Użycie fragmentów
Możesz użyć tilingu, aby zmaksymalizować przyspieszenie aplikacji. Tiling dzieli wątki na równe prostokątne podzbiory lub kafelki. Jeśli używasz odpowiedniego rozmiaru kafelka i algorytmu kafelka, możesz uzyskać jeszcze więcej przyspieszenia z kodu C++ AMP. Podstawowe składniki tilingu to:
tile_staticZmiennych. Główną zaletą tilingu jest uzyskanie dostępu dotile_staticwydajności. Dostęp do danych wtile_staticpamięci może być znacznie szybszy niż dostęp do danych w przestrzeni globalnej (arraylubarray_viewobiektów). Wystąpienie zmiennejtile_staticjest tworzone dla każdego kafelka, a wszystkie wątki na kafelku mają dostęp do zmiennej. W typowym algorytmie kafelków dane są kopiowane dotile_staticpamięci raz z pamięci globalnej, a następnie uzyskiwane wiele razytile_staticz pamięci.tile_barrier::wait, metoda. Wywołanie w celu
tile_barrier::waitwstrzymania wykonywania bieżącego wątku do momentu, aż wszystkie wątki w tym samym kafelku dotrą dotile_barrier::waitwywołania metody . Nie można zagwarantować kolejności uruchamiania wątków, tylko że żadne wątki na kafelku nie będą wykonywane obok wywołania, dopókitile_barrier::waitwszystkie wątki nie osiągną wywołania. Oznacza to, że przy użyciutile_barrier::waitmetody można wykonywać zadania na podstawie kafelka po kafelku, a nie na podstawie wątku po wątku. Typowy algorytm tilinga zawiera kod inicjowaniatile_staticpamięci dla całego kafelka, po którym następuje wywołanie metodytile_barrier::wait.tile_barrier::waitPoniższy kod zawiera obliczenia wymagające dostępu do wszystkichtile_staticwartości.Indeksowanie lokalne i globalne. Masz dostęp do indeksu wątku względem całego
array_viewobiektu lubarrayi indeksu względem kafelka. Użycie indeksu lokalnego może ułatwić odczytywanie i debugowanie kodu. Zazwyczaj indeksowanie lokalne służy do uzyskiwania dostępu do zmiennych oraz indeksowania globalnego w celu uzyskaniatile_staticdostępu doarrayzmiennych iarray_viewzmiennych.klasa tiled_extent i klasa tiled_index. W wywołaniu należy użyć
tiled_extentobiektu zamiastextentobiektu.parallel_for_eachW wywołaniu należy użyćtiled_indexobiektu zamiastindexobiektu.parallel_for_each
Aby móc korzystać z tilingu, algorytm musi podzielić domenę obliczeniową na kafelki, a następnie skopiować dane kafelka do tile_static zmiennych, aby uzyskać szybszy dostęp.
Przykład indeksów globalnych, kafelków i lokalnych
Uwaga
Nagłówki C++ AMP są przestarzałe, począwszy od programu Visual Studio 2022 w wersji 17.0.
Dołączenie wszystkich nagłówków AMP spowoduje wygenerowanie błędów kompilacji. Zdefiniuj _SILENCE_AMP_DEPRECATION_WARNINGS przed dołączeniem żadnych nagłówków AMP, aby wyciszyć ostrzeżenia.
Na poniższym diagramie przedstawiono macierz 8x9 danych rozmieszczonych na 2x3 kafelkach.
