Samouczek: analiza tekstu z usługami Azure AI
Z tego samouczka dowiesz się, jak używać analiza tekstu do analizowania tekstu bez struktury w usłudze Azure Synapse Analytics. analiza tekstu to usługi sztucznej inteligencji platformy Azure, które umożliwiają wyszukiwanie tekstu i analizę tekstu za pomocą funkcji przetwarzania języka naturalnego (NLP).
W tym samouczku pokazano używanie analizy tekstu z usługą SynapseML w celu:
- Wykrywanie etykiet tonacji na poziomie zdania lub dokumentu
- Identyfikowanie języka dla danego tekstu wejściowego
- Rozpoznawanie jednostek z tekstu za pomocą linków do dobrze znanego baza wiedzy
- Wyodrębnianie kluczowych fraz z tekstu
- Identyfikowanie różnych jednostek w tekście i kategoryzowanie ich do wstępnie zdefiniowanych klas lub typów
- Identyfikowanie i redagowanie poufnych jednostek w danym tekście
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Obszar roboczy usługi Azure Synapse Analytics z kontem magazynu usługi Azure Data Lake Storage Gen2 skonfigurowanym jako magazyn domyślny. Musisz być współautorem danych obiektu blob usługi Storage w systemie plików usługi Data Lake Storage Gen2, z którym pracujesz.
- Pula platformy Spark w obszarze roboczym usługi Azure Synapse Analytics. Aby uzyskać szczegółowe informacje, zobacz Tworzenie puli Spark w usłudze Azure Synapse.
- Kroki wstępnego konfigurowania opisane w samouczku Konfigurowanie usług azure AI w usłudze Azure Synapse.
Rozpocznij
Otwórz program Synapse Studio i utwórz nowy notes. Aby rozpocząć, zaimportuj usługę SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Konfigurowanie analizy tekstu
Użyj połączonej analizy tekstu skonfigurowanej w krokach wstępnej konfiguracji.
linked_service_name = "<Your linked service for text analytics>"
Tonacja tekstu
Analiza tonacji tekstu umożliwia wykrywanie etykiet tonacji (takich jak "negatywne", "neutralne" i "pozytywne") oraz wyniki ufności na poziomie zdania i dokumentu. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Oczekiwane wyniki
| text | Sentyment |
|---|---|
| Jestem dziś bardzo szczęśliwy, to słoneczne! | positive |
| Jestem sfrustrowany tym ruchem w godzinach szczytu | negative |
| Usługi sztucznej inteligencji platformy Azure na platformie Spark są złe | neutral |
