Migracja danych, etL i ładowanie migracji teradata
Ten artykuł jest drugą częścią siedmioczęściowej serii, która zawiera wskazówki dotyczące migracji z usługi Teradata do usługi Azure Synapse Analytics. Celem tego artykułu są najlepsze rozwiązania dotyczące migracji ETL i ładowania.
Zagadnienia dotyczące migracji danych
Wstępne decyzje dotyczące migracji danych z usługi Teradata
Podczas migracji magazynu danych Teradata należy zadać kilka podstawowych pytań związanych z danymi. Przykład:
Czy nieużywane struktury tabel powinny być migrowane?
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu użytkowników?
Podczas migrowania składnic danych: pozostać fizycznym lub wirtualnym?
W następnych sekcjach omówiono te punkty w kontekście migracji z teradata.
Czy przeprowadzić migrację nieużywanych tabel?
Porada
W starszych systemach nie jest niczym niezwykłym, aby tabele stały się nadmiarowe w czasie — w większości przypadków nie trzeba ich migrować.
Warto migrować tylko tabele, które są używane w istniejącym systemie. Tabele, które nie są aktywne, można zarchiwizować, a nie zmigrować, aby dane są dostępne w razie potrzeby w przyszłości. Najlepiej użyć systemowych metadanych i plików dziennika, a nie dokumentacji, aby określić, które tabele są używane, ponieważ dokumentacja może być nieaktualna.
Jeśli ta opcja jest włączona, tabele i dzienniki wykazu systemu Teradata zawierają informacje, które mogą określić, kiedy dana tabela była ostatnio dostępna— co z kolei może służyć do decydowania, czy tabela jest kandydatem do migracji.
Oto przykładowe zapytanie, które DBC.Tables zawiera datę ostatniego dostępu i ostatniej modyfikacji:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
Jeśli rejestrowanie jest włączone, a historia dziennika jest dostępna, inne informacje, takie jak tekst zapytania SQL, są dostępne w tabeli DBQLogTbl i skojarzonych tabelach rejestrowania. Aby uzyskać więcej informacji, zobacz Historia dziennika teradata.
Jakie jest najlepsze podejście do migracji w celu zminimalizowania ryzyka i wpływu na użytkowników?
To pytanie pojawia się często, ponieważ firmy mogą chcieć zmniejszyć wpływ zmian w modelu danych magazynu danych w celu zwiększenia elastyczności. Firmy często widzą możliwość dalszej modernizacji lub przekształcania danych podczas migracji ETL. Takie podejście niesie ze sobą większe ryzyko, ponieważ zmienia jednocześnie wiele czynników, co utrudnia porównywanie wyników starego systemu z nowym. Wprowadzanie tutaj zmian w modelu danych może również mieć wpływ na zadania ETL nadrzędne lub podrzędne w innych systemach. Ze względu na to ryzyko lepiej jest przeprojektować tę skalę po migracji magazynu danych.
Nawet jeśli model danych został celowo zmieniony w ramach ogólnej migracji, dobrym rozwiązaniem jest migrowanie istniejącego modelu zgodnie z założeniami do Azure Synapse, zamiast ponownego inżynierii na nowej platformie. Takie podejście minimalizuje wpływ na istniejące systemy produkcyjne, a jednocześnie korzysta z wydajności i elastycznej skalowalności platformy Azure w przypadku jednorazowych zadań ponownej inżynierii.
Podczas migracji z usługi Teradata rozważ utworzenie środowiska Teradata na maszynie wirtualnej na platformie Azure jako krok po kroku w procesie migracji.
Porada
Najpierw przeprowadź migrację istniejącego modelu, nawet jeśli w przyszłości zaplanowano zmianę modelu danych.
Używanie wystąpienia teradata maszyny wirtualnej w ramach migracji
Jedną z opcjonalnych metod migracji z lokalnego środowiska Teradata jest wykorzystanie środowiska platformy Azure do utworzenia wystąpienia teradata na maszynie wirtualnej na platformie Azure, posuniętym z docelowym środowiskiem Azure Synapse. Jest to możliwe, ponieważ platforma Azure zapewnia tani magazyn w chmurze i elastyczną skalowalność.
