Zagadnienia dotyczące platformy aplikacji dla obciążeń o krytycznym znaczeniu na platformie Azure
Platforma Azure udostępnia wiele usług obliczeniowych do hostowania aplikacji o wysokiej dostępności. Usługi różnią się możliwościami i złożonością. Zalecamy wybranie usług na podstawie:
- Wymagania niefunkcjonalne dotyczące niezawodności, dostępności, wydajności i zabezpieczeń.
- Czynniki decyzyjne, takie jak skalowalność, koszt, funkcjonalność i złożoność.
Wybór platformy hostingu aplikacji jest kluczową decyzją, która ma wpływ na wszystkie inne obszary projektowania. Na przykład starsze lub zastrzeżone oprogramowanie programistyczne może nie być uruchamiane w usługach PaaS lub w aplikacjach konteneryzowanych. To ograniczenie wpływałoby na wybór platformy obliczeniowej.
Aplikacja o znaczeniu krytycznym może używać więcej niż jednej usługi obliczeniowej do obsługi wielu złożonych obciążeń i mikrousług, z których każda ma różne wymagania.
Ten obszar projektowania zawiera zalecenia związane z opcjami wyboru, projektowania i konfiguracji obliczeń. Zalecamy również zapoznanie się z drzewem decyzyjnym Obliczenia.
Ważne
Ten artykuł jest częścią serii obciążeń Azure Well-Architected Framework o znaczeniu krytycznym. Jeśli nie znasz tej serii, zalecamy rozpoczęcie od tematu Co to jest obciążenie o krytycznym znaczeniu?
Globalna dystrybucja zasobów platformy
Typowy wzorzec obciążenia o krytycznym znaczeniu obejmuje zasoby globalne i zasoby regionalne.
Usługi platformy Azure, które nie są ograniczone do określonego regionu świadczenia usługi Azure, są wdrażane lub konfigurowane jako zasoby globalne. Niektóre przypadki użycia obejmują dystrybucję ruchu w wielu regionach, przechowywanie stanu trwałego dla całej aplikacji i buforowanie globalnych danych statycznych. Jeśli musisz uwzględnić zarówno architekturę jednostki skalowania, jak i dystrybucję globalną, zastanów się, w jaki sposób zasoby są optymalnie dystrybuowane lub replikowane w różnych regionach świadczenia usługi Azure.
Inne zasoby są wdrażane regionalnie. Te zasoby, które są wdrażane w ramach sygnatury wdrożenia, zwykle odpowiadają jednostce skalowania. Jednak region może mieć więcej niż jedną sygnaturę, a sygnatura może zawierać więcej niż jedną jednostkę. Niezawodność zasobów regionalnych ma kluczowe znaczenie, ponieważ są one odpowiedzialne za uruchamianie głównego obciążenia.
Na poniższej ilustracji przedstawiono projekt wysokiego poziomu. Użytkownik uzyskuje dostęp do aplikacji za pośrednictwem centralnego globalnego punktu wejścia, który następnie przekierowuje żądania do odpowiedniego regionalnego sygnatury wdrożenia:
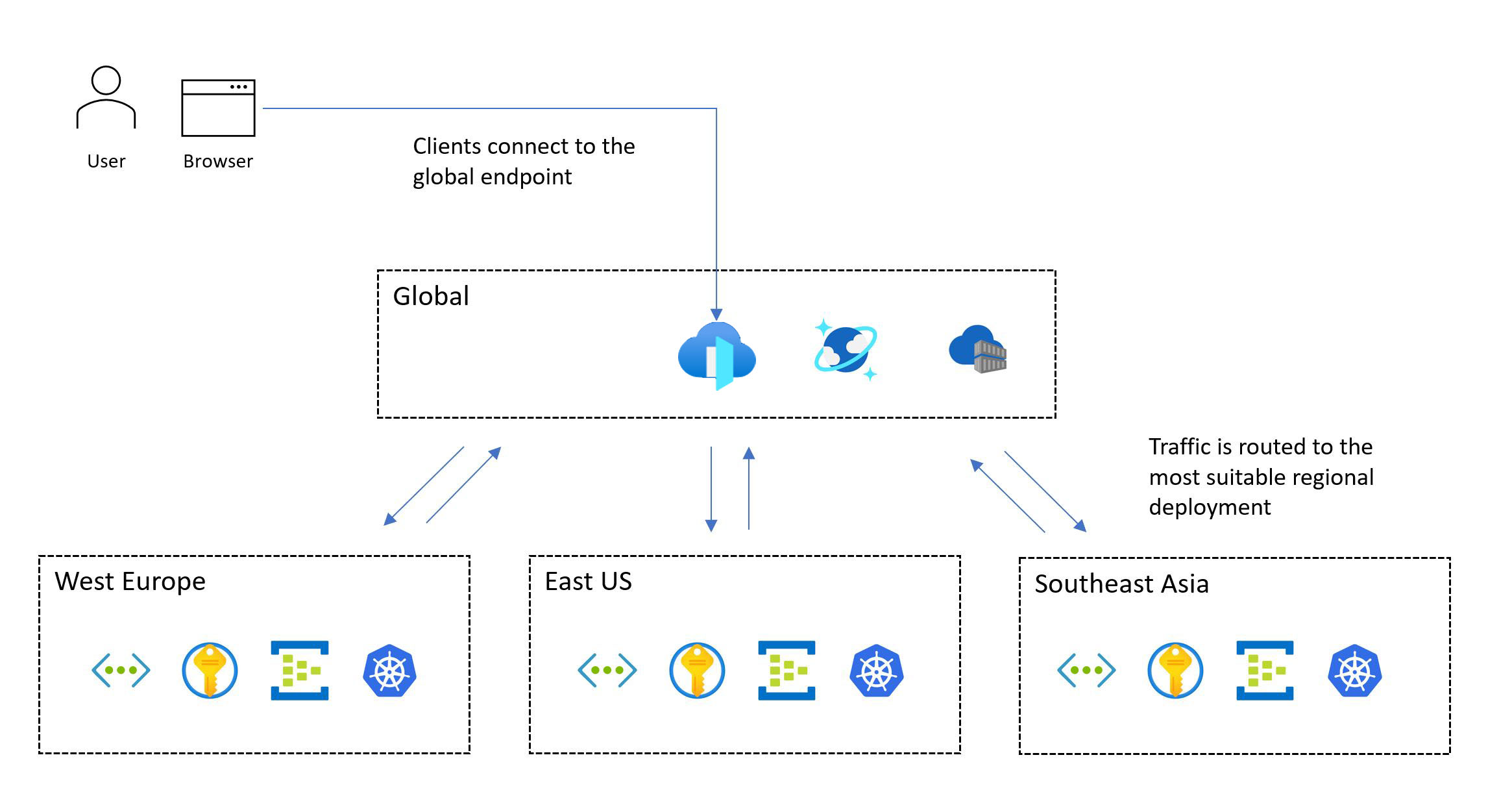
Metodologia projektowania o krytycznym znaczeniu wymaga wdrożenia w wielu regionach. Ten model zapewnia regionalną odporność na uszkodzenia, dzięki czemu aplikacja pozostaje dostępna nawet wtedy, gdy cały region ulegnie awarii. Podczas projektowania aplikacji w wielu regionach należy wziąć pod uwagę różne strategie wdrażania, takie jak aktywne/aktywne i aktywne/pasywne, wraz z wymaganiami aplikacji, ponieważ istnieją znaczące kompromisy dla każdego podejścia. W przypadku obciążeń o krytycznym znaczeniu zdecydowanie zalecamy model aktywny/aktywny.
