Odporność platformy Azure
Napiwek
Ta zawartość jest fragmentem książki eBook, Architekting Cloud Native .NET Applications for Azure, dostępnej na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

Tworzenie niezawodnej aplikacji w chmurze różni się od tradycyjnego tworzenia aplikacji lokalnych. Podczas gdy w przeszłości zakupiono sprzęt wyższej klasy do skalowania w górę, w środowisku chmury skalowanym w poziomie. Zamiast próbować zapobiec awariom, celem jest zminimalizowanie ich skutków i utrzymanie stabilności systemu.
Oznacza to, że niezawodne aplikacje w chmurze wyświetlają różne cechy:
- Są odporne, bezpiecznie odzyskiwane po problemach i nadal działają.
- Są one wysoce dostępne i działają zgodnie z projektem w dobrej kondycji bez znaczących przestojów.
Zrozumienie, jak te cechy współpracują ze sobą — i jak wpływają na koszty — jest niezbędne do tworzenia niezawodnej aplikacji natywnej dla chmury. Następnie przyjrzymy się sposobom tworzenia odporności i dostępności w aplikacjach natywnych dla chmury korzystających z funkcji z chmury platformy Azure.
Projektowanie z odpornością
Powiedzieliśmy, że odporność umożliwia aplikacji reagowanie na awarię i nadal pozostaje funkcjonalne. Oficjalny dokument dotyczący odporności na platformie Azure zawiera wskazówki dotyczące osiągania odporności na platformie Azure. Oto kilka kluczowych zaleceń:
Awaria sprzętowa. Tworzenie nadmiarowości w aplikacji przez wdrożenie składników w różnych domenach błędów. Upewnij się na przykład, że maszyny wirtualne platformy Azure są umieszczone w różnych stojakach przy użyciu zestawów dostępności.
Awaria centrum danych. Tworzenie nadmiarowości w aplikacji ze strefami izolacji błędów w centrach danych. Na przykład upewnij się, że maszyny wirtualne platformy Azure są umieszczane w różnych centrach danych izolowanych przez błędy przy użyciu usługi Azure Strefy dostępności.
Awaria regionalna. Zreplikuj dane i składniki do innego regionu, aby aplikacje mogły zostać szybko odzyskane. Na przykład użyj usługi Azure Site Recovery, aby replikować maszyny wirtualne platformy Azure do innego regionu świadczenia usługi Azure.
Obciążeniem. Równoważenie obciążenia między wystąpieniami w celu obsługi skoków użycia. Na przykład umieść co najmniej dwie maszyny wirtualne platformy Azure za modułem równoważenia obciążenia, aby dystrybuować ruch do wszystkich maszyn wirtualnych.
Przypadkowe usunięcie lub uszkodzenie danych. Tworzenie kopii zapasowej danych w taki sposób, aby można je było przywrócić w przypadku usunięcia lub uszkodzenia. Na przykład użyj usługi Azure Backup, aby okresowo tworzyć kopie zapasowe maszyn wirtualnych platformy Azure.
Projektowanie z nadmiarowością
Błędy różnią się w zakresie wpływu. Awaria sprzętowa, taka jak dysk, który zakończył się niepowodzeniem, może mieć wpływ na jeden węzeł w klastrze. Awaria przełącznika sieciowego może mieć wpływ na cały stojak serwerowy. Mniej typowe awarie, takie jak utrata zasilania, mogą zakłócić całe centrum danych. Rzadko cały region staje się niedostępny.
Nadmiarowość to jeden ze sposobów zapewnienia odporności aplikacji. Dokładny poziom wymaganej nadmiarowości zależy od wymagań biznesowych i będzie mieć wpływ zarówno na koszt, jak i złożoność systemu. Na przykład wdrożenie w wielu regionach jest droższe i bardziej złożone do zarządzania niż wdrożenie w jednym regionie. Aby zarządzać trybem failover i powrotem po awarii, potrzebne będą procedury operacyjne. Dodatkowe koszty i złożoność mogą być uzasadnione w przypadku niektórych scenariuszy biznesowych, ale nie innych.
Aby utworzyć architekturę nadmiarowości, musisz zidentyfikować ścieżki krytyczne w aplikacji, a następnie określić, czy w każdym punkcie ścieżki występuje nadmiarowość? Jeśli podsystem powinien zakończyć się niepowodzeniem, czy aplikacja przejdzie w tryb failover do czegoś innego? Na koniec potrzebujesz jasnego zrozumienia tych funkcji wbudowanych w platformę w chmurze platformy Azure, którą można wykorzystać, aby spełnić wymagania dotyczące nadmiarowości. Poniżej przedstawiono zalecenia dotyczące tworzenia architektury nadmiarowości:
Wdrażanie wielu wystąpień usług. Jeśli aplikacja zależy od pojedynczego wystąpienia usługi, tworzy pojedynczy punkt awarii. Aprowizowanie wielu wystąpień zwiększa odporność i skalowalność. Podczas hostowania w usłudze Azure Kubernetes Service można deklaratywnie skonfigurować nadmiarowe wystąpienia (zestawy replik) w pliku manifestu kubernetes. Wartość liczby replik można zarządzać programowo, w portalu lub za pomocą funkcji skalowania automatycznego.
Korzystanie z modułu równoważenia obciążenia. Równoważenie obciążenia dystrybuuje żądania aplikacji do wystąpień usługi w dobrej kondycji i automatycznie usuwa wystąpienia w złej kondycji z rotacji. Podczas wdrażania na platformie Kubernetes równoważenie obciążenia można określić w pliku manifestu kubernetes w sekcji Usługi.
Planowanie wdrożenia w wielu regionach. Jeśli aplikacja zostanie wdrożona w jednym regionie i region stanie się niedostępny, aplikacja stanie się również niedostępna. Może to być niedopuszczalne zgodnie z warunkami umów dotyczących poziomu usług aplikacji. Zamiast tego rozważ wdrożenie aplikacji i jej usług w wielu regionach. Na przykład klaster usługi Azure Kubernetes Service (AKS) jest wdrażany w jednym regionie. Aby chronić system przed awarią regionalną, możesz wdrożyć aplikację w wielu klastrach usługi AKS w różnych regionach i użyć funkcji Sparowane regiony w celu koordynowania aktualizacji platformy i określania priorytetów działań związanych z odzyskiwaniem.
Włącz replikację geograficzną. Replikacja geograficzna dla usług, takich jak Azure SQL Database i Cosmos DB, spowoduje utworzenie pomocniczych replik danych w wielu regionach. Chociaż obie usługi będą automatycznie replikować dane w tym samym regionie, replikacja geograficzna chroni Cię przed awarią regionalną, umożliwiając przejście w tryb failover do regionu pomocniczego. Innym najlepszym rozwiązaniem dla centrów replikacji geograficznej wokół przechowywania obrazów kontenerów. Aby wdrożyć usługę w usłudze AKS, musisz przechowywać i ściągać obraz z repozytorium. Usługa Azure Container Registry integruje się z usługą AKS i może bezpiecznie przechowywać obrazy kontenerów. Aby zwiększyć wydajność i dostępność, rozważ replikację geograficzną obrazów do rejestru w każdym regionie, w którym masz klaster usługi AKS. Następnie każdy klaster usługi AKS ściąga obrazy kontenerów z lokalnego rejestru kontenerów w swoim regionie, jak pokazano na rysunku 6–4:
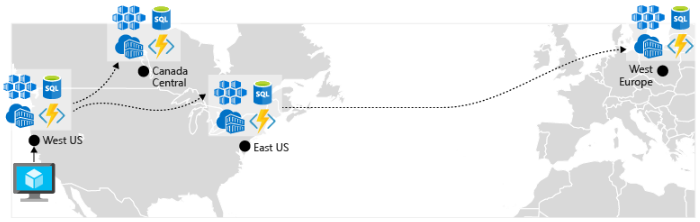
Rysunek 6–4. Zreplikowane zasoby w różnych regionach
- Implementowanie modułu równoważenia obciążenia ruchu DNS.Usługa Azure Traffic Manager zapewnia wysoką dostępność krytycznych aplikacji przez równoważenie obciążenia na poziomie DNS. Może kierować ruch do różnych regionów na podstawie lokalizacji geograficznej, czasu odpowiedzi klastra, a nawet kondycji punktu końcowego aplikacji. Na przykład usługa Azure Traffic Manager może kierować klientów do najbliższego klastra usługi AKS i wystąpienia aplikacji. Jeśli masz wiele klastrów usługi AKS w różnych regionach, użyj usługi Traffic Manager, aby kontrolować przepływ ruchu do aplikacji uruchamianych w każdym klastrze. Rysunek 6–5 przedstawia ten scenariusz.
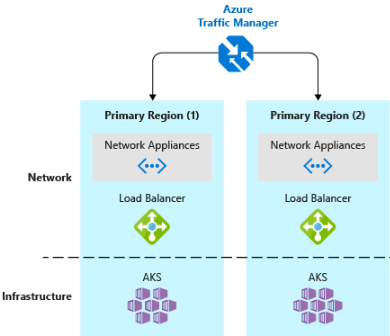
Rysunek 6–5. Usługi AKS i Azure Traffic Manager
Projektowanie pod kątem skalowalności
Chmura rozwija się w zakresie skalowania. Możliwość zwiększania/zmniejszania zasobów systemowych w celu rozwiązania problemu rosnącego/malejącego obciążenia systemu jest kluczowym zestawem chmury platformy Azure. Jednak w celu efektywnego skalowania aplikacji potrzebna jest wiedza na temat funkcji skalowania każdej usługi platformy Azure uwzględnionej w aplikacji. Poniżej przedstawiono zalecenia dotyczące efektywnego implementowania skalowania w systemie.
