Instalowanie sterowników procesorów GPU firmy NVIDIA na maszynach wirtualnych z serii N z systemem Linux
Uwaga
W tym artykule odwołuje się do systemu CentOS — dystrybucji systemu Linux, która jest stanem End Of Life (EOL). Rozważ odpowiednie użycie i zaplanuj. Aby uzyskać więcej informacji, zobacz wskazówki dotyczące zakończenia życia systemu CentOS.
Dotyczy: ✔️ maszyny wirtualne z systemem Linux
Aby korzystać z możliwości procesora GPU maszyn wirtualnych serii N platformy Azure wspieranych przez procesory GPU FIRMY NVIDIA, należy zainstalować sterowniki procesora GPU FIRMY NVIDIA. Rozszerzenie sterownika procesora GPU firmy NVIDIA instaluje odpowiednie sterowniki NVIDIA CUDA lub GRID na maszynie wirtualnej serii N. Zainstaluj rozszerzenie lub zarządzaj nim przy użyciu witryny Azure Portal lub narzędzi, takich jak interfejs wiersza polecenia platformy Azure lub szablony usługi Azure Resource Manager. Zapoznaj się z dokumentacją rozszerzenia sterownika procesora GPU firmy NVIDIA, aby zapoznać się z obsługiwanymi dystrybucjami i krokami wdrażania.
Jeśli zdecydujesz się ręcznie zainstalować sterowniki procesora GPU firmy NVIDIA, ten artykuł zawiera obsługiwane dystrybucje, sterowniki i kroki instalacji i weryfikacji. Informacje o ręcznym konfigurowaniu sterowników są również dostępne dla maszyn wirtualnych z systemem Windows.
Aby zapoznać się ze specyfikacjami maszyn wirtualnych serii N, pojemnościami magazynu i szczegółami dysku, zobacz Rozmiary maszyn wirtualnych z systemem Linux z procesorem GPU.
Obsługiwane dystrybucje i sterowniki
Sterowniki NVIDIA CUDA
Najnowsze sterowniki CUDA i obsługiwane systemy operacyjne można znaleźć w witrynie internetowej firmy NVIDIA . Upewnij się, że instalujesz lub uaktualnisz do najnowszych obsługiwanych sterowników CUDA dla twojej dystrybucji.
Uwaga
Najnowsze obsługiwane sterowniki CUDA dla oryginalnych maszyn wirtualnych SKU serii NC to obecnie 470.82.01. Nowsze wersje sterowników nie są obsługiwane na kartach K80 w nc.
Uwaga
Maszyny wirtualne azure NVads A10 v5 obsługują tylko wersje sterowników GRID 14.1(510.73) lub nowsze. Sterownik vGPU dla jednostki SKU A10 to ujednolicony sterownik obsługujący zarówno obciążenia graficzne, jak i obliczeniowe.
Napiwek
Alternatywą dla ręcznej instalacji sterowników CUDA na maszynie wirtualnej z systemem Linux jest wdrożenie obrazu maszyny wirtualnej platformy Azure Nauka o danych. Wersja DSVM dla systemu Ubuntu 16.04 LTS wstępnie instaluje sterowniki NVIDIA CUDA, bibliotekę sieci neuronowej CUDA CUDA i inne narzędzia.
Sterowniki NVIDIA GRID
Firma Microsoft redystrybuuje instalatory sterowników NVIDIA GRID dla maszyn wirtualnych serii NV i NVv3 używanych jako wirtualne stacje robocze lub aplikacje wirtualne. Zainstaluj tylko te sterowniki GRID na maszynach wirtualnych nv platformy Azure, tylko w systemach operacyjnych wymienionych w poniższej tabeli. Sterowniki te obejmują licencjonowanie oprogramowania wirtualnego procesora GPU GRID na platformie Azure. Nie musisz konfigurować serwera licencji oprogramowania NVIDIA vGPU.
Sterowniki GRID redystrybuowane przez platformę Azure nie działają na większości maszyn wirtualnych serii innych niż NV, takich jak NC, NCv2, NCv3, ND i NDv2 serii maszyn wirtualnych, ale działa na serii NCasT4v3.
