Samouczek: przechwytywanie danych usługi Event Hubs w formacie parquet i analizowanie za pomocą usługi Azure Synapse Analytics
W tym samouczku pokazano, jak za pomocą edytora kodu usługi Stream Analytics utworzyć zadanie, które przechwytuje dane usługi Event Hubs w usłudze Azure Data Lake Storage Gen2 w formacie parquet.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Wdrażanie generatora zdarzeń wysyłającego przykładowe zdarzenia do centrum zdarzeń
- Tworzenie zadania usługi Stream Analytics przy użyciu edytora kodu
- Przeglądanie danych wejściowych i schematu
- Konfigurowanie usługi Azure Data Lake Storage Gen2, do której będą przechwytywane dane centrum zdarzeń
- Uruchamianie zadania usługi Stream Analytics
- Wykonywanie zapytań dotyczących plików parquet za pomocą usługi Azure Synapse Analytics
Wymagania wstępne
Przed rozpoczęciem upewnij się, że zostały wykonane następujące kroki:
- Jeśli nie masz subskrypcji platformy Azure, utwórz bezpłatne konto.
- Wdróż aplikację generatora zdarzeń TollApp na platformie Azure. Ustaw parametr "interval" na 1 i użyj nowej grupy zasobów dla tego kroku.
- Utwórz obszar roboczy usługi Azure Synapse Analytics przy użyciu konta usługi Data Lake Storage Gen2.
Tworzenie zadania usługi Stream Analytics przy użyciu edytora kodu
Znajdź grupę zasobów, w której wdrożono generator zdarzeń TollApp.
Wybierz przestrzeń nazw usługi Azure Event Hubs. Możesz otworzyć go na osobnej karcie lub w oknie.
Na stronie Przestrzeń nazw usługi Event Hubs wybierz pozycję Event Hubs w obszarze Jednostki w menu po lewej stronie.
Wybierz
entrystreamwystąpienie.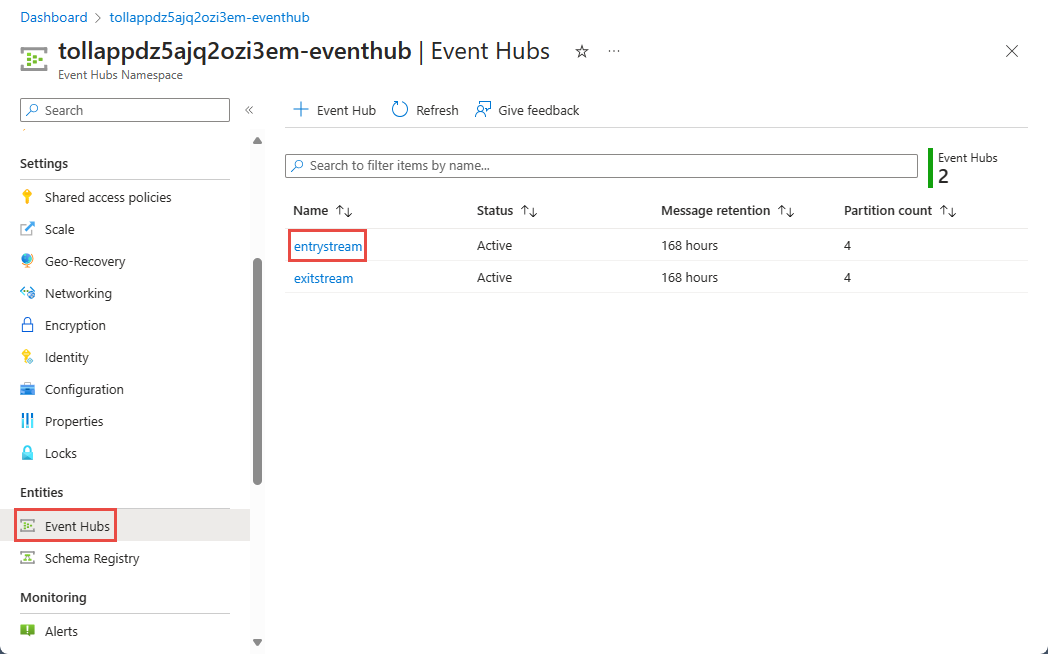
Na stronie wystąpienia usługi Event Hubs wybierz pozycję Przetwarzanie danych w sekcji Funkcje w menu po lewej stronie.
Wybierz pozycję Rozpocznij na kafelku Przechwytywanie danych do usługi ADLS Gen2 w formacie Parquet.