Projektowanie pod kątem skalowania. Aplikacja musi być zaprojektowana pod kątem skalowania. Aby rozpocząć, usługi powinny być bezstanowe, aby żądania mogły być kierowane do dowolnego wystąpienia. Posiadanie usług bezstanowych oznacza również, że dodawanie lub usuwanie wystąpienia nie ma negatywnego wpływu na bieżących użytkowników.
Partycjonowanie obciążeń. Rozdzielanie domen na niezależne, samodzielne mikrousługi umożliwiają każdej usłudze skalowanie niezależnie od innych. Zazwyczaj usługi będą miały różne potrzeby i wymagania dotyczące skalowalności. Partycjonowanie umożliwia skalowanie tylko tego, co należy skalować bez niepotrzebnego kosztu skalowania całej aplikacji.
Faworyzowanie skalowania w poziomie. Aplikacje oparte na chmurze faworyzują skalowanie zasobów w górę, a nie skalowanie w górę. Skalowanie w poziomie (nazywane również skalowaniem w poziomie) polega na dodaniu większej liczby zasobów usług do istniejącego systemu w celu spełnienia wymagań i udostępnienia żądanego poziomu wydajności. Skalowanie w górę (nazywane również skalowaniem w pionie) polega na zastąpieniu istniejących zasobów bardziej zaawansowanym sprzętem (więcej rdzeni dysku, pamięci i przetwarzania). Skalowanie w górę można wywoływać automatycznie za pomocą funkcji skalowania automatycznego dostępnych w niektórych zasobach w chmurze platformy Azure. Skalowanie w górę w wielu zasobach powoduje również nadmiarowość w całym systemie. Na koniec skalowanie w górę pojedynczego zasobu jest zwykle droższe niż skalowanie w poziomie w wielu mniejszych zasobach. Rysunek 6–6 przedstawia dwa podejścia:
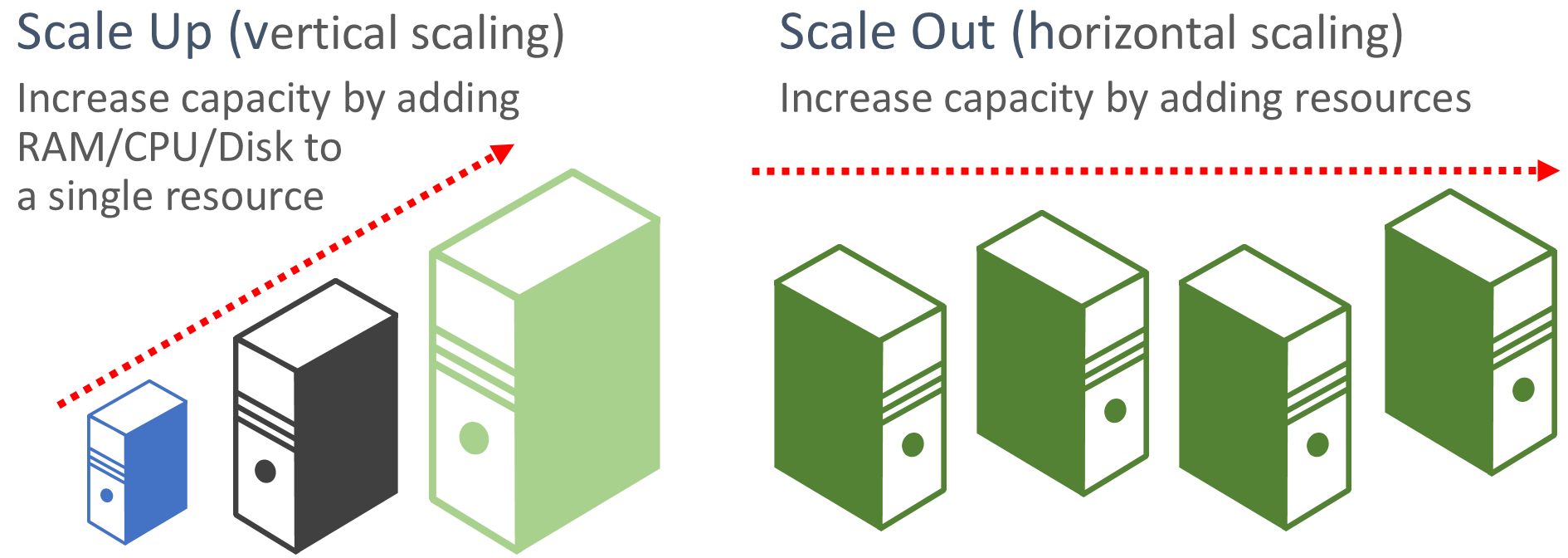
Rysunek 6–6. Skalowanie w górę i skalowanie w poziomie
Skaluj proporcjonalnie. Podczas skalowania usługi należy traktować zestawy zasobów. Jaki wpływ na magazyny danych zaplecza, pamięci podręcznej i usług zależnych, które miałyby znacząco zwiększyć skalę w poziomie? Niektóre zasoby, takie jak Cosmos DB, mogą być skalowane proporcjonalnie, a wiele innych nie może. Chcesz mieć pewność, że nie przeskalujesz zasobu do punktu, w którym zostaną wyczerpane inne skojarzone zasoby.
