Zarządzanie bibliotekami pul platformy Apache Spark w usłudze Azure Synapse Analytics
Po zidentyfikowaniu pakietów Scala, Java, R (wersja zapoznawcza) lub Python, których chcesz użyć lub zaktualizować dla aplikacji Spark, możesz zainstalować lub usunąć je z puli spark. Biblioteki na poziomie puli są dostępne dla wszystkich notesów i zadań uruchomionych w puli.
Istnieją dwa podstawowe sposoby instalowania biblioteki w puli platformy Spark:
- Zainstaluj bibliotekę obszarów roboczych, która została przekazana jako pakiet obszaru roboczego.
- Aby zaktualizować biblioteki języka Python, podaj plik specyfikacji środowiska requirements.txt lub Conda environment.yml w celu zainstalowania pakietów z repozytoriów, takich jak PyPI lub Conda-Forge. Aby uzyskać więcej informacji, zobacz sekcję Formaty specyfikacji środowiska.
Po zapisaniu zmian zadanie platformy Spark uruchamia instalację i buforuje wynikowe środowisko w celu późniejszego ponownego użycia. Po zakończeniu zadania nowe zadania platformy Spark lub sesje notesu używają zaktualizowanych bibliotek puli.
Ważne
- Jeśli instalowany pakiet jest duży lub trwa długo, czas uruchamiania wystąpienia platformy Spark ma wpływ na czas uruchamiania.
- Zmiana wersji PySpark, Python, Scala/Java, .NET, R lub Spark nie jest obsługiwana.
- Instalowanie pakietów z zewnętrznych repozytoriów, takich jak PyPI, Conda-Forge, lub domyślne kanały Conda nie są obsługiwane w obszarach roboczych z włączoną ochroną eksfiltracji danych.
Zarządzanie pakietami z programu Synapse Studio lub witryny Azure Portal
Biblioteki puli platformy Spark można zarządzać za pomocą programu Synapse Studio lub witryny Azure Portal.
W witrynie Azure Portal przejdź do obszaru roboczego usługi Azure Synapse Analytics.