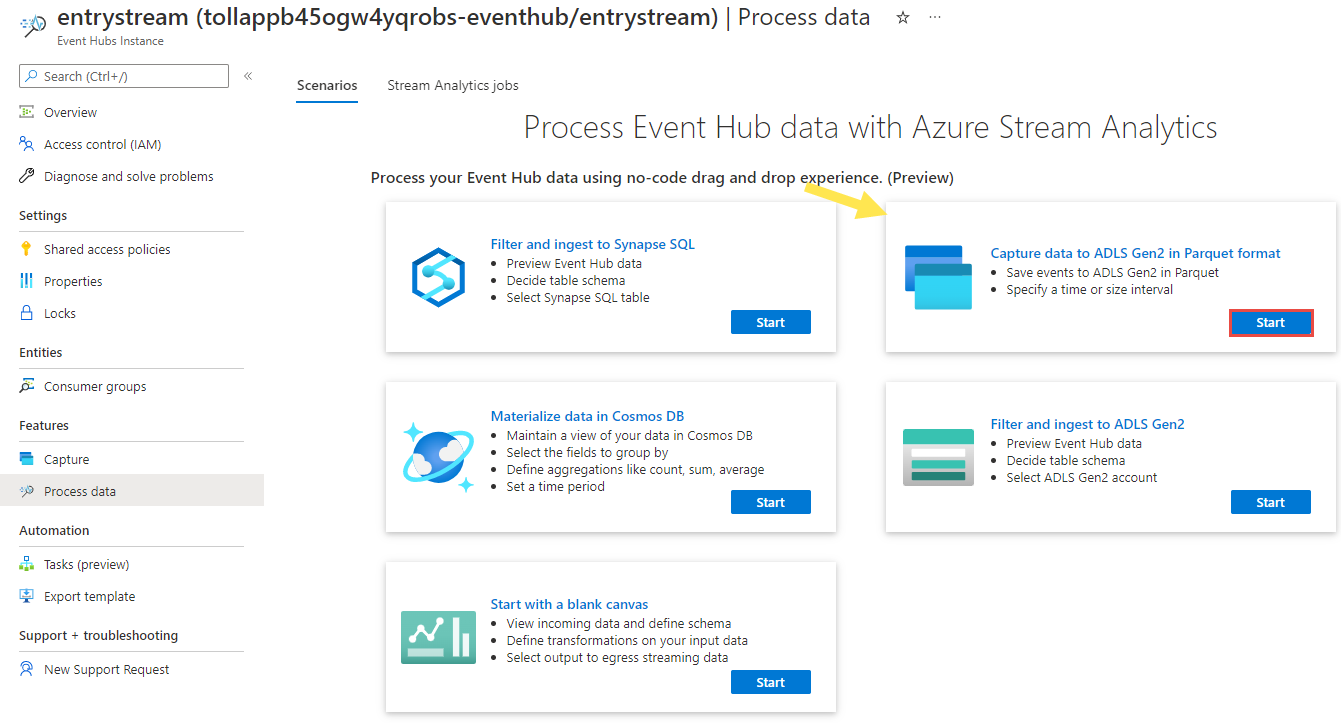
Nadaj zadanie
parquetcapturenazwę i wybierz pozycję Utwórz.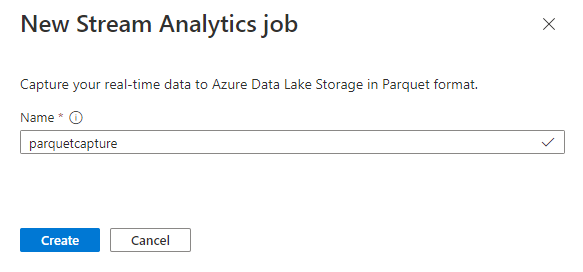
Na stronie konfiguracji centrum zdarzeń wykonaj następujące kroki:
W obszarze Grupa odbiorców wybierz pozycję Użyj istniejącej.
Upewnij się, że
$Defaultwybrano grupę odbiorców.Upewnij się, że serializacja jest ustawiona na JSON.
Upewnij się, że dla metody uwierzytelniania ustawiono wartośćParametry połączenia.
Upewnij się, że nazwa klucza dostępu współdzielonego centrum zdarzeń jest ustawiona na RootManageSharedAccessKey.
Wybierz pozycję Połącz w dolnej części okna.