Nie każde obciążenie obsługuje lub wymaga jednoczesnego uruchamiania wielu regionów. Należy rozważyć określone wymagania dotyczące aplikacji przed kompromisami, aby określić optymalną decyzję projektową. W przypadku niektórych scenariuszy aplikacji, które mają mniejsze cele dotyczące niezawodności, aktywne/pasywne lub fragmentowanie może być odpowiednimi alternatywami.
Strefy dostępności mogą zapewnić wdrożenia regionalne o wysokiej dostępności w różnych centrach danych w regionie. Prawie wszystkie usługi platformy Azure są dostępne w konfiguracji strefowej, w której usługa jest delegowana do określonej strefy lub konfiguracji strefowo nadmiarowej, gdzie platforma automatycznie zapewnia, że usługa rozciąga się między strefami i może wytrzymać awarię strefy. Te konfiguracje zapewniają odporność na uszkodzenia do poziomu centrum danych.
Uwagi dotyczące projektowania
Możliwości regionalne i strefowe. Nie wszystkie usługi i możliwości są dostępne w każdym regionie świadczenia usługi Azure. Ta kwestia może mieć wpływ na wybrane regiony. Ponadto strefy dostępności nie są dostępne w każdym regionie.
Pary regionalne. Regiony platformy Azure są pogrupowane w pary regionalne składające się z dwóch regionów w jednej lokalizacji geograficznej. Niektóre usługi platformy Azure używają sparowanych regionów w celu zapewnienia ciągłości działania i zapewnienia poziomu ochrony przed utratą danych. Na przykład magazyn geograficznie nadmiarowy platformy Azure (GRS) replikuje dane do pomocniczego sparowanego regionu automatycznie, zapewniając trwałość danych, jeśli region podstawowy nie jest możliwy do odzyskania. Jeśli awaria wpłynie na wiele regionów świadczenia usługi Azure, co najmniej jeden region w każdej parze ma priorytet na potrzeby odzyskiwania.
Spójność danych. W przypadku wyzwań związanych ze spójnością rozważ użycie globalnie rozproszonego magazynu danych, architektury regionalnej z sygnaturą i częściowo aktywnego/aktywnego wdrożenia. W ramach częściowego wdrożenia niektóre składniki są aktywne we wszystkich regionach, podczas gdy inne znajdują się centralnie w regionie podstawowym.
Bezpieczne wdrażanie. Platforma SDP (Safe Deployment Practice) platformy Azure zapewnia, że wszystkie zmiany kodu i konfiguracji (planowana konserwacja) na platformie Azure przechodzą etapowe wdrażanie. Kondycja jest analizowana pod kątem pogorszenia w czasie wydania. Po pomyślnym zakończeniu faz kanarowych i pilotażowych aktualizacje platformy są serializowane w parach regionalnych, więc tylko jeden region w każdej parze jest aktualizowany w danym momencie.
Pojemność platformy. Podobnie jak w przypadku każdego dostawcy usług w chmurze platforma Azure ma ograniczone zasoby. Niedostępność może być wynikiem ograniczeń pojemności w regionach. W przypadku awarii regionalnej występuje wzrost zapotrzebowania na zasoby, ponieważ obciążenie próbuje odzyskać w sparowanym regionie. Awaria może spowodować problem z pojemnością, w którym podaż tymczasowo nie spełnia zapotrzebowania.
Zalecenia dotyczące projektowania
Wdróż rozwiązanie w co najmniej dwóch regionach świadczenia usługi Azure, aby chronić przed awariami regionalnymi. Wdróż go w regionach, które mają możliwości i cechy wymagane przez obciążenie. Możliwości powinny spełniać cele dotyczące wydajności i dostępności przy jednoczesnym spełnieniu wymagań dotyczących przechowywania i przechowywania danych.
Na przykład niektóre wymagania dotyczące zgodności danych mogą ograniczać liczbę dostępnych regionów i potencjalnie wymuszać naruszenia projektu. W takich przypadkach zdecydowanie zalecamy dodanie dodatkowych inwestycji w otoki operacyjne w celu przewidywania, wykrywania i reagowania na błędy. Załóżmy, że masz ograniczenie do lokalizacji geograficznej z dwoma regionami, a tylko jeden z tych regionów obsługuje strefy dostępności (model centrum danych 3 + 1). Utwórz wzorzec wdrożenia pomocniczego przy użyciu izolacji domeny błędów, aby umożliwić wdrażanie obu regionów w aktywnej konfiguracji i upewnij się, że region podstawowy zawiera wiele sygnatur wdrożenia.
Jeśli odpowiednie regiony platformy Azure nie oferują potrzebnych możliwości, przygotuj się do naruszenia spójności regionalnych sygnatur wdrażania w celu nadania priorytetów dystrybucji geograficznej i zmaksymalizowania niezawodności. Jeśli odpowiedni jest tylko jeden region świadczenia usługi Azure, wdróż wiele sygnatur wdrożenia (regionalnych jednostek skalowania) w wybranym regionie, aby ograniczyć pewne ryzyko, i użyj stref dostępności, aby zapewnić odporność na uszkodzenia na poziomie centrum danych. Jednak taki znaczący kompromis w dystrybucji geograficznej znacznie ogranicza osiągalne złożone cele SLO i ogólną niezawodność.