W przypadku tego podejścia standardowe narzędzia Teradata, takie jak Teradata Parallel Data Transporter lub narzędzia replikacji danych innych firm, takie jak Replikacja attunity, mogą służyć do wydajnego przenoszenia podzestawu tabel Teradata, które muszą zostać zmigrowane do wystąpienia maszyny wirtualnej. Następnie wszystkie zadania migracji mogą odbywać się w środowisku platformy Azure. Takie podejście ma kilka korzyści:
Po początkowej replikacji danych zadania migracji nie mają wpływu na system źródłowy.
Środowisko platformy Azure ma znane interfejsy, narzędzia i narzędzia Teradata.
Środowisko platformy Azure zapewnia dostępność przepustowości sieci między lokalnym systemem źródłowym a systemem docelowym chmury.
Narzędzia takie jak Azure Data Factory mogą wydajnie wywoływać narzędzia, takie jak Teradata Parallel Transporter, aby szybko i łatwo migrować dane.
Proces migracji jest aranżowany i kontrolowany całkowicie w środowisku platformy Azure.
Podczas migrowania składnic danych: pozostać fizycznym lub wirtualnym?
Porada
Wirtualizacja składnic danych może zaoszczędzić na magazynie i przetwarzaniu zasobów.
W starszych środowiskach magazynu danych Teradata powszechną praktyką jest tworzenie kilku składnic danych, które mają strukturę zapewniającą dobrą wydajność dla zapytań samoobsługowych ad hoc i raportów dla danego działu lub funkcji biznesowej w organizacji. W związku z tym składninica danych zwykle składa się z podzbioru magazynu danych i zawiera zagregowane wersje danych w postaci, która umożliwia użytkownikom łatwe wykonywanie zapytań o te dane z szybkim czasem odpowiedzi za pomocą przyjaznych dla użytkownika narzędzi do zapytań, takich jak Microsoft Power BI, Tableau lub MicroStrategy. Ten formularz jest zazwyczaj modelem danych wymiarowych. Jednym z zastosowań składnic danych jest uwidocznienie danych w formie użytecznej, nawet jeśli bazowy model danych magazynu jest czymś innym, takim jak magazyn danych.
Można użyć oddzielnych składnic danych dla poszczególnych jednostek biznesowych w organizacji, aby zaimplementować niezawodne systemy zabezpieczeń danych, zezwalając tylko użytkownikom na dostęp do określonych składnic danych, które są dla nich istotne, oraz eliminując, zaciemniając lub anonimizując poufne dane.
Jeśli te składnice danych są implementowane jako tabele fizyczne, będą wymagały dodatkowych zasobów magazynu do ich przechowywania oraz dodatkowego przetwarzania w celu ich regularnego kompilowania i odświeżania. Ponadto dane w składnicy będą aktualne tylko jako ostatnia operacja odświeżania i dlatego mogą być nieodpowiednie dla wysoce niestabilnych pulpitów nawigacyjnych danych.
Porada
Wydajność i skalowalność Azure Synapse umożliwia wirtualizację bez poświęcania wydajności.
Wraz z pojawieniem się stosunkowo tanich skalowalnych architektur MPP, takich jak Azure Synapse, i charakterystycznych cech wydajności takich architektur, może być to, że można zapewnić funkcjonalność składnicy danych bez konieczności tworzenia wystąpienia składnicy jako zestawu tabel fizycznych. Jest to osiągane przez efektywne wirtualizację składnic danych za pośrednictwem widoków SQL w głównym magazynie danych lub za pośrednictwem warstwy wirtualizacji przy użyciu funkcji, takich jak widoki na platformie Azure lub produkty wizualizacji partnerów firmy Microsoft. Takie podejście upraszcza lub eliminuje konieczność dodatkowego przetwarzania magazynu i agregacji oraz zmniejsza ogólną liczbę obiektów bazy danych do zmigrowania.
Istnieje kolejna potencjalna korzyść z tego podejścia. Implementując logikę agregacji i sprzężenia w warstwie wirtualizacji oraz przedstawiając zewnętrzne narzędzia raportowania za pośrednictwem zwirtualizowanego widoku, przetwarzanie wymagane do utworzenia tych widoków jest "wypychane" do magazynu danych, co jest na ogół najlepszym miejscem do uruchamiania sprzężeń, agregacji i innych powiązanych operacji na dużych woluminach danych.
Podstawowymi sterownikami do wybierania implementacji wirtualnej składnic danych w przypadku składnic danych fizycznych są:
Większa elastyczność: wirtualna składninica danych jest łatwiejsza do zmiany niż tabele fizyczne i skojarzone procesy ETL.
Niższy całkowity koszt posiadania: zwirtualizowana implementacja wymaga mniejszej liczby magazynów danych i kopii danych.
Eliminacja zadań ETL w celu migracji i uproszczenia architektury magazynu danych w środowisku zwirtualizowanym.
Wydajność: chociaż fizyczne składnice danych były historycznie bardziej wydajne, produkty wirtualizacji wdrażają teraz inteligentne techniki buforowania w celu ograniczenia ryzyka.
Migracja danych z usługi Teradata
Informacje o danych
Częścią planowania migracji jest szczegółowe zrozumienie ilości danych, które należy migrować, ponieważ może to mieć wpływ na decyzje dotyczące podejścia do migracji. Użyj metadanych systemowych, aby określić miejsce fizyczne zajęte przez "nieprzetworzone dane" w tabelach do zmigrowania. W tym kontekście "dane pierwotne" oznaczają ilość miejsca używanego przez wiersze danych w tabeli, z wyłączeniem narzutów, takich jak indeksy i kompresja. Jest to szczególnie istotne w przypadku największych tabel faktów, ponieważ zwykle będą one składać się z ponad 95% danych.
Możesz uzyskać dokładną liczbę danych do zmigrowania dla danej tabeli, wyodrębniając reprezentatywną próbkę danych — na przykład milion wierszy — do nieskompresowanego, płaskiego pliku danych ASCII. Następnie użyj rozmiaru tego pliku, aby uzyskać średni rozmiar danych pierwotnych na wiersz tej tabeli. Na koniec pomnóż ten średni rozmiar przez łączną liczbę wierszy w pełnej tabeli, aby nadać nieprzetworzonemu rozmiarowi danych dla tabeli. Użyj tego nieprzetworzonego rozmiaru danych w planowaniu.
Zagadnienia dotyczące migracji ETL
Wstępne decyzje dotyczące migracji ETL teradata
Porada
Zaplanuj z wyprzedzeniem podejście do migracji ETL i korzystaj z obiektów platformy Azure tam, gdzie jest to konieczne.
W przypadku przetwarzania ETL/ELT starsze magazyny danych Teradata mogą używać niestandardowych skryptów przy użyciu narzędzi Teradata, takich jak BTEQ i Teradata Parallel Transporter (TPT) lub narzędzi ETL innych firm, takich jak Informatica lub Ab Initio. Czasami magazyny danych Teradata używają kombinacji metod ETL i ELT, które ewoluowały w czasie. Podczas planowania migracji do Azure Synapse należy określić najlepszy sposób wdrożenia wymaganego przetwarzania ETL/ELT w nowym środowisku przy jednoczesnym zminimalizowaniu kosztów i ryzyka. Aby dowiedzieć się więcej na temat przetwarzania ETL i ELT, zobacz Podejście projektowe ELT i ETL.
W poniższych sekcjach omówiono opcje migracji i przedstawiono zalecenia dotyczące różnych przypadków użycia. Ten schemat blokowy zawiera podsumowanie jednego podejścia:
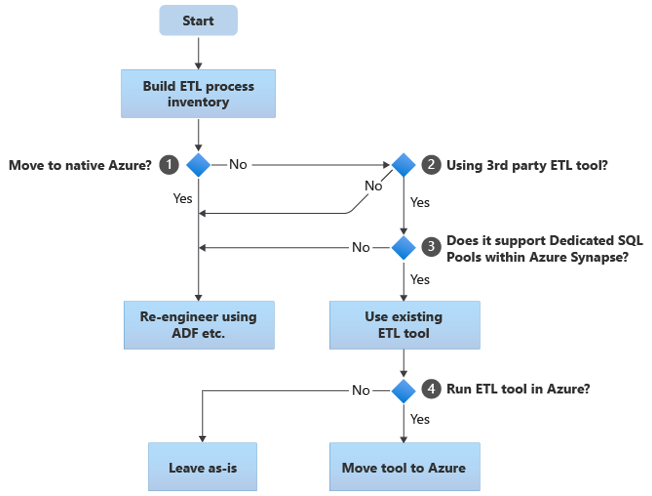
Pierwszym krokiem jest zawsze utworzenie spisu procesów ETL/ELT, które należy zmigrować. Podobnie jak w przypadku innych kroków, istnieje możliwość, że standardowe funkcje platformy Azure "wbudowane" sprawiają, że migracja niektórych istniejących procesów jest niepotrzebna. W celach związanych z planowaniem ważne jest zrozumienie skali migracji do wykonania.
W poprzednim schemacie blokowym decyzja 1 odnosi się do decyzji wysokiego poziomu o tym, czy przeprowadzić migrację do całkowicie natywnego środowiska platformy Azure. Jeśli przenosisz się do całkowicie natywnego środowiska platformy Azure, zalecamy ponowne zaprojektowanie przetwarzania ETL przy użyciu potoków i działań w usłudze Azure Data Factory lub Azure Synapse Pipelines. Jeśli nie przenosisz się do całkowicie natywnego środowiska platformy Azure, decyzja 2 dotyczy tego, czy istniejące narzędzie ETL innej firmy jest już używane.
W środowisku Teradata niektóre lub wszystkie operacje ETL mogą być wykonywane przez niestandardowe skrypty przy użyciu narzędzi specyficznych dla teradata, takich jak BTEQ i TPT. W takim przypadku twoim podejściem powinno być ponowne zaprojektowanie przy użyciu usługi Data Factory.
Porada
Wykorzystanie inwestycji w istniejące narzędzia innych firm w celu zmniejszenia kosztów i ryzyka.
Jeśli narzędzie ETL innej firmy jest już używane, a zwłaszcza jeśli istnieje duża inwestycja w umiejętności lub kilka istniejących przepływów pracy i harmonogramów używa tego narzędzia, decyzja 3 polega na tym, czy narzędzie może efektywnie obsługiwać Azure Synapse jako środowisko docelowe. W idealnym przypadku narzędzie będzie zawierać "natywne" łączniki, które mogą korzystać z obiektów platformy Azure, takich jak PolyBase lub COPY INTO, w celu najbardziej wydajnego ładowania danych. Istnieje sposób wywoływania procesu zewnętrznego, takiego jak PolyBase lub COPY INTO, i przekazywania odpowiednich parametrów. W takim przypadku skorzystaj z istniejących umiejętności i przepływów pracy, Azure Synapse jako nowe środowisko docelowe.
Jeśli zdecydujesz się zachować istniejące narzędzie ETL innej firmy, mogą istnieć korzyści wynikające z uruchamiania tego narzędzia w środowisku platformy Azure (zamiast na istniejącym lokalnym serwerze ETL) i Azure Data Factory obsługiwać ogólną aranżację istniejących przepływów pracy. Jedną z zalet jest to, że mniej danych należy pobrać z platformy Azure, przetworzyć, a następnie przekazać z powrotem na platformę Azure. Dlatego decyzja 4 polega na tym, czy pozostawić istniejące narzędzie uruchomione zgodnie z rzeczywistym działaniem, czy przenieść je do środowiska platformy Azure, aby uzyskać korzyści związane z kosztami, wydajnością i skalowalnością.
Ponowne inżynieryj istniejące skrypty specyficzne dla teradata
Jeśli niektóre lub wszystkie istniejące przetwarzanie ETL/ELT magazynu Teradata jest obsługiwane przez niestandardowe skrypty korzystające z narzędzi specyficznych dla teradata, takich jak BTEQ, MLOAD lub TPT, te skrypty muszą zostać ponownie zakodowane dla nowego środowiska Azure Synapse. Podobnie, jeśli procesy ETL zostały zaimplementowane przy użyciu procedur składowanych w teradata, należy je również ponownie zakodować.
Porada
Spis zadań ETL do zmigrowania powinien zawierać skrypty i procedury składowane.
Niektóre elementy procesu ETL są łatwe do zmigrowania, na przykład przez proste zbiorcze ładowanie danych do tabeli przejściowej z pliku zewnętrznego. Może być nawet możliwe zautomatyzowanie tych części procesu, na przykład przy użyciu technologii PolyBase zamiast szybkiego ładowania lub MLOAD. Jeśli wyeksportowane pliki są parquet, możesz użyć natywnego czytnika Parquet, który jest szybszy niż PolyBase. Inne części procesu, które zawierają dowolne złożone procedury SQL i/lub składowane, zajmie więcej czasu, aby ponownie wykonać inżyniera.
Jednym ze sposobów testowania bazy danych Teradata SQL pod kątem zgodności z Azure Synapse jest przechwycenie niektórych reprezentatywnych instrukcji SQL z dzienników teradata, a następnie prefiks tych zapytań za pomocą EXPLAINpolecenia , a następnie — przy założeniu, że model danych migrowanych podobnie do podobnych w Azure Synapse — uruchom te EXPLAIN instrukcje w Azure Synapse. Każdy niezgodny program SQL wygeneruje błąd, a informacje o błędzie mogą określić skalę zadania odzyskiwania.
Partnerzy firmy Microsoft oferują narzędzia i usługi do migrowania bazy danych Teradata SQL i procedur składowanych do Azure Synapse.
Korzystanie z narzędzi ETL innych firm
Jak opisano w poprzedniej sekcji, w wielu przypadkach istniejący starszy system magazynu danych zostanie już wypełniony i utrzymywany przez produkty ETL innych firm. Aby uzyskać listę partnerów integracji danych firmy Microsoft dla Azure Synapse, zobacz Partnerzy integracji danych.
Ładowanie danych z usługi Teradata
Opcje dostępne podczas ładowania danych z usługi Teradata
Porada
Narzędzia innych firm mogą uprościć i zautomatyzować proces migracji, a tym samym zmniejszyć ryzyko.
Jeśli chodzi o migrację danych z magazynu danych Teradata, istnieją pewne podstawowe pytania związane z ładowaniem danych, które należy rozwiązać. Musisz zdecydować, w jaki sposób dane zostaną fizycznie przeniesione z istniejącego lokalnego środowiska Teradata do Azure Synapse w chmurze oraz które narzędzia będą używane do przenoszenia i ładowania. Rozważ następujące pytania, które zostały omówione w następnych sekcjach.
Czy wyodrębnisz dane do plików, czy przeniesiesz je bezpośrednio za pośrednictwem połączenia sieciowego?
Czy będziesz organizować proces z systemu źródłowego, czy ze środowiska docelowego platformy Azure?
Jakich narzędzi użyjesz do automatyzacji procesu i zarządzania nim?
Transfer danych za pośrednictwem plików lub połączenia sieciowego?
Porada
Zapoznaj się z woluminami danych, które mają zostać zmigrowane, i dostępną przepustowością sieci, ponieważ te czynniki wpływają na decyzję dotyczącą podejścia do migracji.
Po utworzeniu tabel baz danych do zmigrowania w Azure Synapse można przenieść dane, aby wypełnić te tabele ze starszego systemu Teradata i do nowego środowiska. Istnieją dwa podstawowe podejścia:
Wyodrębnianie pliku: wyodrębnianie danych z tabel Teradata do plików prostych, zwykle w formacie CSV, za pośrednictwem BTEQ, Fast Export lub Teradata Parallel Transporter (TPT). Używaj TPT zawsze, gdy jest to możliwe, ponieważ jest to najbardziej wydajne pod względem przepływności danych.
Takie podejście wymaga miejsca, aby wylądować wyodrębnione pliki danych. Miejsce może być lokalne dla źródłowej bazy danych Teradata (jeśli jest dostępna wystarczająca ilość miejsca) lub zdalne w Azure Blob Storage. Najlepszą wydajność jest osiągana, gdy plik jest zapisywany lokalnie, ponieważ pozwala to uniknąć narzutów sieciowych.
Aby zminimalizować wymagania dotyczące magazynu i transferu sieciowego, dobrym rozwiązaniem jest kompresowanie wyodrębnionych plików danych przy użyciu narzędzia takiego jak gzip.
Po wyodrębnieniu pliki proste można przenieść do Azure Blob Storage (pogrupowane z docelowym wystąpieniem Azure Synapse) lub załadować bezpośrednio do Azure Synapse przy użyciu technologii PolyBase lub COPY INTO. Metoda fizycznego przenoszenia danych z lokalnego magazynu do środowiska chmury platformy Azure zależy od ilości danych i dostępnej przepustowości sieci.
Firma Microsoft oferuje różne opcje przenoszenia dużych ilości danych, w tym narzędzia AZCopy do przenoszenia plików między siecią do usługi Azure Storage, usługi Azure ExpressRoute na potrzeby przenoszenia danych zbiorczych za pośrednictwem połączenia z siecią prywatną oraz urządzenia Azure Data Box, na którym pliki są przenoszone do fizycznego urządzenia magazynu, które następnie są wysyłane do centrum danych platformy Azure do załadowania. Aby uzyskać więcej informacji, zobacz Transfer danych.