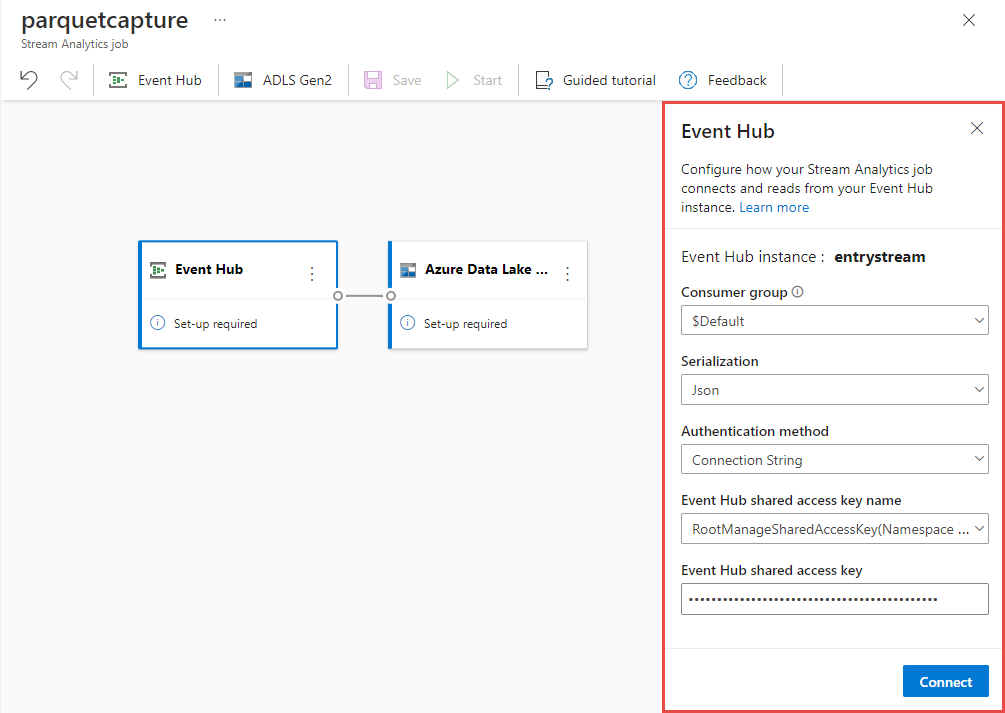
W ciągu kilku sekund zobaczysz przykładowe dane wejściowe i schemat. Możesz usunąć pola, zmienić nazwę pól lub zmienić typ danych.
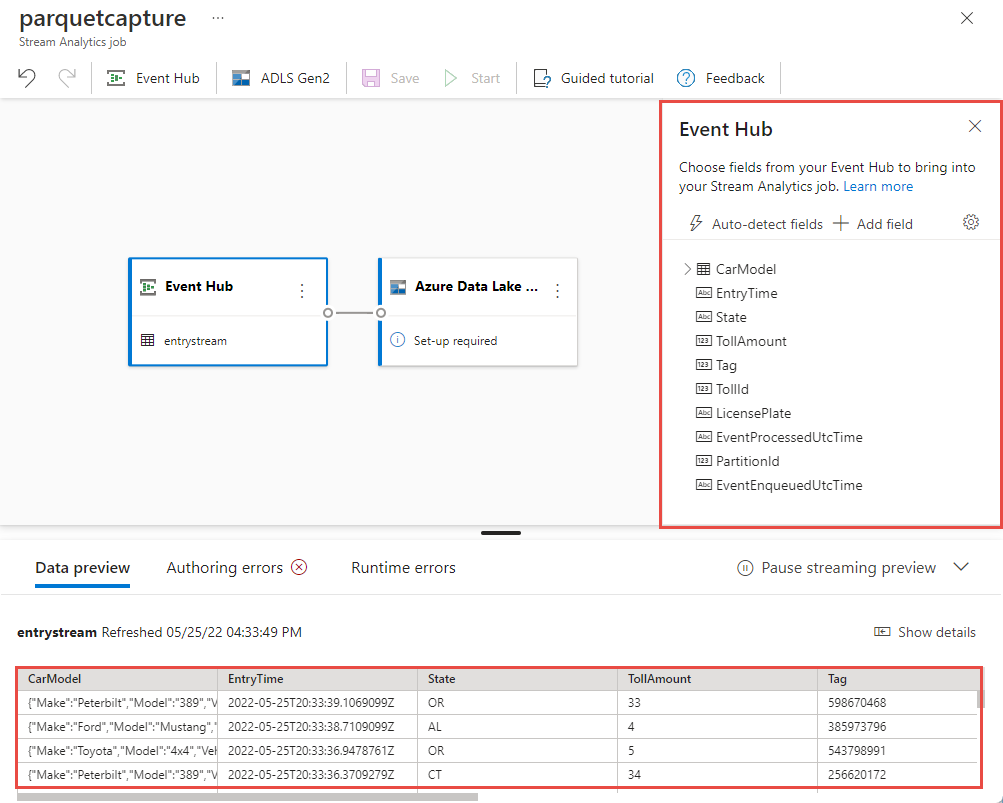
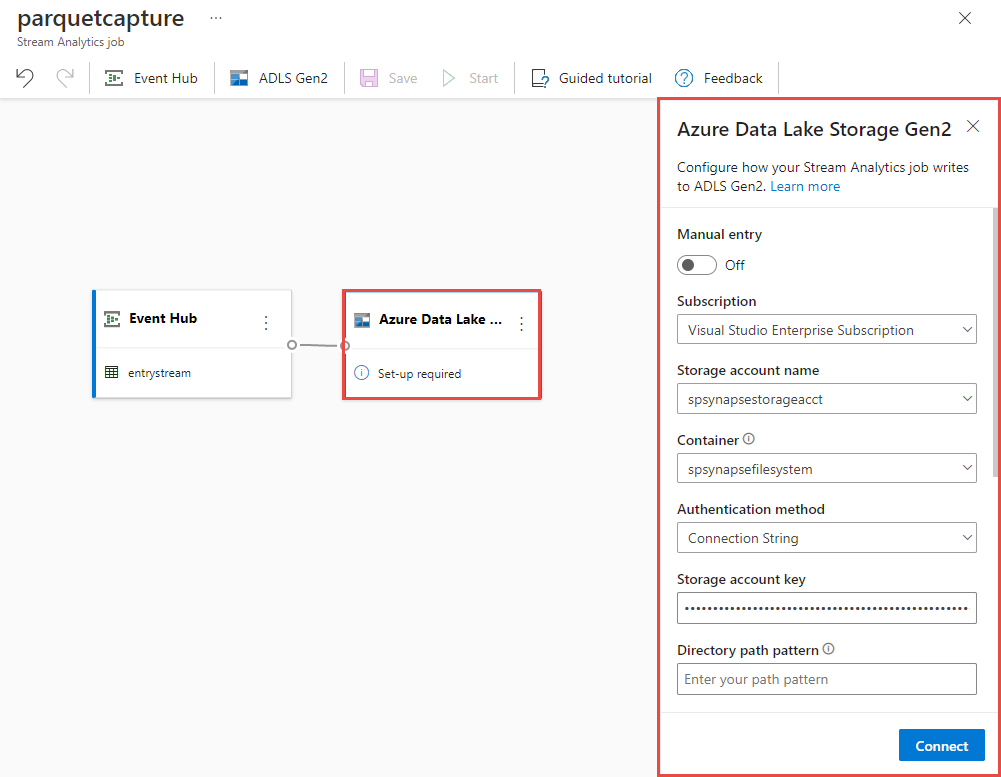
Wybierz kafelek usługi Azure Data Lake Storage Gen2 na kanwie i skonfiguruj go, określając
Subskrypcja, w której znajduje się konto usługi Azure Data Lake Gen2
Nazwa konta magazynu, które powinno być tym samym kontem usługi ADLS Gen2 używanym z obszarem roboczym usługi Azure Synapse Analytics wykonanym w sekcji Wymagania wstępne.
Kontener, w którym zostaną utworzone pliki Parquet.
W polu Ścieżka tabeli delty określ nazwę tabeli.
Wzorzec daty i godziny jako domyślny rrrr-mm-dd i HH.
