Samouczek: trenowanie modelu w języku Python przy użyciu zautomatyzowanego uczenia maszynowego (przestarzałe)
Azure Machine Learning to oparte na chmurze środowisko, które umożliwia trenowanie, wdrażanie, automatyzowanie i śledzenie modeli uczenia maszynowego oraz zarządzanie nimi.
W tym samouczku użyjesz zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning, aby utworzyć model regresji w celu przewidywania cen opłat za taksówkę. Ten proces dociera do najlepszego modelu, akceptując dane treningowe i ustawienia konfiguracji oraz automatycznie iterując za pomocą kombinacji różnych metod, modeli i ustawień hiperparametrów.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Pobierz dane przy użyciu platformy Apache Spark i zestawów danych Platformy Azure Open.
- Przekształcanie i czyszczenie danych przy użyciu ramek danych platformy Apache Spark.
- Trenowanie modelu regresji w zautomatyzowanym uczeniu maszynowym.
- Obliczanie dokładności modelu.
Zanim rozpoczniesz
- Utwórz bezserwerową pulę platformy Apache Spark 2.4, korzystając z przewodnika Szybki start Tworzenie bezserwerowej puli platformy Apache Spark.
- Ukończ samouczek konfigurowania obszaru roboczego usługi Azure Machine Learning, jeśli nie masz istniejącego obszaru roboczego usługi Azure Machine Learning.
Ostrzeżenie
- Od 29 września 2023 r. usługa Azure Synapse przestanie obsługiwać oficjalne środowiska uruchomieniowe platformy Spark 2.4. Po 29 września 2023 r. nie będziemy zwracać się do żadnych biletów pomocy technicznej związanych z platformą Spark 2.4. W przypadku usterek lub poprawek zabezpieczeń platformy Spark 2.4 nie będzie dostępny potok wydania. Użycie platformy Spark 2.4 po dacie redukcji pomocy technicznej jest podejmowane na własne ryzyko. Zdecydowanie odradzamy jego dalsze wykorzystanie ze względu na potencjalne obawy dotyczące zabezpieczeń i funkcjonalności.
- W ramach procesu wycofywania dla platformy Apache Spark 2.4 chcemy powiadomić Cię, że rozwiązanie AutoML w usłudze Azure Synapse Analytics również będzie przestarzałe. Obejmuje to zarówno interfejs niskiego kodu, jak i interfejsy API używane do tworzenia wersji próbnych rozwiązania AutoML za pomocą kodu.
- Należy pamiętać, że funkcje rozwiązania AutoML były dostępne wyłącznie za pośrednictwem środowiska uruchomieniowego platformy Spark 2.4.
- W przypadku klientów, którzy chcą nadal korzystać z funkcji automatycznego uczenia maszynowego, zalecamy zapisanie danych na koncie usługi Azure Data Lake Storage Gen2 (ADLSg2). Z tego miejsca możesz bezproblemowo uzyskać dostęp do środowiska automatycznego uczenia maszynowego za pośrednictwem usługi Azure Machine Learning (AzureML). Więcej informacji na temat tego obejścia jest dostępne tutaj.
Omówienie modeli regresji
Modele regresji przewidują wartości liczbowe danych wyjściowych na podstawie niezależnych predyktorów. W regresji celem jest pomoc w ustanowieniu relacji między tymi niezależnymi zmiennymi prognostykującymi, szacując, jak jedna zmienna wpływa na inne.
Przykład oparty na danych dotyczących taksówek w Nowym Jorku
W tym przykładzie użyjesz platformy Spark do przeprowadzenia analizy danych porad dotyczących przejazdu taksówką z Nowego Jorku (NYC). Dane są dostępne za pośrednictwem usługi Azure Open Datasets. Ten podzestaw zestawu danych zawiera informacje o żółtych przejazdach taksówką, w tym informacje o każdej podróży, godzinie rozpoczęcia i zakończenia oraz lokalizacjach oraz kosztach.
Ważne
Mogą istnieć dodatkowe opłaty za ściąganie tych danych z lokalizacji przechowywania. W poniższych krokach utworzysz model, aby przewidzieć ceny taryf taksówek w Nowym Jorku.
Pobieranie i przygotowywanie danych
Oto, jak to zrobić:
Utwórz notes przy użyciu jądra PySpark. Aby uzyskać instrukcje, zobacz Tworzenie notesu.
Uwaga
Ze względu na jądro PySpark nie trzeba jawnie tworzyć żadnych kontekstów. Kontekst platformy Spark jest automatycznie tworzony podczas uruchamiania pierwszej komórki kodu.
