Szybki start: przekształcanie danych przy użyciu przepływów danych mapowania
W tym przewodniku Szybki start utworzysz potok, który przekształca dane ze źródła usługi Azure Data Lake Storage Gen2 (ADLS Gen2) do ujścia usługi ADLS Gen2 przy użyciu przepływu danych mapowania. Wzorzec konfiguracji w tym przewodniku Szybki start można rozszerzyć podczas przekształcania danych przy użyciu przepływu danych mapowania
W tym przewodniku Szybki start wykonasz następujące czynności:
- Tworzenie potoku przy użyciu działania Przepływ danych w usłudze Azure Synapse Analytics.
- Utwórz przepływ danych mapowania z czterema przekształceniami.
- Testowe uruchamianie potoku.
- Monitorowanie działania Przepływ danych
Wymagania wstępne
Subskrypcja platformy Azure: jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto platformy Azure.
Obszar roboczy usługi Azure Synapse: utwórz obszar roboczy usługi Synapse przy użyciu witryny Azure Portal, postępując zgodnie z instrukcjami w przewodniku Szybki start: tworzenie obszaru roboczego usługi Synapse.
Konto usługi Azure Storage: magazyn usługi ADLS jest używany jako magazyn danych źródłowych i ujścia . Jeśli nie masz konta magazynu, utwórz je, wykonując czynności przedstawione w artykule Tworzenie konta magazynu platformy Azure.
Plik, który przekształcamy w tym samouczku, jest MoviesDB.csv, który można znaleźć tutaj. Aby pobrać plik z usługi GitHub, skopiuj zawartość do wybranego edytora tekstów, aby zapisać lokalnie jako plik .csv. Aby przekazać plik na konto magazynu, zobacz Przekazywanie obiektów blob za pomocą witryny Azure Portal. Przykłady będą odwoływać się do kontenera o nazwie "sample-data".
Przejdź do programu Synapse Studio
Po utworzeniu obszaru roboczego usługi Azure Synapse masz dwa sposoby otwierania programu Synapse Studio:
- Otwórz obszar roboczy usługi Synapse w witrynie Azure Portal. Wybierz pozycję Otwórz na karcie Open Synapse Studio w obszarze Wprowadzenie.
- Otwórz usługę Azure Synapse Analytics i zaloguj się do obszaru roboczego.
W tym przewodniku Szybki start jako przykład użyjemy obszaru roboczego o nazwie "adftest2020". Spowoduje to automatyczne przejście do strony głównej programu Synapse Studio.
Tworzenie potoku z działaniem Przepływ danych
Potok zawiera przepływ logiczny na potrzeby wykonywania zestawu działań. W tej sekcji utworzysz potok zawierający działanie Przepływ danych.
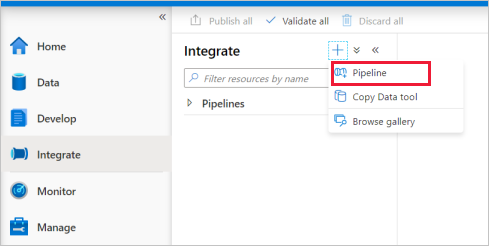
Przejdź do karty Integracja . Wybierz ikonę znaku plus obok nagłówka potoków i wybierz pozycję Potok.
Na stronie Ustawienia właściwości potoku wprowadź wartość TransformFilmy w polu Nazwa.
W obszarze Przenoszenie i przekształcanie w okienku Działania przeciągnij przepływ danych na kanwę potoku.
W oknie podręcznym Dodawanie przepływu danych wybierz pozycję Utwórz nowy przepływ danych —> przepływ danych. Po zakończeniu wybierz przycisk OK.
Nadaj przepływowi danych nazwę TransformFilms na stronie Właściwości .
Tworzenie logiki przekształcania na kanwie przepływu danych
Po utworzeniu Przepływ danych nastąpi automatyczne wysłanie do kanwy przepływu danych. W tym kroku utworzysz przepływ danych, który pobiera MoviesDB.csv w magazynie usługi ADLS i agreguje średnią ocenę komedii z 1910 do 2000 roku. Następnie zapiszesz ten plik z powrotem do magazynu usługi ADLS.
