Samouczek: trenowanie modelu uczenia maszynowego bez kodu (przestarzałe)
Możesz wzbogacić dane w tabelach platformy Spark przy użyciu nowych modeli uczenia maszynowego, które trenujesz przy użyciu zautomatyzowanego uczenia maszynowego. W usłudze Azure Synapse Analytics możesz wybrać tabelę Spark w obszarze roboczym, która będzie używana jako zestaw danych szkoleniowych do tworzenia modeli uczenia maszynowego, i możesz to zrobić w środowisku bez użycia kodu.
Z tego samouczka dowiesz się, jak trenować modele uczenia maszynowego przy użyciu wolnego od kodu środowiska w programie Synapse Studio. Usługa Synapse Studio to funkcja usługi Azure Synapse Analytics.
Użyjesz zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning zamiast ręcznie kodować środowisko. Typ trenowanego modelu zależy od problemu, który próbujesz rozwiązać. W tym samouczku użyjesz modelu regresji, aby przewidzieć taryfy taksówek z zestawu danych taksówek w Nowym Jorku.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Ostrzeżenie
- Od 29 września 2023 r. usługa Azure Synapse przestanie obsługiwać oficjalne środowiska uruchomieniowe platformy Spark 2.4. Po 29 września 2023 r. nie będziemy zwracać się do żadnych biletów pomocy technicznej związanych z platformą Spark 2.4. W przypadku usterek lub poprawek zabezpieczeń platformy Spark 2.4 nie będzie dostępny potok wydania. Użycie platformy Spark 2.4 po dacie redukcji pomocy technicznej jest podejmowane na własne ryzyko. Zdecydowanie odradzamy jego dalsze wykorzystanie ze względu na potencjalne obawy dotyczące zabezpieczeń i funkcjonalności.
- W ramach procesu wycofywania dla platformy Apache Spark 2.4 chcemy powiadomić Cię, że rozwiązanie AutoML w usłudze Azure Synapse Analytics również będzie przestarzałe. Obejmuje to zarówno interfejs niskiego kodu, jak i interfejsy API używane do tworzenia wersji próbnych rozwiązania AutoML za pomocą kodu.
- Należy pamiętać, że funkcje rozwiązania AutoML były dostępne wyłącznie za pośrednictwem środowiska uruchomieniowego platformy Spark 2.4.
- W przypadku klientów, którzy chcą nadal korzystać z funkcji automatycznego uczenia maszynowego, zalecamy zapisanie danych na koncie usługi Azure Data Lake Storage Gen2 (ADLSg2). Z tego miejsca możesz bezproblemowo uzyskać dostęp do środowiska automatycznego uczenia maszynowego za pośrednictwem usługi Azure Machine Learning (AzureML). Więcej informacji na temat tego obejścia jest dostępne tutaj.
Wymagania wstępne
- Obszar roboczy usługi Azure Synapse Analytics. Upewnij się, że ma ono konto magazynu usługi Azure Data Lake Storage Gen2 skonfigurowane jako magazyn domyślny. W przypadku systemu plików usługi Data Lake Storage Gen2, z którym pracujesz, upewnij się, że jesteś współautorem danych obiektu blob usługi Storage.
- Pula platformy Apache Spark (wersja 2.4) w obszarze roboczym usługi Azure Synapse Analytics. Aby uzyskać szczegółowe informacje, zobacz Szybki start: tworzenie bezserwerowej puli platformy Apache Spark przy użyciu programu Synapse Studio.
- Połączona usługa Azure Machine Learning w obszarze roboczym usługi Azure Synapse Analytics. Aby uzyskać szczegółowe informacje, zobacz Szybki start: tworzenie nowej połączonej usługi Azure Machine Learning w usłudze Azure Synapse Analytics.
Zaloguj się do witryny Azure Portal.
Zaloguj się w witrynie Azure Portal.
Tworzenie tabeli Platformy Spark dla zestawu danych trenowania
Na potrzeby tego samouczka potrzebna jest tabela Platformy Spark. Poniższy notes tworzy jeden:
Pobierz notes Create-Spark-Table-NYCTaxi- Data.ipynb.