Ważne
W przypadku scenariuszy przeznaczonych dla celu slo, który jest większy lub równy 99,99%, zalecamy co najmniej trzy regiony wdrażania. Oblicz złożony cel slo dla wszystkich przepływów użytkownika. Upewnij się, że te cele są zgodne z celami biznesowymi.
W przypadku scenariuszy aplikacji o dużej skali, które mają znaczne ilości ruchu, zaprojektuj rozwiązanie do skalowania w wielu regionach, aby poruszać się po potencjalnych ograniczeniach pojemności w jednym regionie. Dodatkowe regionalne sygnatury wdrożenia mogą osiągnąć wyższy złożony cel slo. Aby uzyskać więcej informacji, zobacz implementowanie obiektów docelowych w wielu regionach.
Zdefiniuj i zweryfikuj cele punktu odzyskiwania (RPO) i cele czasu odzyskiwania (RTO).
W ramach jednej lokalizacji geograficznej określ priorytety użycia par regionalnych w celu skorzystania z serializacji wdrożeń SDP na potrzeby planowanej konserwacji i priorytetyzacji regionalnej w przypadku nieplanowanej konserwacji.
Geograficznie kolokują zasoby platformy Azure z użytkownikami, aby zminimalizować opóźnienie sieci i zmaksymalizować kompleksową wydajność.
- Można również użyć rozwiązań, takich jak content delivery network (CDN) lub buforowanie brzegowe, aby zwiększyć optymalne opóźnienie sieci dla rozproszonych baz użytkowników. Aby uzyskać więcej informacji, zobacz Globalny routing ruchu, Usługi dostarczania aplikacji oraz Buforowanie i dostarczanie zawartości statycznej.
Dopasuj bieżącą dostępność usługi do planów rozwoju produktów podczas wybierania regionów wdrażania. Niektóre usługi mogą nie być natychmiast dostępne w każdym regionie.
Konteneryzacja
Kontener zawiera kod aplikacji oraz powiązane pliki konfiguracji, biblioteki i zależności, które aplikacja musi uruchomić. Konteneryzacja zapewnia warstwę abstrakcji dla kodu aplikacji i jego zależności oraz tworzy separację od bazowej platformy hostingu. Pojedynczy pakiet oprogramowania jest wysoce przenośny i może działać spójnie na różnych platformach infrastruktury i dostawcach usług w chmurze. Deweloperzy nie muszą ponownie pisać kodu i mogą wdrażać aplikacje szybciej i bardziej niezawodnie.
Ważne
Zalecamy używanie kontenerów dla pakietów aplikacji o znaczeniu krytycznym. Zwiększają one wykorzystanie infrastruktury, ponieważ można hostować wiele kontenerów w tej samej infrastrukturze zwirtualizowanej. Ponadto, ponieważ wszystkie oprogramowanie jest zawarte w kontenerze, można przenieść aplikację w różnych systemach operacyjnych, niezależnie od środowisk uruchomieniowych lub wersji biblioteki. Zarządzanie jest również łatwiejsze w przypadku kontenerów niż w przypadku tradycyjnego hostingu zwirtualizowanego.
Aplikacje o krytycznym znaczeniu muszą szybko skalować, aby uniknąć wąskich gardeł wydajności. Ponieważ obrazy kontenerów są wstępnie skompilowane, można ograniczyć uruchamianie tylko podczas uruchamiania aplikacji, co zapewnia szybką skalowalność.
Uwagi dotyczące projektowania
Monitorowanie. Monitorowanie usług w celu uzyskania dostępu do aplikacji w kontenerach może być trudne. Zwykle potrzebne jest oprogramowanie innych firm do zbierania i przechowywania wskaźników stanu kontenera, takich jak użycie procesora CPU lub pamięci RAM.
Zabezpieczenia. Jądro systemu operacyjnego platformy hostingu jest współużytkowane przez wiele kontenerów, tworząc pojedynczy punkt ataku. Jednak ryzyko dostępu do maszyny wirtualnej hosta jest ograniczone, ponieważ kontenery są odizolowane od bazowego systemu operacyjnego.
Stan. Chociaż istnieje możliwość przechowywania danych w uruchomionym systemie plików kontenera, dane nie będą utrwalane po ponownym utworzeniu kontenera. Zamiast tego utrwalaj dane, instalowania magazynu zewnętrznego lub zewnętrznej bazy danych.
Zalecenia dotyczące projektowania
Konteneryzowanie wszystkich składników aplikacji. Użyj obrazów kontenerów jako podstawowego modelu dla pakietów wdrażania aplikacji.
Określ priorytety środowisk uruchomieniowych kontenerów opartych na systemie Linux, jeśli to możliwe. Obrazy są bardziej lekkie, a nowe funkcje dla węzłów/kontenerów systemu Linux są często wydawane.
Utwórz kontenery niezmienne i zamienialne z krótkimi cyklami życia.
Pamiętaj, aby zebrać wszystkie odpowiednie dzienniki i metryki z kontenera, hosta kontenera i klastra bazowego. Wyślij zebrane dzienniki i metryki do ujednoliconego ujścia danych w celu dalszego przetwarzania i analizy.
Przechowywanie obrazów kontenerów w usłudze Azure Container Registry. Replikacja geograficzna umożliwia replikowanie obrazów kontenerów we wszystkich regionach. Włącz usługę Microsoft Defender dla rejestrów kontenerów, aby zapewnić skanowanie luk w zabezpieczeniach pod kątem obrazów kontenerów. Upewnij się, że dostęp do rejestru jest zarządzany przez identyfikator Entra firmy Microsoft.
Hosting kontenerów i aranżacja
Kilka platform aplikacji platformy Azure może efektywnie hostować kontenery. Istnieją zalety i wady związane z każdą z tych platform. Porównaj opcje w kontekście wymagań biznesowych. Jednak zawsze optymalizuj niezawodność, skalowalność i wydajność. Więcej informacji można znaleźć w tych artykułach:
Ważne
Usługi Azure Kubernetes Service (AKS) i Azure Container Apps powinny być jednymi z pierwszych wyborów do zarządzania kontenerami w zależności od wymagań. Mimo że usługa aplikacja systemu Azure nie jest orkiestratorem, jako platforma kontenera o niskim tarciu, nadal jest to wykonalna alternatywa dla usługi AKS.
