jest podklasa .DbContext Ta klasa zawiera właściwości reprezentujące kolekcje jednostek, z których aplikacja będzie pracować. Przykład eShopOnWeb zawiera CatalogContext kolekcje dla elementów, marek i typów:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
Element DbContext musi mieć konstruktor, który akceptuje DbContextOptions i przekazuje ten argument do konstruktora podstawowego DbContext . Jeśli w aplikacji masz tylko jedną wartość DbContext, możesz przekazać wystąpienie DbContextOptionsklasy , ale jeśli masz więcej niż jeden typ ogólny DbContextOptions<T> , przekaż typ DbContext jako parametr ogólny.
Konfigurowanie programu EF Core
W aplikacji ASP.NET Core zwykle skonfigurujesz program EF Core w Program.cs z innymi zależnościami aplikacji. Program EF Core używa klasy DbContextOptionsBuilder, która obsługuje kilka przydatnych metod rozszerzeń, aby usprawnić konfigurację. Aby skonfigurować metodę CatalogContext do używania bazy danych programu SQL Server z parametry połączenia zdefiniowanym w obszarze Konfiguracja, należy dodać następujący kod:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Aby użyć bazy danych w pamięci:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Po zainstalowaniu programu EF Core, utworzeniu typu podrzędnego DbContext i dodaniu typu do usług aplikacji możesz przystąpić do korzystania z programu EF Core. Możesz zażądać wystąpienia typu DbContext w dowolnej usłudze, która jej potrzebuje, i rozpocząć pracę z utrwalone jednostki przy użyciu LINQ, jakby były po prostu w kolekcji. Program EF Core wykonuje pracę nad tłumaczeniem wyrażeń LINQ na zapytania SQL w celu przechowywania i pobierania danych.
Zapytania są wykonywane przez program EF Core, konfigurując rejestrator i upewniając się, że jego poziom jest ustawiony na co najmniej informacje, jak pokazano na rysunku 8-1.
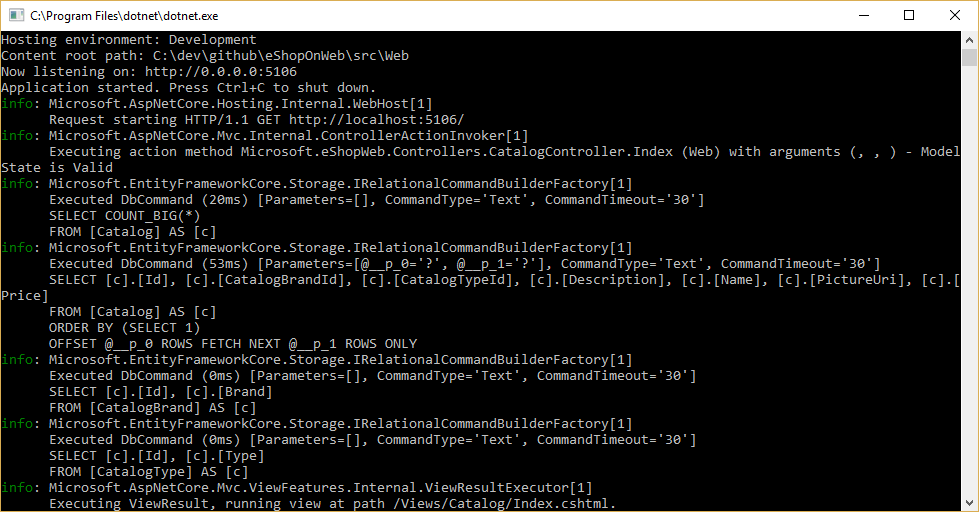
Rysunek 8–1. Rejestrowanie zapytań programu EF Core w konsoli
Pobieranie i przechowywanie danych
Aby pobrać dane z platformy EF Core, uzyskujesz dostęp do odpowiedniej właściwości i filtrujesz wynik przy użyciu linQ. Można również użyć LINQ do wykonywania projekcji, przekształcania wyniku z jednego typu na inny. Poniższy przykład pobiera katalog CatalogBrands uporządkowany według nazwy, filtrowany według właściwości Enabled i przewidywany na SelectListItem typ:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
W powyższym przykładzie ważne jest, aby dodać wywołanie metody ToListAsync w celu natychmiastowego wykonania zapytania. W przeciwnym razie instrukcja przypisze element IQueryable<SelectListItem> brandItems, który nie zostanie wykonany, dopóki nie zostanie wyliczony. Istnieją zalety i wady zwracania IQueryable wyników z metod. Umożliwia ona dalsze modyfikowanie konstrukcji zapytania EF Core, ale może również powodować błędy występujące tylko w czasie wykonywania, jeśli operacje są dodawane do zapytania, którego program EF Core nie może przetłumaczyć. Ogólnie bezpieczniej jest przekazać wszystkie filtry do metody wykonującej dostęp do danych i zwrócić kolekcję w pamięci (na przykład List<T>) w wyniku.
