Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Planowane przejście w tryb failover zarządzane przez klienta może być przydatne w scenariuszach, takich jak planowanie i testowanie na wypadek awarii i odzyskiwania, proaktywne działanie naprawcze w przypadku przewidywanych awarii na dużą skalę oraz awarie niezwiązane z magazynowaniem.
Podczas planowanego procesu pracy w trybie failover są zamieniane podstawowe i pomocnicze regiony konta magazynu. Oryginalny region podstawowy jest obniżany i staje się nowym pomocniczym, a oryginalny region pomocniczy jest promowany i staje się nowym podstawowym. Konto magazynowe musi być dostępne zarówno w regionie podstawowym, jak i zapasowym przed zainicjowaniem planowanego przełączenia awaryjnego.
W tym artykule opisano, co się dzieje podczas planowanego, zarządzanego przez klienta przejścia w tryb awaryjny i powrotu do normalności na każdym etapie procesu. Aby dowiedzieć się, jak działa przełączenie awaryjne spowodowane nieoczekiwaną awarią punktu końcowego magazynu, zobacz Jak zarządzany przez klienta (nieplanowany) tryb failover działa.
Ważne
Planowane przełączenie awaryjne zarządzane przez klienta jest obecnie dostępne w wersji zapoznawczej i jest ograniczone do następujących regionów:
- Azja Wschodnia
- Southeast Asia
- Australia Wschodnia
- Australia Południowo-Wschodnia
- Francja Środkowa
- Francja Południowa
- Indie Środkowe
- Indie Zachodnie
- Szwajcaria Zachodnia
- Szwajcaria Północna
Aby włączyć wersję zapoznawczą, zobacz Skonfigurowanie funkcji w wersji zapoznawczej w subskrypcji platformy Azure i określ nazwę funkcji jako AllowSoftFailover. Nazwa dostawcy dla tej funkcji w wersji zapoznawczej to Microsoft.Storage.
Zobacz Dodatkowe warunki użytkowania wersji zapoznawczych platformy Microsoft Azure, aby zapoznać się z postanowieniami prawnymi dotyczącymi funkcji platformy Azure, które są w wersji beta lub wersji zapoznawczej albo w inny sposób nie zostały jeszcze wydane jako ogólnie dostępne.
Ważne
Po zaplanowanym przełączeniu awaryjnym wartość czasu ostatniej synchronizacji (LST) konta magazynu może być nieaktualna lub zgłaszana jako NULL, gdy obecne są dane usługi Azure Files.
Migawki systemu są okresowo tworzone w drugorzędnym regionie konta magazynowego, aby zachować spójne punkty odzyskiwania używane podczas przełączeń awaryjnych i powrotu do normalnej pracy. Rozpoczęcie planowanego failoveru zarządzanego przez klienta powoduje, że pierwotny region podstawowy staje się nowym regionem pomocniczym. W niektórych przypadkach nie ma dostępnych migawek systemowych na nowej wtórnej po zakończeniu planowanego failover, co powoduje, że ogólna wartość LST konta wydaje się przestarzała lub jest wyświetlana jako Null.
Ponieważ działania użytkownika, takie jak tworzenie, modyfikowanie lub usuwanie obiektów, mogą wyzwalać tworzenie migawki, każde konto, na którym te działania występują po zaplanowanym przejściu w tryb failover, nie będzie wymagać dodatkowej uwagi. Jednak konta bez migawek ani aktywności użytkownika mogą nadal wyświetlać Null wartość LST aż do momentu, gdy zostanie uruchomione tworzenie migawki systemu.
W razie potrzeby wykonaj jedną z następujących czynności dla każdego udziału na koncie magazynu, aby wyzwolić tworzenie migawki. Po zakończeniu konto powinno wyświetlić prawidłową wartość LST w ciągu 30 minut.
- Zainstaluj udział, a następnie otwórz dowolny plik do odczytu.
- Prześlij testowy lub przykładowy plik do współdzielonego folderu.
Zarządzanie redundancją podczas planowanego przejścia w tryb awaryjny (failover) i powrotu do normalnej pracy (failback)
Napiwek
Aby szczegółowo zrozumieć różne stany nadmiarowości podczas procesu pracy w trybie failover i powrotu po awarii zarządzanego przez klienta, zobacz Nadmiarowość usługi Azure Storage dla definicji każdego z nich.
Podczas planowanego procesu przełączenia awaryjnego punkty końcowe usługi przechowywania w regionie podstawowym stają się tylko do odczytu, podczas gdy bieżące aktualizacje nadal są replikowane do regionu zapasowego. Następnie wszystkie wpisy DNS punktu końcowego usługi magazynowej są przełączane. Pomocnicze punkty końcowe konta magazynu stają się nowymi podstawowymi punktami końcowymi, a oryginalne podstawowe punkty końcowe stają się nowymi pomocniczymi punktami końcowymi. Replikacja danych w każdym regionie pozostaje niezmieniona, mimo że regiony podstawowe i pomocnicze są przełączane.
Proces planowanego powrotu po awarii jest zasadniczo taki sam jak planowany proces trybu failover, ale z jednym wyjątkiem. Podczas planowanego powrotu po awarii, platforma Azure przechowuje oryginalną konfigurację nadmiarowości konta magazynu i przywraca ją do pierwotnego stanu. Jeśli na przykład konto magazynu zostało pierwotnie skonfigurowane jako GZRS, konto magazynu będzie GZRS po przywróceniu po awarii.
Uwaga
W przeciwieństwie do trybu failover zarządzanego przez klienta (nieplanowanego) podczas planowanego przejścia w tryb failover replikacja z regionu podstawowego do pomocniczego musi zostać ukończona przed zmianą wpisów DNS dla punktów końcowych na nową pomocniczą. W związku z tym utrata danych nie jest oczekiwana podczas planowanego przejścia w tryb failover lub powrotu po awarii, o ile zarówno regiony podstawowe, jak i pomocnicze są dostępne w całym procesie.
Jak zainicjować proces przełączenia awaryjnego
Aby dowiedzieć się, jak zainicjować przełączenie awaryjne konta, zobacz Inicjowanie przełączenia awaryjnego konta.
Proces planowanego przejścia w tryb failover i powrotu po awarii
Na poniższych diagramach przedstawiono, co się dzieje podczas planowanego przełączenia w tryb failover zarządzanego przez klienta i powrotu po awarii konta przechowywania.
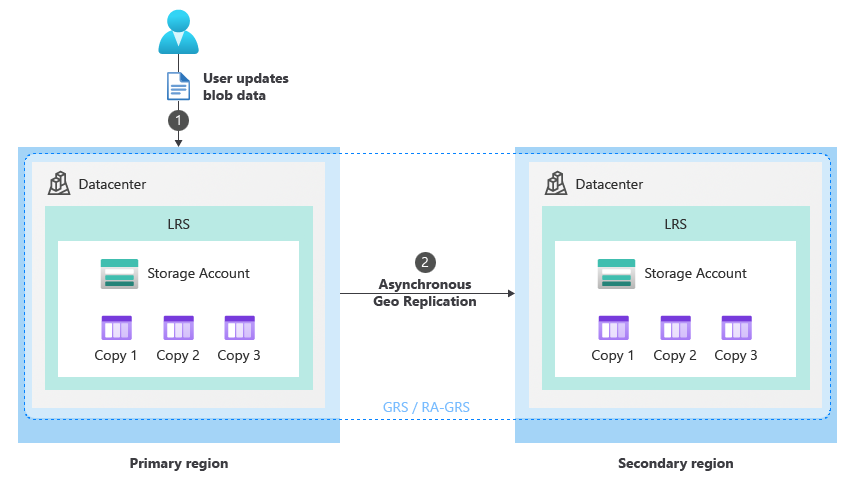
W normalnych okolicznościach klient zapisuje dane na koncie magazynu w regionie podstawowym za pośrednictwem punktów końcowych usługi magazynu (1). Dane są następnie kopiowane asynchronicznie z regionu podstawowego do regionu pomocniczego (2). Na poniższej ilustracji przedstawiono normalny stan konta magazynu skonfigurowanego jako GRS:

