Minimalizuj problemy z bazą danych SQL na potrzeby migracji oracle
Ten artykuł jest częścią piątej części siedmioczęściowej serii, która zawiera wskazówki dotyczące migracji z bazy danych Oracle do usługi Azure Synapse Analytics. Celem tego artykułu jest najlepsze rozwiązania dotyczące minimalizowania problemów z programem SQL.
Omówienie
Charakterystyka środowisk Oracle
Początkowy produkt bazy danych Oracle, wydany w 1979 r., był komercyjną relacyjną bazą danych SQL dla aplikacji przetwarzania transakcji online (OLTP) — z znacznie niższymi stawkami transakcji niż obecnie. Od tej początkowej wersji środowisko Oracle ewoluowało, aby stało się znacznie bardziej złożone i obejmuje wiele funkcji. Funkcje obejmują architektury klient-serwer, rozproszone bazy danych, przetwarzanie równoległe, analizę danych, wysoką dostępność, magazynowanie danych, techniki przechowywania danych w pamięci i obsługę wystąpień opartych na chmurze.
Napiwek
Oracle zapoczątkowała koncepcję "urządzenia magazynu danych" na początku 2000 roku.
Ze względu na koszt i złożoność utrzymywania i uaktualniania starszych lokalnych środowisk Oracle wielu istniejących użytkowników Oracle chce korzystać z innowacji oferowanych przez środowiska w chmurze. Nowoczesne środowiska chmurowe, takie jak chmura, IaaS i PaaS, umożliwiają delegowanie zadań, takich jak konserwacja infrastruktury i programowanie platformy dla dostawcy chmury.
Wiele magazynów danych, które obsługują złożone zapytania analityczne SQL na dużych woluminach danych, korzystają z technologii Oracle. Te magazyny danych często mają wymiarowy model danych, taki jak schematy gwiazdy lub płatka śniegu, i używają składnic danych dla poszczególnych działów.
Napiwek
Wiele istniejących instalacji Oracle to magazyny danych korzystające z modelu danych wymiarowych.
Połączenie modeli danych SQL i wymiarowych w programie Oracle upraszcza migrację do usługi Azure Synapse, ponieważ koncepcje języka SQL i podstawowego modelu danych można przenosić. Firma Microsoft zaleca przeniesienie istniejącego modelu danych na platformę Azure w celu zmniejszenia ryzyka, nakładu pracy i czasu migracji. Mimo że plan migracji może obejmować zmianę bazowego modelu danych, na przykład przejście z modelu Inmon do magazynu danych, warto początkowo przeprowadzić migrację zgodnie z rzeczywistym działaniem. Po początkowej migracji możesz wprowadzić zmiany w środowisku chmury platformy Azure, aby skorzystać z jej wydajności, elastycznej skalowalności, wbudowanych funkcji i korzyści związanych z kosztami.
Mimo że język SQL jest ustandaryzowany, niektórzy dostawcy czasami implementują zastrzeżone rozszerzenia. W związku z tym podczas migracji mogą wystąpić różnice w języku SQL, które wymagają obejścia w usłudze Azure Synapse.
Wdrażanie migracji opartej na metadanych za pomocą obiektów platformy Azure
Proces migracji można zautomatyzować i zorganizować przy użyciu możliwości środowiska platformy Azure. Takie podejście minimalizuje osiągnięcie wydajności w istniejącym środowisku Oracle, które może już działać blisko pojemności.
Azure Data Factory to oparta na chmurze usługa integracji danych, która obsługuje tworzenie opartych na danych przepływów pracy w chmurze w celu organizowania i automatyzowania przenoszenia danych i przekształcania danych. Za pomocą usługi Data Factory można tworzyć i planować oparte na danych przepływy pracy (potoki), które pozyskują dane z różnych magazynów danych. Usługa Data Factory może przetwarzać i przekształcać dane przy użyciu usług obliczeniowych, takich jak Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics i Azure Machine Learning.
Platforma Azure obejmuje również usługi Azure Database Migration Services , które ułatwiają planowanie i przeprowadzanie migracji ze środowisk, takich jak Oracle. Asystent migracji do programu SQL Server (SSMA) dla firmy Oracle może zautomatyzować migrację baz danych Oracle, w tym w niektórych przypadkach funkcje i kod proceduralny.
Napiwek
Automatyzacja procesu migracji przy użyciu funkcji usługi Azure Data Factory.
Jeśli planujesz używać obiektów platformy Azure, takich jak Data Factory, do zarządzania procesem migracji, najpierw utwórz metadane zawierające listę wszystkich tabel danych, które należy migrować i ich lokalizację.
Różnice języka SQL DDL między bazą danych Oracle i usługą Azure Synapse
Standard ANSI SQL definiuje podstawową składnię poleceń języka Data Definition Language (DDL). Niektóre polecenia DDL, takie jak CREATE TABLE i CREATE VIEW, są wspólne dla rozwiązań Oracle i Azure Synapse, ale zostały rozszerzone w celu zapewnienia funkcji specyficznych dla implementacji, takich jak indeksowanie, dystrybucja tabel i opcje partycjonowania.
Napiwek
Polecenia CREATE TABLE sql DDL i CREATE VIEW mają standardowe podstawowe elementy, ale są również używane do definiowania opcji specyficznych dla implementacji.
W poniższych sekcjach omówiono opcje specyficzne dla oracle, które należy wziąć pod uwagę podczas migracji do usługi Azure Synapse.
Zagadnienia dotyczące tabeli/widoku
Podczas migracji tabel między różnymi środowiskami zazwyczaj tylko nieprzetworzone dane i metadane, które opisują je fizycznie. Inne elementy bazy danych z systemu źródłowego, takie jak indeksy i pliki dziennika, zwykle nie są migrowane, ponieważ mogą być niepotrzebne lub zaimplementowane inaczej w nowym środowisku. Na przykład TEMPORARY opcja w składni oracle CREATE TABLE jest odpowiednikiem prefiksu nazwy tabeli z znakiem # w usłudze Azure Synapse.
Optymalizacje wydajności w środowisku źródłowym, takie jak indeksy, wskazują, gdzie można dodać optymalizację wydajności w nowym środowisku docelowym. Jeśli na przykład indeksy mapowane bitowo są często używane w zapytaniach w źródłowym środowisku Oracle, sugeruje to, że indeks nieklasowany powinien zostać utworzony w usłudze Azure Synapse. Inne natywne techniki optymalizacji wydajności, takie jak replikacja tabel, mogą być bardziej odpowiednie niż proste tworzenie indeksów podobnych do podobnych. Program SSMA for Oracle może udostępniać zalecenia dotyczące migracji dotyczące dystrybucji i indeksowania tabel.
Napiwek
Istniejące indeksy wskazują kandydatów do indeksowania w zmigrowanym magazynie.
Definicje widoków SQL zawierają instrukcje języka DML (SQL Data Manipulation Language), które definiują widok, zazwyczaj z co najmniej jedną SELECT instrukcją. Podczas migracji instrukcji CREATE VIEW weź pod uwagę różnice DML między oracle i Azure Synapse.
Nieobsługiwane typy obiektów bazy danych Oracle
Funkcje specyficzne dla programu Oracle mogą być często zastępowane przez funkcje usługi Azure Synapse. Jednak niektóre obiekty bazy danych Oracle nie są bezpośrednio obsługiwane w usłudze Azure Synapse. Poniższa lista nieobsługiwanych obiektów bazy danych Oracle zawiera opis sposobu osiągnięcia równoważnych funkcji w usłudze Azure Synapse:
Opcje indeksowania: w programie Oracle kilka opcji indeksowania, takich jak indeksy mapowane bitowo, indeksy oparte na funkcjach i indeksy domeny, nie mają bezpośredniego odpowiednika w usłudze Azure Synapse. Chociaż usługa Azure Synapse nie obsługuje tych typów indeksów, można osiągnąć podobny spadek liczby operacji we/wy dysku przy użyciu typów indeksów zdefiniowanych przez użytkownika i/lub partycjonowania Zmniejszenie wydajności operacji we/wy dysku.
Możesz dowiedzieć się, które kolumny są indeksowane i ich typ indeksu, wykonując zapytania dotyczące tabel i widoków wykazu systemu, takich jak
ALL_INDEXES,DBA_INDEXES,USER_INDEXESiDBA_IND_COL. Możesz też wykonywać zapytania dotyczące widoków lubv$object_usagepo włączeniudba_index_usagemonitorowania.Funkcje usługi Azure Synapse, takie jak przetwarzanie zapytań równoległych i buforowanie danych i wyników w pamięci, sprawiają, że prawdopodobnie w aplikacjach magazynu danych jest wymagana mniejsza liczba indeksów w celu osiągnięcia doskonałych celów wydajności.
Tabele klastrowane: tabele Oracle można organizować tak, aby wiersze tabeli, do których często uzyskiwano dostęp (na podstawie wspólnej wartości), są fizycznie przechowywane razem. Ta strategia zmniejsza we/wy dysku podczas pobierania danych. Oracle ma również opcję skrótu klastra dla poszczególnych tabel, która stosuje wartość skrótu do klucza klastra i fizycznie przechowuje wiersze z tą samą wartością skrótu.
W usłudze Azure Synapse możesz uzyskać podobny wynik, partycjonując i/lub używając innych indeksów.
Zmaterializowane widoki: Oracle obsługuje zmaterializowane widoki i zaleca co najmniej jedną z nich dla dużych tabel z wieloma kolumnami, w których tylko kilka kolumn jest regularnie używanych w zapytaniach. Zmaterializowane widoki są automatycznie odświeżane przez system po zaktualizowaniu danych w tabeli podstawowej.
W 2019 r. firma Microsoft ogłosiła, że usługa Azure Synapse będzie obsługiwać zmaterializowane widoki z taką samą funkcjonalnością jak w programie Oracle. Zmaterializowane widoki są teraz funkcją w wersji zapoznawczej w usłudze Azure Synapse.
Wyzwalacze w bazie danych: w programie Oracle wyzwalacz można skonfigurować tak, aby był uruchamiany automatycznie po wystąpieniu zdarzenia wyzwalającego. Wyzwalanie zdarzeń może być następujące:
Instrukcja DML, taka jak
INSERT,UPDATElubDELETE, jest uruchamiana. Jeśli zdefiniowano wyzwalacz, który jest uruchamiany przed instrukcjąINSERTw tabeli klienta, wyzwalacz zostanie wyzwolony raz, zanim nowy wiersz zostanie wstawiony do tabeli klienta.Instrukcja DDL, taka jak
CREATElubALTER, jest uruchamiana. To zdarzenie wyzwalające jest często używane do rejestrowania zmian schematu w celach inspekcji.Zdarzenie systemowe, takie jak uruchamianie lub zamykanie bazy danych Oracle.
Zdarzenie użytkownika, takie jak logowanie lub wylogowywanie.
Usługa Azure Synapse nie obsługuje wyzwalaczy bazy danych Oracle. Można jednak osiągnąć równoważną funkcjonalność przy użyciu usługi Data Factory, chociaż wymaga to refaktoryzacji procesów korzystających z wyzwalaczy.
Synonimy: Firma Oracle obsługuje definiowanie synonimów jako alternatywnych nazw dla kilku typów obiektów bazy danych. Te typy obejmują tabele, widoki, sekwencje, procedury, funkcje składowane, pakiety, zmaterializowane widoki, obiekty schematu klasy Java, obiekty zdefiniowane przez użytkownika lub inne synonimy.
Usługa Azure Synapse obecnie nie obsługuje definiowania synonimów, chociaż jeśli synonim w programie Oracle odwołuje się do tabeli lub widoku, możesz zdefiniować widok w usłudze Azure Synapse tak, aby był zgodny z alternatywną nazwą. Jeśli synonim w programie Oracle odwołuje się do funkcji lub procedury składowanej, możesz zastąpić synonim w usłudze Azure Synapse inną funkcją lub procedurą składowaną, która wywołuje obiekt docelowy.
Typy zdefiniowane przez użytkownika: Firma Oracle obsługuje obiekty zdefiniowane przez użytkownika, które mogą zawierać serię poszczególnych pól, z których każda ma własną definicję i wartości domyślne. Te obiekty można następnie przywoływać w definicji tabeli w taki sam sposób, jak wbudowane typy danych, takie jak
NUMBERlubVARCHAR.Usługa Azure Synapse obecnie nie obsługuje typów zdefiniowanych przez użytkownika. Jeśli dane potrzebne do migracji zawierają typy danych zdefiniowanych przez użytkownika, "spłaszczają" je do konwencjonalnej definicji tabeli lub jeśli są tablicami danych, normalizuj je w oddzielnej tabeli.
Generowanie języka SQL DDL
Istniejące skrypty i CREATE VIEW oracle CREATE TABLE można edytować, aby uzyskać równoważne definicje w usłudze Azure Synapse. W tym celu może być konieczne użycie zmodyfikowanych typów danych i usunięcie lub zmodyfikowanie klauzul specyficznych dla oracle, takich jak TABLESPACE.
Napiwek
Użyj istniejących metadanych Oracle, aby zautomatyzować generowanie i CREATE TABLE CREATE VIEW rozszerzenie DDL dla usługi Azure Synapse.
W środowisku Oracle tabele wykazu systemu określają bieżącą definicję tabeli/widoku. W przeciwieństwie do dokumentacji obsługiwanej przez użytkownika informacje o katalogu systemowym są zawsze kompletne i zsynchronizowane z bieżącymi definicjami tabeli. Dostęp do informacji katalogu systemu można uzyskać za pomocą narzędzi, takich jak Oracle SQL Developer. Program Oracle SQL Developer może wygenerować CREATE TABLE instrukcje DDL, które można edytować w celu zastosowania do równoważnych tabel w usłudze Azure Synapse, jak pokazano na następnym zrzucie ekranu.

Program Oracle SQL Developer zwraca następującą CREATE TABLE instrukcję, która zawiera klauzule specyficzne dla oracle, które należy usunąć. Zamapuj wszystkie nieobsługiwane typy danych przed uruchomieniem zmodyfikowanej CREATE TABLE instrukcji w usłudze Azure Synapse.
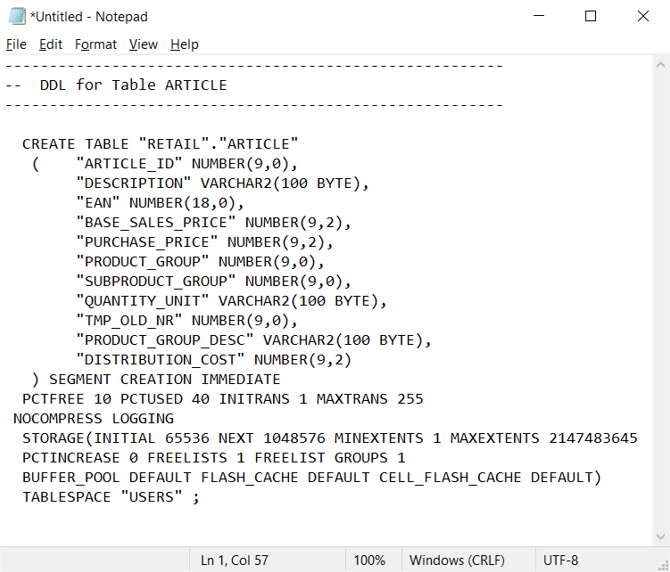
Alternatywnie można automatycznie generować CREATE TABLE instrukcje na podstawie informacji w tabelach wykazu Oracle przy użyciu zapytań SQL, SSMA lub narzędzi migracji innych firm . To podejście jest najszybszym, najbardziej spójnym sposobem generowania CREATE TABLE instrukcji dla wielu tabel.
Napiwek
Narzędzia i usługi innych firm mogą automatyzować zadania mapowania danych.
Zewnętrzni dostawcy oferują narzędzia i usługi do automatyzacji migracji, w tym mapowanie typów danych. Jeśli narzędzie ETL innej firmy jest już używane w środowisku Oracle, użyj tego narzędzia, aby zaimplementować wszelkie wymagane przekształcenia danych.
Różnice między językami SQL DML między oracle i usługą Azure Synapse
Standard ANSI SQL definiuje podstawową składnię poleceń DML, takich jak SELECT, INSERT, UPDATEi DELETE. Mimo że bazy danych Oracle i Azure Synapse obsługują polecenia DDL, w niektórych przypadkach implementują to samo polecenie inaczej.
Napiwek
Standardowe polecenia SELECTDML SQL , INSERTi UPDATE mogą mieć dodatkowe opcje składni w różnych środowiskach bazy danych.
W poniższych sekcjach omówiono polecenia DML specyficzne dla oracle, które należy wziąć pod uwagę podczas migracji do usługi Azure Synapse.
Różnice składni języka SQL DML
Istnieją pewne różnice składni języka SQL DML między bazą danych Oracle SQL i usługą Azure Synapse T-SQL:
DUALtabela: Oracle ma tabelę systemową o nazwieDUAL, która składa się z dokładnie jednej kolumny o nazwiedummyi jednego rekordu o wartościX. TabelaDUALsystemowa jest używana, gdy zapytanie wymaga nazwy tabeli ze względów składniowych, ale zawartość tabeli nie jest potrzebna.Przykładowe zapytanie Oracle używające
DUALtabeli toSELECT sysdate from dual;. Odpowiednik usługi Azure Synapse toSELECT GETDATE();. Aby uprościć migrację języka DML, możesz utworzyć równoważnąDUALtabelę w usłudze Azure Synapse przy użyciu następującego języka DDL.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GONULLvalues:NULLwartość w Oracle jest pustym ciągiem reprezentowanymCHARprzez typ ciągu lubVARCHARdługości0. W usłudze Azure Synapse i większości innych baz danychNULLoznacza coś innego. Należy zachować ostrożność podczas migrowania danych lub podczas migrowania procesów obsługujących lub przechowujące dane, aby upewnić się, żeNULLwartości są obsługiwane spójnie.Składnia sprzężenia zewnętrznego Oracle: chociaż nowsze wersje programu Oracle obsługują składnię sprzężenia zewnętrznego ANSI, starsze systemy Oracle używają zastrzeżonej składni dla sprzężeń zewnętrznych używających znaku plusa (
+) w instrukcji SQL. W przypadku migrowania starszego środowiska Oracle może wystąpić starsza składnia. Na przykład:SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;Równoważna standardowa składnia ANSI to:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;DATEdane: w programie OracleDATEtyp danych może przechowywać zarówno datę, jak i godzinę. Usługa Azure Synapse przechowuje datę i godzinę w osobnychDATEtypach danych ,TIMEiDATETIME. Podczas migrowania kolumn OracleDATEsprawdź, czy przechowują zarówno datę, jak i godzinę, czy tylko datę. Jeśli przechowują tylko datę, zamapuj kolumnę naDATE, w przeciwnym razie naDATETIME.DATEarytmetyka: Oracle obsługuje odejmowanie jednej daty z innej, na przykładSELECT date '2018-12-31' - date '2018-1201' from dual;. W usłudze Azure Synapse można odjąć daty przy użyciuDATEDIFF()funkcji, na przykładSELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle może odjąć liczby całkowite z dat, na przykład
SELECT hire_date, (hire_date-1) FROM employees;. W usłudze Azure Synapse można dodawać lub odejmować liczby całkowite z dat przy użyciuDATEADD()funkcji .Aktualizacje za pośrednictwem widoków: w programie Oracle można uruchamiać operacje wstawiania, aktualizowania i usuwania względem widoku, aby zaktualizować tabelę bazową. W usłudze Azure Synapse uruchamiasz te operacje względem tabeli podstawowej — a nie widoku. Może być konieczne ponowne utworzenie inżyniera przetwarzania ETL, jeśli tabela Oracle zostanie zaktualizowana za pomocą widoku.
Wbudowane funkcje: w poniższej tabeli przedstawiono różnice w składni i użyciu niektórych wbudowanych funkcji.
| Oracle, funkcja | opis | Odpowiednik usługi Synapse |
|---|---|---|
| ADD_MONTHS | Dodaj określoną liczbę miesięcy | DATEADD |
| CAST | Konwertowanie jednego wbudowanego typu danych na inny | CAST |
| DEKODOWANIA | Ocena listy warunków | Wyrażenie CASE |
| EMPTY_BLOB | Tworzenie pustej wartości obiektu BLOB | 0x stała (pusty ciąg binarny) |
| EMPTY_CLOB | Tworzenie pustej wartości CLOB lub NCLOB | '' (pusty ciąg) |
| INITCAP | Wielką literą każdego wyrazu | Funkcja zdefiniowana przez użytkownika |
| INSTR | Znajdowanie położenia podciągów w ciągu | CHARINDEX |
| LAST_DAY | Pobieranie ostatniej daty miesiąca | EOMONTH |
| LENGTH | Pobieranie długości ciągu w znakach | LEN |
| LPAD | Ciąg okienka po lewej stronie do określonej długości | Wyrażenie przy użyciu funkcji REPLIKOWANIE, PRAWO i LEWA |
| MOD | Pobierz pozostałą część dzielenia jednej liczby przez inną | % operator |
| MONTHS_BETWEEN | Pobieranie liczby miesięcy między dwiema datami | DATEDIFF |
| NVL | Zamień na NULL wyrażenie |
ISNULL |
| SUBSTR | Zwracanie podciągów z ciągu | SUBSTRING |
| TO_CHAR dla daty/godziny | Konwertowanie daty/godziny na ciąg | NAWRÓCIĆ |
| TO_DATE | Konwertowanie ciągu na data/godzina | NAWRÓCIĆ |
| PRZETŁUMACZ | Podstawianie jeden do jednego znaku | Wyrażenia używające funkcji REPLACE lub zdefiniowanej przez użytkownika |
| TRIM | Przycinanie znaków wiodących lub końcowych | LTRIM i RTRIM |
| TRUNC dla daty/godziny | Obcinanie daty/godziny | Wyrażenia korzystające z funkcji KONWERTUJ |
| UNISTR | Konwertowanie punktów kodu Unicode na znaki | Wyrażenia korzystające z NCHAR |
Funkcje, procedury składowane i sekwencje
Podczas migracji magazynu danych ze środowiska dojrzałego, takiego jak Oracle, prawdopodobnie trzeba migrować elementy inne niż proste tabele i widoki. W przypadku funkcji, procedur składowanych i sekwencji sprawdź, czy narzędzia w środowisku platformy Azure mogą zastąpić ich funkcjonalność, ponieważ zwykle bardziej wydajne jest używanie wbudowanych narzędzi platformy Azure niż ponowne kodowanie funkcji Oracle.
W ramach fazy przygotowania utwórz spis obiektów, które muszą zostać zmigrowane, zdefiniuj metodę ich obsługi i przydziel odpowiednie zasoby w planie migracji.
Narzędzia firmy Microsoft, takie jak SSMA dla oracle i Azure Database Migration Services, lub produkty i usługi migracji innych firm , mogą zautomatyzować migrację funkcji, procedur składowanych i sekwencji.
Napiwek
Produkty i usługi innych firm mogą zautomatyzować migrację elementów innych niż dane.
W poniższych sekcjach omówiono migrację funkcji, procedur składowanych i sekwencji.
Funkcje
Podobnie jak w przypadku większości produktów baz danych, oracle obsługuje funkcje systemowe i zdefiniowane przez użytkownika w ramach implementacji JĘZYKA SQL. Podczas migracji starszej platformy bazy danych do usługi Azure Synapse zwykle można migrować typowe funkcje systemowe bez konieczności zmiany. Niektóre funkcje systemowe mogą mieć nieco inną składnię, ale można zautomatyzować wszelkie wymagane zmiany.
W przypadku funkcji systemowych Oracle lub dowolnych funkcji zdefiniowanych przez użytkownika, które nie mają odpowiedników w usłudze Azure Synapse, zakoduj ponownie te funkcje przy użyciu docelowego języka środowiska. Funkcje zdefiniowane przez użytkownika oracle są kodowane w języku PL/SQL, Java lub C. Usługa Azure Synapse używa języka Transact-SQL do implementowania funkcji zdefiniowanych przez użytkownika.
Procedury składowane
Większość nowoczesnych produktów baz danych obsługuje procedury przechowywania w bazie danych. Firma Oracle udostępnia język PL/SQL w tym celu. Procedura składowana zwykle zawiera zarówno instrukcje SQL, jak i logikę proceduralną oraz zwraca dane lub stan.
Usługa Azure Synapse obsługuje procedury składowane przy użyciu języka T-SQL, dlatego należy ponownie zakodować wszystkie zmigrowane procedury składowane w języku T-SQL.
Sekwencje
W programie Oracle sekwencja jest nazwanym obiektem bazy danych utworzonym przy użyciu polecenia CREATE SEQUENCE. Sekwencja udostępnia unikatowe wartości liczbowe za pomocą CURRVAL metod i NEXTVAL . Wygenerowane unikatowe liczby można użyć jako wartości klucza zastępczego dla kluczy podstawowych. Usługa Azure Synapse nie implementuje CREATE SEQUENCEmetody , ale można zaimplementować sekwencje przy użyciu IDENTITY kolumn lub kodu SQL, który generuje następny numer sekwencji w serii.
Używanie narzędzia EXPLAIN do sprawdzania poprawności starszej wersji bazy danych SQL
Napiwek
Użyj rzeczywistych zapytań z istniejących dzienników zapytań systemowych, aby znaleźć potencjalne problemy z migracją.
Przy założeniu, że model danych podobnych do podobnych w usłudze Azure Synapse ma te same nazwy tabel i kolumn, jednym ze sposobów testowania starszej wersji bazy danych Oracle SQL pod kątem zgodności z usługą Azure Synapse jest:
- Przechwyć niektóre reprezentatywne instrukcje SQL ze starszych dzienników historii zapytań systemowych.
- Prefiks tych zapytań za pomocą instrukcji
EXPLAIN. - Uruchom instrukcje
EXPLAINw usłudze Azure Synapse.
Każdy niezgodny program SQL wygeneruje błąd, a informacje o błędzie mogą służyć do określenia skali zadania ponownego generowania. Takie podejście nie wymaga załadowania żadnych danych do środowiska platformy Azure. Wystarczy utworzyć odpowiednie tabele i widoki.
Podsumowanie
Istniejące starsze instalacje Oracle są zwykle implementowane w sposób, który sprawia, że migracja do usługi Azure Synapse jest stosunkowo prosta. Oba środowiska używają języka SQL do obsługi zapytań analitycznych na dużych woluminach danych i zazwyczaj używają jakiejś formy modelu danych wymiarowych. Te czynniki sprawiają, że instalacje Oracle są dobrym kandydatem do migracji do usługi Azure Synapse.
Podsumowując, nasze zalecenia dotyczące minimalizowania zadania migracji kodu SQL z bazy danych Oracle do usługi Azure Synapse to:
Przeprowadź migrację istniejącego modelu danych w taki sposób, aby zminimalizować ryzyko, nakład pracy i czas migracji, nawet jeśli zaplanowano inny model danych, taki jak magazyn danych.
Zapoznaj się z różnicami między implementacją bazy danych Oracle SQL i implementacją usługi Azure Synapse.
Użyj metadanych i dzienników zapytań z istniejącej implementacji Oracle, aby ocenić wpływ zmiany środowiska. Zaplanuj podejście, aby wyeliminować różnice.
Automatyzacja procesu migracji w celu zminimalizowania ryzyka, nakładu pracy i czasu migracji. Możesz użyć narzędzi firmy Microsoft, takich jak Azure Database Migration Services i SSMA.
Rozważ użycie specjalistycznych narzędzi i usług innych firm w celu usprawnienia migracji.
Następne kroki
Aby dowiedzieć się więcej na temat narzędzi firmy Microsoft i innych firm, zobacz następny artykuł z tej serii: Narzędzia do migracji magazynu danych Oracle do usługi Azure Synapse Analytics.