Program EF Core śledzi zmiany jednostek pobieranych od trwałości. Aby zapisać zmiany w śledzonej jednostce, wystarczy wywołać SaveChangesAsync metodę w obiekcie DbContext, upewniając się, że jest to to to samo wystąpienie DbContext, które zostało użyte do pobrania jednostki. Dodawanie i usuwanie jednostek odbywa się bezpośrednio we właściwej właściwości DbSet, ponownie za pomocą wywołania polecenia w celu SaveChangesAsync wykonania poleceń bazy danych. W poniższym przykładzie pokazano dodawanie, aktualizowanie i usuwanie jednostek z trwałości.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
Program EF Core obsługuje zarówno metody synchroniczne, jak i asynchroniczne na potrzeby pobierania i zapisywania. W aplikacjach internetowych zaleca się używanie wzorca asynchronicznego/await z metodami asynchronicznych, dzięki czemu wątki serwera internetowego nie są blokowane podczas oczekiwania na ukończenie operacji dostępu do danych.
Aby uzyskać więcej informacji, zobacz Buforowanie i przesyłanie strumieniowe.
Pobieranie powiązanych danych
Gdy program EF Core pobiera jednostki, wypełnia wszystkie właściwości przechowywane bezpośrednio z tej jednostki w bazie danych. Właściwości nawigacji, takie jak listy powiązanych jednostek, nie są wypełniane i mogą mieć ich wartość ustawioną na wartość null. Ten proces zapewnia, że program EF Core nie pobiera większej ilości danych niż jest potrzebny, co jest szczególnie ważne w przypadku aplikacji internetowych, które muszą szybko przetwarzać żądania i zwracać odpowiedzi w wydajny sposób. Aby uwzględnić relacje z jednostką korzystającą z ładowania chętnego, należy określić właściwość przy użyciu metody dołączania rozszerzenia w zapytaniu, jak pokazano poniżej:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Można uwzględnić wiele relacji, a także uwzględnić podrelacje za pomocą polecenia ThenInclude. Program EF Core wykona pojedyncze zapytanie w celu pobrania wynikowego zestawu jednostek. Alternatywnie możesz uwzględnić właściwości nawigacji właściwości nawigacji, przekazując element "". -oddzielony ciąg do .Include() metody rozszerzenia, w następujący sposób:
.Include("Items.Products")
Oprócz hermetyzacji logiki filtrowania specyfikacja może określać kształt zwracanych danych, w tym właściwości do wypełnienia. Przykład eShopOnWeb zawiera kilka specyfikacji, które pokazują hermetyzację informacji o chętnym ładowaniu w specyfikacji. Tutaj możesz zobaczyć, jak specyfikacja jest używana w ramach zapytania:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Inną opcją ładowania powiązanych danych jest użycie jawnego ładowania. Jawne ładowanie umożliwia załadowanie dodatkowych danych do jednostki, która została już pobrana. Ponieważ takie podejście obejmuje oddzielne żądanie do bazy danych, nie jest zalecane w przypadku aplikacji internetowych, co powinno zminimalizować liczbę rund bazy danych wykonanych na żądanie.
Ładowanie leniwe to funkcja, która automatycznie ładuje powiązane dane w miarę odwoływania się do niej przez aplikację. Program EF Core dodał obsługę leniwego ładowania w wersji 2.1. Ładowanie opóźnione nie jest domyślnie włączone i wymaga zainstalowania programu Microsoft.EntityFrameworkCore.Proxies. Podobnie jak w przypadku jawnego ładowania, ładowanie z opóźnieniem powinno być zwykle wyłączone dla aplikacji internetowych, ponieważ jego użycie spowoduje wykonywanie dodatkowych zapytań bazy danych w ramach każdego żądania internetowego. Niestety obciążenie związane z opóźnieniem ładowania często jest niezauważone w czasie programowania, gdy opóźnienie jest małe i często zestawy danych używane do testowania są małe. Jednak w środowisku produkcyjnym, z większą liczbą użytkowników, większą ilością danych i większym opóźnieniem, dodatkowe żądania bazy danych mogą często powodować niską wydajność aplikacji internetowych, które intensywnie korzystają z leniwego ładowania.
Unikaj ładowania jednostek z opóźnieniem w aplikacjach internetowych
Warto przetestować aplikację podczas badania rzeczywistych zapytań bazy danych, które wykonuje. W pewnych okolicznościach program EF Core może sprawić, że wiele zapytań lub zapytanie będzie droższe niż jest optymalne dla aplikacji. Jednym z takich problemów jest znany jako eksplozja kartezjańskiej. Zespół platformy EF Core udostępnia metodę AsSplitQuery jako jeden z kilku sposobów dostosowywania zachowania środowiska uruchomieniowego.
Hermetyzowanie danych
Program EF Core obsługuje kilka funkcji, które umożliwiają prawidłowe hermetyzowanie stanu modelu. Typowym problemem w modelach domeny jest to, że uwidaczniają właściwości nawigacji kolekcji jako publicznie dostępne typy list. Ten problem umożliwia każdemu współpracownikowi manipulowanie zawartością tych typów kolekcji, co może pomijać ważne reguły biznesowe związane z kolekcją, co może spowodować pozostawienie obiektu w nieprawidłowym stanie. Rozwiązaniem tego problemu jest uwidocznienie dostępu tylko do odczytu do powiązanych kolekcji i jawne udostępnienie metod definiujących sposoby manipulowania nimi przez klientów, jak w tym przykładzie:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Ten typ jednostki nie uwidacznia publicznego List lub ICollection właściwości, ale uwidacznia typ, który opakowuje IReadOnlyCollection bazowy typ listy. W przypadku korzystania z tego wzorca możesz wskazać program Entity Framework Core, aby użyć pola zapasowego w następujący sposób:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Innym sposobem, w jaki można ulepszyć model domeny, jest użycie obiektów wartości dla typów, które nie mają tożsamości i są rozróżniane tylko przez ich właściwości. Użycie takich typów, jak właściwości jednostek, może pomóc zachować logikę specyficzną dla obiektu wartości, do którego należy, i może uniknąć zduplikowania logiki między wieloma jednostkami korzystającymi z tej samej koncepcji. W programie Entity Framework Core można utrwalać obiekty wartości w tej samej tabeli co ich jednostka będąca właścicielem, konfigurując typ jako jednostkę będącą własnością, w następujący sposób:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
W tym przykładzie ShipToAddress właściwość ma typ Address. Address jest obiektem wartości z kilkoma właściwościami, takimi jak Street i City. Program EF Core mapuje Order obiekt na tabelę z jedną kolumną na Address właściwość, prefiksując każdą nazwę kolumny o nazwie właściwości. W tym przykładzie Order tabela będzie zawierać kolumny, takie jak ShipToAddress_Street i ShipToAddress_City. W razie potrzeby można również przechowywać należące do niej typy w oddzielnych tabelach.