Nad kanwą przepływu danych przesuń suwak debugowania przepływu danych. Tryb debugowania umożliwia interaktywne testowanie logiki transformacji względem dynamicznego klastra Spark. Przepływ danych klastry zajmują od 5 do 7 minut, a użytkownicy powinni najpierw włączyć debugowanie, jeśli planują wykonać Przepływ danych programowania. Aby uzyskać więcej informacji, zobacz Tryb debugowania.
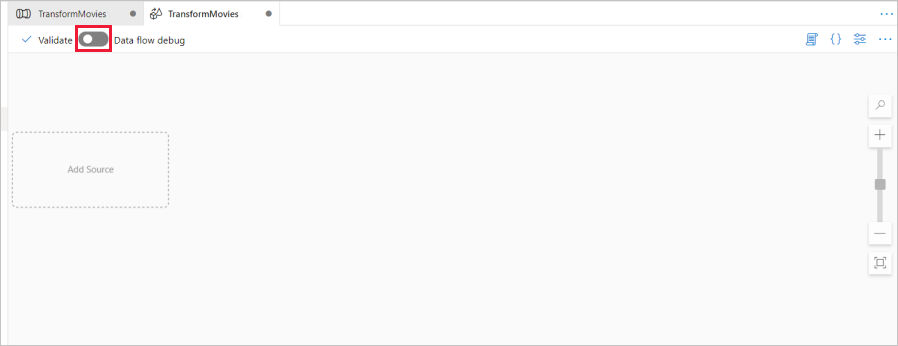
Na kanwie przepływu danych dodaj źródło, klikając pole Dodaj źródło .
Nazwij źródłową bazę danych MoviesDB. Wybierz pozycję Nowy , aby utworzyć nowy źródłowy zestaw danych.
Wybierz pozycję Azure Data Lake Storage Gen2. Wybierz Kontynuuj.

Wybierz pozycję RozdzielanyTekst. Wybierz Kontynuuj.
Nadaj zestawowi danych nazwę MoviesDB. Z listy rozwijanej połączona usługa wybierz pozycję Nowy.
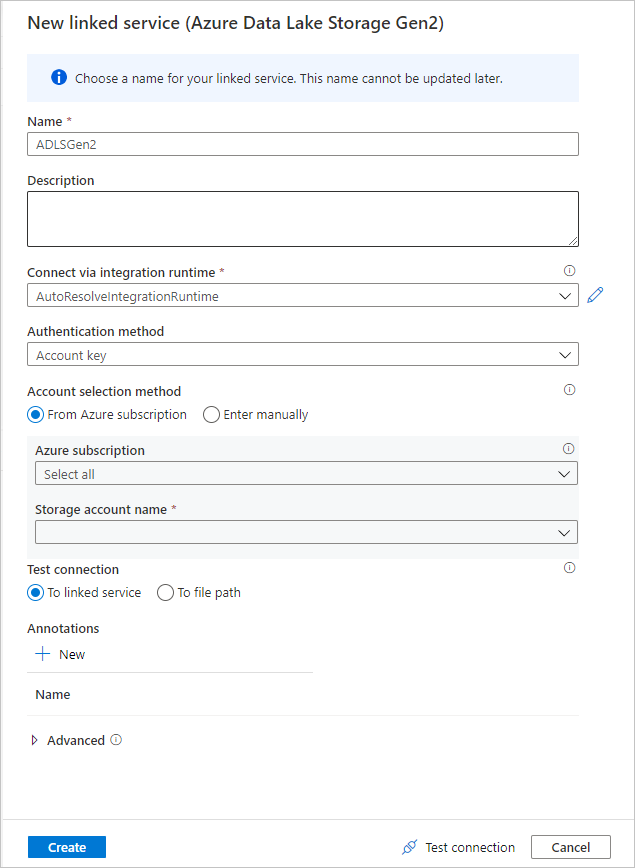
Na ekranie tworzenia połączonej usługi nadaj nazwę połączonej usłudze ADLS Gen2 połączonej usłudze ADLSGen2 i określ metodę uwierzytelniania. Następnie wprowadź poświadczenia połączenia. W tym przewodniku Szybki start używamy klucza konta do nawiązywania połączenia z kontem magazynu. Możesz wybrać pozycję Testuj połączenie , aby sprawdzić, czy poświadczenia zostały wprowadzone poprawnie. Po zakończeniu wybierz pozycję Utwórz.