Detektor języka
Detektor języka ocenia wprowadzanie tekstu dla każdego dokumentu i zwraca identyfikatory języka z wynikiem wskazującym siłę analizy. Ta możliwość jest przydatna w przypadku magazynów zawartości przechowujących dowolne teksty, których język nie jest znany. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Oczekiwane wyniki
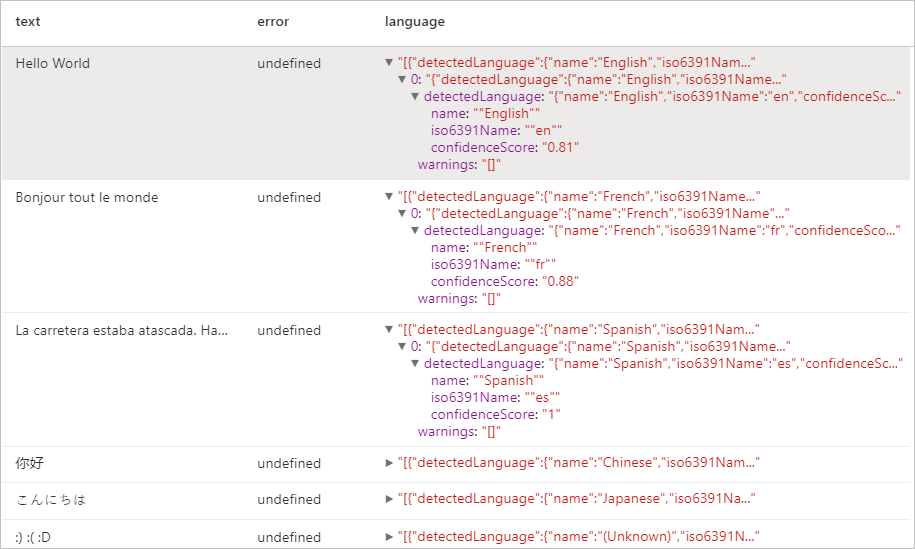
Detektor jednostek
Wykrywacz jednostek zwraca listę rozpoznanych jednostek z linkami do dobrze znanego baza wiedzy. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Oczekiwane wyniki
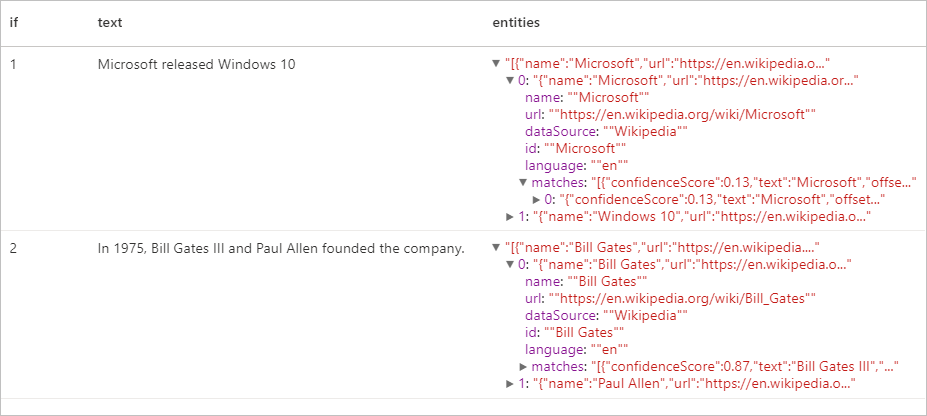
Moduł wyodrębniania kluczowych fraz
Wyodrębnianie kluczowych fraz ocenia tekst bez struktury i zwraca listę kluczowych fraz. Ta możliwość jest przydatna, jeśli chcesz szybko zidentyfikować główne tematy w kolekcji dokumentów. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Oczekiwane wyniki
| text | keyPhrases |
|---|---|
| Cześć ludzie. To jest jakiś tekst wejściowy, który kocham. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Rozpoznawanie jednostek nazwanych
Rozpoznawanie jednostek nazwanych (NER) to możliwość identyfikowania różnych jednostek w tekście i kategoryzowania ich w wstępnie zdefiniowanych klas lub typów, takich jak: osoba, lokalizacja, zdarzenie, produkt i organizacja. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Oczekiwane wyniki
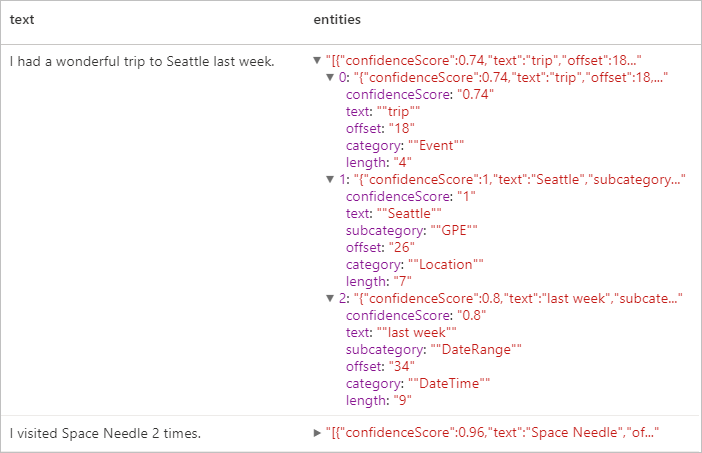
Dane osobowe (PII) w wersji 3.1
Funkcja pii jest częścią NER i może identyfikować i redagować poufne jednostki w tekście, które są skojarzone z osobą indywidualną, takie jak: numer telefonu, adres e-mail, adres e-mail, adres wysyłkowy, numer paszportu. Aby uzyskać listę obsługiwanych języków, zobacz Obsługiwane języki w interfejsie API analiza tekstu.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Oczekiwane wyniki
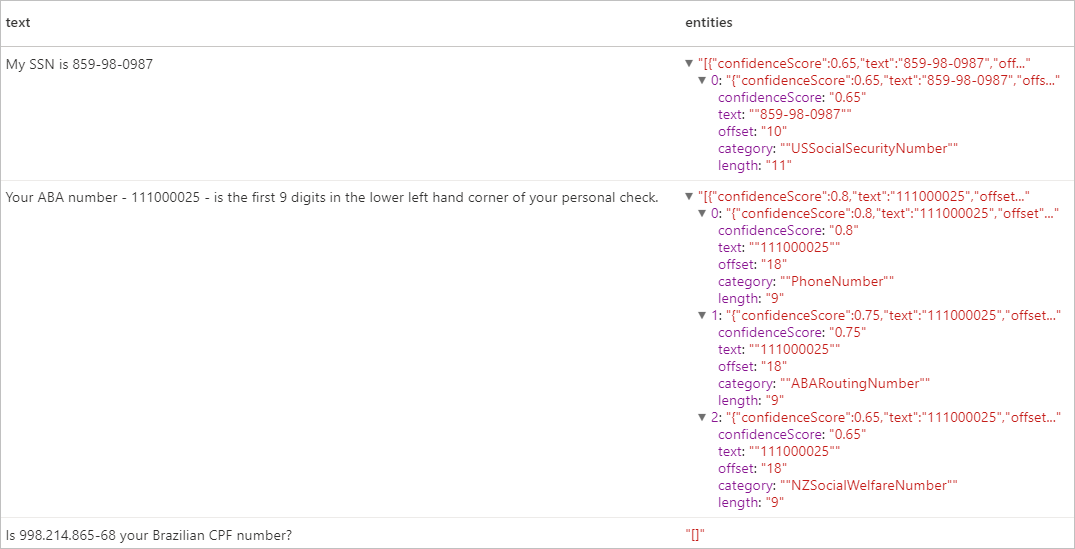
Czyszczenie zasobów
Aby upewnić się, że wystąpienie platformy Spark jest wyłączone, zakończ wszystkie połączone sesje (notesy). Pula zostanie zamknięta po osiągnięciu czasu bezczynności określonego w puli platformy Apache Spark. Możesz również wybrać pozycję Zatrzymaj sesję na pasku stanu w prawym górnym rogu notesu.
