Suwerenność danych przypadająca na mikrousługę
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

Ważną regułą architektury mikrousług jest to, że każda mikrousługa musi posiadać swoje dane i logikę domeny. Tak jak pełna aplikacja jest właścicielem logiki i danych, dlatego każda mikrousługa musi posiadać swoją logikę i dane w ramach autonomicznego cyklu życia z niezależnym wdrożeniem na mikrousługę.
Oznacza to, że koncepcyjny model domeny będzie się różnić między podsystemami lub mikrousługami. Rozważ aplikacje dla przedsiębiorstw, w których aplikacje do zarządzania relacjami z klientami (CRM), podsystemy zakupów transakcyjnych i podsystemy obsługi klienta są wywoływane na unikatowych atrybutach i danych jednostki klienta, a każdy z nich korzysta z innego kontekstu ograniczonego (BC).
Ta zasada jest podobna w projekcie opartym na domenie (DDD), gdzie każdy kontekst ograniczony lub autonomiczny podsystem lub usługa musi posiadać swój model domeny (dane oraz logikę i zachowanie). Każdy kontekst ograniczony DDD jest skorelowany z jedną mikrousługą biznesową (jedną lub kilka usług). Ten punkt dotyczący wzorca ograniczonego kontekstu został rozszerzony w następnej sekcji.
Z drugiej strony tradycyjne (monolityczne) podejście używane w wielu aplikacjach polega na utworzeniu pojedynczej scentralizowanej bazy danych lub kilku bazach danych. Jest to często znormalizowana baza danych SQL używana dla całej aplikacji i wszystkich jej podsystemów wewnętrznych, jak pokazano na rysunku 4–7.
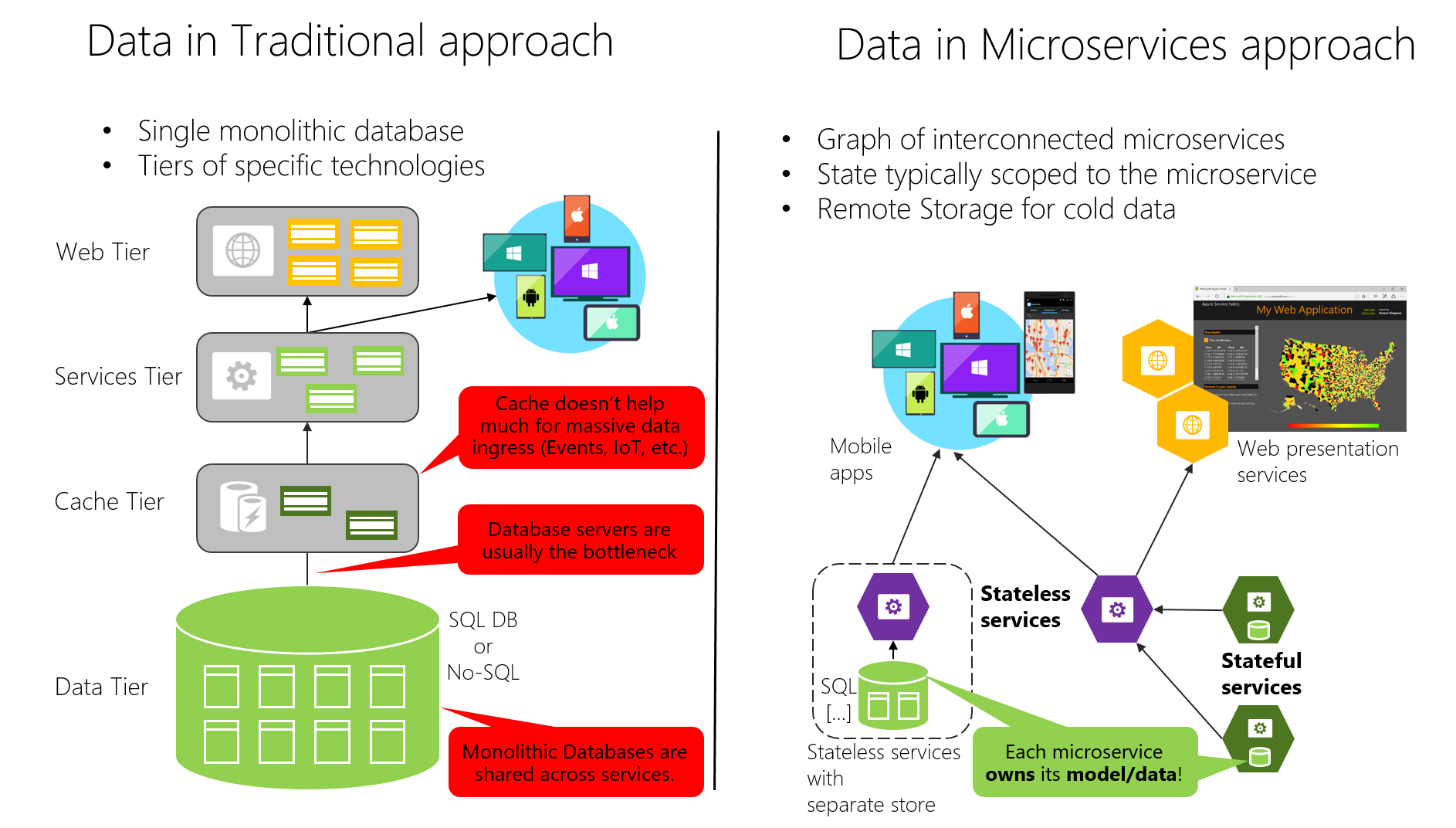
Rysunek 4–7. Porównanie niezależności danych: monolityczna baza danych a mikrousługi
W tradycyjnym podejściu istnieje pojedyncza baza danych współużytkowana we wszystkich usługach, zwykle w architekturze warstwowej. W podejściu mikrousług każda mikrousług jest właścicielem modelu/danych. Podejście scentralizowanej bazy danych początkowo wygląda prostszo i wydaje się umożliwiać ponowne użycie jednostek w różnych