Ponieważ dane pierwotne są w formacie Parquet, możesz użyć kontekstu platformy Spark, aby ściągnąć plik bezpośrednio do pamięci jako ramkę danych. Utwórz ramkę danych platformy Spark, pobierając dane za pośrednictwem interfejsu API Open Datasets. W tym miejscu użyjesz właściwości ramki
schema on readdanych platformy Spark, aby wywnioskować typy danych i schemat.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)W zależności od rozmiaru puli Platformy Spark nieprzetworzone dane mogą być zbyt duże lub zbyt dużo czasu na działanie. Możesz filtrować te dane w dół do czegoś mniejszego, takiego jak miesiąc danych, przy użyciu
start_datefiltrów iend_date. Po przefiltraniu ramki danych można również uruchomićdescribe()funkcję w nowej ramce danych, aby wyświetlić statystyki podsumowania dla każdego pola.Na podstawie statystyk podsumowania widać, że istnieją pewne nieprawidłowości w danych. Na przykład statystyki pokazują, że minimalna odległość podróży jest mniejsza niż 0. Należy odfiltrować te nieregularne punkty danych.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()Wygeneruj funkcje z zestawu danych, wybierając zestaw kolumn i tworząc różne funkcje oparte na czasie z pola odbioru
datetime. Odfiltruj wartości odstające, które zostały zidentyfikowane w poprzednim kroku, a następnie usuń kilka ostatnich kolumn, ponieważ nie są one potrzebne do trenowania.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)Jak widać, spowoduje to utworzenie nowej ramki danych z dodatkowymi kolumnami dla dnia miesiąca, godziny odbioru, dnia tygodnia i łącznego czasu podróży.

Generowanie zestawów danych testów i walidacji
Po zakończeniu zestawu danych można podzielić dane na zestawy treningowe i testowe przy użyciu random_ split funkcji na platformie Spark. Korzystając z podanych wag, ta funkcja losowo dzieli dane na zestaw danych trenowania na potrzeby trenowania modelu i zestawu danych weryfikacji na potrzeby testowania.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
Ten krok gwarantuje, że punkty danych do przetestowania ukończonego modelu nie zostały użyte do wytrenowania modelu.
Nawiązywanie połączenia z obszarem roboczym usługi Azure Machine Learning
W usłudze Azure Machine Learning obszar roboczy to klasa, która akceptuje informacje o subskrypcji i zasobach platformy Azure. Tworzy ona również zasób w chmurze służący do monitorowania i śledzenia przebiegów modelu. W tym kroku utworzysz obiekt obszaru roboczego z istniejącego obszaru roboczego usługi Azure Machine Learning.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
Konwertowanie ramki danych na zestaw danych usługi Azure Machine Learning
Aby przesłać eksperyment zdalny, przekonwertuj zestaw danych na wystąpienie usługi Azure Machine Learning TabularDatset . Tabelaryczny zestaw danych reprezentuje dane w formacie tabelarycznym przez analizowanie podanych plików.
Poniższy kod pobiera istniejący obszar roboczy i domyślny magazyn danych usługi Azure Machine Learning. Następnie przekazuje magazyn danych i lokalizacje plików do parametru path w celu utworzenia nowego TabularDataset wystąpienia.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

Przesyłanie eksperymentu zautomatyzowanego
W poniższych sekcjach przedstawiono proces przesyłania eksperymentu zautomatyzowanego uczenia maszynowego.
Definiowanie ustawień trenowania
Aby przesłać eksperyment, należy zdefiniować parametr eksperymentu i ustawienia modelu na potrzeby trenowania. Aby uzyskać pełną listę ustawień, zobacz Konfigurowanie eksperymentów zautomatyzowanego uczenia maszynowego w języku Python.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}Przekaż zdefiniowane ustawienia trenowania jako
kwargsparametr doAutoMLConfigobiektu. Ponieważ używasz platformy Spark, musisz również przekazać kontekst platformy Spark, który jest automatycznie dostępny dla zmiennejsc. Ponadto należy określić dane treningowe i typ modelu, który jest regresją w tym przypadku.from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
Uwaga
Kroki przetwarzania wstępnego zautomatyzowanego uczenia maszynowego stają się częścią podstawowego modelu. Te kroki obejmują normalizację funkcji, obsługę brakujących danych i konwertowanie tekstu na liczbowe. Jeśli używasz modelu do przewidywania, te same kroki przetwarzania wstępnego stosowane podczas trenowania są automatycznie stosowane do danych wejściowych.
Trenowanie automatycznego modelu regresji
Następnie utworzysz obiekt eksperymentu w obszarze roboczym usługi Azure Machine Learning. Eksperyment działa jako kontener dla poszczególnych przebiegów.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
Po zakończeniu eksperymentu dane wyjściowe zwracają szczegóły dotyczące ukończonych iteracji. W każdej iteracji widać typ modelu, czas trwania i dokładność treningu. Pole BEST śledzi najlepszy wynik trenowania na podstawie typu metryki.

