Dostrajanie wydajności za pomocą zmaterializowanych widoków przy użyciu dedykowanej puli SQL w usłudze Azure Synapse Analytics
W dedykowanej puli SQL zmaterializowane widoki zapewniają niską metodę konserwacji złożonych zapytań analitycznych w celu uzyskania szybkiej wydajności bez żadnych zmian zapytań. W tym artykule omówiono ogólne wskazówki dotyczące używania zmaterializowanych widoków.
Zmaterializowane widoki a widoki standardowe
Pula SQL obsługuje widoki standardowe i zmaterializowane. Obie są tabelami wirtualnymi utworzonymi za pomocą wyrażeń SELECT i przedstawianymi zapytaniami jako tabelami logicznymi. Widoki ujawniają złożoność typowych obliczeń danych i dodają warstwę abstrakcji do zmian obliczeniowych, dzięki czemu nie ma potrzeby ponownego pisania zapytań.
Widok standardowy oblicza swoje dane za każdym razem, gdy widok jest używany. Na dysku nie są przechowywane żadne dane. Osoby zazwyczaj używa standardowych widoków jako narzędzia, które ułatwia organizowanie obiektów logicznych i zapytań w bazie danych. Aby użyć widoku standardowego, zapytanie musi odwoływać się bezpośrednio do niego.
Zmaterializowany widok wstępnie oblicza, przechowuje i utrzymuje swoje dane w dedykowanej puli SQL tak samo jak tabela. Ponowne obliczanie nie jest wymagane za każdym razem, gdy jest używany zmaterializowany widok. Dlatego zapytania używające wszystkich lub podzestawu danych w zmaterializowanych widokach mogą szybciej zwiększyć wydajność. Jeszcze lepiej, zapytania mogą używać zmaterializowanego widoku bez bezpośredniego odwoływanie się do niego, więc nie trzeba zmieniać kodu aplikacji.
Większość wymagań dotyczących widoku standardowego nadal ma zastosowanie do zmaterializowanego widoku. Aby uzyskać szczegółowe informacje na temat zmaterializowanej składni widoku i innych wymagań, zobacz CREATE MATERIALIZED VIEW AS SELECT (TWORZENIE ZMATERIALIZOWANEGO WIDOKU JAKO SELECT).
| Porównanie | Widok | Zmaterializowany widok |
|---|---|---|
| Definicja widoku | Przechowywane w usłudze Azure Data Warehouse. | Przechowywane w usłudze Azure Data Warehouse. |
| Wyświetlanie zawartości | Generowane za każdym razem, gdy widok jest używany. | Wstępnie przetworzone i przechowywane w magazynie danych platformy Azure podczas tworzenia widoku. Zaktualizowano dane w miarę dodawania danych do bazowych tabel. |
| Odświeżanie danych | Zawsze aktualizowane | Zawsze aktualizowane |
| Szybkość pobierania danych widoku ze złożonych zapytań | Mała | Duża |
| Dodatkowy magazyn | Nie | Tak |
| Składnia | CREATE VIEW | UTWÓRZ ZMATERIALIZOWANY WIDOK JAKO WYBIERZ |
Zalety zmaterializowanych widoków
Prawidłowo zaprojektowany zmaterializowany widok zapewnia następujące korzyści:
Skrócony czas wykonywania złożonych zapytań przy użyciu JDN i funkcji agregujących. Im bardziej złożone zapytanie, tym większa jest możliwość oszczędzania czasu wykonywania. Największą korzyścią jest korzyść, gdy koszt obliczeń zapytania jest wysoki, a wynikowy zestaw danych jest niewielki.
Optymalizator zapytań w dedykowanej puli SQL może automatycznie używać wdrożonych zmaterializowanych widoków w celu ulepszenia planów wykonywania zapytań. Ten proces jest niewidoczny dla użytkowników, zapewniając szybszą wydajność zapytań i nie wymaga od zapytań bezpośredniego odwoływanie się do zmaterializowanych widoków.