Wybierz pozycję Połącz
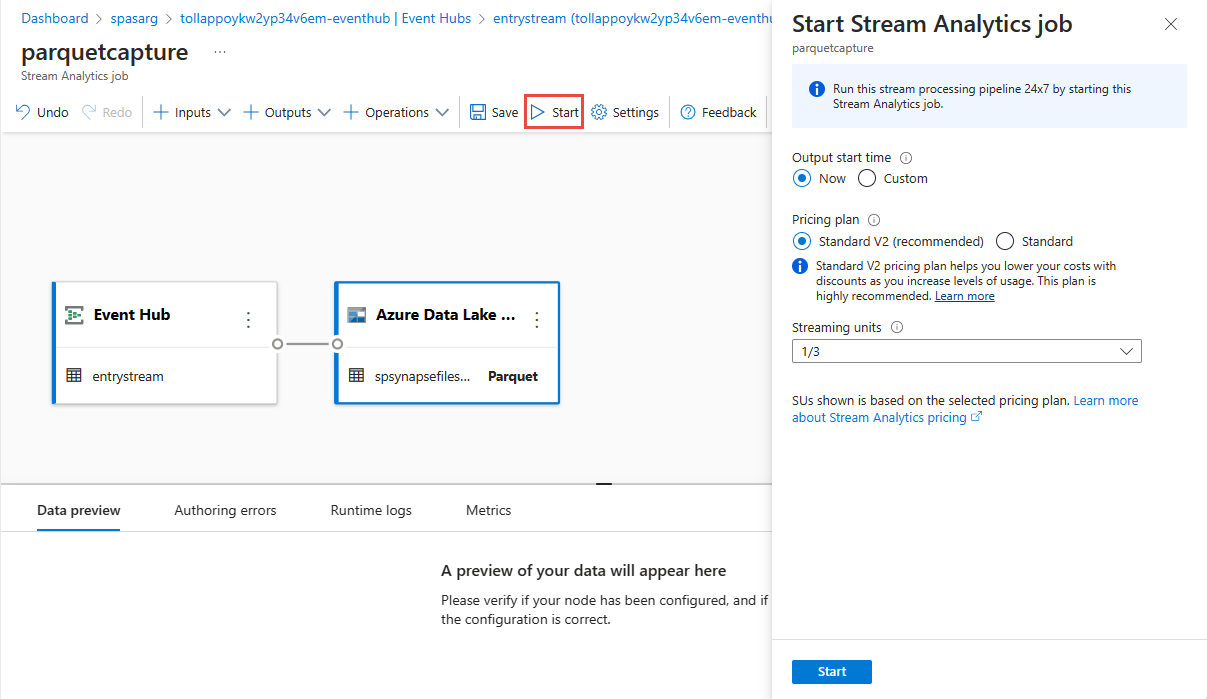
Wybierz pozycję Zapisz na górnej wstążce, aby zapisać zadanie, a następnie wybierz pozycję Uruchom , aby uruchomić zadanie. Po uruchomieniu zadania wybierz pozycję X w prawym rogu, aby zamknąć stronę zadania usługi Stream Analytics.
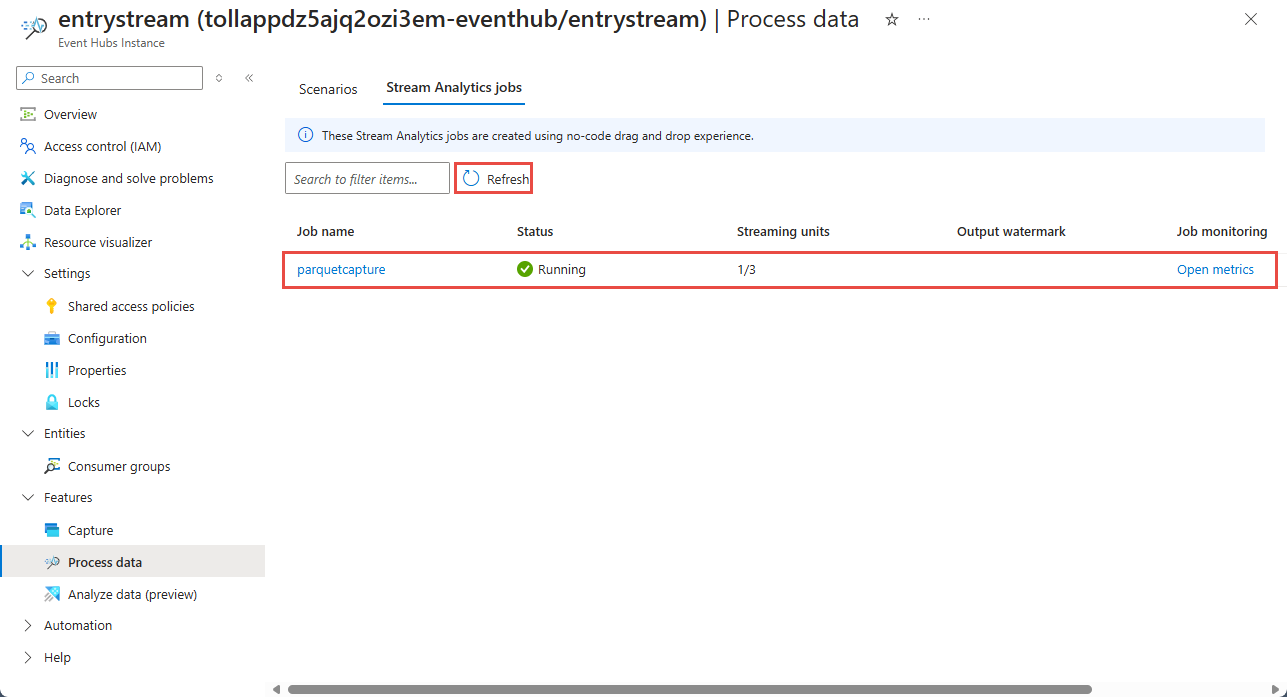
Następnie zostanie wyświetlona lista wszystkich zadań usługi Stream Analytics utworzonych przy użyciu edytora kodu bez. W ciągu dwóch minut zadanie przejdzie do stanu Uruchomione. Wybierz przycisk Odśwież na stronie, aby wyświetlić zmianę stanu z Utworzone —> uruchamianie —> uruchamianie.