Unikaj koligacji. Najlepszym rozwiązaniem jest zapewnienie, że węzeł nie wymaga koligacji lokalnej, często określanej jako lepka sesja. Żądanie powinno mieć możliwość kierowania do dowolnego wystąpienia. Jeśli musisz zachować stan, należy go zapisać w rozproszonej pamięci podręcznej, takiej jak pamięć podręczna Azure Redis Cache.
Korzystaj z funkcji skalowania automatycznego platformy. Używaj wbudowanych funkcji skalowania automatycznego, jeśli jest to możliwe, a nie niestandardowych lub innych firm. Jeśli to możliwe, użyj reguł skalowania zaplanowanego, aby upewnić się, że zasoby są dostępne bez opóźnienia uruchamiania, ale dodaj reaktywne skalowanie automatyczne do reguł zgodnie z potrzebami, aby poradzić sobie z nieoczekiwanymi zmianami zapotrzebowania. Aby uzyskać więcej informacji, zobacz Wskazówki dotyczące skalowania automatycznego.
Skalowanie w poziomie agresywnie. Ostateczną praktyką byłoby agresywne skalowanie w poziomie, dzięki czemu można szybko osiągnąć natychmiastowe skoki ruchu bez utraty działalności. A następnie przeprowadź skalowanie w poziomie (czyli usuń niepotrzebne wystąpienia) konserwatywnie, aby zachować stabilność systemu. Prostym sposobem zaimplementowania tego rozwiązania jest ustawienie okresu ochładzania, czyli czasu oczekiwania między operacjami skalowania, do pięciu minut na dodanie zasobów i maksymalnie 15 minut na usunięcie wystąpień.
Wbudowane ponawianie prób w usługach
Zachęcamy do najlepszych rozwiązań w zakresie implementowania operacji ponawiania prób programistycznych we wcześniejszej sekcji. Należy pamiętać, że wiele usług platformy Azure i ich odpowiednich zestawów SDK klientów obejmuje również mechanizmy ponawiania prób. Poniższa lista zawiera podsumowanie funkcji ponawiania prób w wielu usługach platformy Azure omówionych w tej książce:
Azure Cosmos DB. Klasa DocumentClient z interfejsu API klienta automatycznie ponawia próby niepowodzenia. Liczba ponownych prób i maksymalny czas oczekiwania można skonfigurować. Wyjątki zgłaszane przez interfejs API klienta to żądania, które przekraczają zasady ponawiania lub błędy nie przejściowe.
Azure Redis Cache. Klient Redis StackExchange używa klasy menedżera połączeń, która zawiera ponawianie prób w przypadku nieudanych prób. Liczba ponownych prób, określone zasady ponawiania i czas oczekiwania są konfigurowalne.
Azure Service Bus. Klient usługi Service Bus uwidacznia klasę RetryPolicy, którą można skonfigurować za pomocą interwału wycofywania, liczby ponownych prób i TerminationTimeBuffer, która określa maksymalny czas, jaki może potrwać operacja. Domyślne zasady to dziewięć maksymalnych prób ponawiania próby z 30-sekundowym okresem wycofywania między próbami.
Usługa Azure SQL Database. Obsługa ponawiania prób jest dostępna w przypadku korzystania z biblioteki Entity Framework Core .
Azure Storage. Biblioteka klienta magazynu obsługuje operacje ponawiania prób. Strategie różnią się w zależności od tabel, obiektów blob i kolejek usługi Azure Storage. Ponadto alternatywne ponawianie prób przełącza się między lokalizacjami usług magazynowania podstawowego i pomocniczego, gdy funkcja nadmiarowości geograficznej jest włączona.
Azure Event Hubs. Biblioteka klienta centrum zdarzeń zawiera właściwość RetryPolicy, która zawiera konfigurowalną funkcję wycofywania wykładniczego.