Aby uzyskać więcej informacji na temat określonych wersji procesorów vGPU i gałęzi sterowników, odwiedź witrynę internetową firmy NVIDIA .
| Dystrybucja | Sterownik |
|---|---|
| Ubuntu 20.04 LTS, 22.04 LTS, 24.02 LTS Red Hat Enterprise Linux 8.6, 8.8, 8.9, 8.10, 9.0, 9.2, 9.3, 9.4, 9.5 SUSE Linux Enterprise Server 15 SP2, 12 SP2,12 SP5 Rocky Linux 8.4 |
NVIDIA vGPU 17.5, gałąź sterownika R550 NVIDIA vGPU 17.5, gałąź sterownika R550 |
Uwaga
W przypadku maszyn wirtualnych azure NVads A10 v5 zalecamy klientom, aby zawsze używali najnowszej wersji sterownika. Najnowsza główna gałąź sterownika NVIDIA (n) jest tylko zgodność wsteczna z poprzednią główną gałęzią (n-1). Na przykład procesor vGPU 17.x jest zgodny z poprzednimi wersjami z procesorem vGPU 16.x. Wszystkie maszyny wirtualne nadal działają n-2 lub niższe mogą powodować błędy sterowników, gdy najnowsza gałąź dysku jest wdrażana na hostach platformy Azure.
NVs_v3 maszyny wirtualne obsługują tylko wersję sterownika vGPU 16 lub mniejszą .
Sterownik GRID 17.3 obecnie obsługuje tylko NCasT4_v3 serii maszyn wirtualnych. Aby użyć tego sterownika, pobierz i zainstaluj ręcznie sterownik GRID 17.3 . Mamy problemy z licencjonowaniem serii NVv5 A10, a platforma Azure aktywnie współpracuje z firmą Nvidia, aby rozwiązać ten problem. Użyj wersji niższej niż v17.x w serii NVv5 A10. Rozszerzenie obecnie instaluje sterowniki 16.5 GRID.
Odwiedź witrynę GitHub, aby uzyskać pełną listę wszystkich poprzednich linków sterowników nvidia GRID.
Ostrzeżenie
Instalacja oprogramowania innych firm na produktach systemu Red Hat może wpłynąć na warunki wsparcia systemu Red Hat. Zobacz artykuł bazy wiedzy systemu Red Hat.
Instalowanie sterowników CUDA na maszynach wirtualnych serii N
Poniżej przedstawiono kroki instalowania sterowników CUDA z zestawu narzędzi NVIDIA CUDA Toolkit na maszynach wirtualnych serii N.
Deweloperzy języka C i C++ mogą opcjonalnie zainstalować pełny zestaw narzędzi do tworzenia aplikacji przyspieszanych przez procesor GPU. Aby uzyskać więcej informacji, zobacz Przewodnik instalacji CUDA.
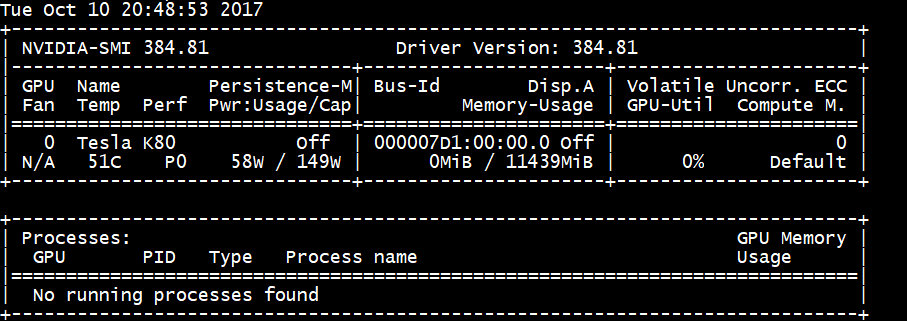
Aby zainstalować sterowniki CUDA, utwórz połączenie SSH z każdą maszyną wirtualną. Aby sprawdzić, czy system ma procesor GPU z obsługą cuda, uruchom następujące polecenie:
lspci | grep -i NVIDIA
Dane wyjściowe są podobne do poniższego przykładu (pokazującego kartę NVIDIA Tesla K80):

Program lspci wyświetla listę urządzeń PCIe na maszynie wirtualnej, w tym kartę sieciową InfiniBand i procesory GPU, jeśli istnieją. Jeśli polecenie lspci nie zostanie zwrócone pomyślnie, może być konieczne zainstalowanie lisów w systemie CentOS/RHEL.