Wyświetlanie danych wyjściowych na koncie usługi Azure Data Lake Storage Gen 2
Znajdź konto usługi Azure Data Lake Storage Gen2 użyte w poprzednim kroku.
Wybierz kontener, który został użyty w poprzednim kroku. Zobaczysz pliki parquet utworzone we wskazanym wcześniej folderze.
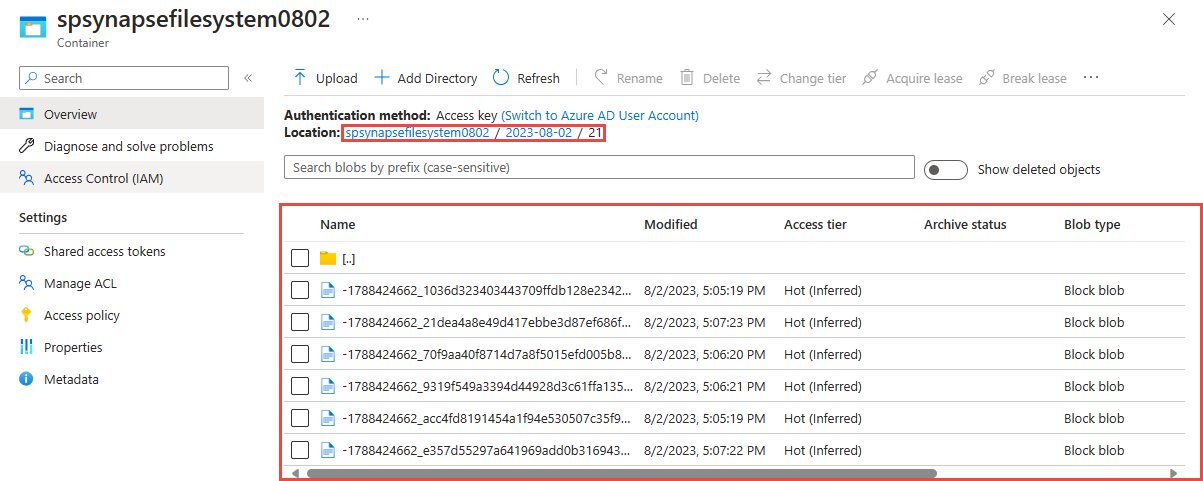

Wykonywanie zapytań dotyczących przechwyconych danych w formacie Parquet za pomocą usługi Azure Synapse Analytics
Wykonywanie zapytań przy użyciu usługi Azure Synapse Spark
Znajdź obszar roboczy usługi Azure Synapse Analytics i otwórz program Synapse Studio.
Utwórz bezserwerową pulę platformy Apache Spark w obszarze roboczym, jeśli jeszcze nie istnieje.
W programie Synapse Studio przejdź do centrum Programowanie i utwórz nowy notes.
