Szybki start: przekształcanie danych przy użyciu definicji zadania platformy Apache Spark
W tym przewodniku Szybki start utworzysz potok przy użyciu usługi Azure Synapse Analytics przy użyciu definicji zadania platformy Apache Spark.
Wymagania wstępne
- Subskrypcja platformy Azure: jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
- Obszar roboczy usługi Azure Synapse: utwórz obszar roboczy usługi Synapse przy użyciu witryny Azure Portal, postępując zgodnie z instrukcjami w przewodniku Szybki start: tworzenie obszaru roboczego usługi Synapse.
- Definicja zadania platformy Apache Spark: utwórz definicję zadania platformy Apache Spark w obszarze roboczym usługi Synapse, postępując zgodnie z instrukcjami w temacie Samouczek: tworzenie definicji zadania platformy Apache Spark w programie Synapse Studio.
Przejdź do programu Synapse Studio
Po utworzeniu obszaru roboczego usługi Azure Synapse masz dwa sposoby otwierania programu Synapse Studio:
- Otwórz obszar roboczy usługi Synapse w witrynie Azure Portal. Wybierz pozycję Otwórz na karcie Open Synapse Studio w obszarze Wprowadzenie.
- Otwórz usługę Azure Synapse Analytics i zaloguj się do obszaru roboczego.
W tym przewodniku Szybki start jako przykład użyjemy obszaru roboczego o nazwie "sampletest".
Tworzenie potoku z definicją zadania platformy Apache Spark
Potok zawiera przepływ logiczny na potrzeby wykonywania zestawu działań. W tej sekcji utworzysz potok zawierający działanie definicji zadania platformy Apache Spark.
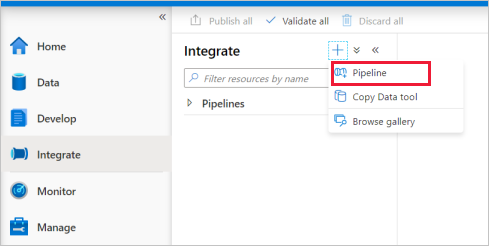
Przejdź do karty Integracja . Wybierz ikonę znaku plus obok nagłówka potoków i wybierz pozycję Potok.
Na stronie Ustawienia właściwości potoku wprowadź demo w polu Nazwa.
W obszarze Synapse w okienku Działania przeciągnij definicję zadania platformy Spark na kanwę potoku.
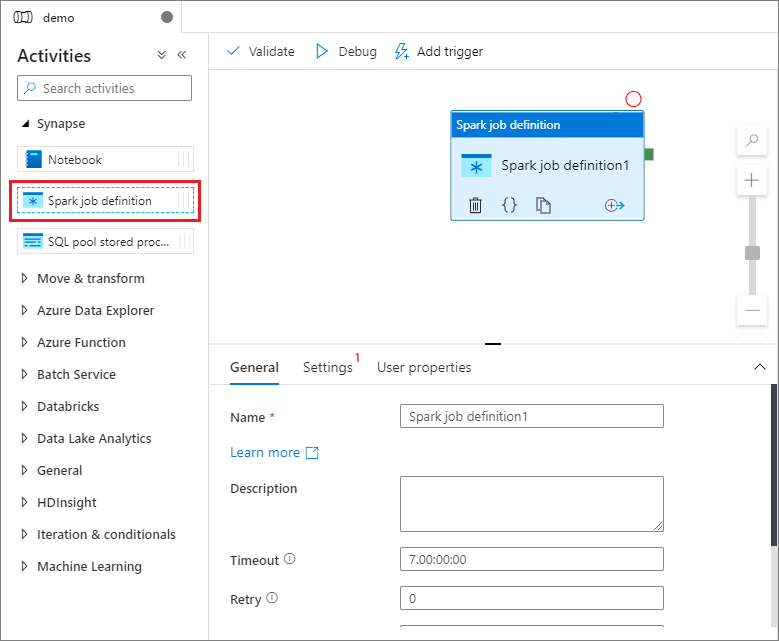
Ustawianie kanwy definicji zadania platformy Apache Spark
Po utworzeniu definicji zadania platformy Apache Spark zostanie automatycznie wysłana do kanwy definicji zadania platformy Spark.
Ustawienia ogólne
Wybierz moduł definicji zadania platformy Spark na kanwie.
Na karcie Ogólne wprowadź przykład w polu Nazwa.
(Opcja) Możesz również wprowadzić opis.
Limit czasu: maksymalny czas uruchomienia działania. Wartość domyślna to siedem dni, czyli maksymalny dozwolony czas. Format jest w formacie D.HH:MM:SS.
Ponów próbę: maksymalna liczba ponownych prób.
Interwał ponawiania prób: liczba sekund między poszczególnymi próbami ponawiania próby.
Bezpieczne dane wyjściowe: po zaznaczeniu dane wyjściowe z działania nie są przechwytywane podczas rejestrowania.
Bezpieczne dane wejściowe: po zaznaczeniu dane wejściowe z działania nie są przechwytywane podczas rejestrowania.