Następnie uruchom polecenia instalacji specyficzne dla twojej dystrybucji.
Ubuntu
Ubuntu pakuje sterowniki własnościowe FIRMY NVIDIA. Te sterowniki pochodzą bezpośrednio z firmy NVIDIA i są po prostu pakowane przez system Ubuntu, dzięki czemu mogą być automatycznie zarządzane przez system. Pobieranie i instalowanie sterowników z innego źródła może prowadzić do uszkodzenia systemu. Ponadto instalowanie sterowników innych firm wymaga dodatkowych kroków na maszynach wirtualnych z włączoną funkcją TrustedLaunch i bezpieczny rozruch. Wymagają one od użytkownika dodania nowego klucza właściciela maszyny do rozruchu systemu. Sterowniki z systemu Ubuntu są podpisane przez firmę Canonical i będą działać z bezpiecznym rozruchem.
Zainstaluj
ubuntu-driversnarzędzie:sudo apt update && sudo apt install -y ubuntu-drivers-commonZainstaluj najnowsze sterowniki FIRMY NVIDIA:
sudo ubuntu-drivers installUruchom ponownie maszynę wirtualną po zainstalowaniu sterownika procesora GPU.
Pobierz i zainstaluj zestaw narzędzi CUDA firmy NVIDIA:
Uwaga
W przykładzie przedstawiono ścieżkę pakietu CUDA dla systemu Ubuntu 24.04 LTS. Zastąp ścieżkę specyficzną dla używanej wersji.
Odwiedź stronę Nvidia Download Center lub NVIDIA CUDA Resources (Zasoby FIRMY NVIDIA CUDA), aby uzyskać pełną ścieżkę specyficzną dla każdej wersji.
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb sudo apt install -y ./cuda-keyring_1.1-1_all.deb sudo apt update sudo apt -y install cuda-toolkit-12-5Instalacja może potrwać kilka minut.
Uruchom ponownie maszynę wirtualną po zakończeniu instalacji:
sudo rebootSprawdź, czy procesor GPU jest poprawnie rozpoznawany (po ponownym uruchomieniu):
nvidia-smi
Aktualizacje sterowników FIRMY NVIDIA
Zalecamy okresowe aktualizowanie sterowników NVIDIA po wdrożeniu.
sudo apt update
sudo apt full-upgrade
CentOS lub Red Hat Enterprise Linux
Zaktualizuj jądro (zalecane). Jeśli zdecydujesz się nie aktualizować jądra, upewnij się, że wersje
kernel-develidkmssą odpowiednie dla jądra.sudo yum install kernel kernel-tools kernel-headers kernel-devel sudo rebootZainstaluj najnowsze usługi Integracji z systemem Linux dla funkcji Hyper-V i platformy Azure. Sprawdź, czy lis jest wymagany, weryfikując wyniki lspci. Jeśli wszystkie urządzenia z procesorem GPU są wyświetlane zgodnie z oczekiwaniami, instalowanie lis nie jest wymagane.
Lis ma zastosowanie do Red Hat Enterprise Linux, CentOS i Oracle Linux Red Hat Compatible Kernel 5.2-5.11, 6.0-6.10 i 7.0-7.7. Aby uzyskać więcej informacji, zapoznaj się z dokumentacją usług Integration Services systemu Linux. Pomiń ten krok, jeśli planujesz używać systemu CentOS/RHEL 7.8 (lub nowszych wersji), ponieważ lis nie jest już wymagany dla tych wersji.
wget https://aka.ms/lis tar xvzf lis cd LISISO sudo ./install.sh sudo rebootPołącz się ponownie z maszyną wirtualną i kontynuuj instalację za pomocą następujących poleceń:
sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm sudo yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.repo sudo yum clean all sudo yum -y install nvidia-driver-latest-dkms cuda-driversInstalacja może potrwać kilka minut.