Dowiedz się więcej o obsłudze jednostek należących do firmy w programie EF Core.
Połączenia odporne
Zasoby zewnętrzne, takie jak bazy danych SQL, mogą czasami być niedostępne. W przypadkach tymczasowej niedostępności aplikacje mogą używać logiki ponawiania prób, aby uniknąć zgłaszania wyjątku. Ta technika jest często określana jako odporność połączenia. Możesz zaimplementować własną technikę ponawiania przy użyciu techniki wycofywania wykładniczego, próbując ponowić próbę z wykładniczo rosnącym czasem oczekiwania, aż zostanie osiągnięta maksymalna liczba ponownych prób. Ta technika obejmuje fakt, że zasoby w chmurze mogą sporadycznie być niedostępne przez krótki czas, co skutkuje niepowodzeniem niektórych żądań.
W przypadku usługi Azure SQL DB platforma Entity Framework Core już zapewnia wewnętrzną odporność połączenia z bazą danych i logikę ponawiania prób. Należy jednak włączyć strategię wykonywania programu Entity Framework dla każdego połączenia DbContext, jeśli chcesz mieć odporne połączenia programu EF Core.
Na przykład poniższy kod na poziomie połączenia platformy EF Core umożliwia odporne połączenia SQL, które są ponawiane, jeśli połączenie zakończy się niepowodzeniem.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Strategie wykonywania i jawne transakcje przy użyciu funkcji BeginTransaction i wielu obiektów DbContexts
Po włączeniu ponownych prób w połączeniach platformy EF Core każda operacja wykonywana przy użyciu programu EF Core staje się własną operacją z możliwością ponawiania prób. Każde zapytanie i każde wywołanie SaveChangesAsync metody będą ponawiane jako jednostka, jeśli wystąpi błąd przejściowy.
Jeśli jednak kod inicjuje transakcję przy użyciu funkcji BeginTransaction, definiujesz własną grupę operacji, które muszą być traktowane jako jednostka; wszystkie elementy wewnątrz transakcji muszą zostać wycofane, jeśli wystąpi awaria. W przypadku próby wykonania tej transakcji podczas korzystania ze strategii wykonywania programu EF (zasad ponawiania prób) zostanie wyświetlony wyjątek podobny do poniższego i dołączenia kilku SaveChangesAsync z wielu elementów DbContexts.
System.InvalidOperationException: skonfigurowana strategia SqlServerRetryingExecutionStrategy wykonywania nie obsługuje transakcji inicjowanych przez użytkownika. Użyj strategii wykonywania zwróconej przez DbContext.Database.CreateExecutionStrategy() usługę , aby wykonać wszystkie operacje w transakcji jako jednostkę, którą można ponowić.
Rozwiązaniem jest ręczne wywołanie strategii wykonywania ef z delegatem reprezentującym wszystko, co należy wykonać. Jeśli wystąpi błąd przejściowy, strategia wykonywania ponownie wywoła delegata. Poniższy kod pokazuje, jak zaimplementować to podejście:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Pierwszy element DbContext jest elementem _catalogContext , a drugi element DbContext znajduje się w _integrationEventLogService obiekcie . Na koniec akcja Zatwierdź będzie wykonywana wiele obiektów DbContexts i przy użyciu strategii wykonywania programu EF.
Odwołania — Entity Framework Core
- Dokumentacja platformy EF Corehttps://learn.microsoft.com/ef/
- EF Core: powiązane danehttps://learn.microsoft.com/ef/core/querying/related-data
- Unikaj ładowania jednostek z opóźnieniem w aplikacjach ASPNEThttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core lub mikro-ORM?
Chociaż program EF Core jest doskonałym wyborem do zarządzania trwałością, a w większości hermetyzuje szczegóły bazy danych od deweloperów aplikacji, nie jest to jedyny wybór. Inną popularną alternatywą typu open source jest Dapper, tzw. mikro-ORM. Mikro-ORM to uproszczone, mniej funkcjonalne narzędzie do mapowania obiektów na struktury danych. W przypadku języka Dapper jego cele projektowe koncentrują się na wydajności, a nie w pełni hermetyzowaniu bazowych zapytań używanych do pobierania i aktualizowania danych. Ponieważ nie abstrakcji SQL od dewelopera, dapper jest "bliżej metalu" i umożliwia deweloperom pisanie dokładnych zapytań, których chcą użyć do danej operacji dostępu do danych.
