Modelowanie relacji
W tym artykule omówiono proces modelowania, który ułatwia projektowanie rozwiązań usługi Azure Table Storage.
Tworzenie modeli domeny to kluczowy krok w projektowaniu złożonych systemów. Zazwyczaj proces modelowania służy do identyfikowania jednostek i relacji między nimi jako sposobu zrozumienia domeny biznesowej i informowania o projekcie systemu. Ta sekcja koncentruje się na tym, jak można przetłumaczyć niektóre typowe typy relacji znalezione w modelach domeny na projekty dla usługi Table Service. Proces mapowania z logicznego modelu danych na fizyczny model danych oparty na bazie danych NoSQL różni się od tego, który jest używany podczas projektowania relacyjnej bazy danych. Projekt relacyjnych baz danych zwykle zakłada, że proces normalizacji danych zoptymalizowany pod kątem zminimalizowania nadmiarowości — i deklaratywne możliwości wykonywania zapytań, które abstrakcje sposobu działania bazy danych.
Relacje jeden-do-wielu
Relacje jeden do wielu między obiektami domeny biznesowej występują często: na przykład jeden dział ma wielu pracowników. Istnieje kilka sposobów implementowania relacji jeden-do-wielu w usłudze Table, z których każda ma zalety i wady, które mogą być istotne dla konkretnego scenariusza.
Rozważmy przykład dużej korporacji wielonarodowej/regionalnej z dziesiątkami tysięcy działów i jednostek pracowników, w których każdy dział ma wielu pracowników, a każdy pracownik jest skojarzony z jednym konkretnym działem. Jednym z podejść jest przechowywanie oddzielnych jednostek działu i pracowników, takich jak:

W tym przykładzie przedstawiono niejawną relację jeden do wielu między typami na podstawie wartości PartitionKey . Każdy dział może mieć wielu pracowników.
W tym przykładzie przedstawiono również jednostkę działu i powiązane z nią jednostki pracowników w tej samej partycji. Możesz użyć różnych partycji, tabel, a nawet kont magazynu dla różnych typów jednostek.
Alternatywną metodą jest denormalizacja danych i przechowywanie tylko jednostek pracowników z zdenormalizowanymi danymi działu, jak pokazano w poniższym przykładzie. W tym konkretnym scenariuszu ta zdenormalizowana metoda może nie być najlepsza, jeśli musisz mieć możliwość zmiany szczegółów kierownika działu, ponieważ w tym celu należy zaktualizować każdego pracownika w dziale.
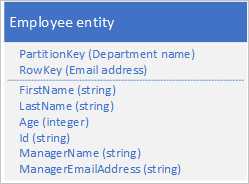
Aby uzyskać więcej informacji, zobacz wzorzec denormalizacji w dalszej części tego przewodnika.
W poniższej tabeli przedstawiono podsumowanie zalet i wad poszczególnych metod opisanych powyżej dotyczących przechowywania jednostek pracowników i działów, które mają relację jeden do wielu. Należy również rozważyć, jak często oczekujesz wykonywania różnych operacji: może być akceptowalne, aby mieć projekt obejmujący kosztowną operację, jeśli ta operacja odbywa się tylko rzadko.
| Metoda | Plusy | Minusy |
|---|---|---|
| Oddzielne typy jednostek, ta sama partycja, ta sama tabela |
|
|
| Oddzielne typy jednostek, różne partycje lub tabele lub konta magazynu |
|
|
| Denormalizacja w pojedynczym typie jednostki |
|
|
*Aby uzyskać więcej informacji, zobacz Entity Group Transactions (Transakcje grupy jednostek)
Wybór między tymi opcjami i zaletami i wadami zależy od konkretnych scenariuszy aplikacji. Na przykład jak często modyfikujesz jednostki działu; czy wszystkie zapytania pracowników wymagają dodatkowych informacji działów; jak blisko zbliżasz się do limitów skalowalności partycji lub konta magazynu?
Relacje jeden do jednego
Modele domen mogą obejmować relacje jeden do jednego między jednostkami. Jeśli musisz zaimplementować relację jeden do jednego w usłudze Table Service, musisz również wybrać sposób łączenia dwóch powiązanych jednostek, gdy trzeba je pobrać. Ten link może być niejawny, oparty na konwencji w wartościach klucza lub jawny, przechowując łącze w postaci wartości PartitionKey i RowKey w każdej jednostce powiązanej. Aby dowiedzieć się, czy należy przechowywać powiązane jednostki w tej samej partycji, zobacz sekcję Relacje jeden do wielu.
Istnieją również zagadnienia dotyczące implementacji, które mogą prowadzić do zaimplementowania relacji jeden do jednego w usłudze Table Service:
- Obsługa dużych jednostek (aby uzyskać więcej informacji, zobacz Wzorzec dużych jednostek).
- Implementowanie kontroli dostępu (aby uzyskać więcej informacji, zobacz Kontrolowanie dostępu za pomocą sygnatur dostępu współdzielonego).
Dołączanie do klienta
Chociaż istnieją sposoby modelowania relacji w usłudze Table Service, nie należy zapominać, że dwa podstawowe przyczyny korzystania z usługi Table Service to skalowalność i wydajność. Jeśli okaże się, że modelujesz wiele relacji, które zagrażają wydajności i skalowalności rozwiązania, należy zadać sobie pytanie, czy konieczne jest utworzenie wszystkich relacji danych w projekcie tabeli. Możesz uprościć projekt i poprawić skalowalność i wydajność rozwiązania, jeśli aplikacja kliencka będzie mogła wykonywać wszelkie niezbędne sprzężenia.
Jeśli na przykład masz małe tabele zawierające dane, które nie zmieniają się często, możesz pobrać te dane raz i buforować je na kliencie. Dzięki temu można uniknąć powtarzających się przekroków w celu pobrania tych samych danych. W przykładach omówionych w tym przewodniku zestaw działów w małej organizacji prawdopodobnie będzie mały i często zmienia się, co czyni go dobrym kandydatem do danych, które aplikacja kliencka może pobierać raz i buforować w miarę wyszukiwania danych.
Relacje dziedziczenia
Jeśli aplikacja kliencka używa zestawu klas, które stanowią część relacji dziedziczenia do reprezentowania jednostek biznesowych, można łatwo utrwalać te jednostki w usłudze Table Service. Na przykład może istnieć następujący zestaw klas zdefiniowanych w aplikacji klienckiej, gdzie Person jest klasą abstrakcyjną.
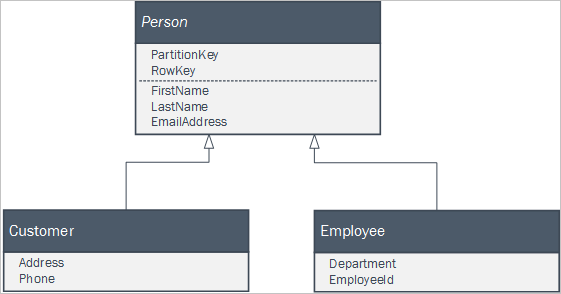
Wystąpienia dwóch konkretnych klas w usłudze Table Service można utrwalać przy użyciu pojedynczej tabeli Person, używając jednostek w tym wyglądzie:

Aby uzyskać więcej informacji na temat pracy z wieloma typami jednostek w tej samej tabeli w kodzie klienta, zobacz sekcję Praca z heterogenicznymi typami jednostek w dalszej części tego przewodnika. Zawiera to przykłady rozpoznawania typu jednostki w kodzie klienta.