Planowany proces przełączenia awaryjnego (GRS/RA-GRS)
Rozpocznij testowanie odzyskiwania po awarii, inicjując przełączenie awaryjne konta przechowywania w regionie wtórnym. Poniżej opisano kroki w ramach planowanego procesu failover, a kolejna ilustracja przedstawia:
Konto magazynowe w regionie podstawowym i pomocniczym doświadczy tymczasowej utraty dostępu zarówno do odczytu, jak i zapisu.
Ukończono replikację wszystkich danych z regionu podstawowego do regionu pomocniczego.
Wpisy DNS dla punktów końcowych usługi przechowywania w regionie pomocniczym są promowane i stają się nowymi podstawowymi punktami końcowymi dla konta przechowywania.
Przejście w tryb failover zwykle trwa około godziny.

Po zakończeniu przełączenia awaryjnego oryginalny region podstawowy staje się nowym pomocniczym (1), a oryginalny region pomocniczy staje się nowym podstawowym (2). Identyfikatory URI punktów końcowych usługi magazynu dla obiektów blob, tabel, kolejek i plików pozostają takie same, ale ich wpisy DNS są zmieniane tak, aby wskazywały nowy region podstawowy (3). Użytkownicy mogą wznowić zapisywanie danych na konto magazynowe w nowym regionie podstawowym, a dane są następnie kopiowane asynchronicznie do nowego pomocniczego (4), jak pokazano na poniższej ilustracji.

Podczas pracy w trybie failover wykonaj testy odzyskiwania po awarii.
Planowany proces powrotu po awarii (GRS/RA-GRS)
Po zakończeniu testowania wykonaj kolejne przełączenie awaryjne, aby przywrócić działanie w pierwotnym regionie głównym. Podczas procesu przełączenia awaryjnego, co pokazano na poniższej ilustracji:
Konto przechowywania w regionie podstawowym i pomocniczym doświadczy tymczasowej utraty dostępu zarówno do odczytu, jak i zapisu.
Wszystkie dane kończą replikację z bieżącego regionu podstawowego do bieżącego regionu pomocniczego.
Wpisy DNS dla punktów końcowych usługi magazynu są zmieniane tak, aby wskazywały region, który był podstawowy, zanim wykonano pierwsze przełączenie awaryjne.
Powrót po awarii zwykle trwa około godziny.

Po zakończeniu przywracania konto magazynowe zostanie przywrócone do pierwotnej konfiguracji nadmiarowości. Użytkownicy mogą wznowić zapisywanie danych na koncie magazynowym w oryginalnym, podstawowym regionie (1), podczas gdy replikacja do oryginalnego, pomocniczego regionu (2) będzie kontynuowana tak jak przed awarią przełącznika.