Platforma EF Core ma dwie znaczące funkcje, które oddzielają ją od narzędzia Dapper, ale także dodają do obciążeń związanych z wydajnością. Pierwszy to tłumaczenie z wyrażeń LINQ do języka SQL. Tłumaczenia te są buforowane, ale mimo to po raz pierwszy występują obciążenia związane z wykonywaniem tych tłumaczeń. Drugi to śledzenie zmian jednostek (dzięki czemu można wygenerować wydajne instrukcje aktualizacji). To zachowanie można wyłączyć dla określonych zapytań przy użyciu AsNoTracking rozszerzenia . Program EF Core generuje również zapytania SQL, które zwykle są bardzo wydajne i w każdym przypadku doskonale akceptowalne z punktu widzenia wydajności, ale jeśli potrzebujesz dokładnej kontroli nad precyzyjnym zapytaniem do wykonania, możesz również przekazać niestandardowy kod SQL (lub wykonać procedurę składowaną) przy użyciu platformy EF Core. W tym przypadku dapper nadal przewyższa ef Core, ale tylko bardzo nieznacznie. Bieżące dane porównawcze wydajności dla różnych metod dostępu do danych można znaleźć w witrynie Dapper.
Aby zobaczyć, jak składnia języka Dapper różni się od platformy EF Core, rozważ te dwie wersje tej samej metody pobierania listy elementów:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Jeśli musisz utworzyć bardziej złożone grafy obiektów za pomocą narzędzia Dapper, musisz samodzielnie napisać skojarzone zapytania (w przeciwieństwie do dodawania funkcji Dołączanie tak jak w programie EF Core). Ta funkcja jest obsługiwana za pomocą różnych składni, w tym funkcji o nazwie Multi Mapping, która umożliwia mapowanie pojedynczych wierszy na wiele zamapowanych obiektów. Na przykład, biorąc pod uwagę klasę Post z właściwością Właściciel typu Użytkownik, następujący kod SQL zwróci wszystkie niezbędne dane:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Każdy zwrócony wiersz zawiera zarówno dane Użytkownika, jak i Post. Ponieważ dane użytkownika powinny być dołączane do danych Post za pośrednictwem właściwości Właściciel, używana jest następująca funkcja:
(post, user) => { post.Owner = user; return post; }
Pełna lista kodu zwracająca kolekcję wpisów z właściwością Owner wypełniona skojarzonymi danymi użytkownika będzie następująca:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Ponieważ oferuje ona mniej hermetyzacji, narzędzie Dapper wymaga od deweloperów więcej informacji na temat sposobu przechowywania ich danych, wydajnego wykonywania zapytań i pisania większej ilości kodu w celu ich pobrania. Gdy model ulegnie zmianie, zamiast po prostu utworzyć nową migrację (inną funkcję EF Core) i/lub zaktualizować informacje o mapowaniu w jednym miejscu w obiekcie DbContext, każde zapytanie, którego dotyczy ten wpływ, musi zostać zaktualizowane. Te zapytania nie mają gwarancji czasu kompilacji, więc mogą one przerwać w czasie wykonywania w odpowiedzi na zmiany modelu lub bazy danych, co utrudnia szybkie wykrywanie błędów. W zamian za te kompromisy Dapper oferuje bardzo szybką wydajność.
W przypadku większości aplikacji i większości części prawie wszystkich aplikacji platforma EF Core oferuje akceptowalną wydajność. W związku z tym korzyści związane z produktywnością deweloperów mogą przeważyć nad obciążeniem wydajności. W przypadku zapytań, które mogą korzystać z buforowania, rzeczywiste zapytanie może być wykonywane tylko niewielki procent czasu, co sprawia, że stosunkowo małe różnice w wydajności zapytań są stosunkowo małe.
SQL lub NoSQL
Tradycyjnie relacyjne bazy danych, takie jak SQL Server, zdominowały platformę handlową do trwałego przechowywania danych, ale nie są one jedynym dostępnym rozwiązaniem. Bazy danych NoSQL, takie jak MongoDB , oferują inne podejście do przechowywania obiektów. Zamiast mapować obiekty na tabele i wiersze, kolejną opcją jest serializowanie całego grafu obiektów i przechowywanie wyniku. Korzyści wynikające z tego podejścia, przynajmniej początkowo, są prostotą i wydajnością. Łatwiej jest przechowywać pojedynczy zserializowany obiekt z kluczem niż rozkładać obiekt na wiele tabel z relacjami i aktualizować wiersze, które mogły ulec zmianie od czasu ostatniego pobrania obiektu z bazy danych. Podobnie pobieranie i deserializacji pojedynczego obiektu z magazynu opartego na kluczach jest zwykle znacznie szybsze i łatwiejsze niż złożone sprzężenia lub wiele zapytań bazy danych wymaganych do pełnego tworzenia tego samego obiektu z relacyjnej bazy danych. Brak blokad lub transakcji lub stałego schematu sprawia również, że bazy danych NoSQL są dostępne do skalowania na wielu maszynach, obsługując bardzo duże zestawy danych.