Zagadnienia i zalecenia dotyczące projektowania usługi Azure Kubernetes Service
Usługa AKS, zarządzana usługa Kubernetes, umożliwia szybką aprowizację klastra bez konieczności wykonywania złożonych działań administracyjnych klastra i oferuje zestaw funkcji, który obejmuje zaawansowane możliwości sieci i tożsamości. Aby uzyskać pełny zestaw zaleceń, zobacz Artykuł Azure Well-Architected Framework review - AKS (Przegląd platformy Azure Well-Architected Framework — AKS).
Ważne
Istnieją pewne podstawowe decyzje dotyczące konfiguracji, których nie można zmienić bez ponownego wdrażania klastra usługi AKS. Przykłady obejmują wybór między publicznymi i prywatnymi klastrami AKS, włączaniem usługi Azure Network Policy, integracją firmy Microsoft i używaniem tożsamości zarządzanych dla usługi AKS zamiast jednostek usługi.
Niezawodność
Usługa AKS zarządza natywną płaszczyzną sterowania kubernetes. Jeśli płaszczyzna sterowania nie jest dostępna, przestój obciążenia. Skorzystaj z funkcji niezawodności oferowanych przez usługę AKS:
Wdróż klastry AKS w różnych regionach świadczenia usługi Azure jako jednostkę skalowania, aby zmaksymalizować niezawodność i dostępność. Strefy dostępności umożliwiają zmaksymalizowanie odporności w regionie świadczenia usługi Azure przez dystrybucję płaszczyzny sterowania usługi AKS i węzłów agenta w fizycznie oddzielnych centrach danych. Jeśli jednak opóźnienie kolokacji jest problemem, możesz wykonać wdrożenie usługi AKS w ramach jednej strefy lub użyć grup umieszczania w pobliżu, aby zminimalizować opóźnienie międzywęźle.
Użyj umowy SLA czasu działania usługi AKS dla klastrów produkcyjnych, aby zmaksymalizować gwarancje dostępności punktu końcowego interfejsu API platformy Kubernetes.
Skalowalność
Weź pod uwagę limity skalowania usługi AKS, takie jak liczba węzłów, pule węzłów na klaster i klastry na subskrypcję.
Jeśli limity skalowania są ograniczeniem, skorzystaj ze strategii jednostki skalowania i wdróż więcej jednostek w klastrach.
Włącz automatyczne skalowanie klastra, aby automatycznie dostosować liczbę węzłów agenta w odpowiedzi na ograniczenia zasobów.
Użyj narzędzia do automatycznego skalowania zasobników w poziomie, aby dostosować liczbę zasobników we wdrożeniu na podstawie użycia procesora CPU lub innych metryk.
W przypadku scenariuszy o dużej skali i zwiększaniu szybkości rozważ użycie węzłów wirtualnych na potrzeby rozległej i szybkiej skali.
Zdefiniuj żądania zasobów zasobnika i limity w manifestach wdrażania aplikacji. Jeśli tego nie zrobisz, mogą wystąpić problemy z wydajnością.
Izolacja
Zachowaj granice między infrastrukturą używaną przez obciążenie i narzędzia systemowe. Udostępnianie infrastruktury może prowadzić do wysokiego wykorzystania zasobów i hałaśliwych scenariuszy sąsiadów.
Użyj oddzielnych pul węzłów dla usług systemowych i roboczych. Dedykowane pule węzłów dla składników obciążenia powinny być oparte na wymaganiach dotyczących wyspecjalizowanych zasobów infrastruktury, takich jak maszyny wirtualne procesora GPU o wysokiej pamięci. Ogólnie rzecz biorąc, aby zmniejszyć niepotrzebne obciążenie związane z zarządzaniem, unikaj wdrażania dużej liczby pul węzłów.
Użyj defektów i tolerancji , aby zapewnić dedykowane węzły i ograniczyć aplikacje intensywnie korzystające z zasobów.
Oceń wymagania dotyczące koligacji aplikacji i koligacji oraz skonfiguruj odpowiednią kolokację kontenerów w węzłach.
Zabezpieczenia
Domyślna wanilia Kubernetes wymaga znacznej konfiguracji, aby zapewnić odpowiedni stan zabezpieczeń dla scenariuszy o znaczeniu krytycznym. Usługa AKS rozwiązuje różne zagrożenia bezpieczeństwa gotowe do użycia. Funkcje obejmują klastry prywatne, inspekcję i logowanie się do usługi Log Analytics, obrazy węzłów ze wzmocnionymi zabezpieczeniami i tożsamości zarządzane.
Zastosuj wskazówki dotyczące konfiguracji podane w punkcie odniesienia zabezpieczeń usługi AKS.
Użyj funkcji usługi AKS do obsługi zarządzania tożsamościami i dostępem klastra, aby zmniejszyć nakład pracy i zastosować spójne zarządzanie dostępem.
Użyj tożsamości zarządzanych zamiast jednostek usługi, aby uniknąć zarządzania i rotacji poświadczeń. Tożsamości zarządzane można dodawać na poziomie klastra. Na poziomie zasobnika można używać tożsamości zarządzanych za pośrednictwem Tożsamość obciążeń Microsoft Entra.
Integracja z firmą Microsoft Entra umożliwia scentralizowane zarządzanie kontami i hasłami, zarządzanie dostępem do aplikacji i rozszerzoną ochronę tożsamości. Użyj kontroli dostępu opartej na rolach kubernetes z identyfikatorem Entra firmy Microsoft w celu uzyskania najniższych uprawnień i zminimalizuj przyznawanie uprawnień administratora, aby chronić dostęp do konfiguracji i wpisów tajnych. Ponadto ogranicz dostęp do pliku konfiguracji klastra Kubernetes przy użyciu kontroli dostępu opartej na rolach platformy Azure. Ogranicz dostęp do akcji, które kontenery mogą wykonywać, zapewniają najmniejszą liczbę uprawnień i unikają eskalacji uprawnień głównych.
Uaktualnienia
Klastry i węzły muszą być regularnie uaktualniane. Usługa AKS obsługuje wersje platformy Kubernetes zgodnie z cyklem wydania natywnego rozwiązania Kubernetes.
Zasubskrybuj publiczny plan usługi AKS i informacje o wersji w usłudze GitHub, aby być na bieżąco z nadchodzącymi zmianami, ulepszeniami i, co najważniejsze, wersjami i wycofaniem wersji platformy Kubernetes.