Uwaga
Po przesłaniu eksperymentu zautomatyzowanego uczenia maszynowego uruchamia ona różne iteracji i typy modeli. Ten przebieg zazwyczaj trwa od 60 do 90 minut.
Pobieranie najlepszego modelu
Aby wybrać najlepszy model z iteracji, użyj get_output funkcji , aby zwrócić najlepszy przebieg i dopasowany model. Poniższy kod pobiera najlepszy przebieg i dopasowany model dla każdej zarejestrowanej metryki lub określonej iteracji.
# Get best model
best_run, fitted_model = local_run.get_output()
Dokładność modelu testowania
Aby przetestować dokładność modelu, użyj najlepszego modelu do uruchamiania przewidywań taryf taksówek na zestawie danych testowych. Funkcja
predictużywa najlepszego modelu i przewiduje wartościy(kwota taryfy) z zestawu danych weryfikacji.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)Błąd główny średniokwadratowy to często używana miara różnic między przykładowymi wartościami przewidywanymi przez model i obserwowanymi wartościami. Obliczasz błąd root-mean-square wyników, porównując ramkę
y_testdanych z wartościami przewidywanymi przez model.Funkcja
mean_squared_errorprzyjmuje dwie tablice i oblicza średni błąd kwadratowy między nimi. Następnie należy wziąć pierwiastek kwadratowy wyniku. Ta metryka wskazuje w przybliżeniu, jak daleko przewidywania taryf taksówek pochodzą z rzeczywistych wartości taryfy.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151Błąd root-mean-square jest dobrą miarą tego, jak dokładnie model przewiduje odpowiedź. Z wyników widać, że model jest dość dobry w przewidywaniu opłat za taksówkę z funkcji zestawu danych, zazwyczaj w wysokości 2,00 USD.
Uruchom następujący kod, aby obliczyć błąd mean-absolute-percent. Ta metryka wyraża dokładność jako wartość procentową błędu. Robi to, obliczając bezwzględną różnicę między poszczególnymi wartościami przewidywanymi i rzeczywistymi, a następnie sumując wszystkie różnice. Następnie wyraża tę sumę jako wartość procentową sumy wartości rzeczywistych.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263Z dwóch metryk dokładności przewidywania widać, że model jest dość dobry w przewidywaniu opłat za taksówkę z funkcji zestawu danych.
Po dopasowaniu modelu regresji liniowej należy teraz określić, jak dobrze model pasuje do danych. W tym celu wykreślisz rzeczywiste wartości taryfy względem przewidywanych danych wyjściowych. Ponadto obliczasz miarę R-kwadrat, aby zrozumieć, jak blisko danych znajduje się linia regresji dopasowanej.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()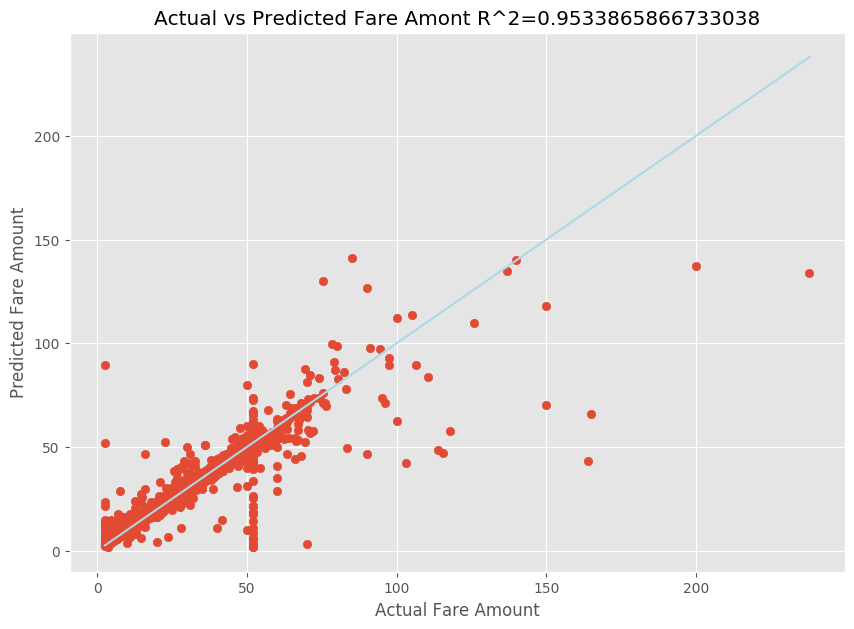
Z wyników widać, że miara R-kwadrat stanowi 95 procent wariancji. Jest to również weryfikowane przez rzeczywisty wykres w porównaniu z obserwowanym wykresem. Im większa wariancja, dla którego odpowiada model regresji, tym bliżej punkty danych spadną do linii regresji dopasowanej.