Z drugiej strony bazy danych NoSQL (zwykle nazywane) mają swoje wady. Relacyjne bazy danych używają normalizacji, aby wymuszać spójność i unikać duplikowania danych. Takie podejście zmniejsza całkowity rozmiar bazy danych i zapewnia, że aktualizacje udostępnionych danych są dostępne natychmiast w całej bazie danych. W relacyjnej bazie danych tabela Adres może odwoływać się do tabeli Country według identyfikatora, tak aby w przypadku zmiany nazwy kraju/regionu rekordy adresów korzystały z aktualizacji bez konieczności aktualizowania. Jednak w bazie danych NoSQL, adres i skojarzony z nim kraj mogą być serializowane jako część wielu przechowywanych obiektów. Aktualizacja nazwy kraju/regionu wymagałaby zaktualizowania wszystkich takich obiektów, a nie jednego wiersza. Relacyjne bazy danych mogą również zapewnić integralność relacyjną, wymuszając reguły, takie jak klucze obce. Bazy danych NoSQL zwykle nie oferują takich ograniczeń dotyczących danych.
Inna złożoność baz danych NoSQL musi zajmować się przechowywaniem wersji. Po zmianie właściwości obiektu może nie być w stanie wykonać deserializacji z poprzednich wersji, które były przechowywane. W związku z tym wszystkie istniejące obiekty, które mają serializowaną (poprzednią) wersję obiektu, muszą zostać zaktualizowane, aby były zgodne z nowym schematem. Takie podejście nie różni się koncepcyjnie od relacyjnej bazy danych, gdzie zmiany schematu czasami wymagają aktualizacji skryptów lub aktualizacji mapowania. Jednak liczba wpisów, które należy zmodyfikować, jest często znacznie większa w podejściu NoSQL, ponieważ istnieje więcej duplikacji danych.
W bazach danych NoSQL można przechowywać wiele wersji obiektów, co zwykle nie obsługuje relacyjnych baz danych schematu. Jednak w tym przypadku kod aplikacji będzie musiał uwzględnić istnienie poprzednich wersji obiektów, dodając dodatkową złożoność.
Bazy danych NoSQL zwykle nie wymuszają acid, co oznacza, że mają zarówno zalety wydajności, jak i skalowalności w relacyjnych bazach danych. Są one dobrze dostosowane do bardzo dużych zestawów danych i obiektów, które nie są dobrze dostosowane do magazynu w znormalizowanych strukturach tabel. Nie ma powodu, dla którego jedna aplikacja nie może korzystać zarówno z relacyjnych baz danych, jak i Baz danych NoSQL, używając każdej z nich, gdzie jest ona najlepiej odpowiednia.
Azure Cosmos DB
Azure Cosmos DB to w pełni zarządzana usługa bazy danych NoSQL, która oferuje magazyn danych bez schematu oparty na chmurze. Usługa Azure Cosmos DB została utworzona pod kątem szybkiej i przewidywalnej wydajności, wysokiej dostępności, elastycznego skalowania i dystrybucji globalnej. Pomimo bycia bazą danych NoSQL deweloperzy mogą korzystać z zaawansowanych i znanych funkcji zapytań SQL w danych JSON. Wszystkie zasoby w usłudze Azure Cosmos DB są przechowywane jako dokumenty JSON. Zasoby są zarządzane jako elementy, które są dokumentami zawierającymi metadane i źródła danych, które są kolekcjami elementów. Rysunek 8–2 przedstawia relację między różnymi zasobami usługi Azure Cosmos DB.
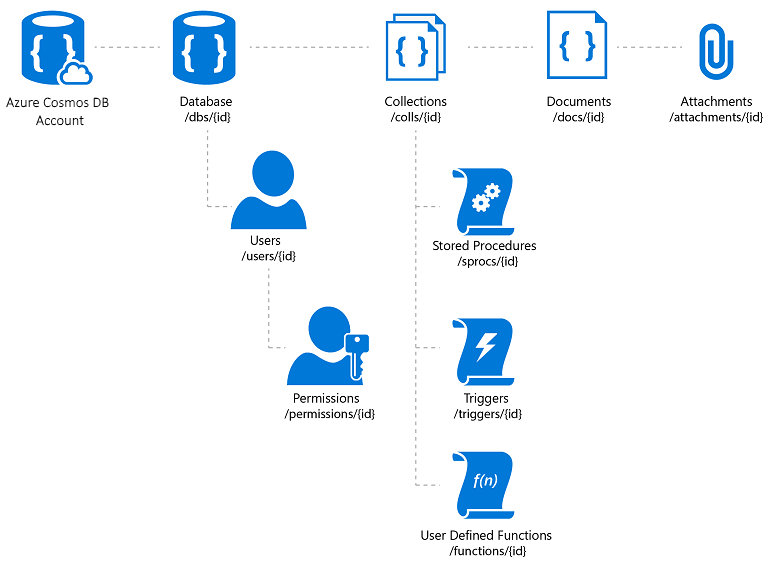
Rysunek 8–2. Organizacja zasobów usługi Azure Cosmos DB.
Język zapytań usługi Azure Cosmos DB to prosty, ale zaawansowany interfejs do wykonywania zapytań dotyczących dokumentów JSON. Język obsługuje podzbiór gramatyki ANSI SQL i dodaje głęboką integrację obiektów, tablic, konstrukcji obiektów i wywoływania funkcji języka JavaScript.
Dokumentacja — Azure Cosmos DB
- Wprowadzenie do usługi Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Inne opcje trwałości
Oprócz opcji magazynu relacyjnego i NoSQL aplikacje ASP.NET Core mogą używać usługi Azure Storage do przechowywania różnych formatów danych i plików w sposób skalowalny w chmurze. Usługa Azure Storage jest wysoce skalowalna, więc możesz rozpocząć przechowywanie małych ilości danych i skalować w górę do przechowywania setek lub terabajtów, jeśli aplikacja tego wymaga. Usługa Azure Storage obsługuje cztery rodzaje danych:
Usługa Blob Storage dla magazynu tekstu bez struktury lub magazynu binarnego, nazywanego również magazynem obiektów.