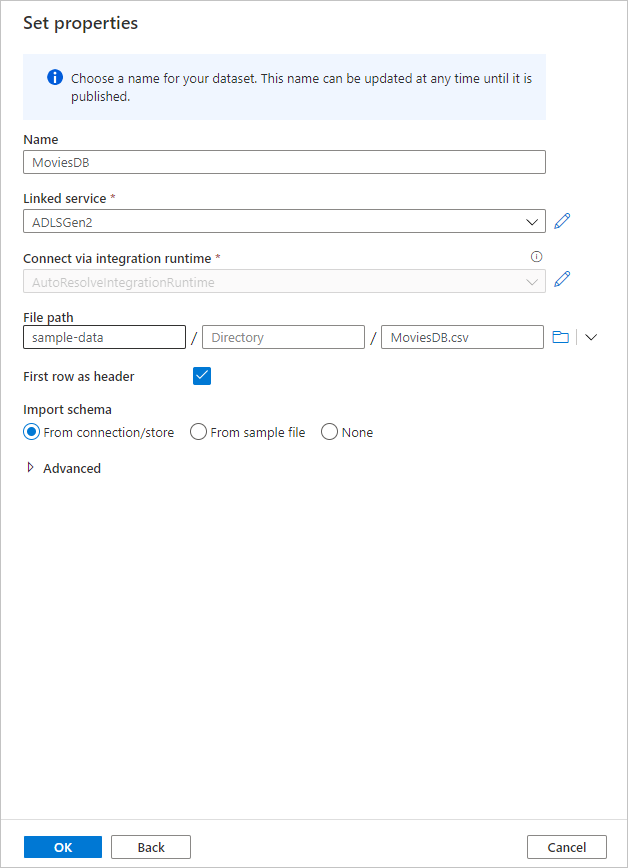
Po powrocie do ekranu tworzenia zestawu danych w polu Ścieżka pliku wprowadź miejsce, w którym znajduje się plik. W tym przewodniku Szybki start plik "MoviesDB.csv" znajduje się w kontenerze "sample-data". Ponieważ plik ma nagłówki, zaznacz pozycję Pierwszy wiersz jako nagłówek. Wybierz pozycję Z połączenia/magazynu , aby zaimportować schemat nagłówka bezpośrednio z pliku w magazynie. Po zakończeniu wybierz przycisk OK.
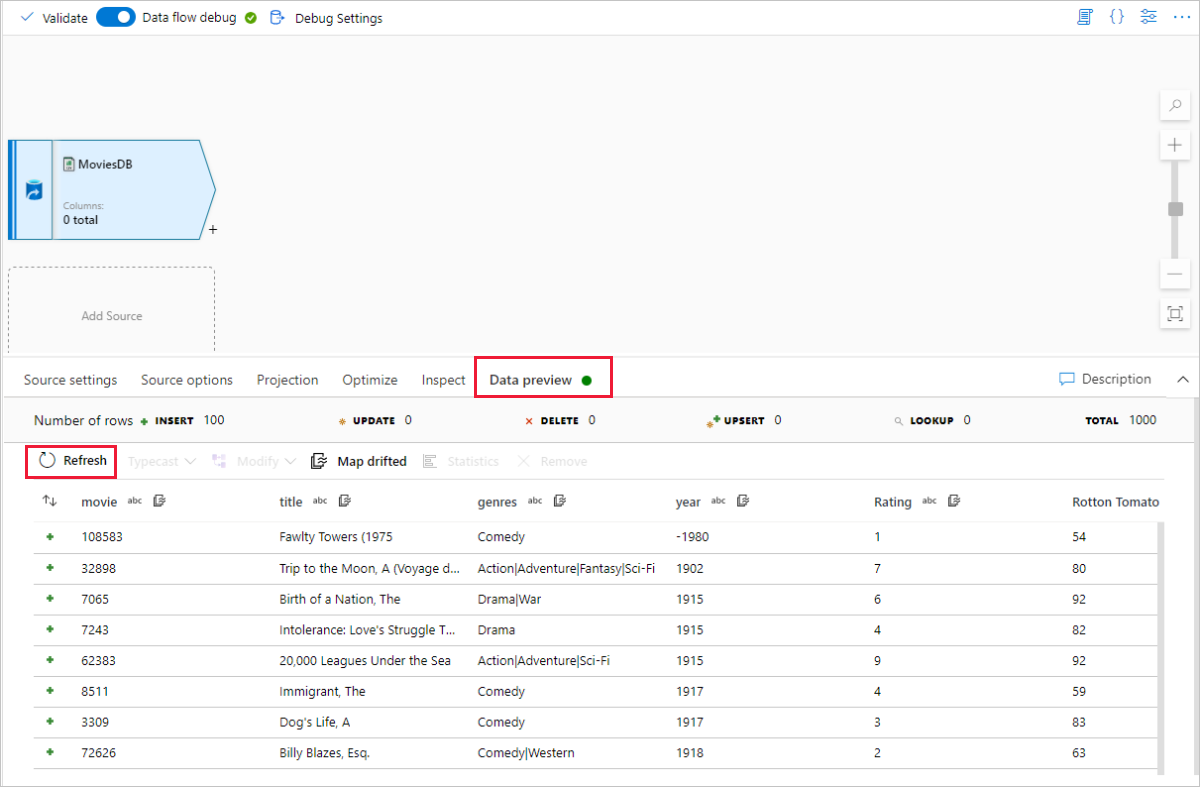
Jeśli klaster debugowania został uruchomiony, przejdź do karty Podgląd danych przekształcenia źródła i wybierz pozycję Odśwież , aby uzyskać migawkę danych. Możesz użyć podglądu danych, aby sprawdzić, czy transformacja jest poprawnie skonfigurowana.
Obok węzła źródłowego na kanwie przepływu danych wybierz ikonę plusa, aby dodać nową transformację. Pierwszą dodaną transformacją jest filtr.
Nadaj transformacji filtrowi nazwę FilterYears. Wybierz pole wyrażenia obok pozycji Filtruj , aby otworzyć konstruktora wyrażeń. W tym miejscu określisz warunek filtrowania.