W sekcji Pule analizy wybierz kartę Pule platformy Apache Spark i wybierz pulę Spark z listy.
Wybierz pozycję Pakiety w sekcji Ustawienia puli Spark.
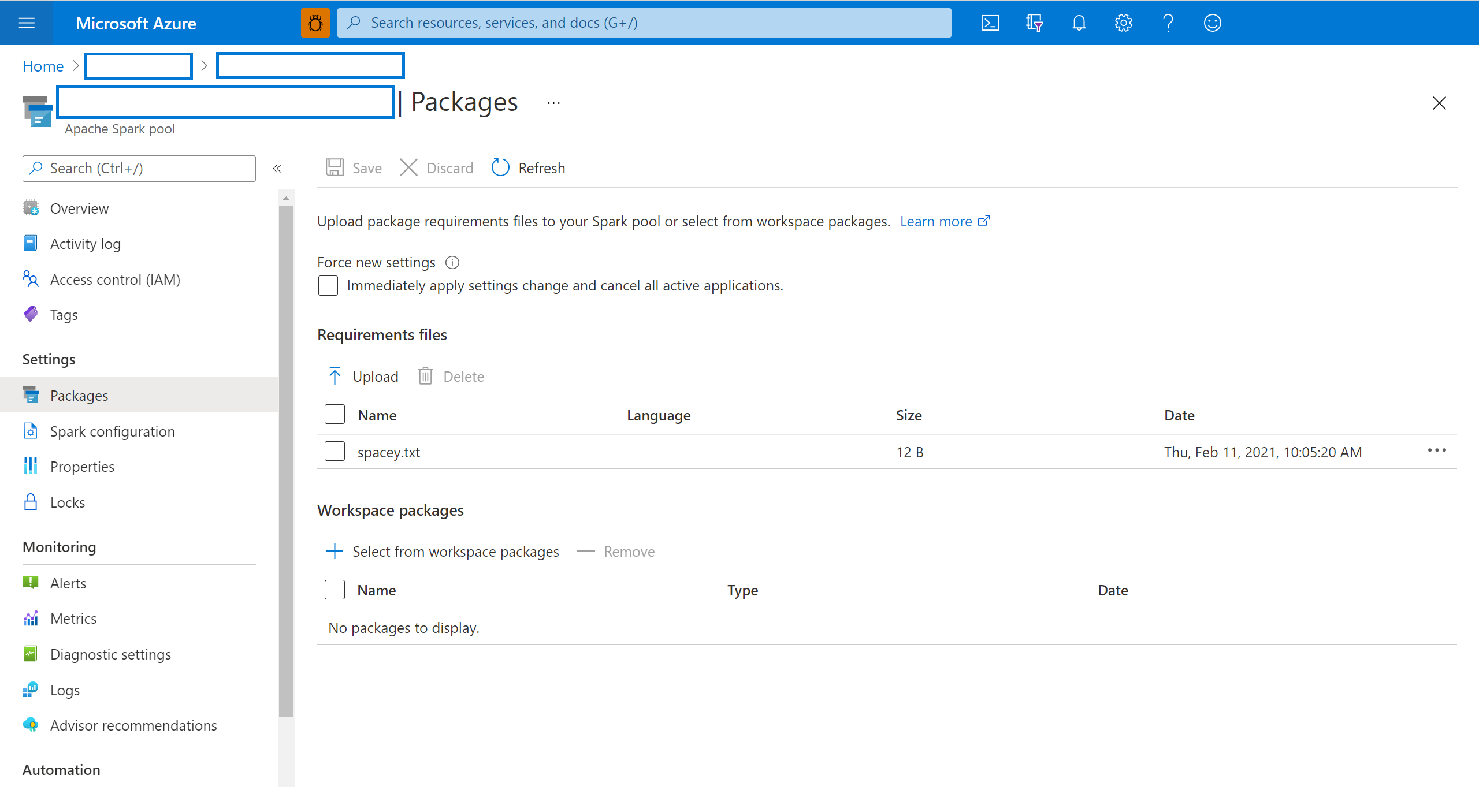
W przypadku bibliotek kanału informacyjnego języka Python przekaż plik konfiguracji środowiska przy użyciu selektora plików w sekcji Pakiety strony.
Możesz również wybrać dodatkowe pakiety obszarów roboczych, aby dodać pliki Jar, Wheel lub Tar.gz do puli.
Możesz również usunąć przestarzałe pakiety z sekcji Pakiety obszaru roboczego, a pula nie dołącza już tych pakietów.
Po zapisaniu zmian zadanie systemowe zostanie wyzwolone w celu zainstalowania i buforowania określonych bibliotek. Ten proces pomaga skrócić ogólny czas uruchamiania sesji.
Po pomyślnym zakończeniu zadania wszystkie nowe sesje pobierają zaktualizowane biblioteki puli.


Ważne
Wybierając opcję Wymuś nowe ustawienia, kończysz wszystkie bieżące sesje dla wybranej puli Spark. Po zakończeniu sesji należy poczekać na ponowne uruchomienie puli.
Jeśli to ustawienie jest niezaznaczone, musisz poczekać na zakończenie bieżącej sesji platformy Spark lub zatrzymać ją ręcznie. Po zakończeniu sesji należy zezwolić na ponowne uruchomienie puli.
Śledzenie postępu instalacji
Zadanie platformy Spark zarezerwowane przez system jest inicjowane za każdym razem, gdy pula jest aktualizowana przy użyciu nowego zestawu bibliotek. To zadanie platformy Spark pomaga monitorować stan instalacji bibliotek. Jeśli instalacja nie powiedzie się z powodu konfliktów bibliotek lub innych problemów, pula Spark zostanie przywrócona do poprzedniego lub domyślnego stanu.
Ponadto użytkownicy mogą sprawdzać dzienniki instalacji, aby zidentyfikować konflikty zależności lub sprawdzić, które biblioteki zostały zainstalowane podczas aktualizacji puli.