Uwaga
Odwiedź repozytorium Fedora i Nvidia CUDA, aby wybrać prawidłowy pakiet dla wersji CentOS lub RHEL, której chcesz użyć.
Na przykład systemy CentOS 8 i RHEL 8 wymagają następujących kroków.
sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
sudo yum install dkms
sudo wget https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo -O /etc/yum.repos.d/cuda-rhel8.repo
sudo yum install cuda-drivers
Aby opcjonalnie zainstalować kompletny zestaw narzędzi CUDA, wpisz:
sudo yum install cudaUwaga
Jeśli zostanie wyświetlony komunikat o błędzie związany z brakującymi pakietami, takimi jak vulkan-filesystem, może być konieczne edytowanie /etc/yum.repos.d/rh-cloud, poszukaj opcjonalnych obr./min i ustaw wartość 1
Uruchom ponownie maszynę wirtualną i przejdź do weryfikacji instalacji.
Weryfikowanie instalacji sterownika
Aby wykonać zapytanie dotyczące stanu urządzenia z procesorem GPU, na maszynie wirtualnej należy uruchomić połączenie SSH i uruchomić narzędzie wiersza polecenia nvidia-smi zainstalowane ze sterownikiem.
Jeśli sterownik jest zainstalowany, usługa Nvidia SMI wyświetla narzędzie GPU-Util jako 0% do momentu uruchomienia obciążenia procesora GPU na maszynie wirtualnej. Wersja sterownika i szczegóły procesora GPU mogą różnić się od wyświetlanych.
Łączność sieciowa RDMA
Łączność sieciowa RDMA można włączyć na maszynach wirtualnych serii N z obsługą rdMA, takich jak NC24r wdrożonych w tym samym zestawie dostępności lub w jednej grupie umieszczania w zestawie skalowania maszyn wirtualnych. Sieć RDMA obsługuje ruch interfejsu MPI (Message Passing Interface) dla aplikacji działających z programem Intel MPI 5.x lub nowszą wersją:
Dystrybucji
Wdróż maszyny wirtualne serii N z obsługą funkcji RDMA z jednego z obrazów w witrynie Azure Marketplace, które obsługują łączność RDMA na maszynach wirtualnych serii N:
Ubuntu 16.04 LTS — konfigurowanie sterowników RDMA na maszynie wirtualnej i rejestrowanie się w środowisku Intel w celu pobrania programu Intel MPI:
Instalowanie języka dapl, rdmacm, ibverbs i mlx4
sudo apt-get update sudo apt-get install libdapl2 libmlx4-1W pliku /etc/waagent.conf włącz funkcję RDMA, usuwając komentarz z następujących wierszy konfiguracji. Aby edytować ten plik, musisz mieć dostęp do katalogu głównego.
OS.EnableRDMA=y OS.UpdateRdmaDriver=yDodaj lub zmień następujące ustawienia pamięci w kb w pliku /etc/security/limits.conf. Aby edytować ten plik, musisz mieć dostęp do katalogu głównego. W celach testowych można ustawić memlock na nieograniczone. Na przykład:
<User or group name> hard memlock unlimited.<User or group name> hard memlock <memory required for your application in KB> <User or group name> soft memlock <memory required for your application in KB>Zainstaluj bibliotekę Intel MPI. Kup i pobierz bibliotekę z firmy Intel lub pobierz bezpłatną wersję ewaluacyjną.
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgzObsługiwane są tylko środowiska uruchomieniowe Intel MPI 5.x.
Aby uzyskać instrukcje instalacji, zobacz Przewodnik instalacji biblioteki Intel MPI.
Włącz funkcję ptrace dla procesów innych niż debuger innych niż root (wymagane w przypadku najnowszych wersji programu Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
Na maszynie wirtualnej są zainstalowane sterowniki HPC oparte na systemie CentOS 7.4 — RDMA i Intel MPI 5.1.
HpC oparte na systemie CentOS — CentOS-HPC 7.6 lub nowszy (w przypadku jednostek SKU, w przypadku których rozwiązanie InfiniBand jest obsługiwane przez funkcję SR-IOV). Te obrazy mają wstępnie zainstalowane biblioteki Mellanox OFED i MPI.