Zaimportuj notes do programu Synapse Studio.
Wybierz pulę Spark, której chcesz użyć, a następnie wybierz pozycję Uruchom wszystko. Ten krok pobiera dane dotyczące taksówek w Nowym Jorku z otwartego zestawu danych i zapisuje dane w domyślnej bazie danych Platformy Spark.

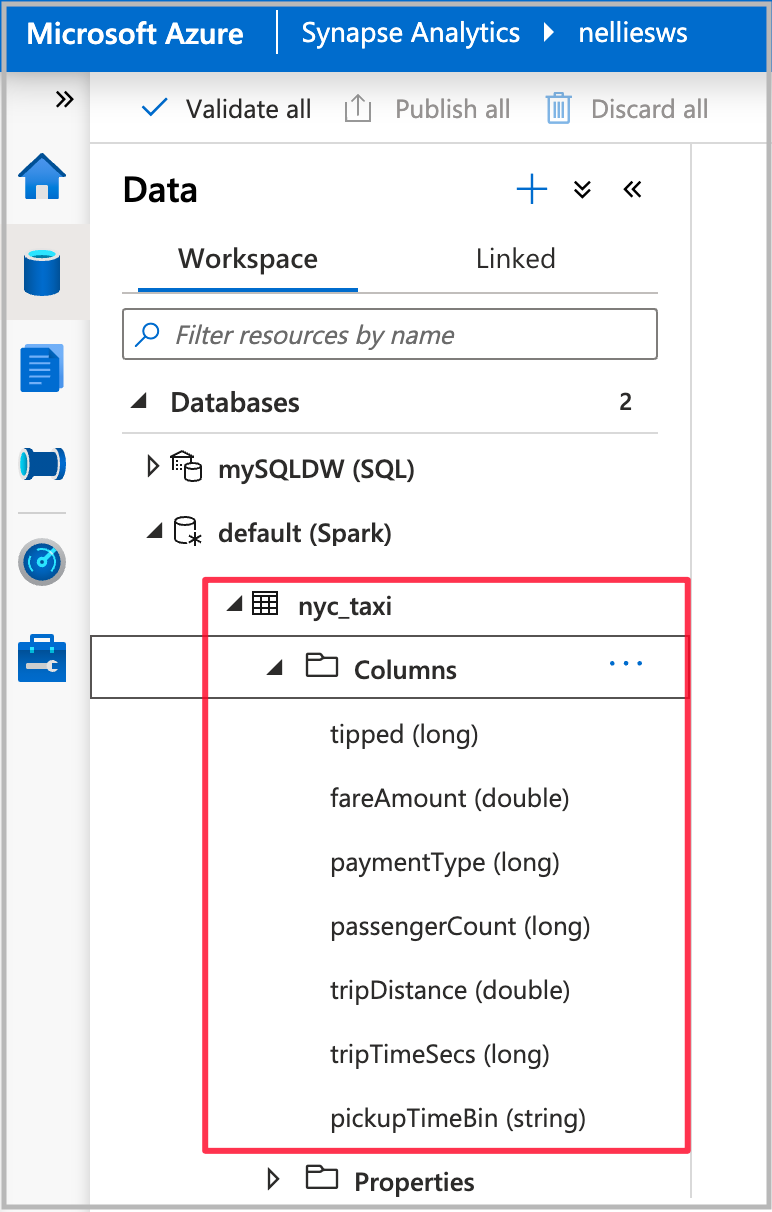
Po zakończeniu uruchamiania notesu zostanie wyświetlona nowa tabela Spark w domyślnej bazie danych Spark. W obszarze Dane znajdź tabelę o nazwie nyc_taxi.
