Monitorowanie aplikacji platformy Apache Spark za pomocą usługi Azure Log Analytics
Z tego samouczka dowiesz się, jak włączyć łącznik programu Synapse Studio wbudowany w usługę Log Analytics. Następnie możesz zbierać i wysyłać metryki i dzienniki aplikacji platformy Apache Spark do obszaru roboczego usługi Log Analytics. Na koniec możesz użyć skoroszytu usługi Azure Monitor do wizualizacji metryk i dzienników.
Konfigurowanie informacji o obszarze roboczym
Wykonaj następujące kroki, aby skonfigurować niezbędne informacje w programie Synapse Studio.
Krok 1. Tworzenie obszaru roboczego usługi Log Analytics
Zapoznaj się z jednym z następujących zasobów, aby utworzyć ten obszar roboczy:
- Utwórz obszar roboczy w witrynie Azure Portal.
- Tworzenie obszaru roboczego przy użyciu interfejsu wiersza polecenia platformy Azure.
- Tworzenie i konfigurowanie obszaru roboczego w usłudze Azure Monitor przy użyciu programu PowerShell.
Krok 2. Zbieranie informacji o konfiguracji
Użyj dowolnej z poniższych opcji, aby przygotować konfigurację.
Opcja 1. Konfigurowanie przy użyciu identyfikatora i klucza obszaru roboczego usługi Log Analytics
Zbierz następujące wartości dla konfiguracji platformy Spark:
-
<LOG_ANALYTICS_WORKSPACE_ID>: identyfikator obszaru roboczego usługi Log Analytics. -
<LOG_ANALYTICS_WORKSPACE_KEY>: klucz usługi Log Analytics. Aby to znaleźć, w witrynie Azure Portal przejdź do obszaru roboczego>Agenci>usługi Azure Log Analytics Klucz podstawowy.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
Opcja 2. Konfigurowanie przy użyciu usługi Azure Key Vault
Uwaga
Musisz udzielić użytkownikom uprawnień do odczytu wpisu tajnego, którzy będą przesyłać aplikacje platformy Apache Spark. Aby uzyskać więcej informacji, zobacz Zapewnianie dostępu do kluczy, certyfikatów i wpisów tajnych usługi Key Vault za pomocą kontroli dostępu opartej na rolach platformy Azure. Po włączeniu tej funkcji w potoku usługi Synapse należy użyć opcji 3. Jest to konieczne, aby uzyskać wpis tajny z usługi Azure Key Vault z tożsamością zarządzaną obszaru roboczego.
Aby skonfigurować usługę Azure Key Vault do przechowywania klucza obszaru roboczego, wykonaj następujące kroki:
Utwórz magazyn kluczy i przejdź do magazynu kluczy w witrynie Azure Portal.
Na stronie ustawień magazynu kluczy wybierz pozycję Wpisy tajne.
Wybierz Generuj/Import.
Na ekranie Tworzenie wpisu tajnego wybierz następujące wartości:
-
Nazwa: Wprowadź nazwę wpisu tajnego. W polu domyślnym wprowadź .
SparkLogAnalyticsSecret -
Wartość: wprowadź wartość
<LOG_ANALYTICS_WORKSPACE_KEY>wpisu tajnego. - Dla pozostałych opcji zostaw wartości domyślne. Następnie wybierz Utwórz.
-
Nazwa: Wprowadź nazwę wpisu tajnego. W polu domyślnym wprowadź .
Zbierz następujące wartości dla konfiguracji platformy Spark:
-
<LOG_ANALYTICS_WORKSPACE_ID>: identyfikator obszaru roboczego usługi Log Analytics. -
<AZURE_KEY_VAULT_NAME>: skonfigurowana nazwa magazynu kluczy. -
<AZURE_KEY_VAULT_SECRET_KEY_NAME>(opcjonalnie): nazwa wpisu tajnego w magazynie kluczy dla klucza obszaru roboczego. Wartość domyślna toSparkLogAnalyticsSecret.
-
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Uwaga
Identyfikator obszaru roboczego można również przechowywać w usłudze Key Vault. Zapoznaj się z poprzednimi krokami i zapisz identyfikator obszaru roboczego przy użyciu nazwy SparkLogAnalyticsWorkspaceIdwpisu tajnego . Alternatywnie możesz użyć konfiguracji spark.synapse.logAnalytics.keyVault.key.workspaceId , aby określić nazwę wpisu tajnego identyfikatora obszaru roboczego w usłudze Key Vault.
Sposób 3. Konfigurowanie za pomocą połączonej usługi
Uwaga
W tej opcji należy udzielić uprawnień odczytu wpisu tajnego do tożsamości zarządzanej obszaru roboczego. Aby uzyskać więcej informacji, zobacz Zapewnianie dostępu do kluczy, certyfikatów i wpisów tajnych usługi Key Vault za pomocą kontroli dostępu opartej na rolach platformy Azure.
Aby skonfigurować połączoną usługę Key Vault w programie Synapse Studio do przechowywania klucza obszaru roboczego, wykonaj następujące kroki:
Wykonaj wszystkie kroki opisane w poprzedniej sekcji "Opcja 2".