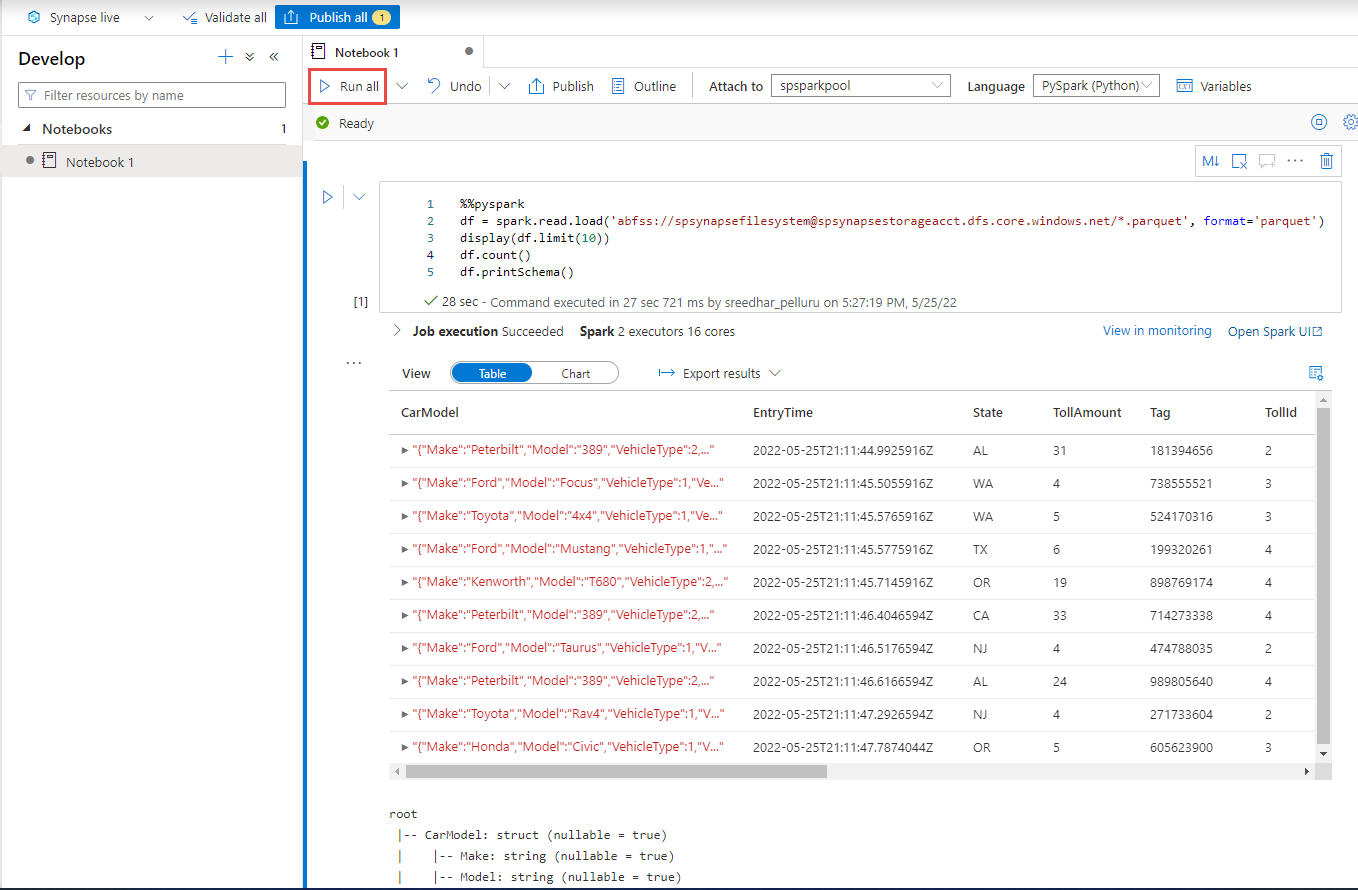
Utwórz nową komórkę kodu i wklej następujący kod w tej komórce. Zastąp kontener i adlsname nazwą kontenera i konta usługi ADLS Gen2 użytego w poprzednim kroku.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()W obszarze Dołącz do na pasku narzędzi wybierz pulę Spark z listy rozwijanej.
Wybierz pozycję Uruchom wszystko , aby wyświetlić wyniki

Wykonywanie zapytań przy użyciu usługi Azure Synapse Serverless SQL
W centrum Programowanie utwórz nowy skrypt SQL.