Otwieranie kreatora zautomatyzowanego uczenia maszynowego
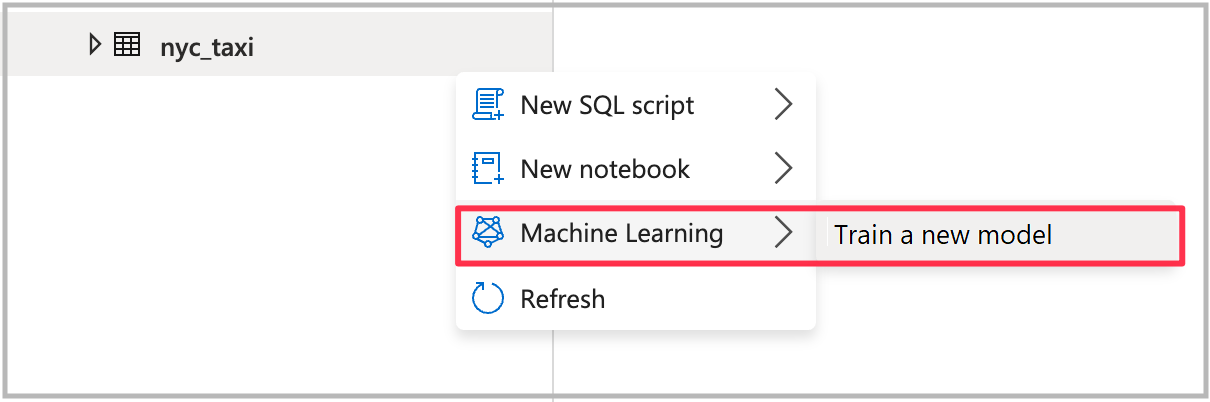
Aby otworzyć kreatora, kliknij prawym przyciskiem myszy tabelę Spark utworzoną w poprzednim kroku. Następnie wybierz pozycję Machine Learning>Train a new model (Uczenie nowego modelu).
Wybierz typ modelu
Wybierz typ modelu uczenia maszynowego dla eksperymentu na podstawie pytania, na które próbujesz odpowiedzieć. Ponieważ wartość, którą próbujesz przewidzieć, to liczba (taryfy taksówek), wybierz tutaj pozycję Regresja . Następnie wybierz pozycję Kontynuuj.
Konfigurowanie eksperymentu
Podaj szczegóły konfiguracji tworzenia eksperymentu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning. Ten przebieg trenuje wiele modeli. Najlepszy model z pomyślnego uruchomienia jest zarejestrowany w rejestrze modeli usługi Azure Machine Learning.
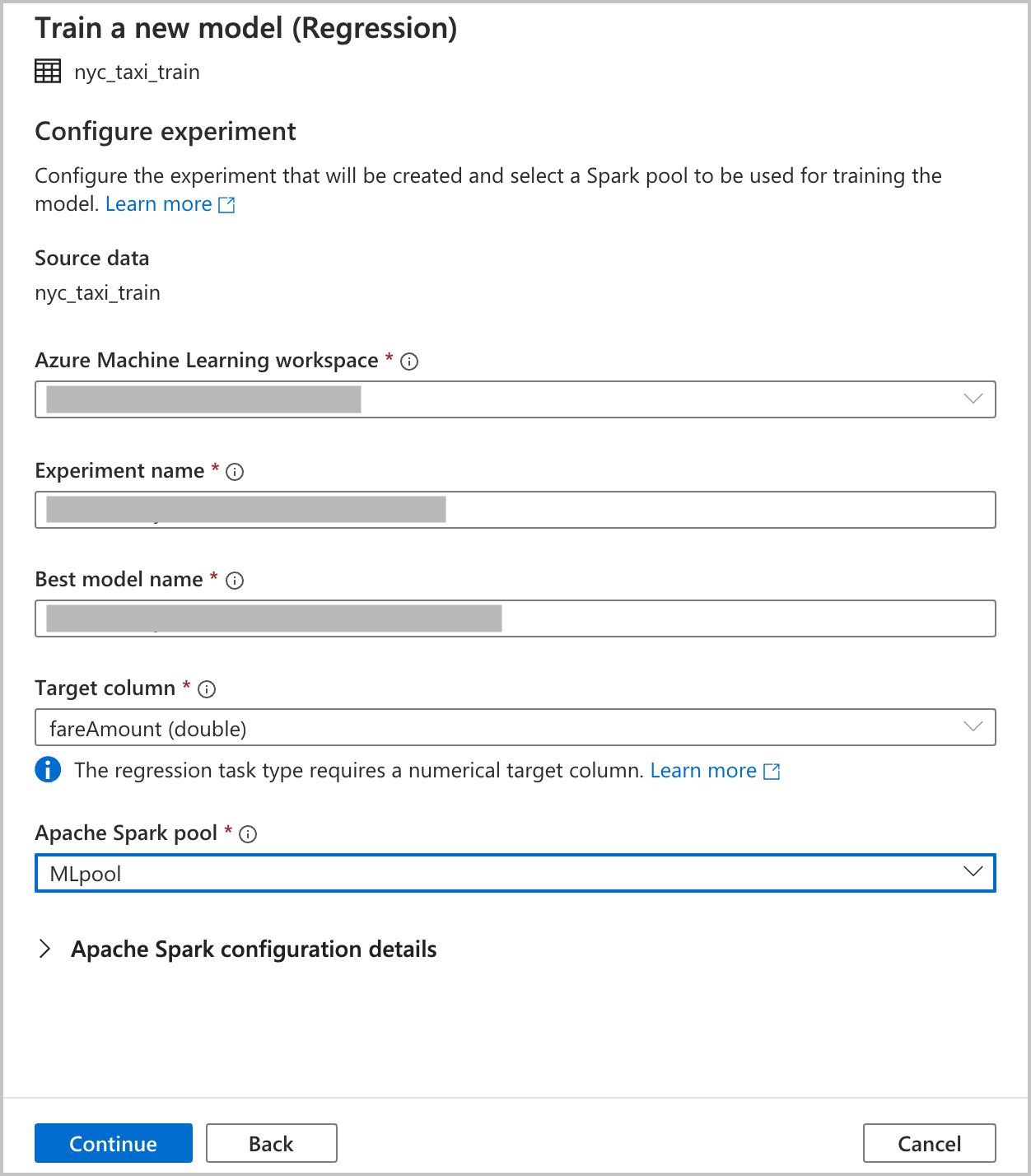
Obszar roboczy usługi Azure Machine Learning: obszar roboczy usługi Azure Machine Learning jest wymagany do utworzenia przebiegu eksperymentu zautomatyzowanego uczenia maszynowego. Musisz również połączyć obszar roboczy usługi Azure Synapse Analytics z obszarem roboczym usługi Azure Machine Learning przy użyciu połączonej usługi. Po spełnieniu wszystkich wymagań wstępnych możesz określić obszar roboczy usługi Azure Machine Learning, którego chcesz użyć na potrzeby tego zautomatyzowanego przebiegu.
