Optymalizowanie zadań platformy Apache Spark w usłudze Azure Synapse Analytics
Dowiedz się, jak zoptymalizować konfigurację klastra Apache Spark dla określonego obciążenia. Najczęstszym wyzwaniem jest wykorzystanie pamięci spowodowane niewłaściwą konfiguracją (zwłaszcza funkcji wykonawczych o nieprawidłowym rozmiarze), długotrwałymi operacjami i zadaniami, których wynikiem są działania kartezjańskie. Możesz przyspieszyć zadania przy użyciu odpowiedniego buforowania i umożliwiając niesymetryczność danych. Aby uzyskać najlepszą wydajność, monitoruj i przejrzyj długotrwałe i zużywające zasoby wykonania zadań platformy Spark.
W poniższych sekcjach opisano typowe optymalizacje i zalecenia dotyczące zadań platformy Spark.
Wybieranie abstrakcji danych
Starsze wersje platformy Spark używają rdD do abstrakcji danych, Spark 1.3 i 1.6, odpowiednio wprowadzonych ramek danych i zestawów danych. Rozważ następujące względne zalety:
- Ramki danych
- Najlepszy wybór w większości sytuacji.
- Zapewnia optymalizację zapytań za pośrednictwem katalizatora.
- Generowanie kodu pełnoetapowego.
- Bezpośredni dostęp do pamięci.
- Niskie obciążenie związane z odzyskiwaniem pamięci (GC).
- Nie tak przyjazne dla deweloperów, jak zestawy danych, ponieważ nie ma kontroli czasu kompilacji ani programowania obiektów domeny.
- Zestawach danych
- Dobre w złożonych potokach ETL, w których wpływ na wydajność jest akceptowalny.
- Nie jest to dobre w agregacjach, w których wpływ na wydajność może być znaczny.
- Zapewnia optymalizację zapytań za pośrednictwem katalizatora.
- Przyjazny dla deweloperów, zapewniając programowanie obiektów domeny i sprawdzanie czasu kompilacji.
- Dodaje obciążenie serializacji/deserializacji.
- Wysokie obciążenie GC.
- Przerywa generowanie kodu pełnoetapowego.
- RDD
- Nie trzeba używać RDD, chyba że trzeba utworzyć nowy niestandardowy RDD.
- Brak optymalizacji zapytań za pośrednictwem katalizatora.
- Brak generowania kodu pełnoetapowego.
- Wysokie obciążenie GC.
- Musi używać starszych interfejsów API platformy Spark 1.x.
Korzystanie z optymalnego formatu danych
Platforma Spark obsługuje wiele formatów, takich jak csv, json, xml, parquet, orc i avro. Platformę Spark można rozszerzyć, aby obsługiwać wiele innych formatów z zewnętrznymi źródłami danych — aby uzyskać więcej informacji, zobacz Pakiety platformy Apache Spark.
Najlepszym formatem wydajności jest parquet z kompresją snappy, która jest domyślna w spark 2.x. Parquet przechowuje dane w formacie kolumnowym i jest wysoce zoptymalizowany na platformie Spark. Ponadto, podczas gdy kompresja snappy może spowodować większe pliki niż kompresja gzip. Ze względu na podzielony charakter tych plików, będą one dekompresowane szybciej.
Korzystanie z pamięci podręcznej
Platforma Spark udostępnia własne natywne mechanizmy buforowania, które mogą być używane za pomocą różnych metod, takich jak .persist(), .cache()i CACHE TABLE. Ta natywna pamięć podręczna jest skuteczna w przypadku małych zestawów danych, a także w potokach ETL, w których należy buforować wyniki pośrednie. Jednak buforowanie natywne platformy Spark nie działa obecnie w przypadku partycjonowania, ponieważ buforowana tabela nie przechowuje danych partycjonowania.
Wydajne korzystanie z pamięci
Platforma Spark działa przez umieszczenie danych w pamięci, więc zarządzanie zasobami pamięci jest kluczowym aspektem optymalizacji wykonywania zadań platformy Spark. Istnieje kilka technik, które można zastosować, aby efektywnie używać pamięci klastra.
Preferuj mniejsze partycje danych i konto dla rozmiaru, typów i dystrybucji danych w strategii partycjonowania.
W usłudze Synapse Spark (środowisko uruchomieniowe 3.1 lub nowsze) serializacja danych Kryo jest domyślnie włączona serializacji danych Kryo.
Rozmiar buforu kryoserializer można dostosować przy użyciu konfiguracji platformy Spark na podstawie wymagań dotyczących obciążenia:
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")Monitorowanie i dostrajanie ustawień konfiguracji platformy Spark.
W dokumentacji struktura pamięci platformy Spark i niektóre parametry pamięci wykonawczej klucza są wyświetlane na następnej ilustracji.
