Zasady sieciowe usługi Azure Kubernetes
Zasady sieciowe zapewniają mikrosegmentację dla zasobników, podobnie jak sieciowe grupy zabezpieczeń (NSG) zapewniają mikrosegmentację maszyn wirtualnych. Implementacja usługi Azure Network Policy Manager obsługuje standardową specyfikację zasad sieci platformy Kubernetes. Za pomocą etykiet można wybrać grupę zasobników i zdefiniować listę reguł ruchu przychodzącego i wychodzącego, aby filtrować ruch do i z tych zasobników. Dowiedz się więcej o zasadach sieci platformy Kubernetes w dokumentacji platformy Kubernetes.
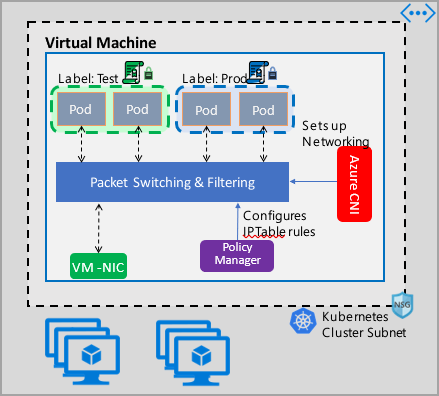
Implementacja zarządzania usługą Azure Network Policy współpracuje z siecią CNI platformy Azure, która zapewnia integrację sieci wirtualnej z kontenerami. Menedżer zasad sieciowych jest obsługiwany w systemach Linux i Windows Server. Implementacja wymusza filtrowanie ruchu przez skonfigurowanie reguł zezwalania i odrzucania adresów IP na podstawie zdefiniowanych zasad w tabelach IPTables systemu Linux lub ACLClPolicies usługi sieci hosta (HNS) dla systemu Windows Server.
Planowanie zabezpieczeń klastra Kubernetes
Podczas implementowania zabezpieczeń klastra użyj sieciowych grup zabezpieczeń do filtrowania ruchu przychodzącego i opuszczającego podsieć klastra (ruch północno-południowy). Użyj usługi Azure Network Policy Manager dla ruchu między zasobnikami w klastrze (ruch wschód-zachód).
Korzystanie z usługi Azure Network Policy Manager
Menedżer usługi Azure Network Policy Manager można używać w następujący sposób, aby zapewnić mikrosegmentację zasobników.
Azure Kubernetes Service (AKS)
Menedżer zasad sieciowych jest dostępny natywnie w usłudze AKS i można go włączyć w momencie tworzenia klastra.
Aby uzyskać więcej informacji, zobacz Zabezpieczanie ruchu między zasobnikami przy użyciu zasad sieciowych w usłudze Azure Kubernetes Service (AKS).
Zrób to samodzielnie (DIY) Klastry Kubernetes na platformie Azure
W przypadku klastrów DIY najpierw zainstaluj wtyczkę CNI i włącz ją na każdej maszynie wirtualnej w klastrze. Aby uzyskać szczegółowe instrukcje, zobacz Wdrażanie wtyczki dla samodzielnie wdrażanego klastra Kubernetes.
Po wdrożeniu klastra uruchom następujące kubectl polecenie, aby pobrać i zastosować demona programu Azure Network Policy Manager ustawionego na klaster.
W przypadku systemu Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
System Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
Rozwiązanie jest również rozwiązaniem typu open source, a kod jest dostępny w repozytorium Azure Container Networking.
Monitorowanie i wizualizowanie konfiguracji sieci za pomocą usługi Azure NPM
Menedżer usługi Azure Network Policy zawiera informacyjne metryki Prometheus, które umożliwiają monitorowanie i lepsze zrozumienie konfiguracji. Udostępnia ona wbudowane wizualizacje w witrynie Azure Portal lub aplikacji Grafana Labs. Możesz rozpocząć gromadzenie tych metryk przy użyciu usługi Azure Monitor lub serwera Prometheus.