Usługa Table Storage dla zestawów danych ze strukturą, dostępna za pośrednictwem kluczy wierszy.
Usługa Queue Storage do obsługi niezawodnych komunikatów opartych na kolejkach.
Usługa File Storage na potrzeby dostępu do plików udostępnionych między maszynami wirtualnymi platformy Azure i aplikacjami lokalnymi.
Dokumentacja — Azure Storage
- Wprowadzenie do usługi Azure Storage https://learn.microsoft.com/azure/storage/common/storage-introduction
Buforowanie
W aplikacjach internetowych każde żądanie internetowe powinno zostać ukończone w najkrótszym możliwym czasie. Jednym ze sposobów osiągnięcia tej funkcji jest ograniczenie liczby wywołań zewnętrznych, które serwer musi wykonać w celu ukończenia żądania. Buforowanie obejmuje przechowywanie kopii danych na serwerze (lub innego magazynu danych, który jest łatwiej odpytywane niż źródło danych). Aplikacje internetowe, a zwłaszcza aplikacje internetowe inne niż SPA, muszą tworzyć cały interfejs użytkownika przy każdym żądaniu. Takie podejście często polega na wielokrotnym tworzeniu wielu tych samych zapytań bazy danych z jednego żądania użytkownika do następnego. W większości przypadków te dane rzadko się zmieniają, dlatego nie ma powodu, aby stale żądać ich z bazy danych. ASP.NET Core obsługuje buforowanie odpowiedzi, buforowanie całych stron i buforowanie danych, które obsługuje bardziej szczegółowe zachowanie buforowania.
Podczas implementowania buforowania ważne jest, aby pamiętać o separacji problemów. Unikaj implementowania logiki buforowania w logice dostępu do danych lub w interfejsie użytkownika. Zamiast tego hermetyzowanie buforowania we własnych klasach i używanie konfiguracji do zarządzania jego zachowaniem. Takie podejście jest zgodne z zasadami Open/Closed i Single Responsibility i ułatwi zarządzanie sposobem używania buforowania w aplikacji w miarę jej rozwoju.
buforowanie odpowiedzi ASP.NET Core
ASP.NET Core obsługuje dwa poziomy buforowania odpowiedzi. Pierwszy poziom nie buforuje niczego na serwerze, ale dodaje nagłówki HTTP, które instruują klientów i serwery proxy o buforowanie odpowiedzi. Ta funkcja jest implementowana przez dodanie atrybutu ResponseCache do poszczególnych kontrolerów lub akcji:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
Poprzedni przykład spowoduje dodanie następującego nagłówka do odpowiedzi, poinstruując klientów, aby buforować wynik przez maksymalnie 60 sekund.
Cache-Control: public,max-age=60
Aby dodać buforowanie po stronie serwera do aplikacji, należy odwołać Microsoft.AspNetCore.ResponseCaching się do pakietu NuGet, a następnie dodać oprogramowanie pośredniczące buforowania odpowiedzi. To oprogramowanie pośredniczące jest skonfigurowane z usługami i oprogramowaniem pośredniczącym podczas uruchamiania aplikacji:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
Oprogramowanie pośredniczące buforowania odpowiedzi automatycznie buforuje odpowiedzi na podstawie zestawu warunków, które można dostosować. Domyślnie buforowane są tylko 200 (OK) odpowiedzi żądane za pośrednictwem metod GET lub HEAD. Ponadto żądania muszą mieć odpowiedź z kontrolką pamięci podręcznej: nagłówek publiczny i nie mogą zawierać nagłówków autoryzacji lub set-cookie. Zobacz pełną listę warunków buforowania używanych przez oprogramowanie pośredniczące buforowania odpowiedzi.
Buforowanie danych
Zamiast (lub oprócz) buforowania pełnych odpowiedzi internetowych można buforować wyniki poszczególnych zapytań dotyczących danych. W przypadku tej funkcji można użyć buforowania pamięci na serwerze internetowym lub użyć rozproszonej pamięci podręcznej. W tej sekcji pokazano, jak zaimplementować buforowanie pamięci.
Dodaj obsługę buforowania pamięci (lub rozproszonej) przy użyciu następującego kodu:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Pamiętaj, aby dodać Microsoft.Extensions.Caching.Memory również pakiet NuGet.
Po dodaniu usługi żądasz IMemoryCache za pośrednictwem iniekcji zależności wszędzie tam, gdzie trzeba uzyskać dostęp do pamięci podręcznej. W tym przykładzie CachedCatalogService obiekt używa wzorca projektowego Serwera proxy (lub Decoratora), zapewniając alternatywną implementację ICatalogService tej metody kontroli dostępu do (lub dodaje zachowanie) do podstawowej CatalogService implementacji.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Aby skonfigurować aplikację do używania buforowanej wersji usługi, ale nadal zezwalaj usłudze na uzyskanie wystąpienia usługi CatalogService, którego potrzebuje w konstruktorze, należy dodać następujące wiersze w Program.cs:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Po wprowadzeniu tego kodu wywołania bazy danych w celu pobrania danych wykazu będą wykonywane tylko raz na minutę, a nie na każdym żądaniu. W zależności od ruchu do witryny może to mieć znaczący wpływ na liczbę zapytań wykonanych w bazie danych oraz średni czas ładowania strony głównej, który obecnie zależy od wszystkich trzech zapytań uwidocznionych przez tę usługę.