Utwórz połączoną usługę Key Vault w programie Synapse Studio:
a. Przejdź do obszaru Synapse Studio>Zarządzaj połączonymi usługami>, a następnie wybierz pozycję Nowy.
b. W polu wyszukiwania wyszukaj usługę Azure Key Vault.
c. Wprowadź nazwę połączonej usługi.
d. Wybierz magazyn kluczy, a następnie wybierz pozycję Utwórz.
spark.synapse.logAnalytics.keyVault.linkedServiceNameDodaj element do konfiguracji platformy Apache Spark.
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
Aby uzyskać listę konfiguracji platformy Apache Spark, zobacz Dostępne konfiguracje platformy Apache Spark
Krok 3. Tworzenie konfiguracji platformy Apache Spark
Możesz utworzyć konfigurację platformy Apache Spark w obszarze roboczym, a podczas tworzenia definicji zadania notesu lub platformy Apache Spark możesz wybrać konfigurację platformy Apache Spark, która ma być używana z pulą platformy Apache Spark. Po jej wybraniu zostaną wyświetlone szczegóły konfiguracji.
Wybierz pozycję Zarządzaj konfiguracjami>platformy Apache Spark.
Wybierz przycisk Nowy , aby utworzyć nową konfigurację platformy Apache Spark.
Nowa strona konfiguracji platformy Apache Spark zostanie otwarta po wybraniu przycisku Nowy .
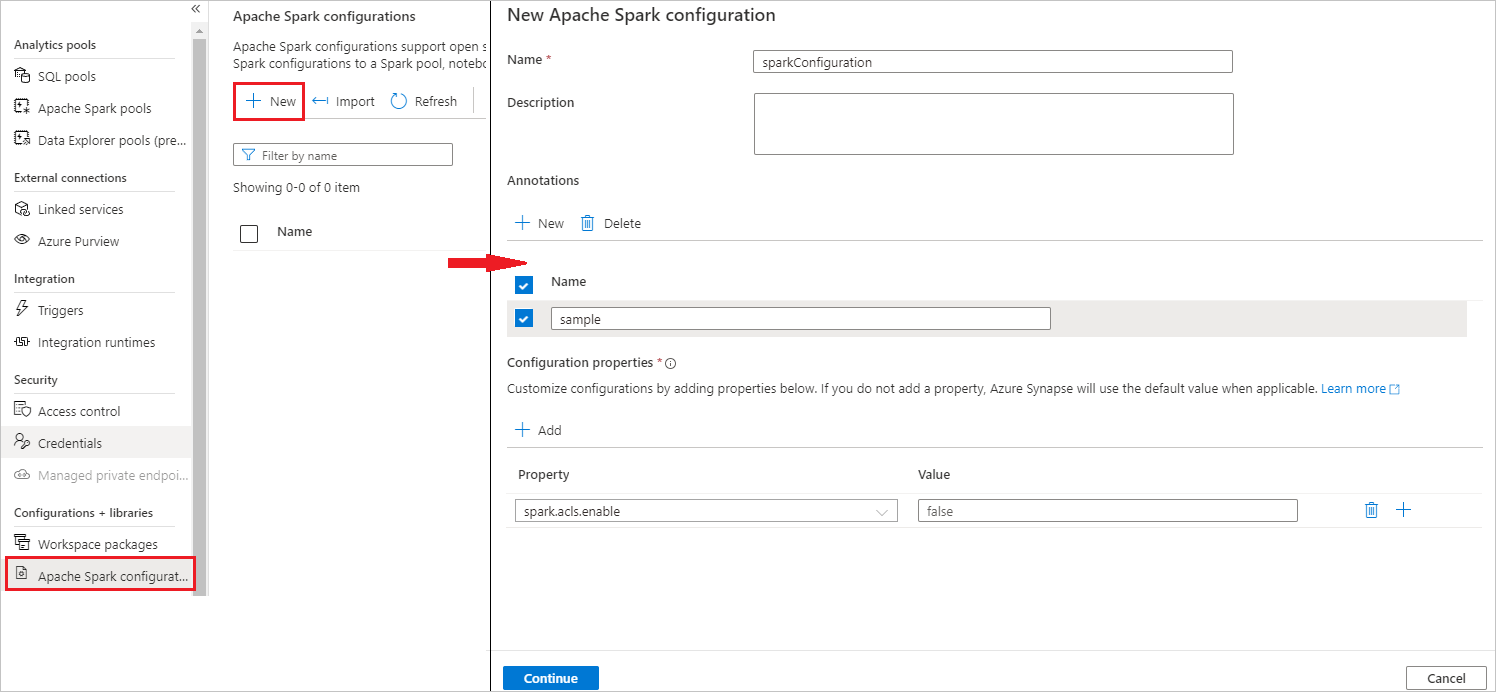
W polu Nazwa możesz wprowadzić preferowaną i prawidłową nazwę.