Rejestrowanie modelu w usłudze Azure Machine Learning
Po zweryfikowaniu najlepszego modelu możesz zarejestrować go w usłudze Azure Machine Learning. Następnie możesz pobrać lub wdrożyć zarejestrowany model i otrzymać wszystkie zarejestrowane pliki.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
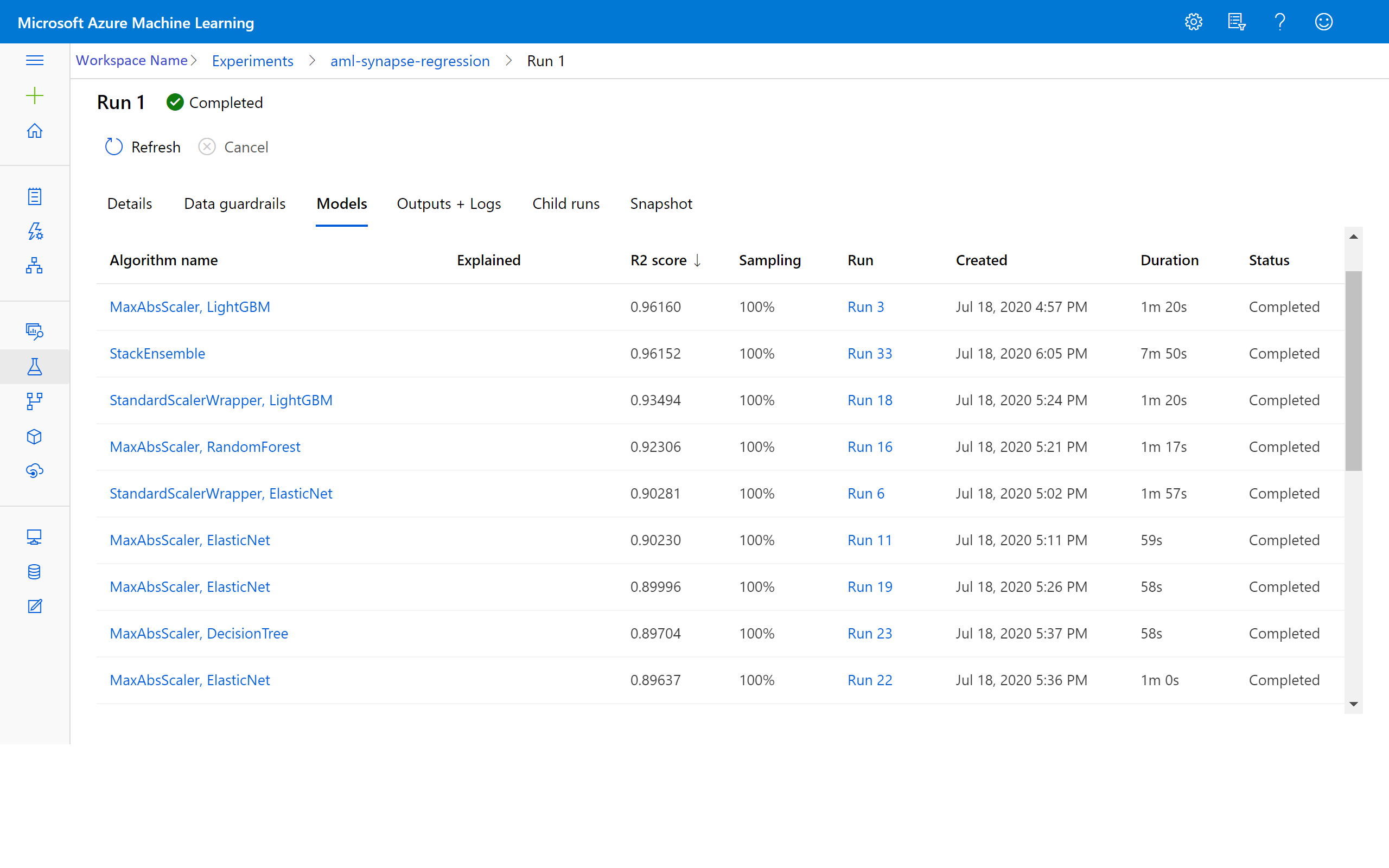
Wyświetlanie wyników w usłudze Azure Machine Learning
Możesz również uzyskać dostęp do wyników iteracji, przechodząc do eksperymentu w obszarze roboczym usługi Azure Machine Learning. W tym miejscu możesz uzyskać dodatkowe szczegóły dotyczące stanu przebiegu, prób modeli i innych metryk modelu.