Problem, który pojawia się, gdy buforowanie jest implementowane, to nieaktualne dane — czyli dane, które uległy zmianie w źródle, ale nieaktualna wersja pozostaje w pamięci podręcznej. Prostym sposobem rozwiązania tego problemu jest użycie małych czasów trwania pamięci podręcznej, ponieważ w przypadku zajętej aplikacji istnieje ograniczona dodatkowa korzyść w celu rozszerzenia danych o długości pamięci podręcznej. Rozważmy na przykład stronę, która tworzy pojedyncze zapytanie bazy danych i jest żądana 10 razy na sekundę. Jeśli ta strona jest buforowana przez jedną minutę, spowoduje to spadek liczby zapytań bazy danych na minutę z 600 do 1, co spowoduje zmniejszenie o 99,8%. Jeśli zamiast tego czas trwania pamięci podręcznej został wykonany o jedną godzinę, ogólna redukcja wyniesie 99,997%, ale teraz prawdopodobieństwo i potencjalny wiek nieaktualnych danych znacznie się zwiększy.
Innym podejściem jest proaktywne usuwanie wpisów pamięci podręcznej po zaktualizowaniu danych, które zawierają. Każdy pojedynczy wpis można usunąć, jeśli jego klucz jest znany:
_cache.Remove(cacheKey);
Jeśli aplikacja uwidacznia funkcjonalność aktualizowania wpisów, które buforuje, możesz usunąć odpowiednie wpisy pamięci podręcznej w kodzie, który wykonuje aktualizacje. Czasami może istnieć wiele różnych wpisów, które zależą od określonego zestawu danych. W takim przypadku może być przydatne tworzenie zależności między wpisami pamięci podręcznej przy użyciu tokenu CancellationChangeToken. Za pomocą tokenu CancellationChangeToken można jednocześnie wygasnąć wiele wpisów pamięci podręcznej, anulując token.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Buforowanie może znacznie zwiększyć wydajność stron internetowych, które wielokrotnie żądają tych samych wartości z bazy danych. Pamiętaj, aby mierzyć dostęp do danych i wydajność stron przed zastosowaniem buforowania i stosować buforowanie tylko wtedy, gdy widać potrzebę poprawy. Buforowanie zużywa zasoby pamięci serwera internetowego i zwiększa złożoność aplikacji, dlatego ważne jest, aby przedwcześnie nie optymalizować przy użyciu tej techniki.
Pobieranie danych do BlazorWebAssembly aplikacji
Jeśli tworzysz aplikacje korzystające z serwera Blazor , możesz użyć programu Entity Framework i innych technologii bezpośredniego dostępu do danych, które zostały omówione do tej pory w tym rozdziale. Jednak podczas tworzenia BlazorWebAssembly aplikacji, takich jak inne struktury SPA, potrzebujesz innej strategii dostępu do danych. Zazwyczaj te aplikacje uzyskują dostęp do danych i wchodzą w interakcje z serwerem za pośrednictwem internetowych punktów końcowych interfejsu API.
Jeśli dane lub operacje są poufne, zapoznaj się z sekcją dotyczącą zabezpieczeń w poprzednim rozdziale i chroń swoje interfejsy API przed nieautoryzowanym dostępem.
Przykład aplikacji znajdziesz BlazorWebAssembly w aplikacji referencyjnej eShopOnWeb w projekcie BlazorAdmin. Ten projekt jest hostowany w projekcie internetowym eShopOnWeb i umożliwia użytkownikom w grupie Administratorzy zarządzanie elementami w sklepie. Zrzut ekranu aplikacji można zobaczyć na rysunku 8–3.