W polu Opis możesz wprowadzić w nim opis.
W obszarze Adnotacje można dodawać adnotacje, klikając przycisk Nowy , a także usunąć istniejące adnotacje, wybierając i klikając przycisk Usuń .
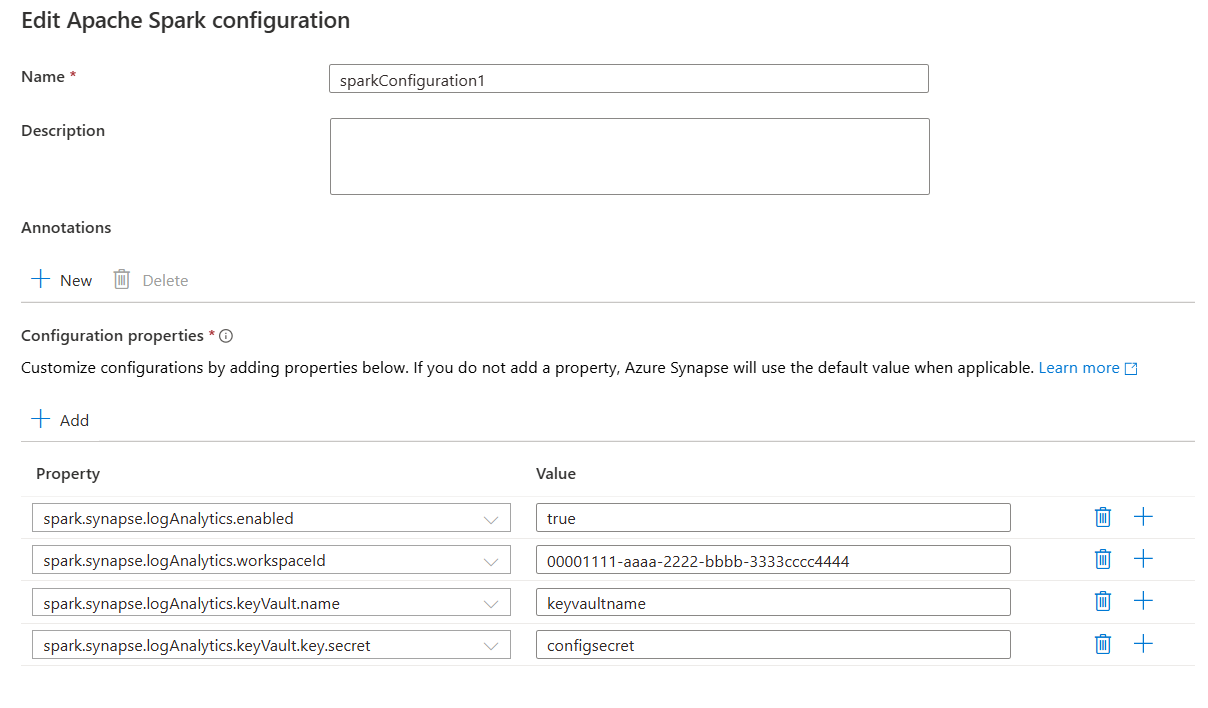
W obszarze Właściwości konfiguracji dodaj wszystkie właściwości z wybranej opcji konfiguracji, wybierając przycisk Dodaj . W polu Właściwość dodaj nazwę właściwości na liście, a w polu Wartość użyj wartości zebranej w kroku 2. Jeśli nie dodasz właściwości, usługa Azure Synapse będzie używać wartości domyślnej, jeśli ma to zastosowanie.
Przesyłanie aplikacji platformy Apache Spark i wyświetlanie dzienników i metryk
Oto, jak to zrobić:
Prześlij aplikację platformy Apache Spark do puli platformy Apache Spark skonfigurowanej w poprzednim kroku. Aby to zrobić, możesz użyć dowolnego z następujących sposobów:
- Uruchom notes w programie Synapse Studio.
- W programie Synapse Studio prześlij zadanie wsadowe platformy Apache Spark za pomocą definicji zadania platformy Apache Spark.
- Uruchamianie potoku zawierającego działanie platformy Apache Spark.
Przejdź do określonego obszaru roboczego usługi Log Analytics, a następnie wyświetl metryki aplikacji i dzienniki po uruchomieniu aplikacji Platformy Apache Spark.
Zapisywanie niestandardowych dzienników aplikacji
Możesz użyć biblioteki Apache Log4j do zapisywania dzienników niestandardowych.
Przykład dla Języka Scala:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
Przykład dla PySpark:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
Użyj przykładowego skoroszytu, aby zwizualizować metryki i dzienniki
Otwórz i skopiuj zawartość pliku skoroszytu.