Wklej następujący skrypt i uruchom go przy użyciu wbudowanego bezserwerowego punktu końcowego SQL. Zastąp kontener i adlsname nazwą kontenera i konta usługi ADLS Gen2 użytego w poprzednim kroku.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*.parquet', FORMAT='PARQUET' ) AS [result]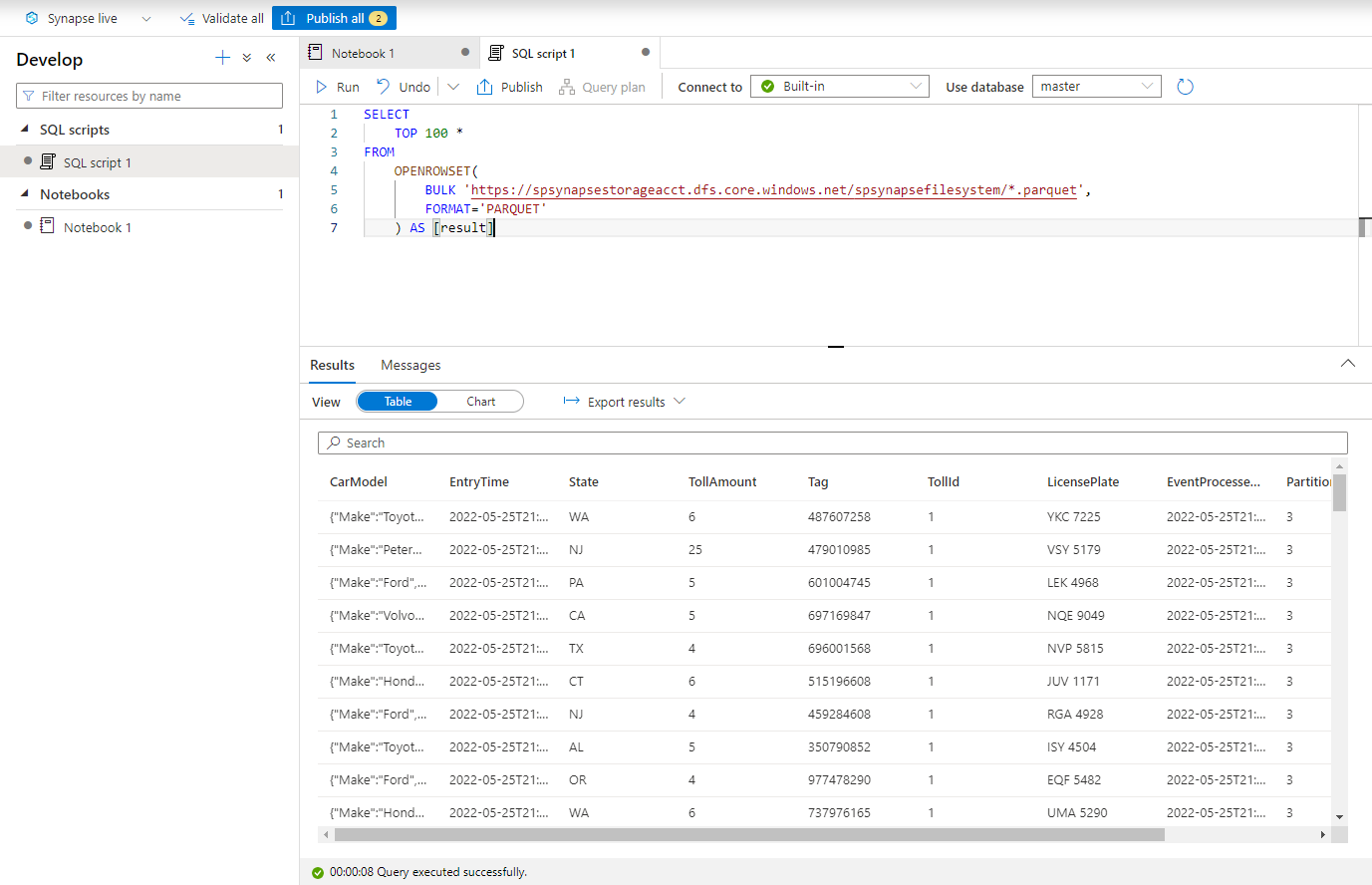

Czyszczenie zasobów
- Znajdź wystąpienie usługi Event Hubs i zapoznaj się z listą zadań usługi Stream Analytics w sekcji Przetwarzanie danych . Zatrzymaj wszystkie uruchomione zadania.
- Przejdź do grupy zasobów użytej podczas wdrażania generatora zdarzeń TollApp.
- Wybierz pozycję Usuń grupę zasobów. Wpisz nazwę grupy zasobów, aby potwierdzić usunięcie.
Następne kroki
W tym samouczku przedstawiono sposób tworzenia zadania usługi Stream Analytics przy użyciu edytora kodu do przechwytywania strumieni danych usługi Event Hubs w formacie Parquet. Następnie użyto usługi Azure Synapse Analytics do wykonywania zapytań dotyczących plików parquet przy użyciu platformy Synapse Spark i usługi Synapse SQL.