Wymaga niskiej konserwacji widoków. Zmaterializowany widok przechowuje dane w dwóch miejscach, indeks klastrowanego magazynu kolumn dla danych początkowych w czasie tworzenia widoku oraz magazyn różnicowy zmian danych przyrostowych. Wszystkie zmiany danych z tabel podstawowych są automatycznie dodawane do magazynu różnicowego w sposób synchroniczny. Proces w tle (krotka mover) okresowo przenosi dane z magazynu różnicowego do indeksu magazynu kolumn widoku. Ten projekt umożliwia wykonywanie zapytań dotyczących zmaterializowanych widoków w celu zwrócenia tych samych danych co bezpośrednie wykonywanie zapytań względem tabel podstawowych.
Dane w zmaterializowanym widoku mogą być dystrybuowane inaczej niż w tabelach podstawowych.
Dane w zmaterializowanych widokach mają takie same korzyści z wysokiej dostępności i odporności, jak dane w zwykłych tabelach.
W porównaniu z innymi dostawcami magazynu danych zmaterializowane widoki zaimplementowane w dedykowanej puli SQL zapewniają również następujące dodatkowe korzyści:
- Automatyczne i synchroniczne odświeżanie danych ze zmianami danych w tabelach podstawowych. Nie jest wymagana żadna akcja ze strony użytkownika.
- Obsługa szerokiej funkcji agregującej. Zobacz CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL) (CREATE MATERIALIZED VIEW AS SELECT (Transact-SQL) (TWORZENIE ZMATERIALIZOWANEGO WIDOKU JAKO SELECT (Transact-SQL).
- Obsługa rekomendacji widoku zmaterializowanego specyficznego dla zapytań. Zobacz EXPLAIN (Transact-SQL).
Typowe scenariusze
Zmaterializowane widoki są zwykle używane w następujących scenariuszach:
Konieczność zwiększenia wydajności złożonych zapytań analitycznych dotyczących dużych ilości danych
Złożone zapytania analityczne zwykle używają większej liczby funkcji agregacji i sprzężeń tabel, powodując większe obciążenie obliczeniowe operacje, takie jak tasowanie i sprzężenia w wykonywaniu zapytań. Dlatego wykonywanie zapytań trwa dłużej, szczególnie w przypadku dużych tabel.
Użytkownicy mogą tworzyć zmaterializowane widoki dla danych zwracanych na podstawie typowych obliczeń zapytań, więc nie jest wymagana ponowna kompilacja, gdy te dane są potrzebne przez zapytania, co pozwala na niższe koszty obliczeniowe i szybsze reagowanie na zapytania.
Potrzebna jest szybsza wydajność bez zmian zapytań lub minimalnych
Zmiany schematu i zapytań w magazynach danych są zwykle przechowywane do minimum, aby obsługiwać regularne operacje ETL i raportowanie. Osoby mogą używać zmaterializowanych widoków do dostrajania wydajności zapytań, jeśli koszt ponoszony przez widoki może zostać przesunięty przez wzrost wydajności zapytań.
W porównaniu z innymi opcjami dostrajania, takimi jak zarządzanie skalowaniem i statystykami, jest to znacznie mniej wpływowa zmiana produkcji w celu utworzenia i utrzymania zmaterializowanego widoku, a jego potencjalny wzrost wydajności jest również wyższy.
- Tworzenie lub utrzymywanie zmaterializowanych widoków nie ma wpływu na zapytania uruchomione względem tabel bazowych.
- Optymalizator zapytań może automatycznie używać wdrożonych zmaterializowanych widoków bez bezpośredniego odwołania do widoku w zapytaniu. Ta funkcja zmniejsza potrzebę zmiany zapytań w dostrajaniu wydajności.
Potrzebna jest inna strategia dystrybucji danych w celu zwiększenia wydajności zapytań
Usługa Azure Data Warehouse to rozproszony i masowo równoległy system przetwarzania (MPP).
Synapse SQL to rozproszony system zapytań, który umożliwia przedsiębiorstwom implementowanie scenariuszy magazynowania danych i wirtualizacji danych przy użyciu standardowych środowisk języka T-SQL znanych inżynierom danych. Rozszerza również możliwości języka SQL, aby rozwiązać problem ze scenariuszami przesyłania strumieniowego i uczenia maszynowego. Dane w tabeli magazynu danych są dystrybuowane między 60 węzłów przy użyciu jednej z trzech strategii dystrybucji (skrót, round_robin lub replikowane).
Rozkład danych jest określony w czasie tworzenia tabeli i pozostaje niezmieniony, dopóki tabela nie zostanie porzucona. Zmaterializowany widok jest tabelą wirtualną na dysku obsługuje dystrybucje skrótów i round_robin danych. Użytkownicy mogą wybrać dystrybucję danych, która różni się od tabel bazowych, ale optymalna dla wydajności zapytań, które często korzystają z widoków.
Wskazówki dotyczące projektowania
Poniżej przedstawiono ogólne wskazówki dotyczące używania zmaterializowanych widoków w celu zwiększenia wydajności zapytań:
Projektowanie pod kątem obciążenia
Przed rozpoczęciem tworzenia zmaterializowanych widoków ważne jest dokładne zrozumienie obciążenia pod względem wzorców zapytań, ważności, częstotliwości i rozmiaru danych wynikowych.
Użytkownicy mogą uruchamiać SQL_statement EXPLAIN WITH_RECOMMENDATIONS <> dla zmaterializowanych widoków zalecanych przez optymalizator zapytań. Ponieważ te zalecenia są specyficzne dla zapytań, zmaterializowany widok, który korzysta z pojedynczego zapytania, może nie być optymalny dla innych zapytań w tym samym obciążeniu.
Oceń te zalecenia z uwzględnieniem potrzeb związanych z obciążeniem. Idealne zmaterializowane widoki to te, które korzystają z wydajności obciążenia.
Należy pamiętać o kompromisie między szybszymi zapytaniami a kosztem
W przypadku każdego zmaterializowanego widoku istnieje koszt przechowywania danych i koszt utrzymania widoku. Wraz ze zmianą danych w tabelach podstawowych rozmiar zmaterializowanego widoku zwiększa się, a jego struktura fizyczna również się zmienia.
Aby uniknąć obniżenia wydajności zapytań, każdy zmaterializowany widok jest utrzymywany oddzielnie przez aparat magazynu danych, w tym przenoszenie wierszy z magazynu różnicowego do segmentów indeksów magazynu kolumn i konsolidowanie zmian danych.
Obciążenie konserwacji zwiększa się w przypadku zwiększenia liczby zmaterializowanych widoków i zmiany tabeli bazowej. Użytkownicy powinni sprawdzić, czy koszt ponoszony ze wszystkich zmaterializowanych widoków może zostać przesunięty przez wzrost wydajności zapytań.
To zapytanie można uruchomić dla listy zmaterializowanego widoku w bazie danych:
SELECT V.name as materialized_view, V.object_id
FROM sys.views V
JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;
Opcje zmniejszenia liczby zmaterializowanych widoków:
Identyfikowanie typowych zestawów danych często używanych przez złożone zapytania w obciążeniu. Utwórz zmaterializowane widoki do przechowywania tych zestawów danych, aby optymalizator mógł używać ich jako bloków konstrukcyjnych podczas tworzenia planów wykonania.
Upuść zmaterializowane widoki, które mają niskie użycie lub nie są już potrzebne. Wyłączony zmaterializowany widok nie jest utrzymywany, ale nadal wiąże się z kosztami magazynowania.
Połącz zmaterializowane widoki utworzone w tych samych lub podobnych tabelach podstawowych, nawet jeśli ich dane nie nakładają się na siebie. Połączenie zmaterializowanych widoków może spowodować większy rozmiar widoku niż suma oddzielnych widoków, jednak koszt konserwacji widoku powinien zostać zmniejszony. Na przykład:
-- Query 1 would benefit from having a materialized view created with this SELECT statement
SELECT A, SUM(B)
FROM T
GROUP BY A
-- Query 2 would benefit from having a materialized view created with this SELECT statement
SELECT C, SUM(D)
FROM T
GROUP BY C
-- You could create a single materialized view of this form
SELECT A, C, SUM(B), SUM(D)
FROM T
GROUP BY A, C
Nie wszystkie dostrajanie wydajności wymaga zmiany zapytania
Optymalizator magazynu danych może automatycznie używać wdrożonych zmaterializowanych widoków w celu zwiększenia wydajności zapytań. Ta obsługa jest stosowana w sposób niewidoczny dla zapytań, które nie odwołują się do widoków i do zapytań korzystających z agregacji nieobsługiwanych podczas tworzenia zmaterializowanych widoków. Nie jest wymagana żadna zmiana kwerendy. Możesz sprawdzić szacowany plan wykonania zapytania, aby potwierdzić, czy jest używany zmaterializowany widok.
- Aby uzyskać więcej informacji na temat pobierania rzeczywistego planu wykonania, zobacz Monitorowanie obciążenia dedykowanej puli SQL usługi Azure Synapse Analytics przy użyciu widoków DMV.
- Szacowany plan wykonania można pobrać za pomocą SQL Server Management Studio (SSMS) lub SET SHOWPLAN_XML.
Monitorowanie zmaterializowanych widoków
Zmaterializowany widok jest przechowywany w magazynie danych tak samo jak tabela z klastrowanym indeksem magazynu kolumn (CCI). Odczytywanie danych z zmaterializowanego widoku obejmuje skanowanie indeksu i stosowanie zmian z magazynu różnicowego. Jeśli liczba wierszy w magazynie delty jest zbyt duża, rozpoznawanie zapytania z zmaterializowanego widoku może trwać dłużej niż bezpośrednie wykonywanie zapytań względem tabel podstawowych.
Aby uniknąć obniżenia wydajności zapytań, dobrym rozwiązaniem jest uruchomienie PDW_SHOWMATERIALIZEDVIEWOVERHEAD DBCC w celu monitorowania overhead_ratio widoku (total_rows/base_view_row). Jeśli overhead_ratio jest zbyt wysoka, rozważ ponowne skompilowanie zmaterializowanego widoku, aby wszystkie wiersze w magazynie delty zostały przeniesione do indeksu magazynu kolumn.
Zmaterializowany widok i buforowanie zestawu wyników
Te dwie funkcje są wprowadzane w dedykowanej puli SQL w tym samym czasie na potrzeby dostrajania wydajności zapytań. Buforowanie zestawu wyników służy do osiągnięcia wysokiej współbieżności i szybkiego czasu odpowiedzi z powtarzających się zapytań dotyczących danych statycznych.
Aby użyć buforowanego wyniku, forma zapytania żądającego pamięci podręcznej musi być zgodna z zapytaniem, które wygenerowało pamięć podręczną. Ponadto buforowany wynik musi mieć zastosowanie do całego zapytania.
Zmaterializowane widoki umożliwiają zmiany danych w tabelach podstawowych. Dane w zmaterializowanych widokach można zastosować do fragmentu zapytania. Ta obsługa umożliwia korzystanie z tych samych zmaterializowanych widoków przez różne zapytania, które współdzielą niektóre obliczenia w celu zwiększenia wydajności.
Przykład
W tym przykładzie użyto zapytania przypominającego TPCDS, które znajduje klientów, którzy wydają więcej pieniędzy za pośrednictwem katalogu niż w sklepach. Identyfikuje również preferowanych klientów i ich kraj/region pochodzenia. Zapytanie obejmuje wybranie 100 pierwszych rekordów z unii trzech instrukcji sub-SELECT obejmujących SUM() i GROUP BY.
WITH year_total AS (
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
,'s' sale_type
FROM customer
,store_sales
,date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
,'c' sale_type
FROM customer
,catalog_sales
,date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
UNION ALL
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
,'w' sale_type
FROM customer
,web_sales
,date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
)
SELECT TOP 100
t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
FROM year_total t_s_firstyear
,year_total t_s_secyear
,year_total t_c_firstyear
,year_total t_c_secyear
,year_total t_w_firstyear
,year_total t_w_secyear
WHERE t_s_secyear.customer_id = t_s_firstyear.customer_id
AND t_s_firstyear.customer_id = t_c_secyear.customer_id
AND t_s_firstyear.customer_id = t_c_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_firstyear.customer_id
AND t_s_firstyear.customer_id = t_w_secyear.customer_id
AND t_s_firstyear.sale_type = 's'
AND t_c_firstyear.sale_type = 'c'
AND t_w_firstyear.sale_type = 'w'
AND t_s_secyear.sale_type = 's'
AND t_c_secyear.sale_type = 'c'
AND t_w_secyear.sale_type = 'w'
AND t_s_firstyear.dyear+0 = 1999
AND t_s_secyear.dyear+0 = 1999+1
AND t_c_firstyear.dyear+0 = 1999
AND t_c_secyear.dyear+0 = 1999+1
AND t_w_firstyear.dyear+0 = 1999
AND t_w_secyear.dyear+0 = 1999+1
AND t_s_firstyear.year_total > 0
AND t_c_firstyear.year_total > 0
AND t_w_firstyear.year_total > 0
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_s_firstyear.year_total > 0 THEN t_s_secyear.year_total / t_s_firstyear.year_total ELSE NULL END
AND CASE WHEN t_c_firstyear.year_total > 0 THEN t_c_secyear.year_total / t_c_firstyear.year_total ELSE NULL END
> CASE WHEN t_w_firstyear.year_total > 0 THEN t_w_secyear.year_total / t_w_firstyear.year_total ELSE NULL END
ORDER BY t_s_secyear.customer_id
,t_s_secyear.customer_first_name
,t_s_secyear.customer_last_name
,t_s_secyear.customer_birth_country
OPTION ( LABEL = 'Query04-af359846-253-3');
Sprawdź szacowany plan wykonania zapytania. Istnieje 18 operacji mieszania i 17 sprzężeń, co zajmuje więcej czasu na wykonanie.
Teraz utwórzmy jeden zmaterializowany widok dla każdej z trzech instrukcji sub-SELECT.
CREATE materialized view nbViewSS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ss_ext_list_price-ss_ext_wholesale_cost-ss_ext_discount_amt+ss_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.store_sales
,dbo.date_dim
WHERE c_customer_sk = ss_customer_sk
AND ss_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewCS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(cs_ext_list_price-cs_ext_wholesale_cost-cs_ext_discount_amt+cs_ext_sales_price, 0)/2) year_total
, count_big(*) as cb
FROM dbo.customer
,dbo.catalog_sales
,dbo.date_dim
WHERE c_customer_sk = cs_bill_customer_sk
AND cs_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
GO
CREATE materialized view nbViewWS WITH (DISTRIBUTION=HASH(customer_id)) AS
SELECT c_customer_id customer_id
,c_first_name customer_first_name
,c_last_name customer_last_name
,c_preferred_cust_flag customer_preferred_cust_flag
,c_birth_country customer_birth_country
,c_login customer_login
,c_email_address customer_email_address
,d_year dyear
,sum(isnull(ws_ext_list_price-ws_ext_wholesale_cost-ws_ext_discount_amt+ws_ext_sales_price, 0)/2) year_total
, count_big(*) AS cb
FROM dbo.customer
,dbo.web_sales
,dbo.date_dim
WHERE c_customer_sk = ws_bill_customer_sk
AND ws_sold_date_sk = d_date_sk
GROUP BY c_customer_id
,c_first_name
,c_last_name
,c_preferred_cust_flag
,c_birth_country
,c_login
,c_email_address
,d_year
Sprawdź ponownie plan wykonania oryginalnego zapytania. Teraz liczba sprzężeń zmienia się z 17 do 5 i nie ma już mieszania. Wybierz ikonę Operacja filtru w planie. Na liście danych wyjściowych dane są odczytywane z zmaterializowanych widoków zamiast tabel bazowych.
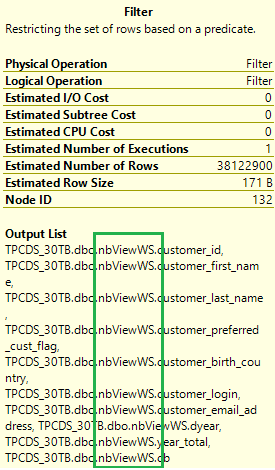
W przypadku zmaterializowanych widoków to samo zapytanie działa znacznie szybciej bez konieczności zmiany kodu.
Następne kroki
Aby uzyskać więcej porad dotyczących programowania, zobacz Omówienie programowania w usłudze Synapse SQL.