Nazwa eksperymentu: określ nazwę eksperymentu. Po przesłaniu przebiegu zautomatyzowanego uczenia maszynowego należy podać nazwę eksperymentu. Informacje dotyczące przebiegu są przechowywane w ramach tego eksperymentu w obszarze roboczym usługi Azure Machine Learning. To środowisko domyślnie tworzy nowy eksperyment i generuje proponowaną nazwę, ale można również podać nazwę istniejącego eksperymentu.
Najlepsza nazwa modelu: określ nazwę najlepszego modelu z przebiegu zautomatyzowanego. Najlepszy model otrzymuje tę nazwę i jest zapisywany w rejestrze modeli usługi Azure Machine Learning automatycznie po tym uruchomieniu. Przebieg zautomatyzowanego uczenia maszynowego tworzy wiele modeli uczenia maszynowego. Na podstawie podstawowej metryki wybranej w późniejszym kroku można porównać te modele i wybrać najlepszy model.
Kolumna docelowa: jest to, co model zostanie wytrenowany do przewidywania. Wybierz kolumnę w zestawie danych zawierającym dane, które chcesz przewidzieć. Na potrzeby tego samouczka wybierz kolumnę
fareAmountliczbową jako kolumnę docelową.Pula platformy Spark: określ pulę platformy Spark, której chcesz użyć na potrzeby przebiegu eksperymentu zautomatyzowanego. Obliczenia są uruchamiane w określonej puli.
Szczegóły konfiguracji platformy Spark: oprócz puli Spark masz możliwość podania szczegółów konfiguracji sesji.