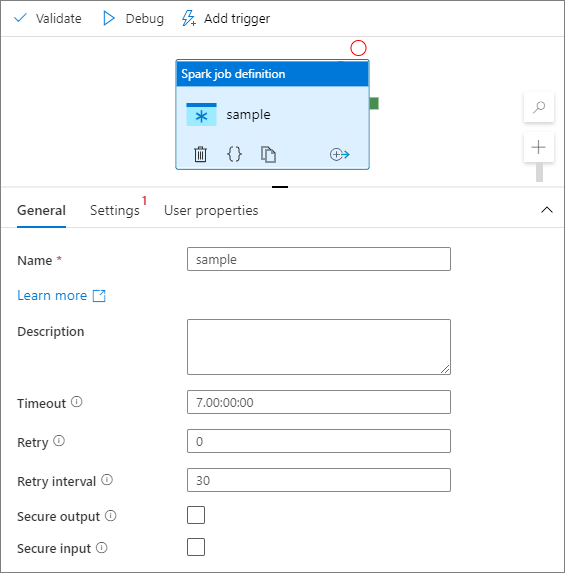
Karta Ustawienia
Na tym panelu możesz odwołać się do definicji zadania platformy Spark do uruchomienia.
Rozwiń listę definicji zadań platformy Spark. Możesz wybrać istniejącą definicję zadania platformy Apache Spark. Możesz również utworzyć nową definicję zadania platformy Apache Spark, wybierając przycisk Nowy , aby odwołać się do definicji zadania platformy Spark do uruchomienia.
(Opcjonalnie) Możesz wypełnić informacje dotyczące definicji zadania platformy Apache Spark. Jeśli następujące ustawienia są puste, do uruchomienia są używane ustawienia samej definicji zadania platformy Spark; Jeśli następujące ustawienia nie są puste, te ustawienia zastępują ustawienia samej definicji zadania platformy Spark.
Właściwości opis Główny plik definicji Główny plik używany do zadania. Wybierz plik PY/JAR/ZIP z magazynu. Możesz wybrać pozycję Przekaż plik , aby przekazać plik na konto magazynu.
Przykład:abfss://…/path/to/wordcount.jarOdwołania z podfolderów Skanowanie podfolderów z folderu głównego głównego pliku definicji. Te pliki są dodawane jako pliki referencyjne. Foldery o nazwach "jars", "pyFiles", "files" lub "archives" są skanowane, a nazwa folderów uwzględnia wielkość liter. Nazwa klasy głównej W pełni kwalifikowany identyfikator lub klasa główna, która znajduje się w głównym pliku definicji.
Przykład:WordCountArgumenty wiersza polecenia Argumenty wiersza polecenia można dodać, klikając przycisk Nowy . Należy zauważyć, że dodanie argumentów wiersza polecenia zastępuje argumenty wiersza polecenia zdefiniowane przez definicję zadania platformy Spark.
Próbka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPula platformy Apache Spark Z listy możesz wybrać pulę platformy Apache Spark. Dokumentacja kodu w języku Python Inne pliki kodu języka Python używane do celów referencyjnych w głównym pliku definicji.
