Optymalizowanie wydajności udziału plików podczas uzyskiwania dostępu do dużych katalogów z klientów systemu Linux
Ten artykuł zawiera zalecenia dotyczące pracy z katalogami, które zawierają dużą liczbę plików. Zazwyczaj dobrym rozwiązaniem jest zmniejszenie liczby plików w jednym katalogu przez rozłożenie plików na wiele katalogów. Istnieją jednak sytuacje, w których nie można uniknąć dużych katalogów. Podczas pracy z dużymi katalogami w udziałach plików platformy Azure zainstalowanych na klientach z systemem Linux należy wziąć pod uwagę następujące sugestie.
Dotyczy
| Typ udziału plików | SMB | NFS |
|---|---|---|
| Udziały plików w warstwie Standardowa (GPv2), LRS/ZRS |
|
|
| Udziały plików w warstwie Standardowa (GPv2), GRS/GZRS |
|
|
| Udziały plików w warstwie Premium (FileStorage), LRS/ZRS |
|
|
Zalecane opcje instalacji
Poniższe opcje instalacji są specyficzne dla wyliczenia i mogą zmniejszyć opóźnienie podczas pracy z dużymi katalogami.
actimeo
Określanie actimeo ustawia wszystkie wartości acregmin, , acregmaxacdirmini acdirmax na tę samą wartość. Jeśli actimeo nie zostanie określony, klient używa wartości domyślnych dla każdej z tych opcji.
Zalecamy ustawienie actimeo między 30 a 60 sekundami podczas pracy z dużymi katalogami. Ustawienie wartości w tym zakresie sprawia, że atrybuty pozostają prawidłowe przez dłuższy czas w pamięci podręcznej atrybutów klienta, co umożliwia operacjom pobieranie atrybutów plików z pamięci podręcznej zamiast pobierania ich za pośrednictwem przewodu. Może to zmniejszyć opóźnienie w sytuacjach, gdy buforowane atrybuty wygasają, gdy operacja jest nadal uruchomiona.
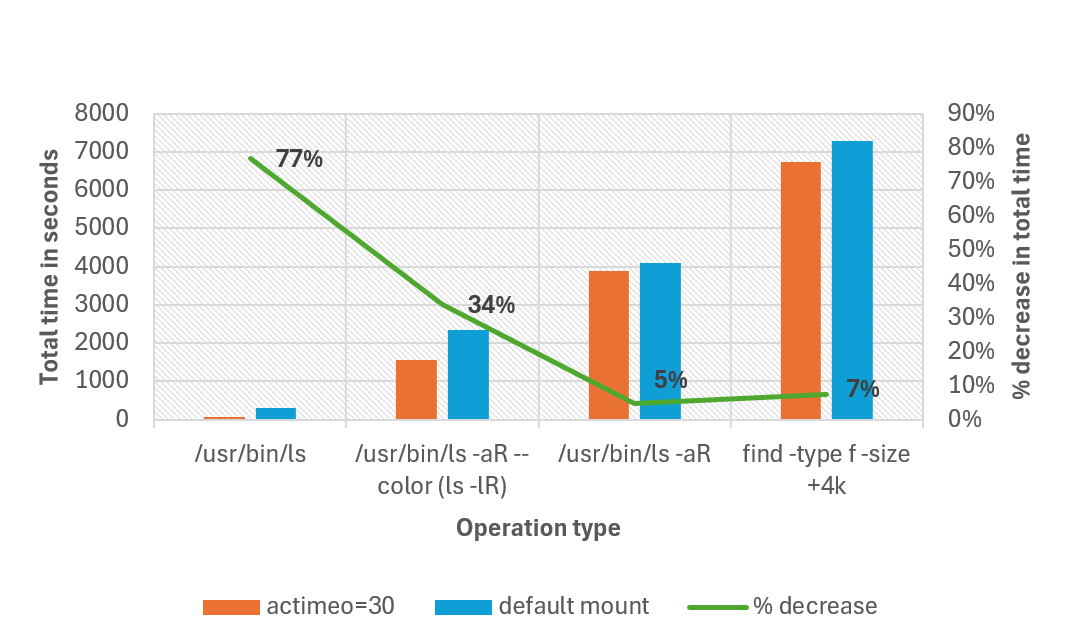
Poniższy wykres porównuje całkowity czas potrzebny na zakończenie różnych operacji z domyślną instalacją, a ustawienie actimeo wartości 30 dla obciążenia, które ma 1 milion plików w jednym katalogu. W naszych testach łączny czas ukończenia zmniejszył się o aż 77% dla niektórych operacji. Wszystkie operacje zostały wykonane z nieprzyzwoiszonych ls.
nconnect
Nconnect to opcja instalacji po stronie klienta dla udziałów plików NFS, która umożliwia używanie wielu połączeń TCP między klientem a usługą Azure Premium Files dla systemu plików NFS 4.1. Zalecamy optymalne ustawienie, nconnect=4 aby zmniejszyć opóźnienia i zwiększyć wydajność.