Konstruktor wyrażeń przepływu danych umożliwia interaktywne tworzenie wyrażeń używanych w różnych przekształceniach. Wyrażenia mogą zawierać wbudowane funkcje, kolumny ze schematu wejściowego i parametry zdefiniowane przez użytkownika. Aby uzyskać więcej informacji na temat tworzenia wyrażeń, zobacz Przepływ danych konstruktora wyrażeń.
W tym przewodniku Szybki start chcesz filtrować filmy komedii gatunkowej, które pojawiły się między latami 1910 i 2000. Ponieważ rok jest obecnie ciągiem, musisz przekonwertować go na liczbę całkowitą przy użyciu
toInteger()funkcji . Użyj operatorów większej lub równej (>=) i mniejszej lub równej operatorom (<=), aby porównać wartości roku literału 1910 i 200-. Połącz te wyrażenia razem z operatorem&&(i). Wyrażenie jest zwracane jako:toInteger(year) >= 1910 && toInteger(year) <= 2000Aby dowiedzieć się, które filmy są komediami, możesz użyć
rlike()funkcji , aby znaleźć wzorzec "Komedia" w gatunkach kolumn. Ujmij wyrażenie zrlikeporównaniem roku, aby uzyskać:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')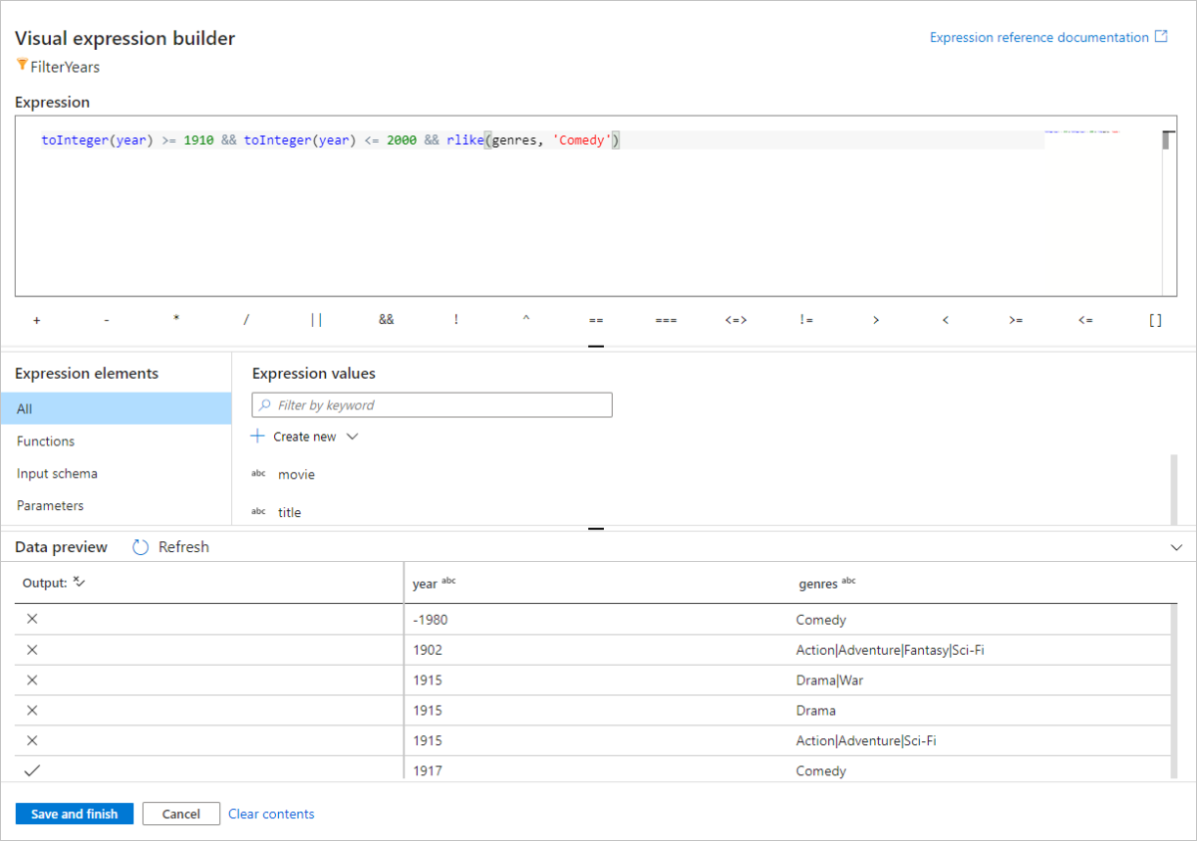