Zastosuj wskazówki podane na liście kontrolnej usługi AKS, aby zapewnić dopasowanie do najlepszych rozwiązań.
Należy pamiętać o różnych metodach obsługiwanych przez usługę AKS na potrzeby aktualizowania węzłów i/lub klastrów. Te metody mogą być ręczne lub zautomatyzowane. Za pomocą planowanej konserwacji można zdefiniować okna obsługi dla tych operacji. Nowe obrazy są wydawane co tydzień. Usługa AKS obsługuje również kanały automatycznego uaktualniania do automatycznego uaktualniania klastrów usługi AKS do nowszych wersji obrazów platformy Kubernetes i/lub nowszych węzłów, gdy są dostępne.
Sieć
Oceń wtyczki sieciowe, które najlepiej pasują do twojego przypadku użycia. Ustal, czy potrzebujesz szczegółowej kontroli nad ruchem między zasobnikami. pomoc techniczna platformy Azure s kubenet, Azure CNI i bring your own CNI for specific use cases (Azure CNI) i bring your own CNI for specific use cases (Używanie własnej sieci CNI w określonych przypadkach użycia).
Określanie priorytetów użycia usługi Azure CNI po ocenie wymagań sieciowych i rozmiaru klastra. Usługa Azure CNI umożliwia korzystanie z zasad sieci platformy Azure lub Calico na potrzeby kontrolowania ruchu w klastrze.
Monitorowanie
Narzędzia do monitorowania powinny mieć możliwość przechwytywania dzienników i metryk z uruchomionych zasobników. Należy również zebrać informacje z interfejsu API metryk platformy Kubernetes w celu monitorowania kondycji uruchomionych zasobów i obciążeń.
Użyj usług Azure Monitor i Application Insights , aby zbierać metryki, dzienniki i diagnostykę z zasobów usługi AKS na potrzeby rozwiązywania problemów.
Włącz i przejrzyj dzienniki zasobów platformy Kubernetes.
Konfigurowanie metryk rozwiązania Prometheus w usłudze Azure Monitor. Szczegółowe informacje o kontenerach w monitorze udostępniają dołączanie, umożliwiają wbudowane funkcje monitorowania i umożliwiają korzystanie z bardziej zaawansowanych funkcji dzięki wbudowanej obsłudze rozwiązania Prometheus.
Ład korporacyjny
Zasady umożliwiają stosowanie scentralizowanych zabezpieczeń do klastrów usługi AKS w spójny sposób. Stosowanie przypisań zasad w zakresie subskrypcji lub wyższym w celu zwiększenia spójności między zespołami deweloperów.
Kontrolowanie, które funkcje są przyznawane zasobnikom i czy uruchamianie jest sprzeczne z zasadami przy użyciu usługi Azure Policy. Ten dostęp jest definiowany za pomocą wbudowanych zasad udostępnianych przez dodatek usługi Azure Policy dla usługi AKS.
Ustanów spójną niezawodność i punkt odniesienia zabezpieczeń dla konfiguracji klastra i zasobnika usługi AKS przy użyciu usługi Azure Policy.
Użyj dodatku usługi Azure Policy dla usługi AKS, aby kontrolować funkcje zasobnika, takie jak uprawnienia główne, i nie zezwalać zasobnikom, które nie są zgodne z zasadami.
Uwaga
Podczas wdrażania w strefie docelowej platformy Azure zasady platformy Azure, które ułatwiają zapewnienie spójnej niezawodności i bezpieczeństwa, powinny być zapewniane przez implementację strefy docelowej.
Implementacje referencyjne o krytycznym znaczeniu zapewniają zestaw zasad punktu odniesienia, które umożliwiają zapewnienie zalecanej niezawodności i konfiguracji zabezpieczeń.
Zagadnienia dotyczące projektowania i zalecenia dotyczące usługi aplikacja systemu Azure Service
W przypadku scenariuszy obciążeń internetowych i opartych na interfejsie API usługa App Service może być wykonalną alternatywą dla usługi AKS. Zapewnia platformę kontenerów o niskim tarciu bez złożoności platformy Kubernetes. Aby uzyskać pełny zestaw zaleceń, zobacz Zagadnienia dotyczące niezawodności dotyczące usługi App Service i doskonałości operacyjnej dla usługi App Service.
Niezawodność
Oceń użycie portów TCP i SNAT. Połączenia TCP są używane dla wszystkich połączeń wychodzących. Porty SNAT są używane do połączeń wychodzących z publicznymi adresami IP. Wyczerpanie portów SNAT jest typowym scenariuszem awarii. Ten problem należy wykryć predykcyjnie, testując obciążenie podczas używania Diagnostyka Azure do monitorowania portów. Jeśli wystąpią błędy SNAT, należy przeprowadzić skalowanie w większej lub większej regionach roboczych lub zaimplementować praktyki kodowania, aby ułatwić zachowanie i ponowne użycie portów SNAT. Przykłady praktyk kodowania, których można użyć, obejmują buforowanie połączeń i leniwe ładowanie zasobów.
Wyczerpanie portów TCP jest kolejnym scenariuszem awarii. Występuje, gdy suma połączeń wychodzących z danego procesu roboczego przekracza pojemność. Liczba dostępnych portów TCP zależy od rozmiaru procesu roboczego. Aby uzyskać zalecenia, zobacz Porty TCP i SNAT.
Skalowalność
Zaplanuj przyszłe wymagania dotyczące skalowalności i wzrost aplikacji, aby można było zastosować odpowiednie zalecenia od samego początku. Dzięki temu można uniknąć długu migracji technicznej w miarę wzrostu rozwiązania.
Włącz automatyczne skalowanie, aby upewnić się, że odpowiednie zasoby są dostępne dla żądań obsługi. Oceń skalowanie poszczególnych aplikacji pod kątem hostowania o wysokiej gęstości w usłudze App Service.
Należy pamiętać, że usługa App Service ma domyślny, miękki limit wystąpień na plan usługi App Service.
Zastosuj reguły automatycznego skalowania. Plan usługi App Service jest skalowany w poziomie, jeśli jakakolwiek reguła w profilu jest spełniona, ale jest skalowana tylko wtedy, gdy zostaną spełnione wszystkie reguły w profilu. Użyj kombinacji reguł skalowania w poziomie i skalowania w poziomie, aby upewnić się, że skalowanie automatyczne może podejmować działania w celu skalowania w poziomie i skalowania w poziomie. Omówienie zachowania wielu reguł skalowania w jednym profilu.
Należy pamiętać, że możesz włączyć skalowanie poszczególnych aplikacji na poziomie planu usługi App Service, aby umożliwić aplikacji skalowanie niezależnie od planu usługi App Service, który go hostuje. Aplikacje są przydzielane do dostępnych węzłów za pomocą najlepszego podejścia do równomiernej dystrybucji. Mimo że dystrybucja parzysta nie jest gwarantowana, platforma zapewnia, że dwa wystąpienia tej samej aplikacji nie są hostowane w tym samym wystąpieniu.
Monitorowanie
Monitoruj zachowanie aplikacji i uzyskaj dostęp do odpowiednich dzienników i metryk, aby upewnić się, że aplikacja działa zgodnie z oczekiwaniami.
Rejestrowanie diagnostyczne umożliwia pozyskiwanie dzienników na poziomie aplikacji i na poziomie platformy do usługi Log Analytics, Azure Storage lub narzędzia innej firmy za pośrednictwem usługi Azure Event Hubs.
Monitorowanie wydajności aplikacji za pomocą usługi Application Insights zapewnia szczegółowe informacje o wydajności aplikacji.
Aplikacje o znaczeniu krytycznym muszą mieć możliwość samodzielnego leczenia, jeśli występują błędy. Włącz automatyczne uzdrowienie w celu automatycznego recyklingu niezdrowych procesów roboczych.
Należy użyć odpowiednich kontroli kondycji, aby ocenić wszystkie krytyczne zależności podrzędne, co pomaga zapewnić ogólną kondycję. Zdecydowanie zalecamy włączenie sprawdzania kondycji w celu zidentyfikowania pracowników, które nie reagują.
Wdrożenie
Aby obejść domyślny limit wystąpień na plan usługi App Service, wdróż plany usługi App Service w wielu jednostkach skalowania w jednym regionie. Wdróż plany usługi App Service w konfiguracji strefy dostępności, aby upewnić się, że węzły robocze są rozproszone między strefami w regionie. Rozważ otwarcie biletu pomocy technicznej, aby zwiększyć maksymalną liczbę procesów roboczych do dwukrotności liczby wystąpień potrzebnych do obsługi normalnego szczytowego obciążenia.
Rejestr kontenerów
Rejestry kontenerów hostują obrazy, które są wdrażane w środowiskach środowiskach uruchomieniowych kontenerów, takich jak usługa AKS. Należy dokładnie skonfigurować rejestry kontenerów dla obciążeń o znaczeniu krytycznym. Awaria nie powinna powodować opóźnień w ściąganiu obrazów, zwłaszcza podczas operacji skalowania. Poniższe zagadnienia i zalecenia koncentrują się na usłudze Azure Container Registry i eksplorują kompromisy związane ze scentralizowanymi i federacyjnymi modelami wdrażania.
Uwagi dotyczące projektowania
Formatuj. Rozważ użycie rejestru kontenerów, który opiera się na formacie dostarczanym przez platformę Docker i standardach dla operacji wypychania i ściągania. Te rozwiązania są zgodne i w większości zamienne.
Model wdrażania. Rejestr kontenerów można wdrożyć jako scentralizowaną usługę używaną przez wiele aplikacji w organizacji. Możesz też wdrożyć go jako dedykowany składnik dla określonego obciążenia aplikacji.
Rejestry publiczne. Obrazy kontenerów są przechowywane w usłudze Docker Hub lub innych publicznych rejestrach, które istnieją poza platformą Azure i daną siecią wirtualną. Niekoniecznie jest to problem, ale może to prowadzić do różnych problemów związanych z dostępnością usługi, ograniczaniem przepustowości i eksfiltracją danych. W przypadku niektórych scenariuszy aplikacji należy replikować publiczne obrazy kontenerów w prywatnym rejestrze kontenerów, aby ograniczyć ruch wychodzący, zwiększyć dostępność lub uniknąć potencjalnego ograniczania przepustowości.
Zalecenia dotyczące projektowania
Użyj wystąpień rejestru kontenerów przeznaczonych dla obciążenia aplikacji. Unikaj tworzenia zależności od scentralizowanej usługi, chyba że wymagania dotyczące dostępności i niezawodności organizacji są w pełni zgodne z aplikacją.
W zalecanym podstawowym wzorcu architektury rejestry kontenerów są zasobami globalnymi, które są długotrwałe. Rozważ użycie jednego globalnego rejestru kontenerów na środowisko. Na przykład użyj globalnego rejestru produkcyjnego.
Upewnij się, że umowa SLA dla rejestru publicznego jest zgodna z twoimi celami dotyczącymi niezawodności i zabezpieczeń. Zanotuj specjalne limity ograniczania przepustowości dla przypadków użycia, które zależą od usługi Docker Hub.
Określanie priorytetów usługi Azure Container Registry na potrzeby hostowania obrazów kontenerów.
Zagadnienia i zalecenia dotyczące projektowania usługi Azure Container Registry
Ta natywna usługa udostępnia szereg funkcji, w tym replikację geograficzną, uwierzytelnianie Firmy Microsoft Entra, automatyczne kompilowanie kontenerów i stosowanie poprawek za pośrednictwem zadań usługi Container Registry.
Niezawodność
Skonfiguruj replikację geograficzną do wszystkich regionów wdrażania, aby usunąć zależności regionalne i zoptymalizować opóźnienia. Usługa Container Registry obsługuje wysoką dostępność za pośrednictwem replikacji geograficznej do wielu skonfigurowanych regionów, zapewniając odporność na awarie regionalne. Jeśli region stanie się niedostępny, inne regiony będą nadal obsługiwać żądania obrazów. Gdy region powraca do trybu online, usługa Container Registry odzyskuje i replikuje zmiany. Ta funkcja zapewnia również kolokację rejestru w każdym skonfigurowanym regionie, co zmniejsza opóźnienie sieci i koszty transferu danych między regionami.
W regionach platformy Azure, które zapewniają obsługę strefy dostępności, warstwa Premium Container Registry obsługuje nadmiarowość strefy w celu zapewnienia ochrony przed awarią strefową. Warstwa Premium obsługuje również prywatne punkty końcowe , aby zapobiec nieautoryzowanemu dostępowi do rejestru, co może prowadzić do problemów z niezawodnością.