Nconnect może być szczególnie przydatne w przypadku obciążeń korzystających z asynchronicznego lub synchronicznego we/wy z wielu wątków.
Dowiedz się więcej.
Zwiększanie liczby zasobników skrótów
Całkowita ilość pamięci RAM obecnej w systemie wyliczenia wpływa na wewnętrzną pracę protokołów systemu plików, takich jak NFS i SMB. Nawet jeśli użytkownicy nie mają dużego użycia pamięci, ilość dostępnej pamięci wpływa na liczbę zasobników skrótów inode, które ma wpływ na/poprawia wydajność wyliczania dla dużych katalogów. Można zmodyfikować liczbę zasobników skrótów inode, które system musi zmniejszyć kolizje skrótów, które mogą wystąpić podczas dużych obciążeń wyliczania.
W tym celu należy zmodyfikować ustawienia konfiguracji rozruchu, podając dodatkowe polecenie jądra, które zacznie obowiązywać podczas rozruchu, aby zwiększyć liczbę zasobników skrótów inode. Wykonaj te czynności.
Za pomocą edytora tekstów edytuj
/etc/default/grubplik.sudo vim /etc/default/grubDodaj następujący tekst do pliku
/etc/default/grub. To polecenie ustawi 128 MB jako rozmiar tabeli skrótów inode, zwiększając zużycie pamięci systemowej przez maksymalnie 128 MB.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Jeśli
GRUB_CMDLINE_LINUXjuż istnieje, dodajihash_entries=16777216spację oddzieloną spacją w następujący sposób:GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Aby zastosować zmiany, uruchom polecenie:
sudo update-grub2Uruchom ponownie system:
sudo rebootAby sprawdzić, czy zmiany zostały wprowadzone, po ponownym uruchomieniu systemu sprawdź polecenia wiersza polecenia jądra:
cat /proc/cmdlineJeśli
ihash_entriesjest widoczny, system zastosował ustawienie, a wydajność wyliczania powinna poprawić wykładniczo.Możesz również sprawdzić dane wyjściowe dmesg, aby sprawdzić, czy zastosowano wiersz polecenia jądra:
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Polecenia i operacje
Sposób określenia poleceń i operacji może również mieć wpływ na wydajność. Wyświetlenie listy wszystkich plików w dużym katalogu przy użyciu ls polecenia jest dobrym przykładem.
Uwaga
Niektóre operacje, takie jak rekursywne ls, findi du wymagają zarówno nazw plików, jak i atrybutów plików, więc łączą wyliczenia katalogów (w celu pobrania wpisów) ze statystyką dla każdego wpisu (aby uzyskać atrybuty). Zalecamy użycie wyższej wartości dla actimeo w punktach instalacji, w których prawdopodobnie uruchamiasz takie polecenia.
Używanie niealiased ls
W niektórych dystrybucjach systemu Linux powłoka automatycznie ustawia domyślne opcje dla ls polecenia, takiego jak ls --color=auto. Spowoduje to zmianę sposobu ls działania za pośrednictwem przewodu i dodanie większej ls liczby operacji do wykonania. Aby uniknąć obniżenia wydajności, zalecamy stosowanie niealializowanych ls. Możesz to zrobić na jeden z trzech sposobów:
Usuń alias przy użyciu polecenia
unalias ls. Jest to tylko tymczasowe rozwiązanie dla bieżącej sesji.W przypadku trwałej zmiany można edytować
lsalias w pliku użytkownikabashrc/bash_aliases. W systemie Ubuntu edytuj~/.bashrcpolecenie , aby usunąć alias dla elementuls.Zamiast wywoływać
lsmetodę , możesz bezpośrednio wywołać pliklsbinarny, na przykład/usr/bin/ls. Dzięki temu można używaćlsbez żadnych opcji, które mogą znajdować się w aliasie. Lokalizację pliku binarnego można znaleźć, uruchamiając poleceniewhich ls.