Uwaga
Karty CX3-Pro są obsługiwane tylko w wersjach LTS mellanox OFED. Użyj wersji LTS Mellanox OFED (4.9-0.1.7.0) na maszynach wirtualnych serii N z kartami ConnectX3-Pro. Aby uzyskać więcej informacji, zobacz Sterowniki systemu Linux.
Ponadto niektóre z najnowszych obrazów HPC witryny Azure Marketplace mają mellanox OFED 5.1 i nowsze wersje, które nie obsługują kart ConnectX3-Pro. Sprawdź wersję Mellanox OFED na obrazie HPC przed użyciem jej na maszynach wirtualnych z kartami ConnectX3-Pro.
Poniższe obrazy to najnowsze obrazy CentOS-HPC obsługujące karty ConnectX3-Pro:
- OpenLogic:CentOS-HPC:7.6:7.6.2020062900
- OpenLogic:CentOS-HPC:7_6gen2:7.6.2020062901
- OpenLogic:CentOS-HPC:7.7.7.7.2020062600
- OpenLogic:CentOS-HPC:7_7-gen2:7.7.2020062601
- OpenLogic:CentOS-HPC:8_1:8.1.2020062400
- OpenLogic:CentOS-HPC:8_1-gen2:8.1.2020062401
Instalowanie sterowników GRID na maszynach wirtualnych serii NV lub NVv3
Aby zainstalować sterowniki NVIDIA GRID na maszynach wirtualnych serii NV lub NVv3, wykonaj połączenie SSH z każdą maszyną wirtualną i wykonaj kroki dystrybucji systemu Linux.
Ubuntu
Uruchom polecenie
lspci. Sprawdź, czy karta lub karty NVIDIA M60 są widoczne jako urządzenia PCI.Instalowanie aktualizacji.
sudo apt-get update sudo apt-get upgrade -y sudo apt-get dist-upgrade -y sudo apt-get install build-essential ubuntu-desktop -y sudo apt-get install linux-azure -yWyłącz sterownik jądra Nouveau, który jest niezgodny ze sterownikiem NVIDIA. (Używaj tylko sterownika NVIDIA na maszynach wirtualnych NV lub NVv2). Aby wyłączyć sterownik, utwórz plik o
/etc/modprobe.dnazwie o następującejnouveau.confzawartości:blacklist nouveau blacklist lbm-nouveauUruchom ponownie maszynę wirtualną i ponownie nawiąz połączenie. Zamknij serwer X:
sudo systemctl stop lightdm.servicePobierz i zainstaluj sterownik GRID:
wget -O NVIDIA-Linux-x86_64-grid.run https://go.microsoft.com/fwlink/?linkid=874272 chmod +x NVIDIA-Linux-x86_64-grid.run sudo ./NVIDIA-Linux-x86_64-grid.runPo wyświetleniu monitu o uruchomienie narzędzia nvidia-xconfig w celu zaktualizowania pliku konfiguracji X wybierz pozycję Tak.
Po zakończeniu instalacji skopiuj plik /etc/nvidia/gridd.conf.template do nowego pliku gridd.conf w lokalizacji /etc/nvidia/
sudo cp /etc/nvidia/gridd.conf.template /etc/nvidia/gridd.confDodaj następujące polecenie do
/etc/nvidia/gridd.conf:IgnoreSP=FALSE EnableUI=FALSEUsuń następujące elementy z
/etc/nvidia/gridd.confnastępujących elementów, jeśli są obecne:FeatureType=0Uruchom ponownie maszynę wirtualną i przejdź do weryfikacji instalacji.
Instalowanie sterownika GRID w systemie Ubuntu z włączonym bezpiecznym rozruchem
Proces instalacji sterownika GRID nie oferuje żadnych opcji pomijania kompilacji i instalacji modułu jądra i wybierania innego źródła podpisanych modułów jądra, dlatego bezpieczny rozruch musi być wyłączony na maszynach wirtualnych z systemem Linux w celu ich używania z usługą GRID po zainstalowaniu podpisanych modułów jądra.