Jeśli masz aktywny klaster debugowania, możesz zweryfikować logikę, klikając pozycję Odśwież , aby wyświetlić dane wyjściowe wyrażenia w porównaniu z użytymi danymi wejściowymi. Istnieje więcej niż jedna prawidłowa odpowiedź na temat tego, jak można osiągnąć tę logikę przy użyciu języka wyrażeń przepływu danych.
Po zakończeniu pracy z wyrażeniem wybierz pozycję Zapisz i zakończ .
Pobierz podgląd danych, aby sprawdzić, czy filtr działa poprawnie.
Kolejną transformacją , którą dodasz, jest przekształcenie agregacji w obszarze Modyfikator schematu.
Nadaj agregacji nazwę AggregateComedyRatings. Na karcie Grupuj według wybierz pozycję rok z listy rozwijanej, aby pogrupować agregacje według roku, w ramach których film został wyjęły.
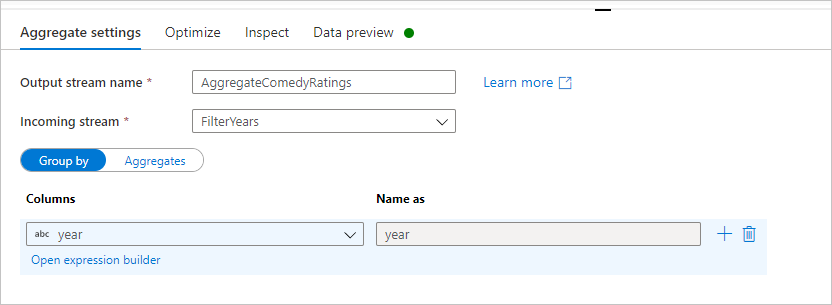
Przejdź do karty Agregacje . W polu tekstowym po lewej stronie nadaj kolumnie agregacji nazwę AverageComedyRating. Wybierz odpowiednie pole wyrażenia, aby wprowadzić wyrażenie agregacji za pomocą konstruktora wyrażeń.
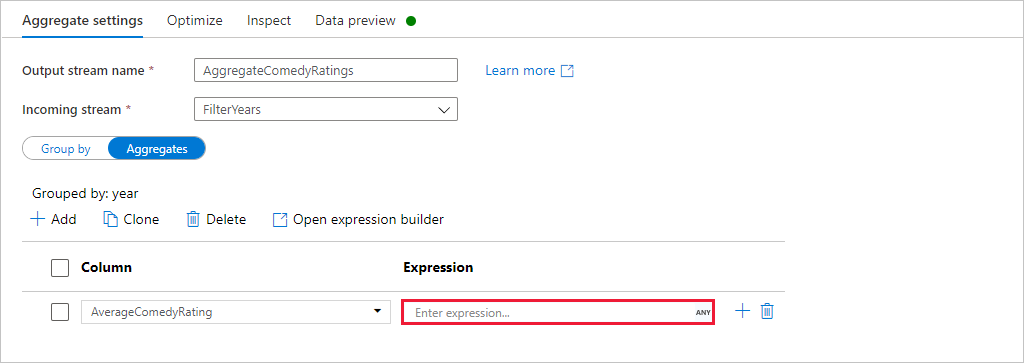
Aby uzyskać średnią kolumny Ocena, użyj
avg()funkcji agregującej. Ponieważ ocena jest ciągiem iavg()przyjmuje dane wejściowe liczbowe, musimy przekonwertować wartość na liczbę za pośrednictwemtoInteger()funkcji. To wyrażenie wygląda następująco:avg(toInteger(Rating))Po zakończeniu wybierz pozycję Zapisz i zakończ .
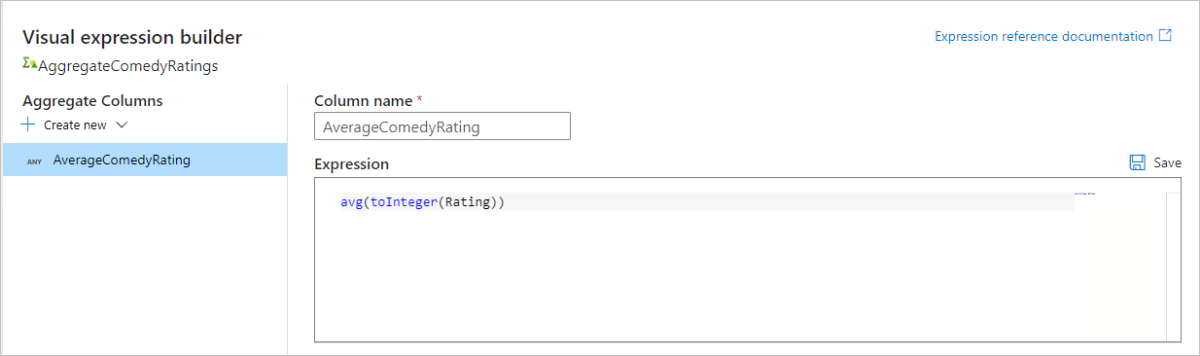
Przejdź do karty Podgląd danych, aby wyświetlić dane wyjściowe przekształcenia. Zwróć uwagę, że istnieją tylko dwie kolumny: rok i AverageComedyRating.
Następnie chcesz dodać przekształcenie ujścia w obszarze Miejsce docelowe.
Nazwij ujście ujścia. Wybierz pozycję Nowy , aby utworzyć zestaw danych ujścia.
Wybierz pozycję Azure Data Lake Storage Gen2. Wybierz Kontynuuj.
Wybierz pozycję RozdzielanyTekst. Wybierz Kontynuuj.
Nadaj zestawowi danych ujście nazwę MoviesSink. W przypadku połączonej usługi wybierz połączoną usługę ADLS Gen2 utworzoną w kroku 7. Wprowadź folder wyjściowy do zapisania danych. W tym przewodniku Szybki start piszemy do folderu "output" w kontenerze "sample-data". Folder nie musi istnieć wcześniej i można go dynamicznie tworzyć. Ustaw wartość Pierwszy wiersz jako nagłówek jako true, a następnie wybierz pozycję Brak w polu Importuj schemat. Po zakończeniu wybierz przycisk OK.
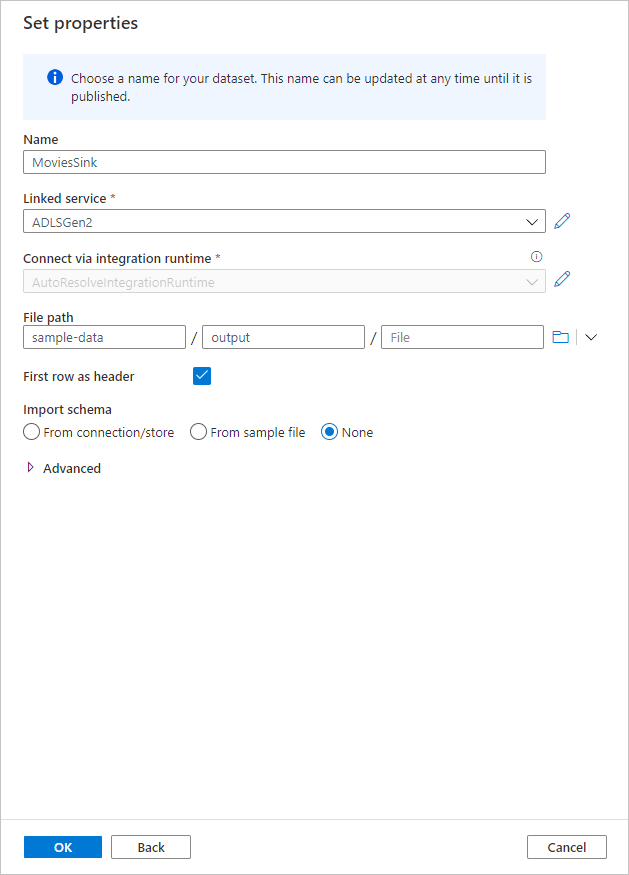
Teraz zakończono tworzenie przepływu danych. Możesz go uruchomić w potoku.
Uruchamianie i monitorowanie Przepływ danych
Potok można debugować przed jego opublikowaniem. W tym kroku wyzwolisz przebieg debugowania potoku przepływu danych. Chociaż podgląd danych nie zapisuje danych, przebieg debugowania zapisuje dane w miejscu docelowym ujścia.
Przejdź do kanwy potoku. Wybierz pozycję Debuguj , aby wyzwolić przebieg debugowania.
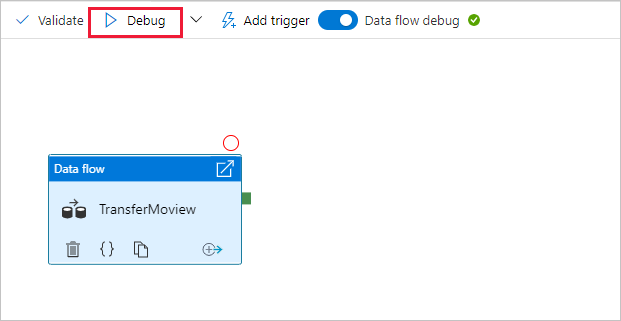
Debugowanie potoku Przepływ danych działań używa aktywnego klastra debugowania, ale inicjowanie nadal trwa co najmniej minutę. Postęp można śledzić za pomocą karty Dane wyjściowe . Po pomyślnym zakończeniu przebiegu wybierz ikonę okularów, aby otworzyć okienko monitorowania.

W okienku monitorowania można zobaczyć liczbę wierszy i czasu spędzonego w każdym kroku transformacji.
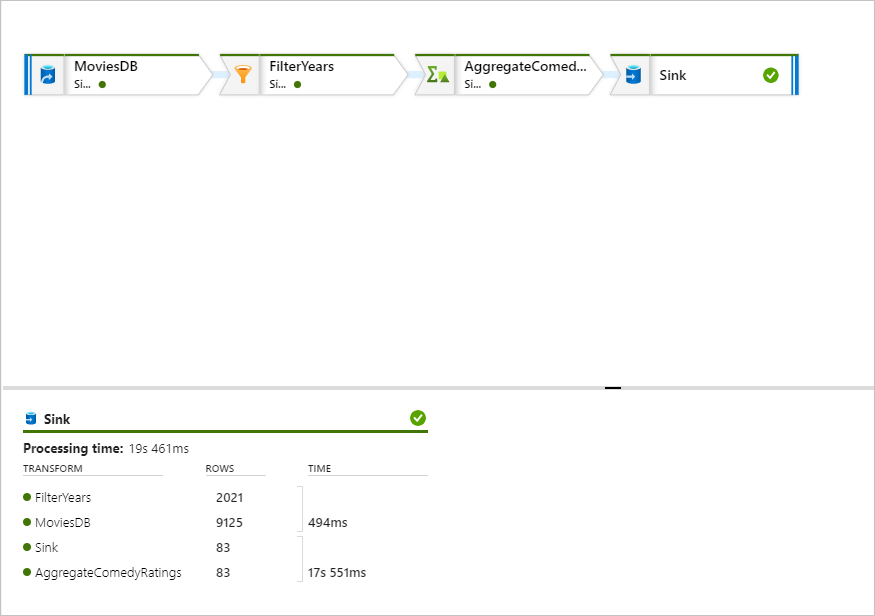
Wybierz przekształcenie, aby uzyskać szczegółowe informacje o kolumnach i partycjonowaniu danych.