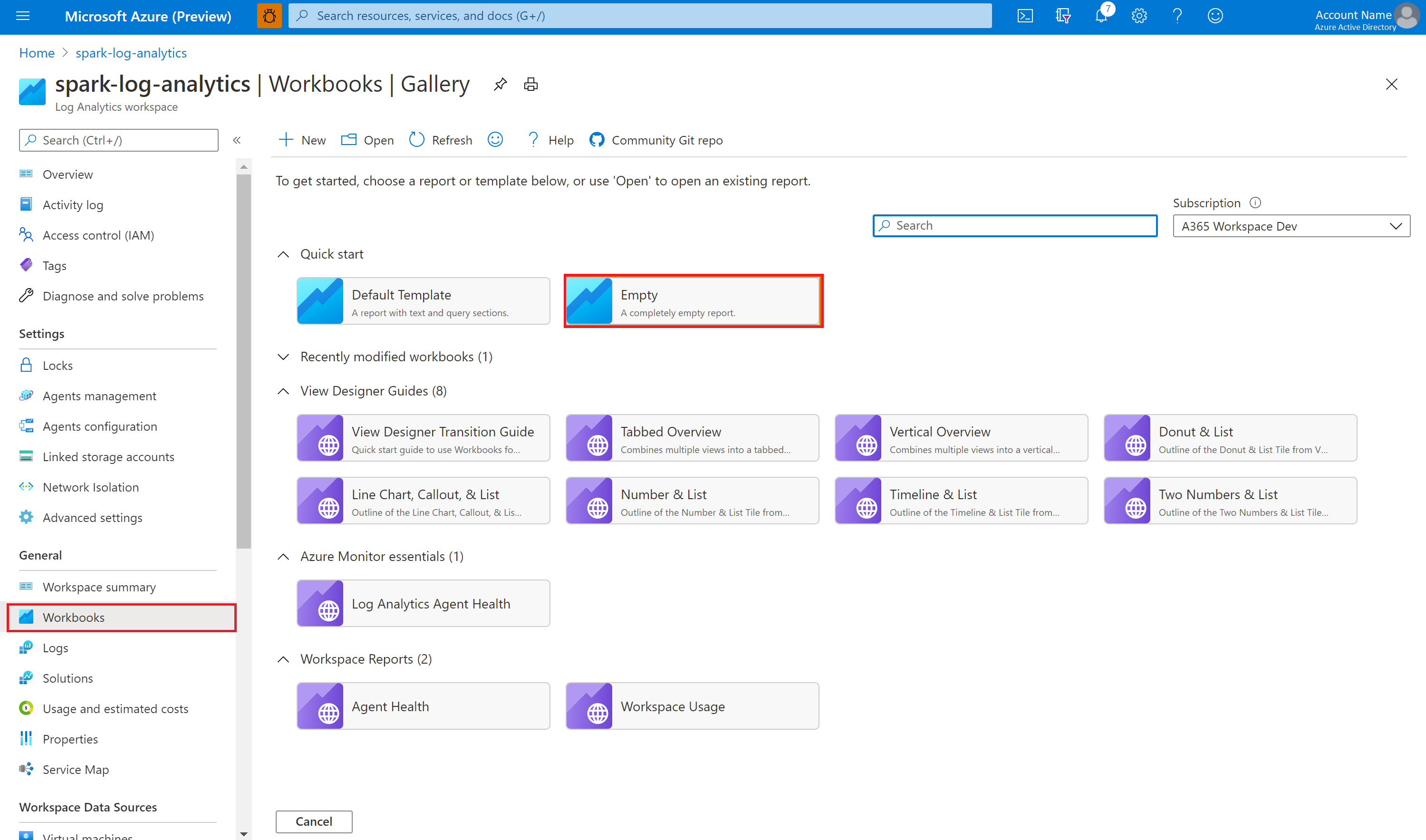
W witrynie Azure Portal wybierz pozycję Skoroszyty obszaru roboczego>usługi Log Analytics.
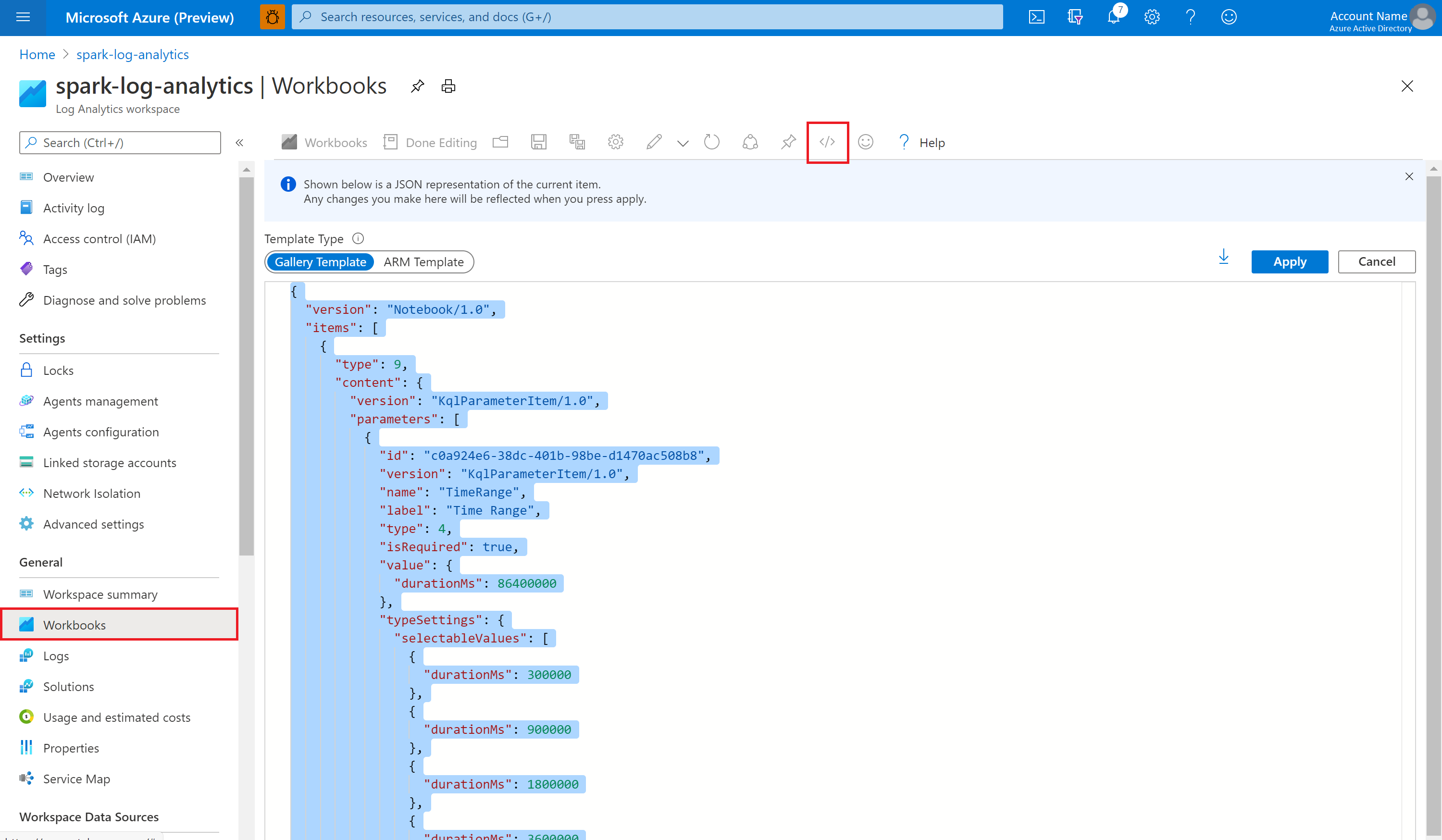
Otwórz pusty skoroszyt. Użyj trybu Edytor zaawansowany, wybierając ikonę </>.
Wklej dowolny kod JSON, który istnieje.
Wybierz pozycję Zastosuj, a następnie wybierz pozycję Zakończono edytowanie.
Następnie prześlij aplikację platformy Apache Spark do skonfigurowanej puli platformy Apache Spark. Po przejściu aplikacji do stanu uruchomienia wybierz uruchomioną aplikację na liście rozwijanej skoroszytu.
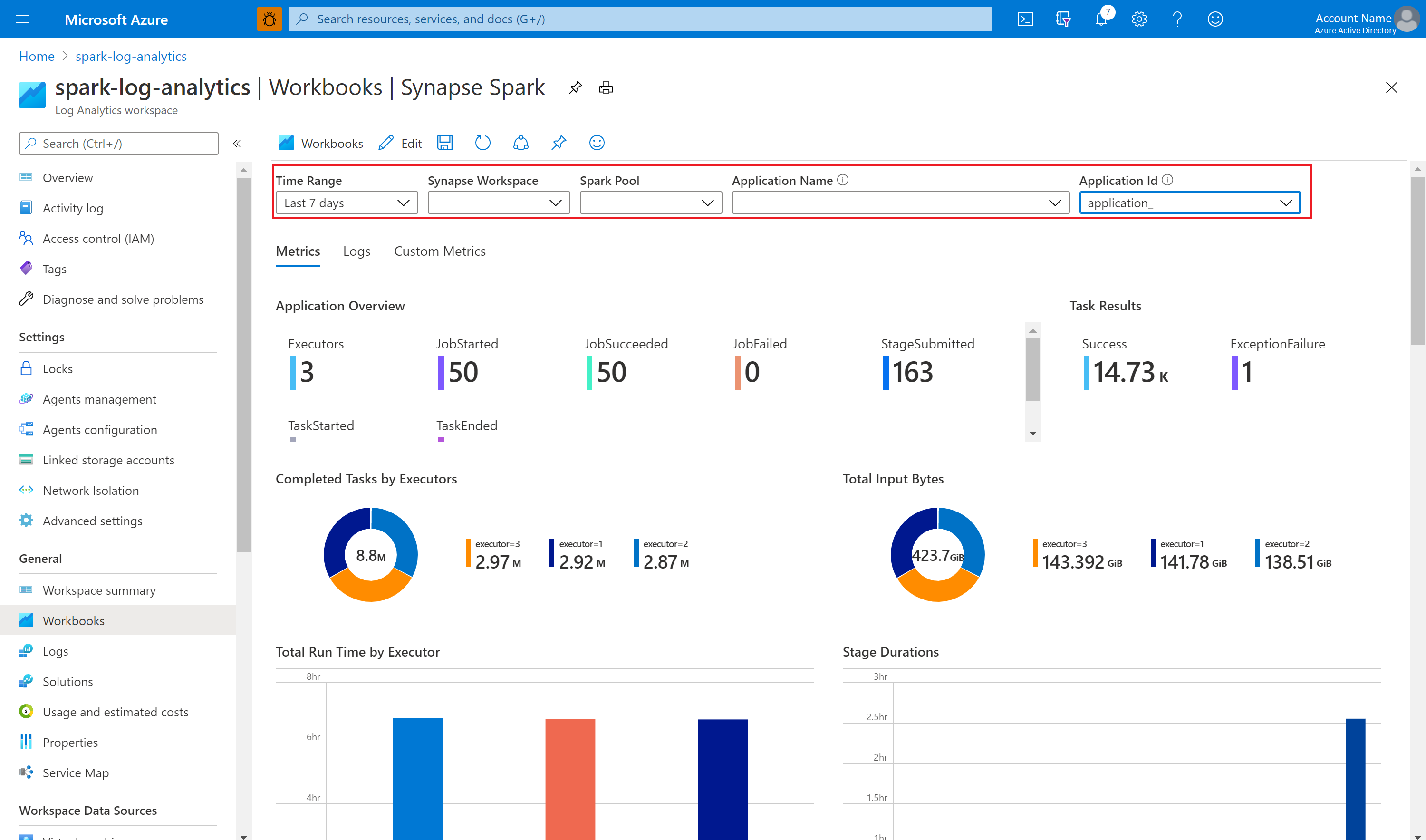
Możesz dostosować skoroszyt. Można na przykład użyć zapytań Kusto i skonfigurować alerty.
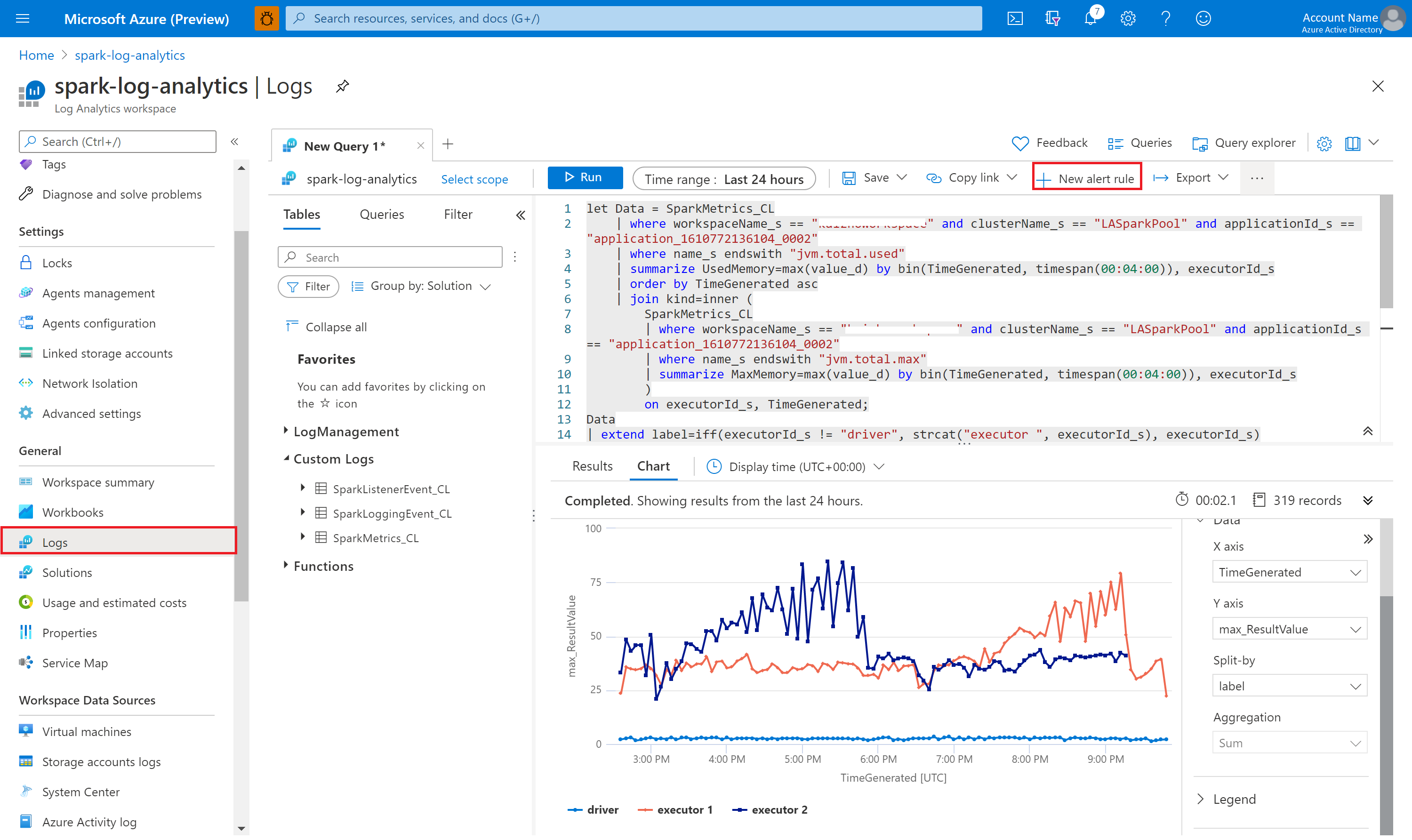
Wykonywanie zapytań dotyczących danych za pomocą usługi Kusto
Poniżej przedstawiono przykład wykonywania zapytań dotyczących zdarzeń platformy Apache Spark:
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Oto przykład wykonywania zapytań dotyczących sterownika aplikacji platformy Apache Spark i dzienników funkcji wykonawczych:
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Oto przykład wykonywania zapytań dotyczących metryk platformy Apache Spark:
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
Tworzenie alertów i zarządzanie nimi
Użytkownicy mogą wykonywać zapytania dotyczące oceny metryk i dzienników z ustawioną częstotliwością oraz wyzwalać alert na podstawie wyników. Aby uzyskać więcej informacji, zobacz Tworzenie, wyświetlanie alertów dzienników i zarządzanie nimi przy użyciu usługi Azure Monitor.
Obszar roboczy usługi Synapse z włączoną ochroną przed eksfiltracją danych
Po utworzeniu obszaru roboczego usługi Synapse z włączoną ochroną przed eksfiltracją danych.
Jeśli chcesz włączyć tę funkcję, musisz utworzyć zarządzane żądania połączenia prywatnego punktu końcowego do zakresów łącza prywatnego usługi Azure Monitor (AMPLS) w zatwierdzonych dzierżawach firmy Microsoft w obszarze roboczym.
Poniższe kroki można wykonać, aby utworzyć zarządzane połączenie prywatnego punktu końcowego z zakresami łącza prywatnego usługi Azure Monitor (AMPLS):
- Jeśli nie ma istniejącej usługi AMPLS, możesz skorzystać z konfiguracji połączenia usługi Azure Monitor Private Link, aby je utworzyć.
- Przejdź do swojego adresu AMPLS w witrynie Azure Portal na stronie Zasoby usługi Azure Monitor wybierz pozycję Dodaj , aby dodać połączenie do obszaru roboczego usługi Azure Log Analytics.
- Przejdź do obszaru > Zarządzanie zarządzanymi prywatnymi punktami końcowymi usługi Synapse Studio>, wybierz przycisk Nowy, wybierz pozycję Zakresy usługi Azure Monitor Private Link i kontynuuj.
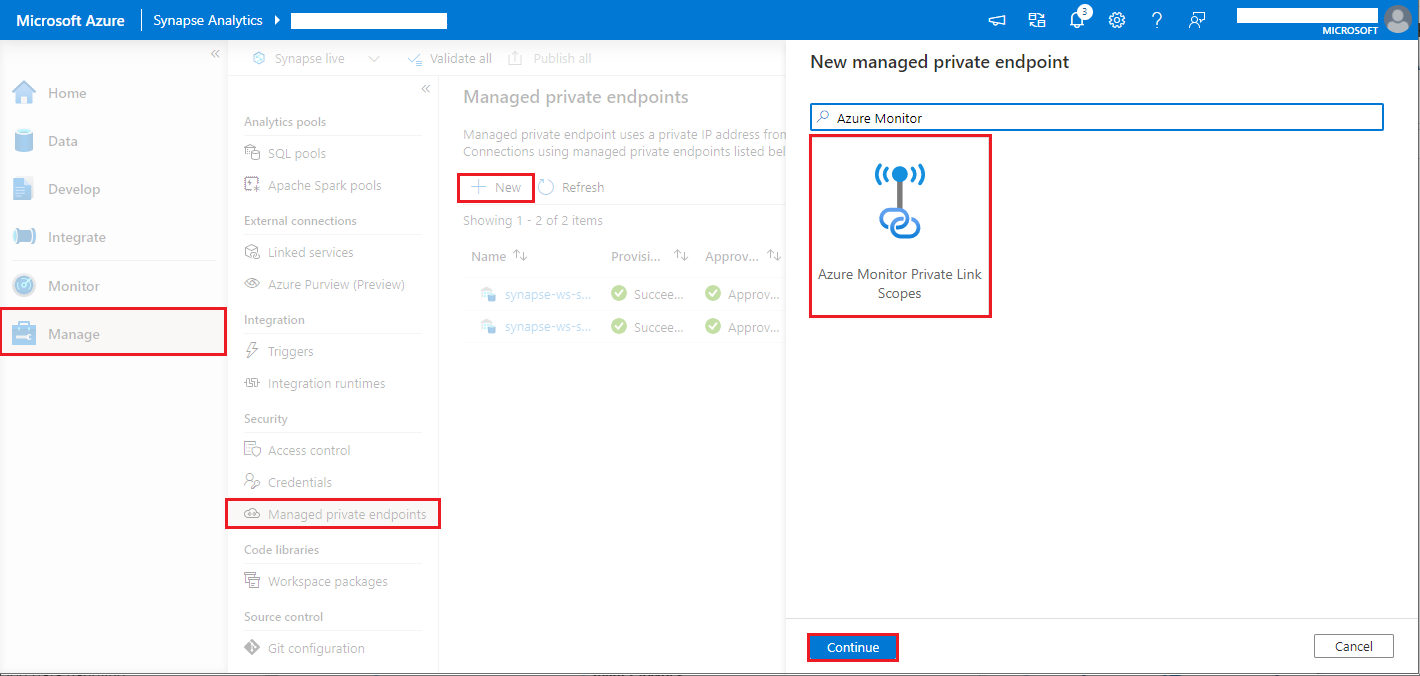
- Wybierz utworzony zakres usługi Azure Monitor Private Link, a następnie wybierz przycisk Utwórz .