Bezpośrednie wyodrębnianie i ładowanie w sieci: docelowe środowisko platformy Azure wysyła żądanie wyodrębniania danych, zwykle za pomocą polecenia SQL, do starszego systemu Teradata w celu wyodrębnienia danych. Wyniki są wysyłane przez sieć i ładowane bezpośrednio do Azure Synapse, bez konieczności rozmieszczania danych do plików pośrednich. Czynnikiem ograniczającym w tym scenariuszu jest zwykle przepustowość połączenia sieciowego między bazą danych Teradata a środowiskiem platformy Azure. W przypadku bardzo dużych ilości danych takie podejście może nie być praktyczne.
Istnieje również podejście hybrydowe, które korzysta z obu metod. Na przykład można użyć metody wyodrębniania sieci bezpośredniej dla mniejszych tabel wymiarów i przykładów większych tabel faktów, aby szybko zapewnić środowisko testowe w Azure Synapse. W przypadku dużych tabel faktów historycznych można użyć metody wyodrębniania i transferu plików przy użyciu usługi Azure Data Box.
Orkiestruj z usługi Teradata lub platformy Azure?
Zalecane podejście podczas przechodzenia do Azure Synapse polega na organizowaniu wyodrębniania i ładowania danych ze środowiska platformy Azure przy użyciu Azure Synapse Pipelines lub Azure Data Factory, a także skojarzonych narzędzi, takich jak PolyBase lub COPY INTO, w celu najbardziej wydajnego ładowania danych. To podejście wykorzystuje możliwości platformy Azure i zapewnia łatwą metodę tworzenia potoków ładowania danych wielokrotnego użytku.
Inne zalety tego podejścia obejmują ograniczony wpływ na system Teradata podczas procesu ładowania danych, ponieważ proces zarządzania i ładowania działa na platformie Azure oraz możliwość automatyzacji procesu przy użyciu potoków ładowania danych opartych na metadanych.
Jakich narzędzi można użyć?
Zadanie przekształcania i przenoszenia danych jest podstawową funkcją wszystkich produktów ETL. Jeśli jeden z tych produktów jest już używany w istniejącym środowisku Teradata, użycie istniejącego narzędzia ETL może uprościć migrację danych z teradata do Azure Synapse. W tym podejściu przyjęto założenie, że narzędzie ETL obsługuje Azure Synapse jako środowisko docelowe. Aby uzyskać więcej informacji na temat narzędzi obsługujących Azure Synapse, zobacz Partnerzy integracji danych.
Jeśli używasz narzędzia ETL, rozważ uruchomienie tego narzędzia w środowisku platformy Azure, aby skorzystać z wydajności, skalowalności i kosztów chmury platformy Azure oraz zwolnienia zasobów w centrum danych Teradata. Kolejną korzyścią jest zmniejszenie przenoszenia danych między chmurą a środowiskami lokalnymi.
Podsumowanie
Podsumowując, nasze zalecenia dotyczące migrowania danych i skojarzonych procesów ETL z teradata do Azure Synapse są następujące:
Zaplanuj z wyprzedzeniem, aby zapewnić pomyślne ćwiczenie dotyczące migracji.
Utwórz szczegółowy spis danych i procesów, które mają być migrowane tak szybko, jak to możliwe.
Użyj systemowych metadanych i plików dziennika, aby uzyskać dokładne informacje na temat danych i użycia procesów. Nie polegaj na dokumentacji, ponieważ może być nieaktualna.
Zapoznaj się z woluminami danych, które mają być migrowane, oraz przepustowość sieci między lokalnym centrum danych a środowiskami chmury platformy Azure.
Rozważ użycie wystąpienia teradata na maszynie wirtualnej platformy Azure jako kamienia krokowego w celu odciążania migracji ze starszego środowiska Teradata.
Korzystaj ze standardowych "wbudowanych" funkcji platformy Azure, aby zminimalizować obciążenie migracji.
Identyfikowanie i zrozumienie najbardziej wydajnych narzędzi do wyodrębniania i ładowania danych w środowiskach Teradata i Azure. Użyj odpowiednich narzędzi w każdej fazie procesu.
Użyj obiektów platformy Azure, takich jak Azure Synapse Pipelines lub Azure Data Factory, aby organizować i automatyzować proces migracji przy jednoczesnym zminimalizowaniu wpływu na system Teradata.
Następne kroki
Aby dowiedzieć się więcej na temat operacji dostępu do zabezpieczeń, zobacz następny artykuł w tej serii: Zabezpieczenia, dostęp i operacje na potrzeby migracji teradata.