Zagadnienia dotyczące pamięci platformy Spark
Platforma Apache Spark w usłudze Azure Synapse używa usługi YARN Apache Hadoop YARN, usługa YARN kontroluje maksymalną sumę pamięci używanej przez wszystkie kontenery w każdym węźle Spark. Na poniższym diagramie przedstawiono kluczowe obiekty i ich relacje.
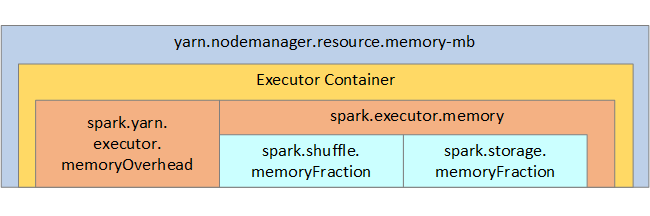
Aby rozwiązać problem z komunikatami braku pamięci, spróbuj:
- Przejrzyj shuffles zarządzania DAG. Zmniejsz liczbę danych źródłowych po stronie mapy, przed partycją (lub zasobnikami), zmaksymalizuj pojedyncze przetasowania i zmniejsz ilość wysyłanych danych.
- Preferuj
ReduceByKeyze stałym limitem pamięci doGroupByKey, który zapewnia agregacje, okna i inne funkcje, ale ma limit niezwiązanej pamięci. - Preferuj
TreeReduceelement , który wykonuje więcej pracy na funkcjach wykonawczych lub partycjach, doReduce, co wykonuje całą pracę na sterowniku. - Korzystaj z ramek danych, a nie obiektów RDD niższego poziomu.
- Utwórz typy złożone, które hermetyzują akcje, takie jak "Top N", różne agregacje lub operacje okien.
Optymalizowanie serializacji danych
Zadania platformy Spark są dystrybuowane, więc odpowiednia serializacji danych jest ważna dla najlepszej wydajności. Istnieją dwie opcje serializacji platformy Spark:
- Serializacja w języku Java
- Serializacja Kryo jest domyślna. Jest to nowszy format i może prowadzić do szybszej i bardziej kompaktowej serializacji niż Java. Kryo wymaga zarejestrowania klas w programie i nie obsługuje jeszcze wszystkich typów serializowalnych.
Korzystanie z zasobników
Zasobnik jest podobny do partycjonowania danych, ale każdy zasobnik może przechowywać zestaw wartości kolumn, a nie tylko jeden. Zasobnik działa dobrze w przypadku partycjonowania na dużych (w milionach lub więcej) liczb wartości, takich jak identyfikatory produktów. Zasobnik jest określany przez utworzenie skrótu klucza zasobnika wiersza. Tabele z zasobnikami oferują unikatowe optymalizacje, ponieważ przechowują metadane dotyczące sposobu ich zasobnika i sortowania.
Oto niektóre zaawansowane funkcje zasobnika:
- Optymalizacja zapytań oparta na zasobnikach metadanych.
- Zoptymalizowane agregacje.
- Zoptymalizowane sprzężenia.
W tym samym czasie można używać partycjonowania i zasobnika.
Optymalizowanie sprzężeń i odczytów losowych
Jeśli masz wolne zadania dotyczące sprzężenia lub mieszania, przyczyną jest prawdopodobnie niesymetryczność danych, która jest asymetrią w danych zadania. Na przykład zadanie mapy może potrwać 20 sekund, ale uruchomienie zadania, w którym dane są przyłączone lub przetasowane, trwa kilka godzin. Aby naprawić niesymetryczność danych, należy skonsolić cały klucz lub użyć izolowanej soli tylko dla niektórych podzestawów kluczy. Jeśli używasz izolowanej soli, należy dodatkowo filtrować, aby odizolować podzbiór kluczy solnych w sprzężeniach mapy. Inną opcją jest wprowadzenie kolumny zasobnika i wstępne agregowanie w zasobnikach.
Innym czynnikiem powodującym powolne sprzężenia może być typ sprzężenia. Domyślnie platforma Spark używa SortMerge typu sprzężenia. Ten typ sprzężenia najlepiej nadaje się do dużych zestawów danych, ale w przeciwnym razie jest kosztowny obliczeniowo, ponieważ musi najpierw posortować lewe i prawe strony danych przed ich scaleniem.
Sprzężenia Broadcast najlepiej nadaje się do mniejszych zestawów danych lub gdy jedna strona sprzężenia jest znacznie mniejsza niż po drugiej stronie. Ten typ sprzężenia emituje jedną stronę do wszystkich funkcji wykonawczych, dlatego wymaga więcej pamięci dla emisji w ogóle.
Typ sprzężenia można zmienić w konfiguracji, ustawiając spark.sql.autoBroadcastJoinThresholdwartość , lub możesz ustawić wskazówkę sprzężenia przy użyciu interfejsów API ramki danych (dataframe.join(broadcast(df2))).
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
Jeśli używasz tabel zasobnika, masz trzeci typ sprzężenia, sprzężenia Merge . Poprawnie podzielony na partycje i wstępnie posortowany zestaw danych pominą kosztowną fazę sortowania ze sprzężenia SortMerge .
Kolejność sprzężeń ma znaczenie, szczególnie w bardziej złożonych zapytaniach. Zacznij od najbardziej selektywnych sprzężeń. Ponadto sprzężenia przenoszenia zwiększają liczbę wierszy po agregacjach, gdy jest to możliwe.
Aby zarządzać równoległością sprzężeń kartezjańskich, możesz dodać zagnieżdżone struktury, okna i być może pominąć co najmniej jeden krok w zadaniu platformy Spark.
Wybieranie prawidłowego rozmiaru funkcji wykonawczej
Podczas podejmowania decyzji o konfiguracji funkcji wykonawczej należy wziąć pod uwagę obciążenie odzyskiwania pamięci w języku Java (GC).
Czynniki mające na celu zmniejszenie rozmiaru funkcji wykonawczej:
- Zmniejsz rozmiar sterty poniżej 32 GB, aby utrzymać obciążenie < GC 10%.
- Zmniejsz liczbę rdzeni, aby utrzymać obciążenie < GC 10%.
Czynniki zwiększające rozmiar funkcji wykonawczej:
- Zmniejszanie obciążenia związanego z komunikacją między funkcjami wykonawczych.
- Zmniejsz liczbę otwartych połączeń między funkcjami wykonawczych (N2) w większych klastrach (>100 funkcji wykonawczych).
- Zwiększ rozmiar sterty, aby obsłużyć zadania intensywnie korzystające z pamięci.
- Opcjonalnie: Zmniejsz obciążenie pamięci na funkcję wykonawcza.
- Opcjonalnie: Zwiększ wykorzystanie i współbieżność przez nadmierne subskrybowanie procesora CPU.
Ogólna zasada kciuka podczas wybierania rozmiaru funkcji wykonawczej:
- Zacznij od 30 GB na funkcję wykonawcza i rozpowszechnij dostępne rdzenie maszyny.
- Zwiększ liczbę rdzeni funkcji wykonawczej dla większych klastrów (> 100 funkcji wykonawczych).
- Zmodyfikuj rozmiar na podstawie przebiegów próbnych i na poprzednich czynnikach, takich jak obciążenie GC.
Podczas uruchamiania zapytań współbieżnych należy wziąć pod uwagę następujące kwestie:
- Zacznij od 30 GB na funkcję wykonawcza i wszystkich rdzeni komputera.
- Tworzenie wielu równoległych aplikacji Spark przez nadmierne subskrybowanie procesora CPU (około 30% poprawy opóźnienia).
- Dystrybuuj zapytania w aplikacjach równoległych.
- Zmodyfikuj rozmiar na podstawie przebiegów próbnych i na poprzednich czynnikach, takich jak obciążenie GC.
Monitoruj wydajność zapytań pod kątem wartości odstających lub innych problemów z wydajnością, przeglądając widok osi czasu, graf SQL, statystyki zadań itd. Czasami jedna lub kilka funkcji wykonawczych jest wolniejszych niż inne, a wykonywanie zadań trwa znacznie dłużej. Dzieje się to często w większych klastrach (> 30 węzłów). W takim przypadku podziel pracę na większą liczbę zadań, aby harmonogram mógł zrekompensować wolne zadania.
Na przykład liczba rdzeni funkcji wykonawczej w aplikacji ma co najmniej dwa razy więcej zadań. Można również włączyć spekulacyjne wykonywanie zadań za pomocą polecenia conf: spark.speculation = true.
Optymalizowanie wykonywania zadań
- Buforuj w razie potrzeby, na przykład jeśli używasz danych dwa razy, a następnie buforuj je.
- Rozgłasz zmienne do wszystkich funkcji wykonawczych. Zmienne są serializowane tylko raz, co powoduje szybsze wyszukiwanie.
- Użyj puli wątków w sterowniku, co skutkuje szybszą operacją dla wielu zadań.
Kluczową wartością wydajności zapytań platformy Spark 2.x jest aparat Tungsten, który zależy od generowania kodu pełnoetapowego. W niektórych przypadkach generowanie kodu pełnoetapowego może być wyłączone.
Jeśli na przykład w wyrażeniu SortAggregate agregacji zostanie użyty typ niezmienialny (string), pojawi się zamiast HashAggregate. Aby na przykład uzyskać lepszą wydajność, spróbuj wykonać następujące czynności, a następnie ponownie włączyć generowanie kodu:
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))