Zalety metryk usługi Azure Network Policy Manager
Użytkownicy wcześniej mogli zapoznać się tylko z konfiguracją sieci za pomocą iptables poleceń i ipset uruchamianych wewnątrz węzła klastra, co daje pełne i trudne do zrozumienia dane wyjściowe.
Ogólnie rzecz biorąc, metryki zapewniają:
Liczba zasad, reguł listy ACL, zestawów ipset, wpisów i wpisów w dowolnym zestawie adresów IP
Czas wykonywania poszczególnych wywołań systemu operacyjnego i obsługi zdarzeń zasobów kubernetes (mediana, 90. percentyl i 99. percentyl)
Informacje o niepowodzeniu obsługi zdarzeń zasobów kubernetes (te zdarzenia zasobów kończą się niepowodzeniem, gdy wywołanie systemu operacyjnego kończy się niepowodzeniem)
Przykładowe przypadki użycia metryk
Alerty za pośrednictwem rozwiązania Prometheus AlertManager
Zobacz konfigurację tych alertów w następujący sposób.
Alert, gdy menedżer zasad sieciowych ma błąd z wywołaniem systemu operacyjnego lub podczas tłumaczenia zasad sieciowych.
Alert, gdy mediana czasu stosowania zmian dla zdarzenia tworzenia wynosiła ponad 100 milisekund.
Wizualizacje i debugowanie za pośrednictwem naszego pulpitu nawigacyjnego narzędzia Grafana lub skoroszytu usługi Azure Monitor
Zobacz, ile reguł IPTables tworzy zasady (posiadanie dużej liczby reguł IPTables może nieznacznie zwiększyć opóźnienie).
Skoreluj liczbę klastrów (na przykład listy ACL) z czasem wykonywania.
Pobierz przyjazną dla człowieka nazwę ipset w danej regule IPTables (na przykład
azure-npm-487392reprezentujepodlabel-role:database).
Wszystkie obsługiwane metryki
Poniższa lista zawiera obsługiwane metryki. Każda etykieta quantile ma możliwe wartości 0.5, 0.9i 0.99. Każda etykieta had_error ma możliwe wartości false i true, reprezentując, czy operacja zakończyła się powodzeniem, czy niepowodzeniem.
| Nazwa metryki | opis | Typ metryki Prometheus | Etykiety |
|---|---|---|---|
npm_num_policies |
liczba zasad sieciowych | Miernik | - |
npm_num_iptables_rules |
liczba reguł IPTables | Miernik | - |
npm_num_ipsets |
liczba zestawów IPSet | Miernik | - |
npm_num_ipset_entries |
liczba wpisów adresu IP we wszystkich zestawach adresów IP | Miernik | - |
npm_add_iptables_rule_exec_time |
środowisko uruchomieniowe służące do dodawania reguły IPTables | Podsumowanie | quantile |
npm_add_ipset_exec_time |
środowisko uruchomieniowe służące do dodawania zestawu adresów IP | Podsumowanie | quantile |
npm_ipset_counts (zaawansowane) |
liczba wpisów w poszczególnych zestawach adresów IP | MiernikVec |
set_name & set_hash |
npm_add_policy_exec_time |
środowisko uruchomieniowe służące do dodawania zasad sieciowych | Podsumowanie |
quantile & had_error |
npm_controller_policy_exec_time |
środowisko uruchomieniowe do aktualizowania/usuwania zasad sieciowych | Podsumowanie |
quantile & ( had_erroroperation z wartościami update lub delete) |
npm_controller_namespace_exec_time |
środowisko uruchomieniowe do tworzenia/aktualizowania/usuwania przestrzeni nazw | Podsumowanie |
quantile& ( operationhad_error z wartościami create, updatelub delete) |
npm_controller_pod_exec_time |
środowisko uruchomieniowe do tworzenia/aktualizowania/usuwania zasobnika | Podsumowanie |
quantile& ( operationhad_error z wartościami create, updatelub delete) |
Istnieją również metryki "exec_time_count" i "exec_time_sum" dla każdej metryki podsumowania "exec_time".
Metryki można złomować za pośrednictwem usługi Azure Monitor dla kontenerów lub za pośrednictwem rozwiązania Prometheus.