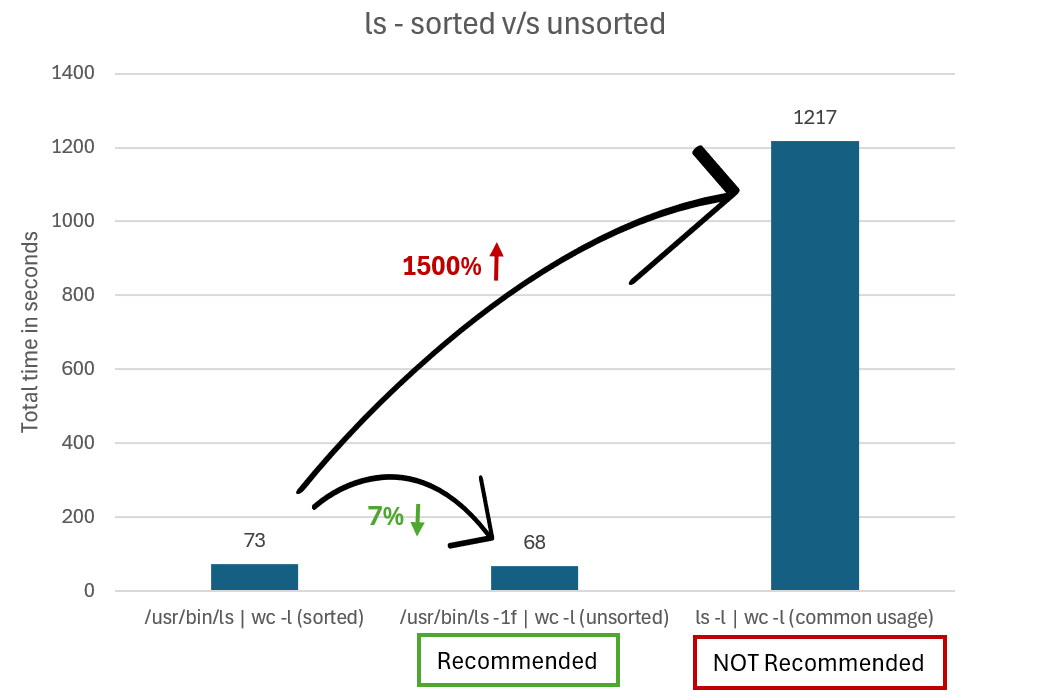
Zapobieganie sortowaniu danych wyjściowych ls
W przypadku używania ls z innymi poleceniami można zwiększyć wydajność, uniemożliwiając ls sortowanie danych wyjściowych w sytuacjach, w których nie dbasz o kolejność zwracania ls plików. Sortowanie danych wyjściowych zwiększa znaczne obciążenie.
Zamiast uruchamiać ls -l | wc -l polecenie , aby uzyskać całkowitą liczbę plików, możesz użyć -f opcji lub -U , ls aby zapobiec sortowaniu danych wyjściowych. Różnica polega na tym, że -f będzie również pokazywać ukryte pliki i -U nie.
Jeśli na przykład bezpośrednio wywołujesz ls plik binarny w systemie Ubuntu, uruchom polecenie /usr/bin/ls -1f | wc -l lub /usr/bin/ls -1U | wc -l.
Poniższy wykres porównuje czas potrzebny do danych wyjściowych przy użyciu nieprzysortowanych, niesortowanych i posortowanych lslswyników.
Operacje kopiowania i tworzenia kopii zapasowych plików
Podczas kopiowania danych z udziału plików lub tworzenia kopii zapasowej z udziałów plików do innej lokalizacji zalecamy użycie migawki udziału jako źródła zamiast aktywnego udziału plików z aktywnym we/wy. Aplikacje do tworzenia kopii zapasowych powinny uruchamiać polecenia bezpośrednio w migawki. Aby uzyskać więcej informacji, zobacz Używanie migawek udziałów w usłudze Azure Files.
Zalecenia na poziomie aplikacji
Podczas tworzenia aplikacji korzystających z dużych katalogów postępuj zgodnie z tymi zaleceniami.
Pomiń atrybuty pliku. Jeśli aplikacja potrzebuje tylko nazwy pliku, a nie atrybutów pliku, takich jak typ pliku lub czas ostatniej modyfikacji, można użyć wielu wywołań do wywołań systemowych, takich jak
getdents64z dobrym rozmiarem buforu. Spowoduje to pobranie wpisów w określonym katalogu bez typu pliku, dzięki czemu operacja będzie szybsza, unikając dodatkowych operacji, które nie są potrzebne.Przeplataj wywołania statystyk. Jeśli aplikacja potrzebuje atrybutów i nazwy pliku, zalecamy przeplatanie wywołań statystyk wraz z
getdents64zamiast pobierania wszystkich wpisów do końca plikugetdents64, a następnie wykonywanie statystyk dla wszystkich zwracanych wpisów. Przeplatanie wywołań statystyk powoduje, że klient zażąda jednocześnie zarówno pliku, jak i jego atrybutów, zmniejszając liczbę wywołań do serwera. W połączeniu z wysokąactimeowartością może to znacznie poprawić wydajność. Na przykład zamiast metody umieść[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ]wywołania statx po każdymgetdents64z nich:[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Zwiększ głębokość we/wy. Jeśli to możliwe, sugerujemy skonfigurowanie
nconnectwartości innej niż zero (większej niż 1) i dystrybucję operacji między wieloma wątkami lub użycie asynchronicznej operacji we/wy. Umożliwi to operacje, które mogą być asynchroniczne, aby korzystać z wielu współbieżnych połączeń z udziałem plików.Wymuszanie użycia pamięci podręcznej. Jeśli aplikacja wykonuje zapytanie dotyczące atrybutów pliku w udziale plików zainstalowanym tylko przez jednego klienta, użyj wywołania systemu statx z flagą
AT_STATX_DONT_SYNC. Ta flaga gwarantuje, że buforowane atrybuty są pobierane z pamięci podręcznej bez synchronizacji z serwerem, co pozwala uniknąć dodatkowych rund sieciowych w celu uzyskania najnowszych danych.