Aby wyświetlić te dzienniki:
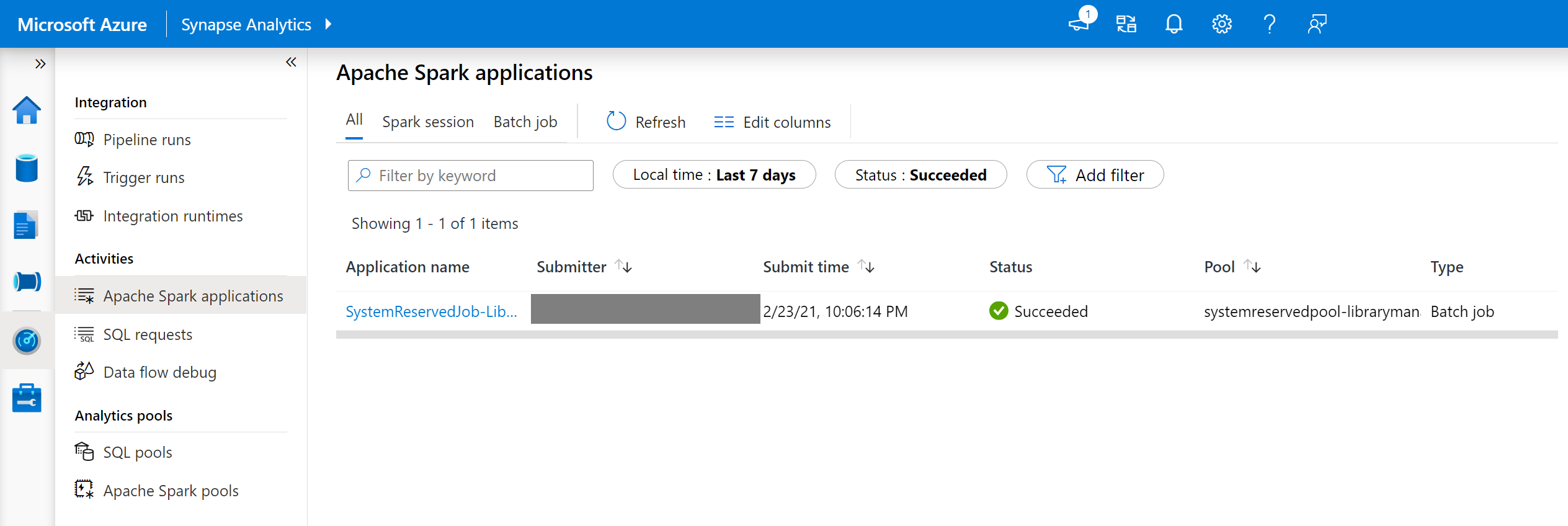
W programie Synapse Studio przejdź do listy aplikacji platformy Spark na karcie Monitorowanie .
Wybierz zadanie aplikacji platformy Spark systemu odpowiadające aktualizacji puli. Te zadania systemowe są uruchamiane jako SystemReservedJob-LibraryManagement.