Wybierz Kontynuuj.
Konfigurowanie modelu
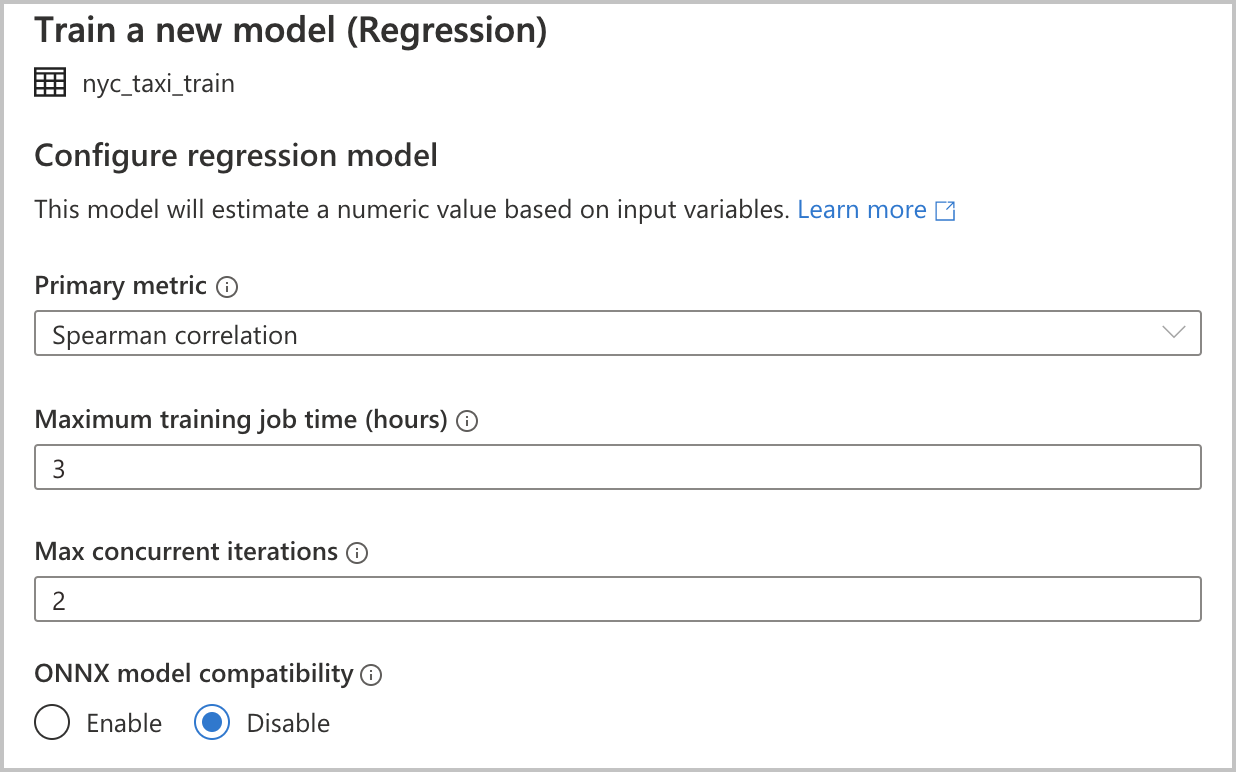
Ponieważ wybrano opcję Regresja jako typ modelu w poprzedniej sekcji, dostępne są następujące konfiguracje (są one również dostępne dla typu modelu klasyfikacji ):
Podstawowa metryka: wprowadź metryka, która mierzy, jak dobrze działa model. Ta metryka służy do porównywania różnych modeli utworzonych w zautomatyzowanym przebiegu i określania, który model był najlepiej wykonywany.
Czas zadania trenowania (godziny): określ maksymalny czas(w godzinach) dla eksperymentu do uruchamiania i trenowania modeli. Należy pamiętać, że można również podać wartości mniejsze niż 1 (na przykład 0,5).
Maksymalna liczba iteracji współbieżnych: wybierz maksymalną liczbę iteracji uruchamianych równolegle.