CentOS lub Red Hat Enterprise Linux
Zaktualizuj jądro i DKMS (zalecane). Jeśli zdecydujesz się nie aktualizować jądra, upewnij się, że wersje
kernel-develidkmssą odpowiednie dla jądra.sudo yum update sudo yum install kernel-devel sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm sudo yum install dkms sudo yum install hyperv-daemonsWyłącz sterownik jądra Nouveau, który jest niezgodny ze sterownikiem NVIDIA. (Używaj tylko sterownika NVIDIA na maszynach wirtualnych NV lub NV3). W tym celu utwórz plik o
/etc/modprobe.dnazwie onouveau.confnastępującej zawartości:blacklist nouveau blacklist lbm-nouveauUruchom ponownie maszynę wirtualną, ponownie połącz się i zainstaluj najnowsze usługi integracji z systemem Linux dla funkcji Hyper-V i platformy Azure. Sprawdź, czy lis jest wymagany, weryfikując wyniki lspci. Jeśli wszystkie urządzenia z procesorem GPU są wyświetlane zgodnie z oczekiwaniami, instalowanie lis nie jest wymagane.
Pomiń ten krok, jeśli planujesz używać systemu CentOS/RHEL 7.8 (lub nowszych wersji), ponieważ lis nie jest już wymagany dla tych wersji.
wget https://aka.ms/lis tar xvzf lis cd LISISO sudo ./install.sh sudo rebootPołącz się ponownie z maszyną wirtualną
lspcii uruchom polecenie . Sprawdź, czy karta lub karty NVIDIA M60 są widoczne jako urządzenia PCI.Pobierz i zainstaluj sterownik GRID:
wget -O NVIDIA-Linux-x86_64-grid.run https://go.microsoft.com/fwlink/?linkid=874272 chmod +x NVIDIA-Linux-x86_64-grid.run sudo ./NVIDIA-Linux-x86_64-grid.runPo wyświetleniu monitu o uruchomienie narzędzia nvidia-xconfig w celu zaktualizowania pliku konfiguracji X wybierz pozycję Tak.
Po zakończeniu instalacji skopiuj plik /etc/nvidia/gridd.conf.template do nowego pliku gridd.conf w lokalizacji /etc/nvidia/
sudo cp /etc/nvidia/gridd.conf.template /etc/nvidia/gridd.confDodaj dwa wiersze do :
/etc/nvidia/gridd.confIgnoreSP=FALSE EnableUI=FALSEUsuń jeden wiersz z
/etc/nvidia/gridd.conf, jeśli jest obecny:FeatureType=0Uruchom ponownie maszynę wirtualną i przejdź do weryfikacji instalacji.
Weryfikowanie instalacji sterownika
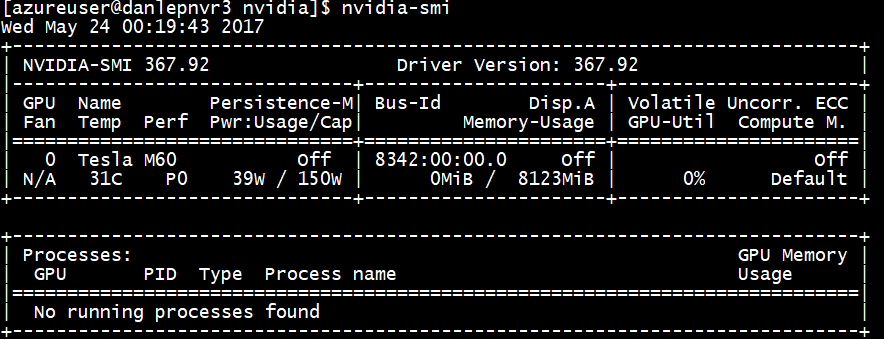
Aby wykonać zapytanie dotyczące stanu urządzenia z procesorem GPU, na maszynie wirtualnej należy uruchomić połączenie SSH i uruchomić narzędzie wiersza polecenia nvidia-smi zainstalowane ze sterownikiem.
Jeśli sterownik jest zainstalowany, narzędzie Nvidia SMI wyświetli narzędzie GPU-Util jako 0% do momentu uruchomienia obciążenia procesora GPU na maszynie wirtualnej. Wersja sterownika i szczegóły procesora GPU mogą różnić się od wyświetlanych.