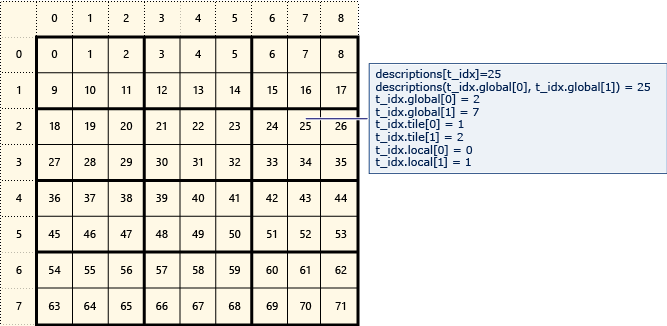
Poniższy przykład przedstawia globalne, kafelki i lokalne indeksy tej macierzy kafelków. Obiekt array_view jest tworzony przy użyciu elementów typu Description. Zawiera Description globalne, kafelki i lokalne indeksy elementu w macierzy. Kod w wywołaniu ustawia parallel_for_each wartości globalnych, kafelków i lokalnych indeksów każdego elementu. Dane wyjściowe wyświetlają wartości w strukturach Description .
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Główną pracą przykładu jest definicja array_view obiektu i wywołanie metody parallel_for_each.
Wektor
Descriptionstruktur jest kopiowany do obiektu 8x9array_view.Metoda
parallel_for_eachjest wywoływana z obiektem jako domeną obliczeniowątiled_extent. Obiekttiled_extentjest tworzony przez wywołanieextent::tile()metody zmiennejdescriptions. Parametry typu wywołania metodyextent::tile(),<2,3>określ, że są tworzone kafelki 2x3. W związku z tym macierz 8x9 jest kafelek na 12 kafelków, cztery wiersze i trzy kolumny.Metoda
parallel_for_eachjest wywoływana przy użyciutiled_index<2,3>obiektu (t_idx) jako indeksu. Parametry typu indeksu (t_idx) muszą być zgodne z parametrami typu domeny obliczeniowej (descriptions.extent.tile< 2, 3>()).Po wykonaniu każdego wątku indeks
t_idxzwraca informacje o tym, który kafelek wątek znajduje się w obiekcie (tiled_index::tilewłaściwość) i lokalizację wątku w kafelku (tiled_index::localwłaściwość).
Synchronizacja kafelków — tile_static i tile_barrier::wait
W poprzednim przykładzie pokazano układ kafelka i indeksy, ale nie jest on bardzo przydatny. Tiling staje się przydatny, gdy kafelki są integralną częścią algorytmu i wykorzystują tile_static zmienne. Ponieważ wszystkie wątki na kafelku mają dostęp do tile_static zmiennych, wywołania są tile_barrier::wait używane do synchronizowania dostępu do tile_static zmiennych. Mimo że wszystkie wątki na kafelku mają dostęp do tile_static zmiennych, nie ma gwarantowanej kolejności wykonywania wątków na kafelku. W poniższym przykładzie pokazano, jak używać tile_static zmiennych i tile_barrier::wait metody do obliczania średniej wartości każdego kafelka. Poniżej przedstawiono klucze do zrozumienia przykładu:
RawData jest przechowywana w macierzy 8x8.