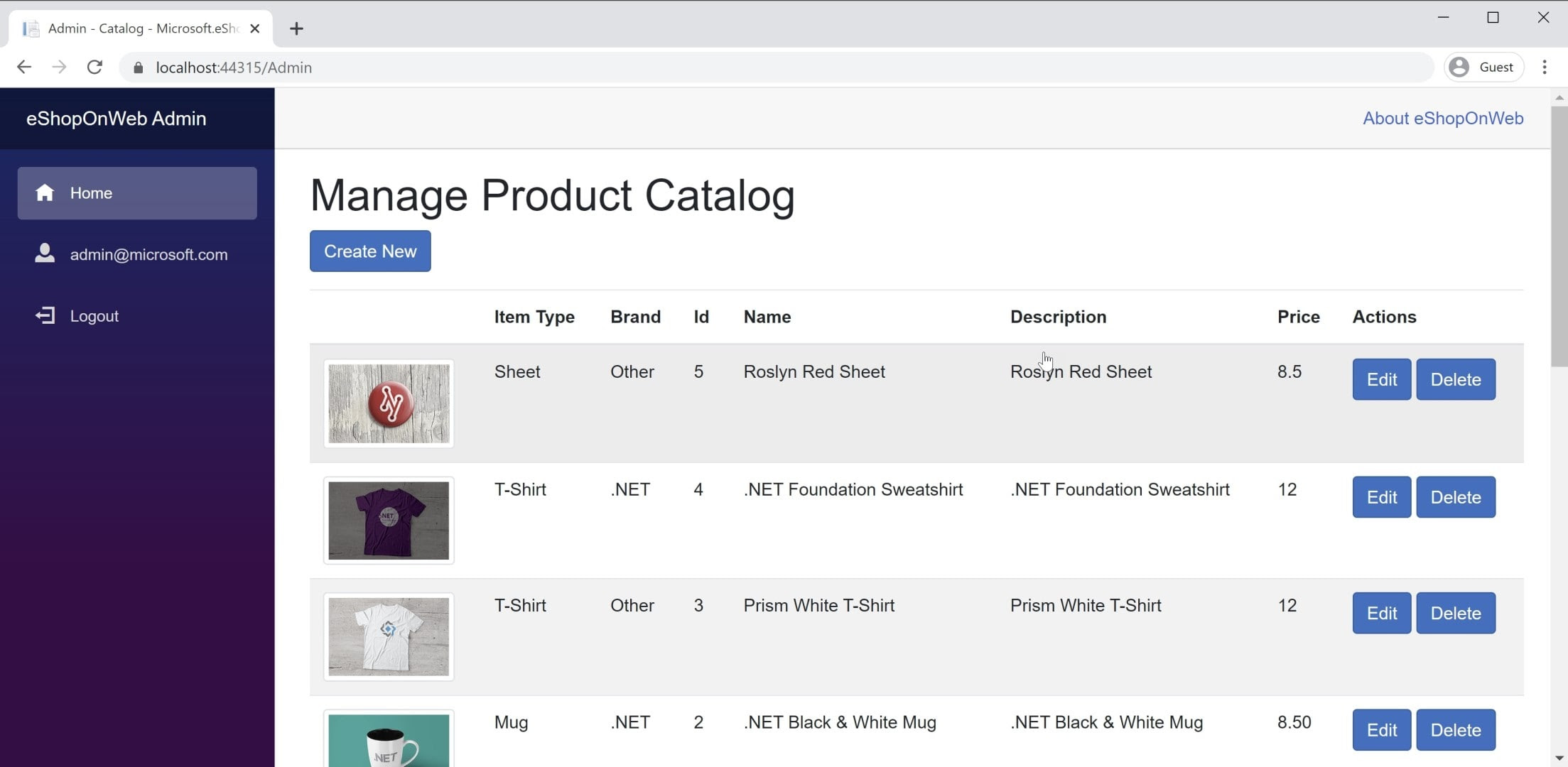
Rysunek 8–3. Zrzut ekranu administratora wykazu eShopOnWeb.
Podczas pobierania danych z internetowych interfejsów API w BlazorWebAssembly aplikacji wystarczy użyć wystąpienia HttpClient , tak jak w dowolnej aplikacji .NET. Podstawowe kroki to utworzenie żądania do wysłania (zwykle w przypadku żądań POST lub PUT), oczekiwanie na samo żądanie, zweryfikowanie kodu stanu i deserializacji odpowiedzi. Jeśli zamierzasz wysyłać wiele żądań do danego zestawu interfejsów API, dobrym pomysłem jest hermetyzowanie interfejsów API i centralne konfigurowanie adresu podstawowego HttpClient . W ten sposób, jeśli musisz dostosować dowolne z tych ustawień między środowiskami, możesz wprowadzić zmiany w jednym miejscu. Należy dodać obsługę tej usługi w pliku Program.Main:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Jeśli chcesz bezpiecznie uzyskać dostęp do usług, należy uzyskać dostęp do bezpiecznego tokenu i skonfigurować ten token, aby przekazać HttpClient ten token jako nagłówek uwierzytelniania z każdym żądaniem:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
To działanie można wykonać z dowolnego składnika, który został HttpClient do niego wstrzyknięty, pod warunkiem, że HttpClient nie został dodany do usług aplikacji z okresem Transient istnienia. Każde odwołanie do elementu w aplikacji odwołuje się do HttpClient tego samego wystąpienia, więc zmienia się na niego w jednym składniku przepływa przez całą aplikację. Dobrym miejscem do przeprowadzenia tego sprawdzania uwierzytelniania (po którym następuje określenie tokenu) jest składnik udostępniony, taki jak główna nawigacja lokacji. Dowiedz się więcej o tym podejściu w projekcie BlazorAdmin w aplikacji referencyjnej eShopOnWeb.
Jedną z zalet BlazorWebAssembly tradycyjnych umów SPA języka JavaScript jest brak konieczności synchronizowania kopii obiektów transferu danych (DTO). Projekt BlazorWebAssembly i projekt internetowego interfejsu API mogą współużytkować te same obiekty DTO we wspólnym udostępnionym projekcie. Takie podejście eliminuje niektóre problemy związane z opracowywaniem umów SPA.
Aby szybko pobrać dane z punktu końcowego interfejsu API, możesz użyć wbudowanej metody pomocniczej . GetFromJsonAsync Istnieją podobne metody post, PUT itp. Poniżej przedstawiono sposób pobierania elementu CatalogItem z punktu końcowego interfejsu API przy użyciu skonfigurowanego HttpClient BlazorWebAssembly w aplikacji:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Gdy masz potrzebne dane, zazwyczaj będziesz śledzić zmiany lokalnie. Jeśli chcesz wprowadzić aktualizacje do magazynu danych zaplecza, w tym celu wywołasz dodatkowe internetowe interfejsy API.
Odwołania — Blazor dane
- Wywoływanie internetowego interfejsu API z platformy ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api