Zgodność modelu ONNX: jeśli włączysz tę opcję, modele trenowane przez zautomatyzowane uczenie maszynowe są konwertowane na format ONNX. Jest to szczególnie istotne, jeśli chcesz użyć modelu do oceniania w pulach SQL usługi Azure Synapse Analytics.
Wszystkie te ustawienia mają wartość domyślną, którą można dostosować.
Uruchamianie przebiegu
Po zakończeniu wszystkich wymaganych konfiguracji można uruchomić automatyczne uruchamianie. Możesz utworzyć przebieg bezpośrednio, wybierając pozycję Utwórz przebieg — spowoduje to uruchomienie bez kodu. Alternatywnie, jeśli wolisz kod, możesz wybrać pozycję Otwórz w notesie — spowoduje to otwarcie notesu zawierającego kod, który tworzy przebieg, aby można było wyświetlić kod i uruchomić samodzielnie.

Uwaga
Jeśli wybrano opcję Prognozowanie szeregów czasowych jako typ modelu w poprzedniej sekcji, musisz wprowadzić dodatkowe konfiguracje. Prognozowanie nie obsługuje również zgodności modelu ONNX.
Bezpośrednie tworzenie przebiegu
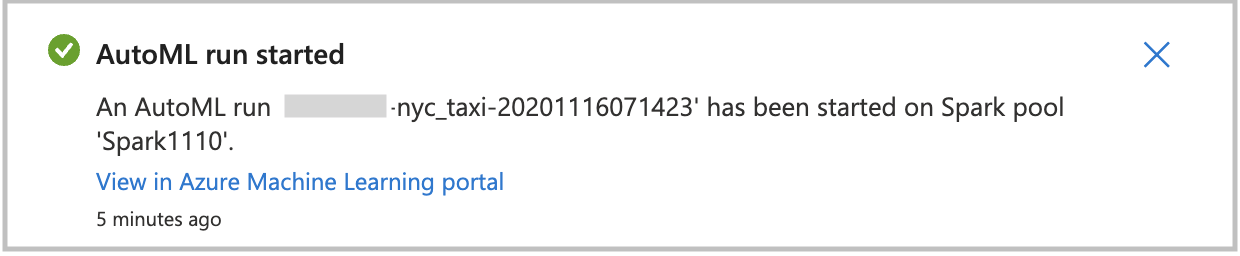
Aby uruchomić automatyczne uczenie maszynowe bezpośrednio, wybierz pozycję Utwórz uruchom. Zostanie wyświetlone powiadomienie wskazujące, że przebieg jest uruchamiany. Następnie zostanie wyświetlone kolejne powiadomienie wskazujące powodzenie. Możesz również sprawdzić stan w usłudze Azure Machine Learning, wybierając link w powiadomieniu.
Tworzenie przebiegu za pomocą notesu
Aby wygenerować notes, wybierz pozycję Otwórz w notesie. Daje to możliwość dodania ustawień lub zmodyfikowania w inny sposób kodu dla przebiegu zautomatyzowanego uczenia maszynowego. Gdy wszystko będzie gotowe do uruchomienia kodu, wybierz pozycję Uruchom wszystko.

Monitorowanie przebiegu
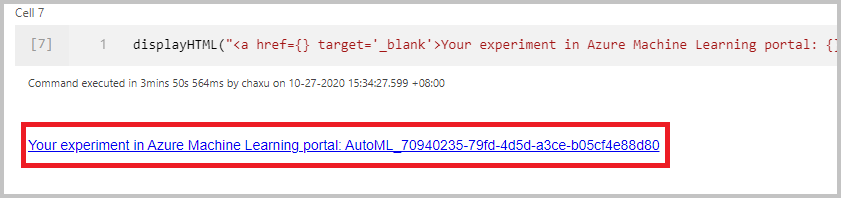
Po pomyślnym przesłaniu przebiegu zostanie wyświetlony link do przebiegu eksperymentu w obszarze roboczym usługi Azure Machine Learning w danych wyjściowych notesu. Wybierz link, aby monitorować automatyczne uruchamianie w usłudze Azure Machine Learning.