Hostowanie obrazów w pobliżu zużywających zasobów obliczeniowych w tych samych regionach świadczenia usługi Azure.
Blokowanie obrazów
Obrazy mogą zostać usunięte, na przykład w wyniku błędu ręcznego. Usługa Container Registry obsługuje blokowanie wersji obrazu lub repozytorium , aby zapobiec zmianom lub usunięciom. Jeśli wcześniej wdrożona wersja obrazu zostanie zmieniona, wdrożenia w tej samej wersji mogą zapewnić różne wyniki przed zmianą i po jej zmianie.
Jeśli chcesz chronić wystąpienie usługi Container Registry przed usunięciem, użyj blokad zasobów.
Oznakowane obrazy
Oznakowane obrazy usługi Container Registry są domyślnie modyfikowalne, co oznacza, że ten sam tag może być używany na wielu obrazach wypychanych do rejestru. W scenariuszach produkcyjnych może to prowadzić do nieprzewidywalnego zachowania, które może mieć wpływ na czas pracy aplikacji.
Zarządzanie tożsamościami i dostępem
Użyj zintegrowanego uwierzytelniania microsoft Entra, aby wypychać i ściągać obrazy zamiast polegać na kluczach dostępu. W przypadku zwiększonych zabezpieczeń w pełni wyłącz użycie klucza dostępu administratora.
Bezserwerowe usługi obliczeniowe
Przetwarzanie bezserwerowe zapewnia zasoby na żądanie i eliminuje konieczność zarządzania infrastrukturą. Dostawca chmury automatycznie aprowizuje, skaluje i zarządza zasobami wymaganymi do uruchomienia wdrożonego kodu aplikacji. Platforma Azure udostępnia kilka bezserwerowych platform obliczeniowych:
Usługa Azure Functions. W przypadku korzystania z usługi Azure Functions logika aplikacji jest implementowana jako odrębne bloki kodu lub funkcji, które są uruchamiane w odpowiedzi na zdarzenia, takie jak żądanie HTTP lub komunikat kolejki. Każda funkcja jest skalowana zgodnie z potrzebami w celu spełnienia wymagań.
Usługa Azure Logic Apps. Usługa Logic Apps najlepiej nadaje się do tworzenia i uruchamiania zautomatyzowanych przepływów pracy, które integrują różne aplikacje, źródła danych, usługi i systemy. Podobnie jak usługa Azure Functions, usługa Logic Apps używa wbudowanych wyzwalaczy do przetwarzania sterowanego zdarzeniami. Jednak zamiast wdrażać kod aplikacji, można tworzyć aplikacje logiki przy użyciu graficznego interfejsu użytkownika, który obsługuje bloki kodu, takie jak warunkowe i pętle.
Azure API Management. Usługa API Management umożliwia publikowanie, przekształcanie, konserwację i monitorowanie interfejsów API zabezpieczeń rozszerzonych przy użyciu warstwy Zużycie.
Power Apps i Power Automate. Te narzędzia zapewniają środowisko programistyczne z małą ilością kodu lub bez kodu, z prostą logiką przepływu pracy i integracją, które można konfigurować za pośrednictwem połączeń w interfejsie użytkownika.
W przypadku aplikacji o krytycznym znaczeniu technologie bezserwerowe zapewniają uproszczone programowanie i operacje, które mogą być przydatne w przypadku prostych przypadków użycia biznesowego. Jednak ta prostota wiąże się z kosztem elastyczności pod względem skalowalności, niezawodności i wydajności oraz nie jest to możliwe w przypadku większości scenariuszy aplikacji o znaczeniu krytycznym.
W poniższych sekcjach przedstawiono zagadnienia dotyczące projektowania i rekomendacje dotyczące korzystania z usług Azure Functions i Logic Apps jako alternatywnych platform dla scenariuszy przepływu pracy niekrytycznych.
Zagadnienia dotyczące projektowania i zalecenia dotyczące usługi Azure Functions
Obciążenia o znaczeniu krytycznym mają krytyczne i niekrytyczne przepływy systemowe. Usługa Azure Functions to realny wybór przepływów, które nie mają tych samych rygorystycznych wymagań biznesowych co krytyczne przepływy systemowe. Dobrze nadaje się do obsługi przepływów opartych na zdarzeniach, które mają procesy krótkotrwałe, ponieważ funkcje wykonują różne operacje, które działają tak szybko, jak to możliwe.
Wybierz opcję hostingu usługi Azure Functions odpowiednią dla warstwy niezawodności aplikacji. Zalecamy plan Premium, ponieważ umożliwia skonfigurowanie rozmiaru wystąpienia obliczeniowego. Plan dedykowany to najmniej bezserwerowa opcja. Zapewnia automatyczne skalowanie, ale te operacje skalowania są wolniejsze niż te z innych planów. Zalecamy użycie planu Premium w celu zmaksymalizowania niezawodności i wydajności.
Istnieją pewne zagadnienia dotyczące zabezpieczeń. Gdy używasz wyzwalacza HTTP do uwidocznienia zewnętrznego punktu końcowego, użyj zapory aplikacji internetowej (WAF), aby zapewnić poziom ochrony punktu końcowego HTTP z typowych wektorów ataków zewnętrznych.
Zalecamy użycie prywatnych punktów końcowych w celu ograniczenia dostępu do prywatnych sieci wirtualnych. Mogą również ograniczyć ryzyko eksfiltracji danych, takie jak złośliwe scenariusze administratora.
Musisz użyć narzędzi do skanowania kodu w kodzie usługi Azure Functions i zintegrować te narzędzia z potokami ciągłej integracji/ciągłego wdrażania.
Zagadnienia dotyczące projektowania i zalecenia dotyczące usługi Azure Logic Apps
Podobnie jak usługa Azure Functions, usługa Logic Apps używa wbudowanych wyzwalaczy do przetwarzania sterowanego zdarzeniami. Jednak zamiast wdrażać kod aplikacji, można tworzyć aplikacje logiki przy użyciu graficznego interfejsu użytkownika, który obsługuje bloki, takie jak warunkowe, pętle i inne konstrukcje.
Dostępnych jest wiele trybów wdrażania. Zalecamy tryb standardowy, aby zapewnić wdrożenie z jedną dzierżawą i wyeliminować hałaśliwe scenariusze sąsiadów. Ten tryb używa konteneryzowanego środowiska uruchomieniowego usługi Logic Apps z jedną dzierżawą, które jest oparte na usłudze Azure Functions. W tym trybie aplikacja logiki może mieć wiele stanowych i bezstanowych przepływów pracy. Należy pamiętać o limitach konfiguracji.