podsystemach, aby wszystko było spójne. Ale rzeczywistość jest w końcu ogromne tabele, które obsługują wiele różnych podsystemów, i które zawierają atrybuty i kolumny, które nie są potrzebne w większości przypadków. To jak próba użycia tej samej mapy fizycznej do wędrówki krótki szlak, biorąc jednodniową podróż samochodową i ucząc się geografii.
Aplikacja monolityczna z pojedynczą relacyjną bazą danych ma dwie ważne korzyści: transakcje ACID i język SQL, zarówno działające we wszystkich tabelach, jak i danych związanych z aplikacją. Takie podejście umożliwia łatwe pisanie zapytania, które łączy dane z wielu tabel.
Jednak dostęp do danych staje się znacznie bardziej skomplikowany podczas przechodzenia do architektury mikrousług. Nawet w przypadku korzystania z transakcji ACID w ramach mikrousługi lub ograniczonego kontekstu należy wziąć pod uwagę, że dane należące do każdej mikrousługi są prywatne dla tej mikrousługi i powinny być dostępne tylko synchronicznie za pośrednictwem punktów końcowych interfejsu API (REST, gRPC, SOAP itp.) lub asynchronicznie za pośrednictwem komunikatów (AMQP lub podobnych).
Hermetyzowanie danych gwarantuje, że mikrousługi są luźno powiązane i mogą ewoluować niezależnie od siebie. Gdyby wiele usług uzyskiwało dostęp do tych samych danych, aktualizacje schematu wymagałyby skoordynowanych aktualizacji wszystkich usług. Spowoduje to przerwanie autonomii cyklu życia mikrousług. Jednak rozproszone struktury danych oznaczają, że nie można wykonać jednej transakcji ACID w mikrousługach. Oznacza to z kolei, że należy użyć spójności ostatecznej, gdy proces biznesowy obejmuje wiele mikrousług. Jest to znacznie trudniejsze do zaimplementowania niż proste sprzężenia SQL, ponieważ nie można tworzyć ograniczeń integralności ani używać transakcji rozproszonych między oddzielnymi bazami danych, jak wyjaśnimy później. Podobnie wiele innych funkcji relacyjnej bazy danych nie jest dostępnych w wielu mikrousługach.