Konfigurowanie usługi Azure Monitor
Pierwszym krokiem jest włączenie usługi Azure Monitor dla kontenerów dla klastra Kubernetes. Kroki można znaleźć w temacie Azure Monitor for containers Overview (Omówienie usługi Azure Monitor dla kontenerów). Po włączeniu usługi Azure Monitor dla kontenerów skonfiguruj usługę Azure Monitor dla kontenerów ConfigMap , aby włączyć integrację i zbieranie metryk programu Prometheus Network Policy Manager.
Usługa Azure Monitor dla kontenerów ConfigMap zawiera sekcję integrations z ustawieniami umożliwiającymi zbieranie metryk menedżera zasad sieciowych.
Te ustawienia są domyślnie wyłączone w ConfigMap. Włączenie podstawowego ustawienia collect_basic_metrics = true, zbiera podstawowe metryki menedżera zasad sieciowych. Włączenie ustawienia collect_advanced_metrics = true zaawansowanego zbiera zaawansowane metryki oprócz podstawowych metryk.
Po edytowaniu obiektu ConfigMap zapisz ją lokalnie i zastosuj ConfigMap do klastra w następujący sposób.
kubectl apply -f container-azm-ms-agentconfig.yaml
Poniższy fragment kodu pochodzi z usługi Azure Monitor dla kontenerów ConfigMap, która pokazuje integrację menedżera zasad sieci z włączoną zaawansowaną kolekcją metryk.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Zaawansowane metryki są opcjonalne i włączane automatycznie włączają podstawową kolekcję metryk. Zaawansowane metryki obejmują obecnie tylko Network Policy Manager_ipset_counts.
Dowiedz się więcej o ustawieniach kolekcji kontenerów usługi Azure Monitor w mapie konfiguracji.
Opcje wizualizacji dla usługi Azure Monitor
Po włączeniu zbierania metryk menedżera zasad sieci można wyświetlić metryki w witrynie Azure Portal przy użyciu szczegółowych informacji o kontenerze lub w narzędziu Grafana.
Wyświetlanie w witrynie Azure Portal w obszarze szczegółowych informacji dla klastra
Otwórz witrynę Azure Portal. Po przejściu do szczegółowych informacji klastra przejdź do pozycji Skoroszyty i otwórz konfigurację menedżera zasad sieciowych (Network Policy Manager).
Oprócz wyświetlania skoroszytu można również bezpośrednio wykonywać zapytania dotyczące metryk rozwiązania Prometheus w sekcji "Dzienniki". Na przykład to zapytanie zwraca wszystkie zbierane metryki.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
Możesz również wykonywać zapytania dotyczące analizy dzienników bezpośrednio dla metryk. Aby uzyskać więcej informacji, zobacz Wprowadzenie do zapytań usługi Log Analytics.
Wyświetlanie na pulpicie nawigacyjnym narzędzia Grafana
Skonfiguruj serwer Grafana i skonfiguruj źródło danych usługi Log Analytics zgodnie z opisem w tym miejscu. Następnie zaimportuj pulpit nawigacyjny narzędzia Grafana z zapleczem usługi Log Analytics do usługi Grafana Labs.
Pulpit nawigacyjny zawiera wizualizacje podobne do skoroszytu platformy Azure. Panele można dodawać do wykresu i wizualizować metryki menedżera zasad sieciowych z tabeli InsightsMetrics.
Konfigurowanie serwera Prometheus
Niektórzy użytkownicy mogą wybrać zbieranie metryk z serwerem Prometheus zamiast usługi Azure Monitor dla kontenerów. Wystarczy dodać dwa zadania do konfiguracji zeskrobania, aby zebrać metryki menedżera zasad sieciowych.
Aby zainstalować serwer Prometheus, dodaj to repozytorium helm w klastrze:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
następnie dodaj serwer
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
gdzie prometheus-server-scrape-config.yaml składa się z:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
Zadanie można również zastąpić azure-npm-node-metrics następującą zawartością lub dołączyć je do istniejącego zadania dla zasobników Kubernetes:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Konfigurowanie alertów dla menedżera alertów
Jeśli używasz serwera Prometheus, możesz skonfigurować menedżera alertów w następujący sposób. Oto przykładowa konfiguracja dwóch opisanych wcześniej reguł alertów:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Opcje wizualizacji dla rozwiązania Prometheus
W przypadku korzystania z serwera Prometheus obsługiwany jest tylko pulpit nawigacyjny narzędzia Grafana.
Jeśli jeszcze tego nie zrobiono, skonfiguruj serwer Grafana i skonfiguruj źródło danych Prometheus. Następnie zaimportuj nasz pulpit nawigacyjny Grafana z zapleczem rozwiązania Prometheus do usługi Grafana Labs.
Wizualizacje dla tego pulpitu nawigacyjnego są identyczne z pulpitem nawigacyjnym z zapleczem analizy kontenerów/analizy dzienników.
Przykładowe pulpity nawigacyjne
Poniżej przedstawiono przykładowy pulpit nawigacyjny metryk menedżera zasad sieciowych w usłudze Container Insights (CI) i narzędzi Grafana.
Liczby podsumowań ciągłej integracji
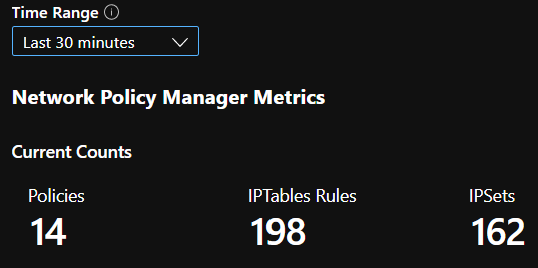
Liczba ciągłej integracji w czasie

Wpisy ci IPSet

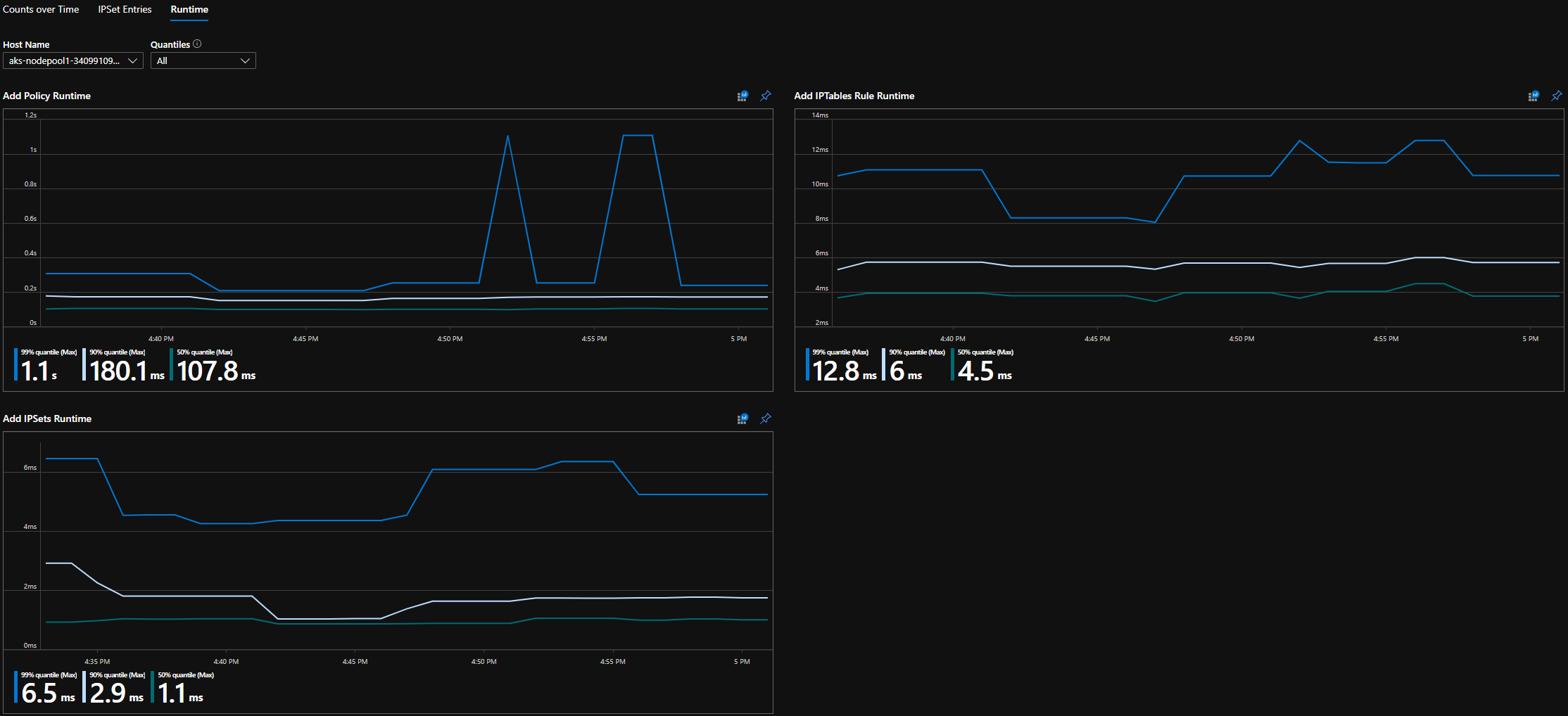
Kwantyle środowiska uruchomieniowego ciągłej integracji
Liczba podsumowań pulpitu nawigacyjnego narzędzia Grafana
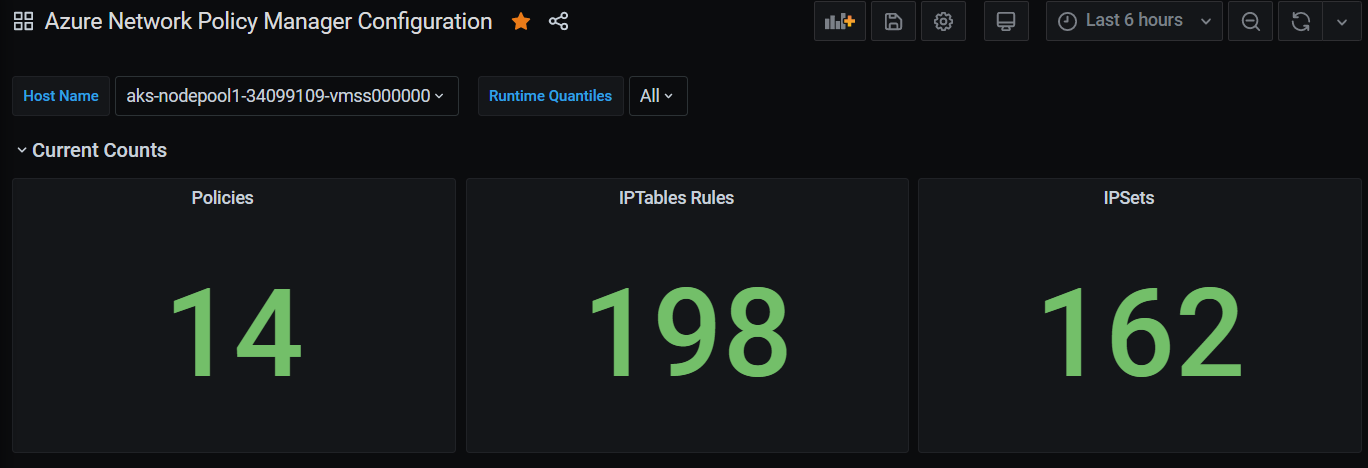
Liczba pulpitów nawigacyjnych narzędzia Grafana w czasie

Wpisy zestawu IPSet pulpitu nawigacyjnego narzędzia Grafana

Kwantyle środowiska uruchomieniowego pulpitu nawigacyjnego narzędzia Grafana

Następne kroki
Dowiedz się więcej o usłudze Azure Kubernetes Service.
Dowiedz się więcej o sieci kontenerów.
Wdróż wtyczkę dla klastrów Kubernetes lub kontenerów platformy Docker.