Obsługuje przekazywanie plików (.py, .py3, .zip) do właściwości "pyFiles". Zastępuje właściwość "pyFiles" zdefiniowaną w definicji zadania platformy Spark.Pliki referencyjne Inne pliki używane do odwołania w głównym pliku definicji. Dynamiczne przydzielanie funkcji wykonawczych To ustawienie mapuje na właściwość alokacji dynamicznej w konfiguracji platformy Spark dla alokacji funkcji wykonawczych aplikacji platformy Spark. Minimalna liczba funkcji wykonawczych Minimalna liczba funkcji wykonawczych do przydzielenia w określonej puli Spark dla zadania. Maksymalna liczba funkcji wykonawczych Maksymalna liczba funkcji wykonawczych do przydzielenia w określonej puli Spark dla zadania. Rozmiar sterownika Liczba rdzeni i pamięci, które mają być używane dla sterownika podanego w określonej puli platformy Apache Spark dla zadania. Konfiguracja platformy Spark Określ wartości właściwości konfiguracji platformy Spark wymienione w artykule: Konfiguracja platformy Spark — właściwości aplikacji. Użytkownicy mogą używać konfiguracji domyślnej i dostosowanej konfiguracji. 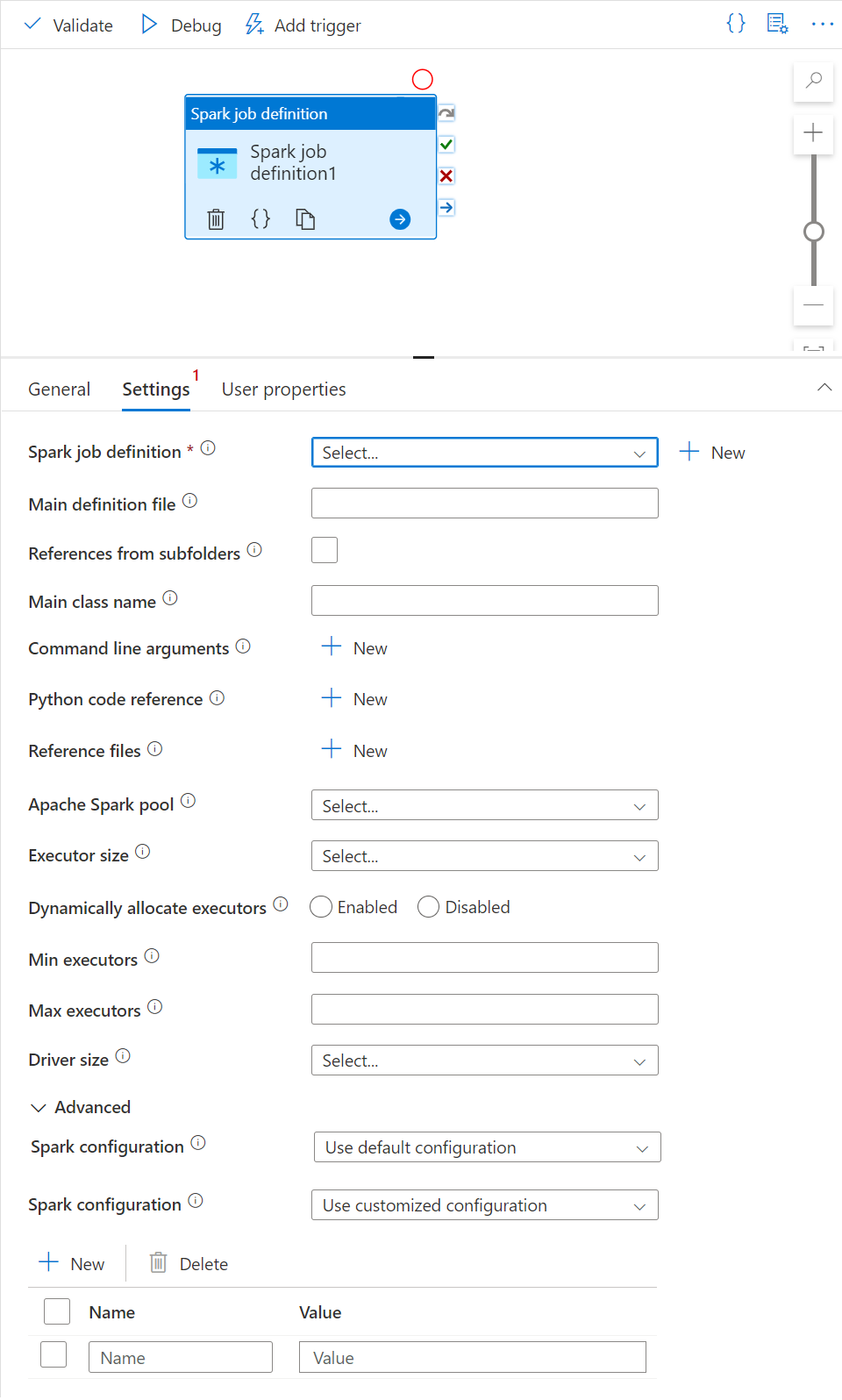
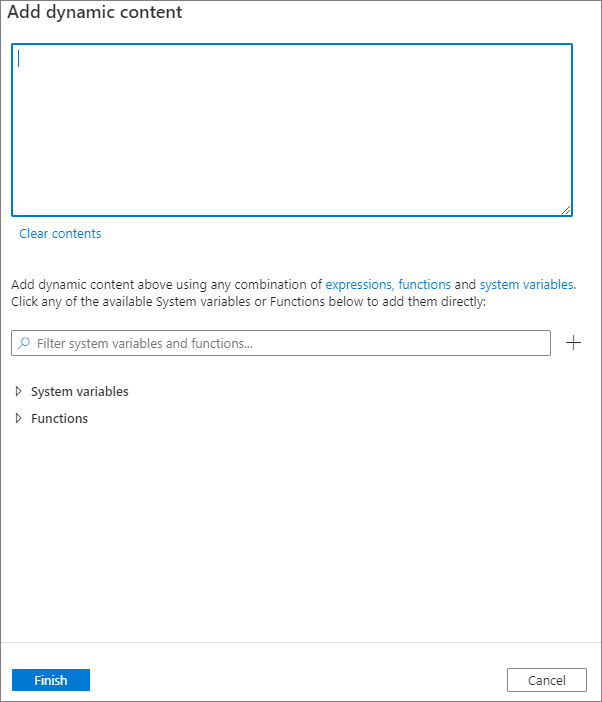
Zawartość dynamiczną można dodać, klikając przycisk Dodaj zawartość dynamiczną lub naciskając skrótu Alt+Shift+D. Na stronie Dodawanie zawartości dynamicznej można użyć dowolnej kombinacji wyrażeń, funkcji i zmiennych systemowych, aby dodać do zawartości dynamicznej.
Karta Właściwości użytkownika
W tym panelu można dodać właściwości działania definicji zadania platformy Apache Spark.

Powiązana zawartość
Przejdź do następujących artykułów, aby dowiedzieć się więcej o obsłudze usługi Azure Synapse Analytics: