Migrowanie z lokalnego magazynu systemu plików HDFS do usługi Azure Storage przy użyciu usługi Azure Data Box
Dane można migrować z lokalnego magazynu systemu plików HDFS klastra Hadoop do usługi Azure Storage (magazynu obiektów blob lub usługi Data Lake Storage) przy użyciu urządzenia Data Box. Możesz wybrać urządzenie Data Box Disk, urządzenie Data Box o pojemności 80 TB lub urządzenie Data Box Heavy o pojemności 770 TB.
Ten artykuł ułatwia wykonywanie następujących zadań:
- Przygotowywanie do migracji danych
- Kopiowanie danych na urządzenie Data Box Disk, Data Box lub Data Box Heavy
- Wysyłanie urządzenia z powrotem do firmy Microsoft
- Stosowanie uprawnień dostępu do plików i katalogów (tylko usługa Data Lake Storage)
Wymagania wstępne
Te elementy są potrzebne do ukończenia migracji.
Konto usługi Azure Storage.
Lokalny klaster Hadoop zawierający dane źródłowe.
Urządzenie Azure Data Box.
Podłącz urządzenie Data Box lub Data Box Heavy do sieci lokalnej i podłącz je.
Jeśli wszystko będzie gotowe, zacznijmy.
Kopiowanie danych na urządzenie Data Box
Jeśli dane pasują do pojedynczego urządzenia Data Box, skopiuj dane na urządzenie Data Box.
Jeśli rozmiar danych przekracza pojemność urządzenia Data Box, użyj opcjonalnej procedury, aby podzielić dane na wiele urządzeń Data Box, a następnie wykonaj ten krok.
Aby skopiować dane z lokalnego magazynu systemu plików HDFS do urządzenia Data Box, należy skonfigurować kilka rzeczy, a następnie użyć narzędzia DistCp .
Wykonaj następujące kroki, aby skopiować dane za pośrednictwem interfejsów API REST usługi Blob/Object Storage na urządzenie Data Box. Interfejs API REST sprawia, że urządzenie jest wyświetlane jako magazyn systemu plików HDFS w klastrze.
Przed skopiowaniem danych za pośrednictwem interfejsu REST zidentyfikuj elementy pierwotne zabezpieczeń i połączeń w celu nawiązania połączenia z interfejsem REST na urządzeniu Data Box lub Data Box Heavy. Zaloguj się do lokalnego internetowego interfejsu użytkownika urządzenia Data Box i przejdź do strony Łączenie i kopiowanie . W przypadku kont magazynu platformy Azure dla urządzenia w obszarze Ustawienia dostępu znajdź i wybierz pozycję REST.
W oknie dialogowym Uzyskiwanie dostępu do konta magazynu i przekazywanie danych skopiuj punkt końcowy usługi Blob Service i klucz konta usługi Storage. Z punktu końcowego usługi blob pomiń
https://ukośnik i .W takim przypadku punkt końcowy to:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Część używanego identyfikatora URI hosta to:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Aby zapoznać się z przykładem, zobacz, jak nawiązać połączenie z interfejsem REST za pośrednictwem protokołu HTTP.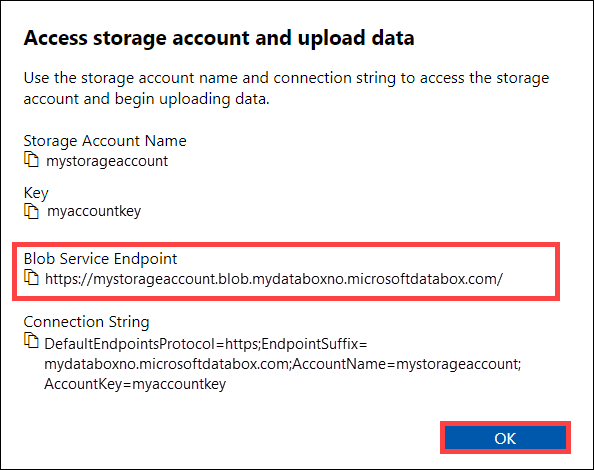
Dodaj punkt końcowy i adres IP węzła Data Box lub Data Box Heavy do
/etc/hostskażdego węzła.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comJeśli używasz innego mechanizmu dla systemu DNS, upewnij się, że punkt końcowy urządzenia Data Box można rozpoznać.
Ustaw zmienną
azjarspowłoki na lokalizacjęhadoop-azureplików jar iazure-storage. Te pliki można znaleźć w katalogu instalacyjnym usługi Hadoop.Aby ustalić, czy te pliki istnieją, użyj następującego polecenia:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure.<hadoop_install_dir>Zastąp symbol zastępczy ścieżką do katalogu, w którym zainstalowano usługę Hadoop. Pamiętaj, aby używać w pełni kwalifikowanych ścieżek.Przykłady:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarUtwórz kontener magazynu, którego chcesz użyć do kopiowania danych. Należy również określić katalog docelowy w ramach tego polecenia. W tym momencie może to być fikcyjny katalog docelowy.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Zastąp
<blob_service_endpoint>symbol zastępczy nazwą punktu końcowego usługi obiektów blob.<account_key>Zastąp symbol zastępczy kluczem dostępu twojego konta.Zastąp
<container-name>symbol zastępczy nazwą kontenera.<destination_directory>Zastąp symbol zastępczy nazwą katalogu, do którego chcesz skopiować dane.
Uruchom polecenie listy, aby upewnić się, że kontener i katalog zostały utworzone.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Zastąp
<blob_service_endpoint>symbol zastępczy nazwą punktu końcowego usługi obiektów blob.<account_key>Zastąp symbol zastępczy kluczem dostępu twojego konta.Zastąp
<container-name>symbol zastępczy nazwą kontenera.
Skopiuj dane z systemu plików HDFS usługi Hadoop do usługi Data Box Blob Storage do utworzonego wcześniej kontenera. Jeśli katalog, do którego kopiujesz, nie zostanie znaleziony, polecenie automatycznie go utworzy.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Zastąp
<blob_service_endpoint>symbol zastępczy nazwą punktu końcowego usługi obiektów blob.<account_key>Zastąp symbol zastępczy kluczem dostępu twojego konta.Zastąp
<container-name>symbol zastępczy nazwą kontenera.<exclusion_filelist_file>Zastąp symbol zastępczy nazwą pliku, który zawiera listę wykluczeń plików.<source_directory>Zastąp symbol zastępczy nazwą katalogu zawierającego dane, które chcesz skopiować.<destination_directory>Zastąp symbol zastępczy nazwą katalogu, do którego chcesz skopiować dane.
Ta
-libjarsopcja służy do udostępnianiahadoop-azure*.jarplikówdistcpzależnychazure-storage*.jari . Może to już wystąpić w przypadku niektórych klastrów.W poniższym przykładzie pokazano, jak polecenie jest używane do kopiowania
distcpdanych.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataAby zwiększyć szybkość kopiowania:
Spróbuj zmienić liczbę maperów. (Domyślna liczba maperów to 20. W powyższym przykładzie użyto
m= 4 maperów).Spróbuj wykonać próbę
-D fs.azure.concurrentRequestCount.out=<thread_number>. Zastąp<thread_number>element liczbą wątków na maper. Produkt liczby maperów i liczby wątków na maper,m*<thread_number>nie powinien przekraczać 32.Spróbuj uruchomić wiele
distcprównolegle.Pamiętaj, że duże pliki działają lepiej niż małe pliki.
Jeśli masz pliki większe niż 200 GB, zalecamy zmianę rozmiaru bloku na 100 MB przy użyciu następujących parametrów:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Wysyłanie urządzenia Data Box do firmy Microsoft
Wykonaj następujące kroki, aby przygotować i wysłać urządzenie Data Box do firmy Microsoft.
Najpierw przygotuj się do wysłania na urządzenie Data Box lub Data Box Heavy.
Po zakończeniu przygotowywania urządzenia pobierz pliki BOM. Użyjesz tych plików BOM lub manifestu później, aby zweryfikować dane przekazane na platformę Azure.
Zamknij urządzenie i usuń.
Zaplanuj odbiór przez firmę UPS.
Aby zapoznać się z urządzeniami Data Box, zobacz Wysyłanie urządzenia Data Box.
Aby uzyskać informacje o urządzeniach Data Box Heavy, zobacz Ship your Data Box Heavy (Dostarczanie urządzenia Data Box Heavy).
Po odebraniu urządzenia przez firmę Microsoft jest on połączony z siecią centrum danych, a dane są przekazywane do konta magazynu określonego podczas składania zamówienia urządzenia. Sprawdź, czy względem plików BOM wszystkie dane są przekazywane na platformę Azure.
Stosowanie uprawnień dostępu do plików i katalogów (tylko usługa Data Lake Storage)
Masz już dane na koncie usługi Azure Storage. Teraz zastosujesz uprawnienia dostępu do plików i katalogów.
Uwaga
Ten krok jest wymagany tylko wtedy, gdy używasz usługi Azure Data Lake Storage jako magazynu danych. Jeśli używasz tylko konta magazynu obiektów blob bez hierarchicznej przestrzeni nazw jako magazynu danych, możesz pominąć tę sekcję.
Tworzenie jednostki usługi dla konta z włączoną usługą Azure Data Lake Storage
Aby utworzyć jednostkę usługi, zobacz How to: Use the portal to create a Microsoft Entra application and service principal that can access resources (Jak utworzyć aplikację i jednostkę usługi Firmy Microsoft, która może uzyskiwać dostęp do zasobów).
Wykonując kroki opisane w sekcji Przypisywanie aplikacji do roli tego artykułu, upewnij się, że przypisano rolę Współautor danych obiektu blob magazynu do jednostki usługi.
Podczas wykonywania kroków w sekcji Pobieranie wartości logowania w artykule zapisz identyfikator aplikacji i wartości wpisów tajnych klienta w pliku tekstowym. Potrzebujesz tych wkrótce.
Generowanie listy skopiowanych plików z uprawnieniami
Z lokalnego klastra Hadoop uruchom następujące polecenie:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
To polecenie generuje listę skopiowanych plików z ich uprawnieniami.
Uwaga
W zależności od liczby plików w systemie plików HDFS uruchomienie tego polecenia może zająć dużo czasu.
Generowanie listy tożsamości i mapowanie ich na tożsamości firmy Microsoft
copy-acls.pyPobierz skrypt. Zobacz sekcję Pobierz skrypty pomocnika i skonfiguruj węzeł brzegowy, aby uruchomić je w tym artykule.Uruchom to polecenie, aby wygenerować listę unikatowych tożsamości.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gTen skrypt generuje plik o nazwie
id_map.jsonzawierający tożsamości, które należy zamapować na tożsamości oparte na dodatku.Otwórz plik
id_map.jsonw edytorze tekstów.Dla każdego obiektu JSON wyświetlanego w pliku zaktualizuj
targetatrybut głównej nazwy użytkownika (UPN) firmy Microsoft (UPN) lub ObjectId (OID) przy użyciu odpowiedniej zamapowanej tożsamości. Po zakończeniu zapisz plik. Ten plik będzie potrzebny w następnym kroku.
Stosowanie uprawnień do skopiowanych plików i stosowanie mapowań tożsamości
Uruchom to polecenie, aby zastosować uprawnienia do danych skopiowanych na konto z włączoną usługą Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Zastąp symbol zastępczy
<storage-account-name>nazwą konta magazynu.Zastąp
<container-name>symbol zastępczy nazwą kontenera.<application-id>Zastąp symbole zastępcze i<client-secret>identyfikatorem aplikacji i kluczem tajnym klienta zebranym podczas tworzenia jednostki usługi.
Dodatek: Dzielenie danych na wiele urządzeń Data Box
Przed przeniesieniem danych na urządzenie Data Box należy pobrać skrypty pomocnika, upewnić się, że dane są zorganizowane tak, aby zmieściły się na urządzeniu Data Box i wykluczyć niepotrzebne pliki.
Pobieranie skryptów pomocnika i konfigurowanie węzła brzegowego w celu ich uruchomienia
Z krawędzi lub węzła głównego lokalnego klastra Hadoop uruchom następujące polecenie:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderTo polecenie klonuje repozytorium GitHub zawierające skrypty pomocnika.
Upewnij się, że pakiet jq jest zainstalowany na komputerze lokalnym.
sudo apt-get install jqZainstaluj pakiet Python Requests.
pip install requestsUstaw uprawnienia wykonywania dla wymaganych skryptów.
chmod +x *.py *.sh
Upewnij się, że dane są zorganizowane tak, aby zmieściły się na urządzeniu Data Box
Jeśli rozmiar danych przekracza rozmiar pojedynczego urządzenia Data Box, możesz podzielić pliki na grupy, które można przechowywać na wielu urządzeniach Data Box.
Jeśli dane nie przekraczają rozmiaru urządzenia Data Box, możesz przejść do następnej sekcji.
W przypadku uprawnień z podwyższonym poziomem uprawnień uruchom
generate-file-listpobrany skrypt, postępując zgodnie ze wskazówkami w poprzedniej sekcji.Oto opis parametrów polecenia:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Skopiuj wygenerowane listy plików do systemu plików HDFS, aby były dostępne dla zadania DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Wykluczanie niepotrzebnych plików
Należy wykluczyć niektóre katalogi z zadania narzędzia DisCp. Na przykład wyklucz katalogi zawierające informacje o stanie, które utrzymują działanie klastra.
W lokalnym klastrze Hadoop, w którym planujesz zainicjować zadanie DistCp, utwórz plik określający listę katalogów, które chcesz wykluczyć.
Oto przykład:
.*ranger/audit.*
.*/hbase/data/WALs.*
Następne kroki
Dowiedz się, jak usługa Data Lake Storage współpracuje z klastrami usługi HDInsight. Aby uzyskać więcej informacji, zobacz Use Azure Data Lake Storage with Azure HDInsight clusters (Używanie usługi Azure Data Lake Storage z klastrami usługi Azure HDInsight).