Rozmiar kafelka to 2x2. Spowoduje to utworzenie siatki 4x4 kafelków, a średnie mogą być przechowywane w macierzy 4x4 przy użyciu
arrayobiektu. Istnieje tylko ograniczona liczba typów, które można przechwycić za pomocą odwołania w funkcji z ograniczeniami AMP. Klasaarrayjest jedną z nich.Rozmiar macierzy i rozmiar próbki są definiowane przy użyciu
#defineinstrukcji, ponieważ parametry typu doarray,array_viewextent, itiled_indexmuszą być wartościami stałymi. Można również użyćconst int staticdeklaracji. Dodatkową korzyścią jest banalna zmiana rozmiaru próbki w celu obliczenia średniej ponad 4x4 kafelków.Dla każdego kafelka zadeklarowana jest tablica
tile_static2x2 wartości zmiennoprzecinkowych. Mimo że deklaracja znajduje się w ścieżce kodu dla każdego wątku, tylko jedna tablica jest tworzona dla każdego kafelka w macierzy.Istnieje wiersz kodu umożliwiający skopiowanie wartości w każdym kafelku do tablicy
tile_static. Dla każdego wątku po skopiowaniu wartości do tablicy wykonanie wątku zostanie zatrzymane z powodu wywołania metodytile_barrier::wait.Gdy wszystkie wątki na kafelku osiągnęły barierę, można obliczyć średnią. Ponieważ kod jest wykonywany dla każdego wątku, istnieje
ifinstrukcja, aby obliczyć średnią tylko dla jednego wątku. Średnia jest przechowywana w zmiennej averages. Bariera jest zasadniczo konstrukcją, która steruje obliczeniami według kafelka, podobnie jak pętlafor.Dane w zmiennej
averages, ponieważ jestarrayto obiekt, muszą zostać skopiowane z powrotem do hosta. W tym przykładzie użyto operatora konwersji wektorów.W pełnym przykładzie można zmienić parametr SAMPLESIZE na 4, a kod jest wykonywany poprawnie bez żadnych innych zmian.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Warunki wyścigu
Może być kuszące utworzenie zmiennej tile_static o nazwie total i zwiększanie tej zmiennej dla każdego wątku w następujący sposób:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Pierwszym problemem z tym podejściem jest to, że tile_static zmienne nie mogą mieć inicjatorów. Drugim problemem jest to, że istnieje warunek wyścigu dla przypisania do total, ponieważ wszystkie wątki na kafelku mają dostęp do zmiennej w żadnej określonej kolejności. Algorytm można zaprogramować tak, aby zezwalał tylko jednemu wątkowi na dostęp do sumy w każdej barierze, jak pokazano poniżej. Jednak to rozwiązanie nie jest rozszerzalne.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Ogrodzenia pamięci
Istnieją dwa rodzaje dostępu do pamięci, które muszą być zsynchronizowane — globalny dostęp do pamięci i tile_static dostęp do pamięci. Obiekt concurrency::array przydziela tylko pamięć globalną. Element concurrency::array_view może odwoływać się do pamięci globalnej, tile_static pamięci lub obu tych elementów w zależności od sposobu jego konstruowania. Istnieją dwa rodzaje pamięci, które muszą być zsynchronizowane:
pamięć globalna
tile_static
Ogrodzenie pamięci zapewnia, że dostęp do pamięci jest dostępny dla innych wątków na kafelku wątku, a dostęp do pamięci jest wykonywany zgodnie z kolejnością programu. Aby to zapewnić, kompilatory i procesory nie zmieniają kolejności operacji odczytu i zapisu w płocie. W języku C++ AMP ogrodzenie pamięci jest tworzone przez wywołanie jednej z następujących metod:
tile_barrier::wait— Metoda: tworzy ogrodzenie wokół pamięci i globalnej
tile_static.tile_barrier::wait_with_all_memory_fence Metoda: tworzy ogrodzenie zarówno wokół pamięci globalnej, jak i
tile_staticpamięci.tile_barrier::wait_with_global_memory_fence Metoda: tworzy ogrodzenie tylko dla pamięci globalnej.
tile_barrier::wait_with_tile_static_memory_fence Metoda: tworzy ogrodzenie tylko
tile_staticwokół pamięci.
Wywoływanie określonego ogrodzenia, którego potrzebujesz, może zwiększyć wydajność aplikacji. Typ bariery wpływa na sposób kompilatora i instrukcji zmiany kolejności sprzętu. Jeśli na przykład używasz globalnego ogrodzenia pamięci, ma zastosowanie tylko do dostępu do pamięci globalnej, a w związku z tym kompilator i sprzęt mogą zmienić kolejność operacji odczytu i zapisu w tile_static zmiennych po obu stronach ogrodzenia.
W następnym przykładzie bariera synchronizuje zapisy z tileValueszmienną tile_static . W tym przykładzie tile_barrier::wait_with_tile_static_memory_fence jest wywoływana nazwa tile_barrier::waitzamiast .
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Zobacz też
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static, słowo kluczowe