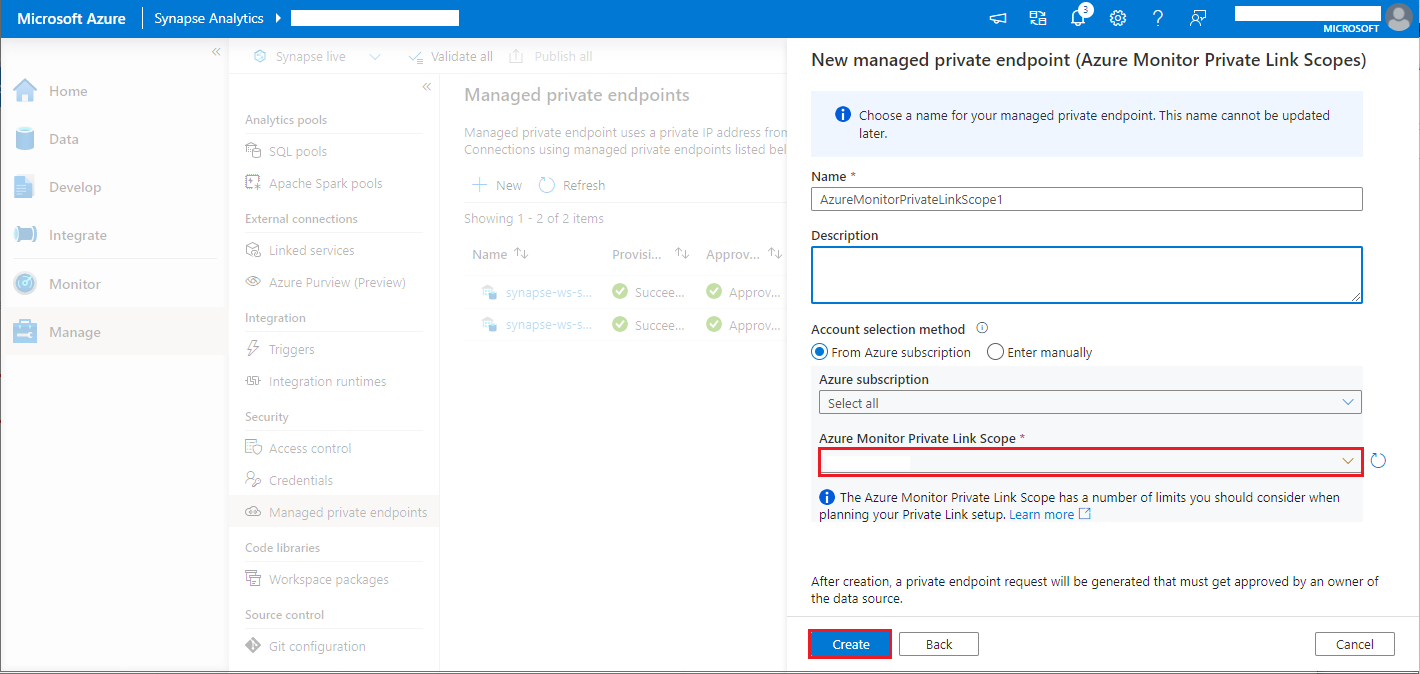
- Poczekaj kilka minut na aprowizowanie prywatnego punktu końcowego.
- Ponownie przejdź do adresu AMPLS w witrynie Azure Portal na stronie Połączenia z prywatnym punktem końcowym wybierz aprowizowaną połączenie i zatwierdź.
Uwaga
- Obiekt AMPLS ma szereg limitów, które należy wziąć pod uwagę podczas planowania konfiguracji usługi Private Link. Zobacz AMPLS limity , aby dowiedzieć się więcej na temat tych limitów.
- Sprawdź, czy masz odpowiednie uprawnienia do tworzenia zarządzanego prywatnego punktu końcowego.