Serwer X11
Jeśli potrzebujesz serwera X11 do połączeń zdalnych z maszyną wirtualną NV lub NVv2, zalecane jest x11vnc, ponieważ umożliwia przyspieszanie sprzętowe grafiki. Identyfikator BusID urządzenia M60 należy ręcznie dodać do pliku konfiguracji X11 (zazwyczaj etc/X11/xorg.conf). Dodaj sekcję podobną "Device" do następującej:
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BoardName "Tesla M60"
BusID "PCI:0@your-BusID:0:0"
EndSection
Ponadto zaktualizuj sekcję "Screen" , aby korzystać z tego urządzenia.
Identyfikator BusID dziesiętny można znaleźć, uruchamiając polecenie
nvidia-xconfig --query-gpu-info | awk '/PCI BusID/{print $4}'
Identyfikator BusID może ulec zmianie po ponownym przydzieleniu lub ponownym uruchomieniu maszyny wirtualnej. W związku z tym możesz utworzyć skrypt w celu zaktualizowania identyfikatora BusID w konfiguracji X11 po ponownym uruchomieniu maszyny wirtualnej. Na przykład utwórz skrypt o nazwie busidupdate.sh (lub innej wybranej nazwie) z zawartością podobną do następującej:
#!/bin/bash
XCONFIG="/etc/X11/xorg.conf"
OLDBUSID=`awk '/BusID/{gsub(/"/, "", $2); print $2}' ${XCONFIG}`
NEWBUSID=`nvidia-xconfig --query-gpu-info | awk '/PCI BusID/{print $4}'`
if [[ "${OLDBUSID}" == "${NEWBUSID}" ]] ; then
echo "NVIDIA BUSID not changed - nothing to do"
else
echo "NVIDIA BUSID changed from \"${OLDBUSID}\" to \"${NEWBUSID}\": Updating ${XCONFIG}"
sed -e 's|BusID.*|BusID '\"${NEWBUSID}\"'|' -i ${XCONFIG}
fi
Następnie utwórz wpis dla skryptu aktualizacji w /etc/rc.d/rc3.d pliku , aby skrypt był wywoływany jako katalog główny podczas rozruchu.
Rozwiązywanie problemów
- Możesz ustawić tryb trwałości przy użyciu
nvidia-smipolecenia, aby dane wyjściowe polecenia było szybsze, gdy trzeba wykonywać zapytania o karty. Aby ustawić tryb trwałości, wykonaj polecenienvidia-smi -pm 1. Należy pamiętać, że jeśli maszyna wirtualna zostanie ponownie uruchomiona, ustawienie trybu zniknie. Zawsze można wykonać skrypt ustawienia trybu podczas uruchamiania. - Jeśli sterowniki NVIDIA CUDA zostały zaktualizowane do najnowszej wersji i okaże się, że łączność RDMA nie działa, zainstaluj ponownie sterowniki RDMA, aby ponownie opublikować tę łączność.
- Podczas instalacji lis, jeśli określona wersja systemu operacyjnego CentOS/RHEL (lub jądro) nie jest obsługiwana dla LIS, zgłaszany jest błąd "Nieobsługiwana wersja jądra". Zgłoś ten błąd wraz z wersjami systemu operacyjnego i jądra.
- Jeśli zadania są przerywane przez błędy ECC na procesorze GPU (poprawialne lub niekorzystywalne), najpierw sprawdź, czy procesor GPU spełnia jakiekolwiek kryteria RMA firmy Nvidia pod kątem błędów ECC. Jeśli procesor GPU kwalifikuje się do RMA, skontaktuj się z pomocą techniczną dotyczącą jego obsługi; w przeciwnym razie uruchom ponownie maszynę wirtualną, aby ponownie dołączyć procesor GPU zgodnie z opisem w tym miejscu. Mniej inwazyjne metody, takie jak
nvidia-smi -rnie działają z rozwiązaniem wirtualizacji wdrożonym na platformie Azure.
Następne kroki
- Aby przechwycić obraz maszyny wirtualnej z systemem Linux za pomocą zainstalowanych sterowników NVIDIA, zobacz Jak uogólnić i przechwycić maszynę wirtualną z systemem Linux.