Co więcej, różne mikrousługi często używają różnych rodzajów baz danych. Nowoczesne aplikacje przechowują i przetwarzają różne rodzaje danych, a relacyjna baza danych nie zawsze jest najlepszym wyborem. W niektórych przypadkach użycia baza danych NoSQL, taka jak Azure CosmosDB lub MongoDB, może mieć bardziej wygodny model danych i oferować lepszą wydajność i skalowalność niż baza danych SQL, taka jak SQL Server lub Azure SQL Database. W innych przypadkach relacyjna baza danych jest nadal najlepszym rozwiązaniem. W związku z tym aplikacje oparte na mikrousługach często używają kombinacji baz danych SQL i NoSQL, które są czasami nazywane podejściem trwałości wielolotowej .
Partycjonowana, trwała architektura wielolotu dla magazynu danych ma wiele korzyści. Obejmują one luźno powiązane usługi i lepszą wydajność, skalowalność, koszty i możliwości zarządzania. Może jednak wprowadzić pewne rozproszone wyzwania związane z zarządzaniem danymi, jak wyjaśniono w sekcji "Identyfikowanie granic modelu domeny" w dalszej części tego rozdziału.
Relacja między mikrousługami a wzorcem kontekstu ograniczonego
Koncepcja mikrousługi pochodzi ze wzorca powiązanego kontekstu (BC) w projekcie opartym na domenie (DDD). DDD zajmuje się dużymi modelami, dzieląc je na wiele kontrolerów domeny i jawnie o ich granicach. Każdy bc musi mieć własny model i bazę danych; podobnie każda mikrousługa jest właścicielem powiązanych danych. Ponadto każdy bc zwykle ma swój własny wszechobecny język , aby ułatwić komunikację między deweloperami oprogramowania i ekspertami w dziedzinie.
Te terminy (głównie jednostki domeny) w wszechobecnym języku mogą mieć różne nazwy w różnych kontekstach powiązanych, nawet jeśli różne jednostki domeny współużytkują tę samą tożsamość (czyli unikatowy identyfikator używany do odczytywania jednostki z magazynu). Na przykład w kontekście powiązanym z profilem użytkownika jednostka Domeny użytkownika może udostępniać tożsamość jednostce domeny Nabywca w kontekście powiązanym.
Mikrousługa jest zatem podobna do kontekstu ograniczonego, ale określa również, że jest to usługa rozproszona. Jest on tworzony jako oddzielny proces dla każdego powiązanego kontekstu i musi używać zanotowanych wcześniej protokołów rozproszonych, takich jak HTTP/HTTPS, WebSockets lub AMQP. Wzorzec ograniczonego kontekstu nie określa jednak, czy kontekst ograniczony jest usługą rozproszoną, czy też jest to po prostu granica logiczna (taka jak podsystem ogólny) w aplikacji wdrażania monolitycznego.
Ważne jest, aby podkreślić, że zdefiniowanie usługi dla każdego kontekstu ograniczonego jest dobrym miejscem do rozpoczęcia. Ale nie musisz ograniczać projektu do niego. Czasami należy zaprojektować ograniczony kontekst lub mikrousługę biznesową składającą się z kilku usług fizycznych. Jednak ostatecznie oba wzorce — kontekst ograniczony i mikrousługi — są ściśle powiązane.
Usługa DDD korzysta z mikrousług, uzyskując rzeczywiste granice w postaci rozproszonych mikrousług. Jednak pomysły, takie jak nieudzielenie modelu między mikrousługami, są również potrzebne w kontekście powiązanym.
Dodatkowe zasoby
Chris Richardson. Wzorzec: Baza danych na usługę
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. WielolotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Strategiczny projekt oparty na domenie z mapowaniem kontekstu
https://www.infoq.com/articles/ddd-contextmapping