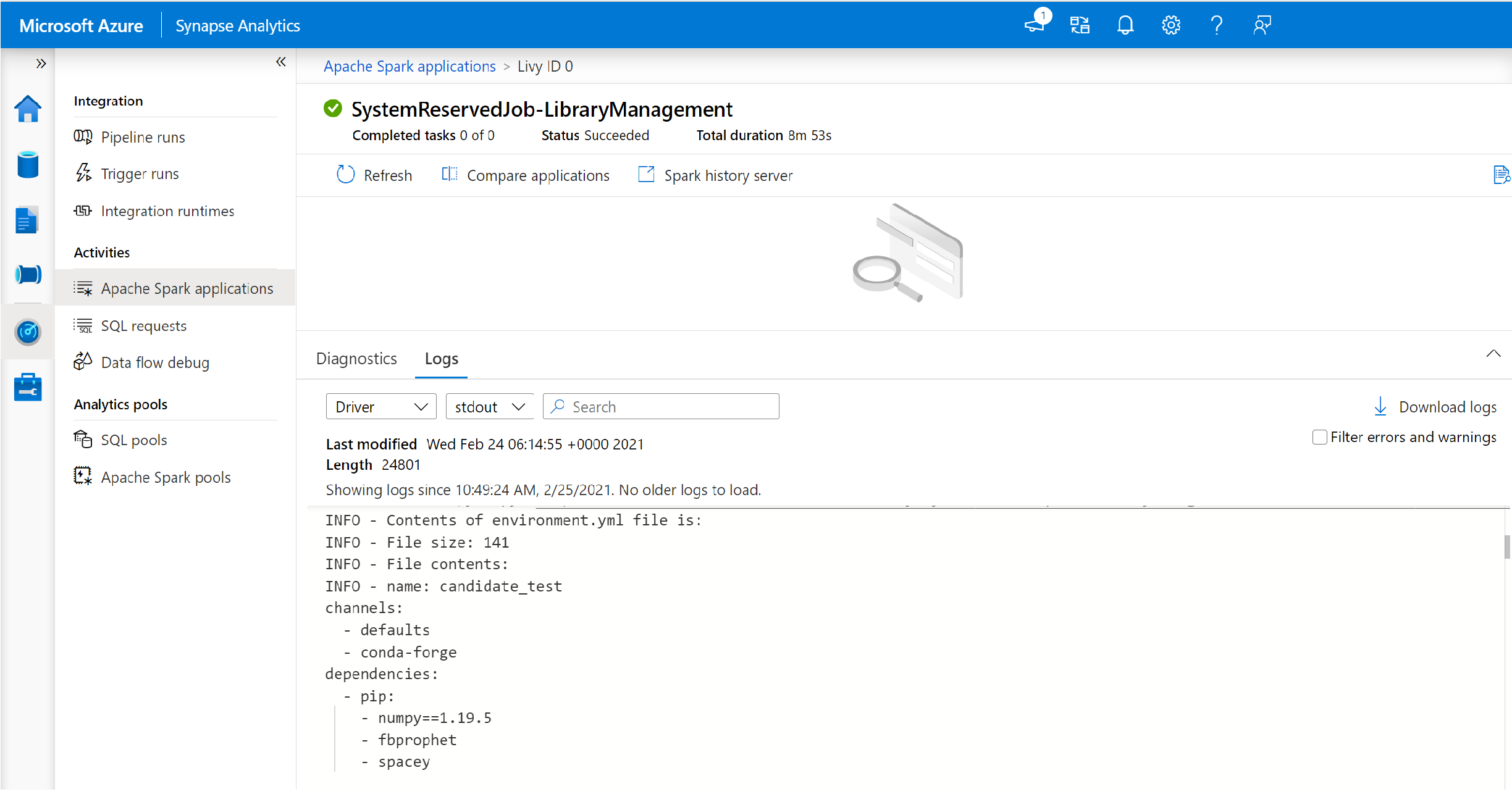
Przełącz się, aby wyświetlić dzienniki strumieni sterownika i stdout.
Wyniki zawierają dzienniki związane z instalacją zależności.


Formaty specyfikacji środowiska
requirements.txt
Plik requirements.txt (dane wyjściowe polecenia pip freeze ) może służyć do uaktualniania środowiska. Po zaktualizowaniu puli pakiety wymienione w tym pliku są pobierane z PyPI. Pełne zależności są następnie buforowane i zapisywane w celu późniejszego ponownego użycia puli.
Poniższy fragment kodu przedstawia format pliku wymagań. Nazwa pakietu PyPI jest wyświetlana wraz z dokładną wersją. Ten plik jest zgodny z formatem opisanym w dokumentacji dotyczącej blokowania potoku.
W tym przykładzie przypięta jest określona wersja.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
Format YML
Ponadto można podać plik environment.yml w celu zaktualizowania środowiska puli. Pakiety wymienione w tym pliku są pobierane z domyślnych kanałów Conda, Conda-Forge i PyPI. Możesz określić inne kanały lub usunąć kanały domyślne przy użyciu opcji konfiguracji.
W tym przykładzie określono kanały i zależności Conda/PyPI.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
Aby uzyskać szczegółowe informacje na temat tworzenia środowiska na podstawie tego pliku environment.yml , zobacz Aktywowanie środowiska.