Migracje ograniczone za pośrednictwem usługi IaaS
Wiele aplikacji, które mają istniejące wdrożenia lokalne, korzysta z technologii wirtualizacji i nadmiarowego sprzętu w celu zapewnienia krytycznych poziomów niezawodności. Modernizacja jest często utrudniona przez ograniczenia biznesowe, które uniemożliwiają pełne dostosowanie do wzorca architektury bazowej (North Star) natywnego dla chmury (North Star), który jest zalecany dla obciążeń o znaczeniu krytycznym. Dlatego wiele aplikacji stosuje podejście etapowe z początkowymi wdrożeniami w chmurze przy użyciu wirtualizacji i usługi Azure Virtual Machines jako podstawowego modelu hostingu aplikacji. Korzystanie z maszyn wirtualnych typu infrastruktura jako usługa (IaaS) może być wymagane w niektórych scenariuszach:
- Dostępne usługi PaaS nie zapewniają wymaganej wydajności ani poziomu kontroli.
- Obciążenie wymaga dostępu do systemu operacyjnego, określonych sterowników lub konfiguracji sieci i systemu.
- Obciążenie nie obsługuje uruchamiania w kontenerach.
- Brak obsługi obciążeń innych firm przez dostawcę.
Ta sekcja koncentruje się na najlepszych sposobach używania maszyn wirtualnych i skojarzonych usług w celu zmaksymalizowania niezawodności platformy aplikacji. Wyróżnia kluczowe aspekty metodologii projektowania o krytycznym znaczeniu, które transponują scenariusze migracji IaaS natywne dla chmury i IaaS.
Uwagi dotyczące projektowania
Koszty operacyjne korzystania z maszyn wirtualnych IaaS są znacznie wyższe niż koszty korzystania z usług PaaS ze względu na wymagania dotyczące zarządzania maszyn wirtualnych i systemów operacyjnych. Zarządzanie maszynami wirtualnymi wymaga częstego wdrażania pakietów i aktualizacji oprogramowania.
Platforma Azure oferuje możliwości zwiększenia dostępności maszyn wirtualnych:
- Strefy dostępności mogą pomóc w osiągnięciu jeszcze wyższego poziomu niezawodności, dystrybuując maszyny wirtualne w fizycznie oddzielonych centrach danych w regionie.
- Zestawy skalowania maszyn wirtualnych platformy Azure zapewniają funkcje automatycznego skalowania liczby maszyn wirtualnych w grupie. Zapewniają one również możliwości monitorowania kondycji wystąpienia i automatycznego naprawiania wystąpień w złej kondycji.
- Zestawy skalowania z elastyczną aranżacją mogą pomóc w ochronie przed awariami sieci, dysku i zasilania przez automatyczne dystrybuowanie maszyn wirtualnych między domenami błędów.
Zalecenia dotyczące projektowania
Ważne
Użyj usług PaaS i kontenerów, jeśli to możliwe, aby zmniejszyć złożoność operacyjną i koszty. Używaj maszyn wirtualnych IaaS tylko wtedy, gdy jest to konieczne.
Rozmiar jednostki SKU maszyny wirtualnej o odpowiednim rozmiarze w celu zapewnienia efektywnego wykorzystania zasobów.
Wdróż co najmniej trzy maszyny wirtualne w różnych strefach dostępności, aby osiągnąć odporność na uszkodzenia na poziomie centrum danych.
- Jeśli wdrażasz komercyjne oprogramowanie poza półki, przed wdrożeniem oprogramowania w środowisku produkcyjnym należy skonsultować się z dostawcą oprogramowania i przetestować je odpowiednio.
W przypadku obciążeń, których nie można wdrożyć w różnych strefach dostępności, użyj elastycznych zestawów skalowania maszyn wirtualnych, które zawierają co najmniej trzy maszyny wirtualne. Aby uzyskać więcej informacji na temat konfigurowania poprawnej liczby domen błędów, zobacz Zarządzanie domenami błędów w zestawach skalowania.
Określanie priorytetów użycia zestawów skalowania maszyn wirtualnych na potrzeby skalowalności i nadmiarowości stref. Jest to szczególnie ważne w przypadku obciążeń, które mają różne obciążenia. Jeśli na przykład liczba aktywnych użytkowników lub żądań na sekundę jest różna.
Nie uzyskujesz bezpośredniego dostępu do poszczególnych maszyn wirtualnych. Używaj modułów równoważenia obciążenia przed nimi, gdy jest to możliwe.
Aby chronić przed awariami regionalnymi, wdróż maszyny wirtualne aplikacji w wielu regionach świadczenia usługi Azure.
- Zobacz obszar projektowania sieci i łączności, aby uzyskać szczegółowe informacje na temat optymalnego kierowania ruchu między aktywnymi regionami wdrażania.
W przypadku obciążeń, które nie obsługują wdrożeń aktywnych/aktywnych w wielu regionach, rozważ wdrożenie wdrożeń aktywnych/pasywnych przy użyciu maszyn wirtualnych rezerwy gorącej/ciepłej na potrzeby regionalnego trybu failover.
Używaj standardowych obrazów z witryny Azure Marketplace, a nie niestandardowych obrazów, które muszą być utrzymywane.
Implementowanie zautomatyzowanych procesów w celu wdrażania i wdrażania zmian na maszynach wirtualnych, co pozwala uniknąć ręcznej interwencji. Aby uzyskać więcej informacji, zobacz Zagadnienia dotyczące IaaS w obszarze projektowania procedur operacyjnych.
Zaimplementuj eksperymenty chaosu, aby wstrzyknąć błędy aplikacji do składników maszyny wirtualnej i obserwować ograniczanie błędów. Aby uzyskać więcej informacji, zobacz Ciągła walidacja i testowanie.
Monitoruj maszyny wirtualne i upewnij się, że dzienniki diagnostyczne i metryki są pozyskiwane do ujednoliconego ujścia danych.
Zaimplementuj rozwiązania zabezpieczeń dla scenariuszy aplikacji o znaczeniu krytycznym, jeśli ma to zastosowanie, oraz najlepsze rozwiązania w zakresie zabezpieczeń obciążeń IaaS na platformie Azure.
Następny krok
Zapoznaj się z zagadnieniami dotyczącymi platformy danych.