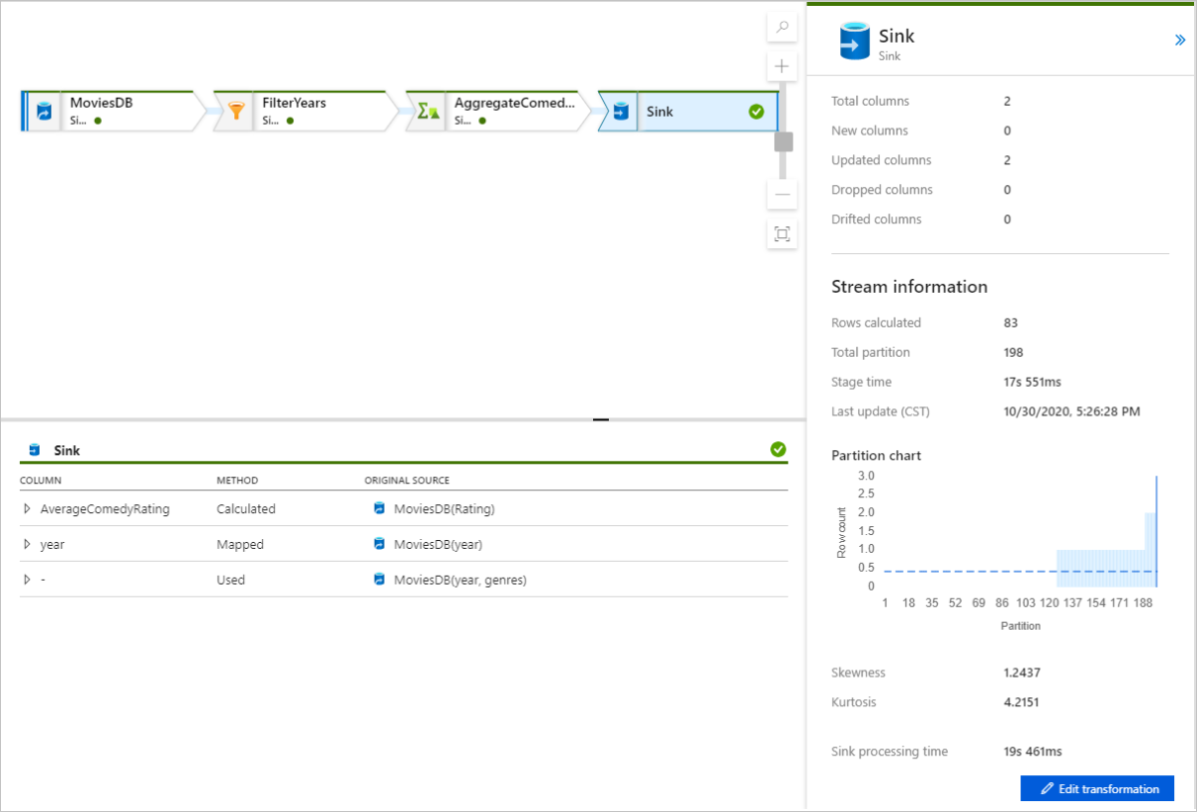
W przypadku poprawnego korzystania z tego przewodnika Szybki start należy zapisać 83 wiersze i 2 kolumny w folderze ujścia. Dane można zweryfikować, sprawdzając magazyn obiektów blob.
Następne kroki
Przejdź do następujących artykułów, aby dowiedzieć się więcej o obsłudze usługi Azure Synapse Analytics: