Replikacja komunikatów i federacja między regionami
W przestrzeniach nazw usługa Azure Service Bus obsługuje tworzenie topologii kolejek łańcuchowych i subskrypcji tematów przy użyciu automatycznego wdrażania w celu umożliwienia implementacji różnych wzorców routingu. Można na przykład udostępnić partnerom dedykowane kolejki, do których mają uprawnienia do wysyłania lub odbierania, i które mogą zostać tymczasowo zawieszone w razie potrzeby, i elastycznie połączyć je z innymi jednostkami, które są prywatne z aplikacją. Można również tworzyć złożone topologie routingu wieloetapowego lub tworzyć kolejki w stylu skrzynki pocztowej, które opróżniają subskrypcje tematów przypominające kolejkę i umożliwiają uzyskanie większej pojemności magazynu na subskrybenta.
Wiele zaawansowanych rozwiązań wymaga również replikowania komunikatów w granicach przestrzeni nazw w celu zaimplementowania tych i innych wzorców. Komunikaty mogą wymagać przepływu między przestrzeniami nazw skojarzonymi z wieloma, różnymi dzierżawami aplikacji lub w wielu różnych regionach świadczenia usługi Azure.
Rozwiązanie będzie obsługiwać wiele przestrzeni nazw usługi Service Bus w różnych regionach i replikować komunikaty między kolejkami i tematami oraz/lub wymieniać komunikaty ze źródłami i miejscami docelowymi, takimi jak Azure Event Hubs, Azure IoT Hub lub Apache Kafka.
Te scenariusze koncentrują się na tym artykule.
Wzorce federacji
Istnieje wiele potencjalnych powodów, dla których warto przenosić komunikaty między jednostkami usługi Service Bus, takimi jak kolejki lub tematy, albo między usługą Service Bus a innymi źródłami i miejscami docelowymi.
W porównaniu z podobnym zestawem wzorców dla usługi Event Hubs federacja jednostek przypominających kolejkę jest bardziej złożona, ponieważ kolejki komunikatów obiecują swoim użytkownikom wyłączność własności w przypadku każdego pojedynczego komunikatu, oczekuje się zachowania kolejności przybycia w dostarczaniu komunikatów, a broker będzie koordynował sprawiedliwą dystrybucję komunikatów między konkurencyjnymi konsumentami.
Istnieją praktyczne przeszkody, w tym ograniczenia twierdzenia CAP, które utrudniają zapewnienie ujednoliconego widoku kolejki, który jest jednocześnie dostępny w wielu regionach, i który pozwala na regionalnie dystrybuowane, konkurujących konsumentów do przejęcia wyłącznej własności komunikatów. Taka kolejka rozproszona geograficznie wymagałaby nie tylko pełnej spójnej replikacji komunikatów, ale także stanu dostarczania każdego komunikatu, zanim komunikaty będą dostępne dla konsumentów. Celem pełnej spójności hipotetycznej, regionalnie rozproszonej kolejki jest bezpośredni konflikt z kluczowym celem, który praktycznie wszyscy klienci usługi Azure Service Bus mają podczas rozważania scenariuszy federacji: maksymalna dostępność i niezawodność dla swoich rozwiązań.
Przedstawione tutaj wzorce koncentrują się zatem na dostępności i niezawodności, a jednocześnie mają na celu uniknięcie zarówno utraty informacji, jak i obsługi zduplikowanych komunikatów.
Odporność na zdarzenia dostępności regionalnej
Chociaż maksymalna dostępność i niezawodność są głównymi priorytetami operacyjnymi dla usługi Service Bus, istnieje jednak wiele sposobów, w jaki producent lub konsument może uniemożliwić rozmowę z przypisaną "podstawową" usługą Service Bus z powodu problemów z siecią lub rozpoznawaniem nazw, lub gdzie jednostka usługi Service Bus może rzeczywiście tymczasowo nie odpowiadać lub zwracać błędy. Wyznaczony procesor komunikatów może również stać się niedostępny.
Takie warunki nie są "katastrofalne", takie jak całkowite porzucenie wdrożenia regionalnego, ponieważ można to zrobić w sytuacji odzyskiwania po awarii, ale scenariusz biznesowy niektórych aplikacji może już mieć wpływ na zdarzenia dostępności, które trwają nie dłużej niż kilka minut, a nawet sekund. Usługa Azure Service Bus jest często używana w środowiskach chmury hybrydowej i z klientami, którzy znajdują się na brzegu sieci, na przykład w sklepach detalicznych, restauracjach, oddziałach bankowych, zakładach produkcyjnych, obiektach logistycznych i lotniskach. Istnieje możliwość, że problem z routingiem sieciowym lub przeciążeniem ma wpływ na możliwość dotarcia do przypisanego punktu końcowego usługi Service Bus przez jedną lokację, a pomocniczy punkt końcowy w innym regionie może być osiągalny. Jednocześnie systemy przetwarzające komunikaty przychodzące z tych lokacji mogą nadal mieć niezamknięty dostęp do podstawowych i pomocniczych punktów końcowych usługi Service Bus.
Istnieje wiele praktycznych przykładów takich aplikacji chmury hybrydowej i brzegowej z niską tolerancją biznesową na wpływ problemów z routingiem sieciowym lub przejściowych problemów z dostępnością jednostki usługi Service Bus. Obejmują one przetwarzanie płatności w sklepach detalicznych, wejście na pokład przy bramach lotniska i zamówienia na telefon komórkowy w restauracjach, z których wszystkie przychodzą na chwilę i pełne wstrzymanie, gdy niezawodna ścieżka komunikacji nie jest dostępna.
W tej kategorii omawiamy trzy odrębne wzorce rozproszone: replikację "all-active", replikację "aktywny-pasywny" i replikację "spillover".
Replikacja all-active
Wzorzec replikacji "all-active" umożliwia dostęp do aktywnej repliki tego samego tematu logicznego (lub kolejki) w wielu przestrzeniach nazw (i regionach), a wszystkie komunikaty staną się dostępne we wszystkich replikach, niezależnie od tego, gdzie zostały one w kolejce. Wzorzec zazwyczaj zachowuje kolejność komunikatów względem dowolnego wydawcy.
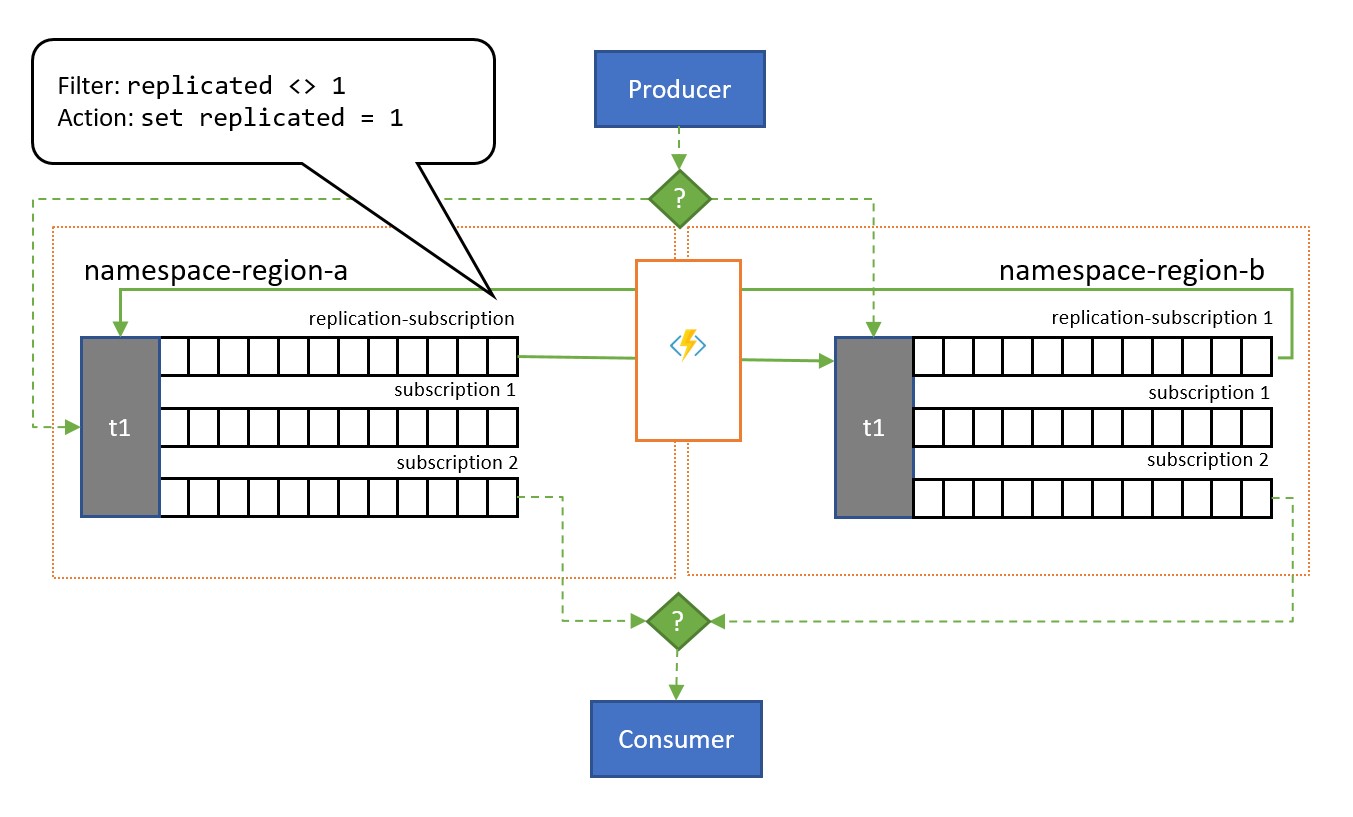
Jak pokazano na ilustracji, wzorzec zwykle opiera się na temat tematów usługi Service Bus. Jeden temat dla każdej przestrzeni nazw, która uczestniczy w schemacie replikacji. Każdy z tych tematów ma jedną "subskrypcję replikacji" dla każdego z pozostałych tematów, do których będą replikowane komunikaty. Na powyższej ilustracji po prostu mamy parę tematów i dlatego pojedynczą subskrypcję replikacji dla odpowiedniego innego tematu. W scenariuszu z trzema przestrzeniami nazw {n1, n2, n3}, temat w przestrzeni nazw n1 będzie miał dwie subskrypcje replikacji, jeden dla odpowiedniego tematu w n2 i jeden dla odpowiedniego tematu w n3.
Każda subskrypcja replikacji ma regułę łączącą wyrażenie filtru SQL (replicated <> 1) i akcję SQL (set replicated = 1). Filtr reguły zapewnia, że tylko komunikaty, w których właściwość replication niestandardowa nie jest ustawiona lub nie ma wartości 1 , stają się uprawnione do tej subskrypcji, a akcja ustawia tę dokładną właściwość na wartość 1 dla każdego wybranego komunikatu bezpośrednio później. Efekt polega na tym, że gdy komunikat zostanie skopiowany do odpowiedniego tematu, nie kwalifikuje się już do replikacji w przeciwnym kierunku i dlatego unikamy komunikatów odbijających się między replikami.
Subskrypcję z odpowiednią regułą można łatwo dodać do dowolnego tematu przy użyciu interfejsu wiersza polecenia platformy Azure w następujący sposób.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Aby modelować kolejkę, każdy temat jest ograniczony tylko do jednej zwykłej subskrypcji (innej niż subskrypcje replikacji), które wszyscy użytkownicy współużytkuje.
Model replikacji wszystkich aktywnych umieszcza kopię każdego komunikatu wysyłanego do dowolnego z tematów w każdym z tematów. Oznacza to, że kod aplikacji w każdym regionie będzie widzieć i przetwarzać wszystkie komunikaty. Ten wzorzec jest odpowiedni w scenariuszach, w których dane są udostępniane w wielu regionach lub jeśli przetwarzanie nadmiarowe jest zwykle pożądane. Jeśli musisz przetworzyć każdy komunikat tylko raz, podobnie jak w przypadku regularnej kolejki, należy wziąć pod uwagę jeden z następujących dwóch wzorców.
Replikacja aktywna-pasywna
Wzorzec replikacji "aktywny-pasywny" jest odmianą wcześniejszego wzorca, w którym tylko jeden z tematów ("podstawowy") jest aktywnie używany przez aplikację do wysyłania i odbierania komunikatów i komunikatów są replikowane do tematu pomocniczego w przypadku, gdy temat podstawowy może stać się niedostępny lub nieosiągalny.
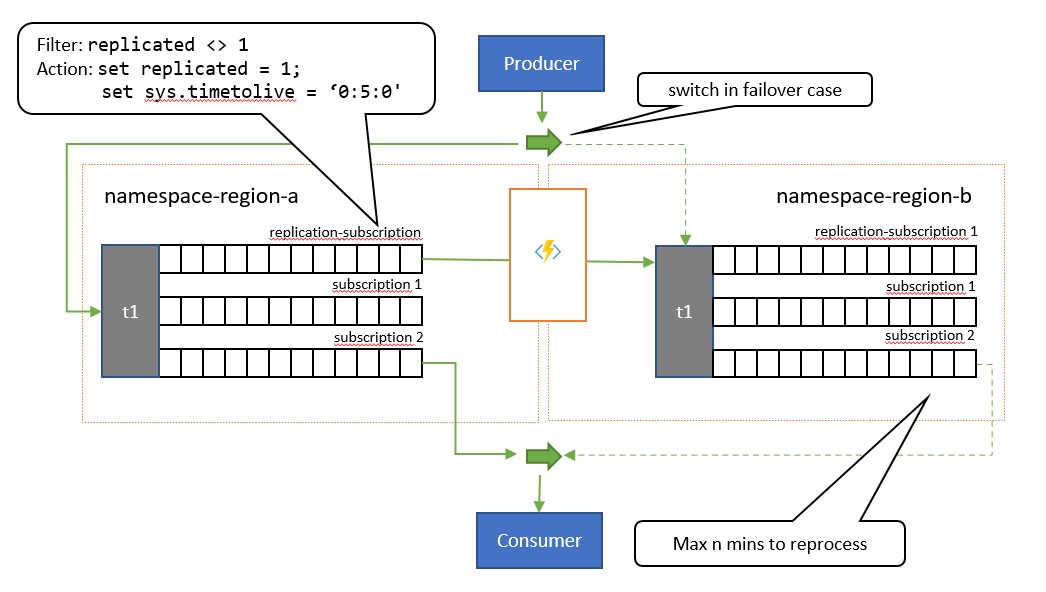
Kluczową różnicą między tym wzorcem a poprzednim wzorcem jest to, że replikacja jest jednokierunkowa z tematu podstawowego do tematu pomocniczego. Temat pomocniczy nigdy nie staje się podstawowym, ale jest opcją tworzenia kopii zapasowej, gdy temat podstawowy jest tymczasowo bezużyteczny.
Wadą korzystania z tego wzorca jest to, że próbuje zminimalizować zduplikowane przetwarzanie. Podczas replikacji właściwość komunikatu TimeToLive jest ustawiana na czas trwania replikowanych komunikatów, który odzwierciedla oczekiwany czas, w którym awaria podstawowego doprowadzi do przejścia w tryb failover. Jeśli na przykład scenariusz przypadków użycia wymaga przełączenia konsumenta do pomocniczego w ciągu co najwyżej 1 minuty od momentu pobrania komunikatów z podstawowego początku pokazującego problemy, pomocnicza powinna w idealnym przypadku mieć wszystkie dostępne komunikaty, do których nie można uzyskać dostępu w podstawowym, ale minimalna liczba komunikatów, które zostały już przetworzone z podstawowego przed pojawieniem się problemów. Jeśli ustawimy TimeToLive wartość dwa razy w tym okresie, 2 minuty, podczas replikacji (set sys.TimeToLive = '0:2:0' w akcji reguły), pomocnicza zachowa komunikaty tylko przez 2 minuty i odrzuci starsze. Oznacza to, że gdy odbiornik przełącza się do pomocniczej, może szybko odczytywać i odrzucać komunikaty starsze niż ostatni przetworzony, a następnie przetwarzać z pierwszego komunikatu, że jeszcze nie widział. Rzeczywisty czas przechowywania będzie zależeć od konkretnego przypadku użycia i szybkiego przejścia do pomocniczego w aplikacji. Ustawienie TimeToLive jest honorowane w zakresie od kilku sekund do dni.
Aplikacja używa pomocniczej, ale może również publikować bezpośrednio w temacie pomocniczym, który działa tak jak w przypadku każdego zwykłego tematu. Po przełączeniu do pomocniczego odbiorca zobaczy kombinację replikowanych komunikatów i komunikatów opublikowanych bezpośrednio do pomocniczej. W związku z tym aplikacja powinna najpierw przełączyć publikowanie z powrotem do podstawowego elementu i nadal zezwalać na opróżnianie lokalnie opublikowanych komunikatów przed przełączeniem konsumenta z powrotem na pomocniczą. Ze względu na wznawianie replikacji automatycznie po ponownym udostępnieniu podstawowego użytkownik otrzyma również nowe komunikaty opublikowane w podstawowym czasie, choć z nieco większym opóźnieniem.
Ten wzorzec jest odpowiedni w scenariuszach, w których komunikaty powinny być przetwarzane tylko raz. Aplikacja musi współpracować w celu śledzenia komunikatów przetworzonych z serwera podstawowego, ponieważ będzie znajdować duplikaty przez czas trwania okna trybu failover w pomocniczym systemie i będzie ponownie znajdować duplikaty podczas przełączania z powrotem. Kryterium deduplikacji powinno być najlepiej dostarczone
MessageIdprzez aplikację. WartośćEnqueuedTimeUtcjest również odpowiednia jako wskaźnik limitu, ale aplikacja musi zezwalać na pewną ilość dryfu zegara (kilka sekund) między podstawowym i pomocniczym, tak jak w przypadku dowolnego systemu rozproszonego.
Replikacja rozlewu
Wzorzec replikacji "rozlania" umożliwia aktywne/aktywne używanie wielu jednostek usługi Service Bus w wielu regionach do obsługi scenariusza, w którym usługa Service Bus jest w dobrej kondycji, ale użytkownik staje się przeciążony liczbą oczekujących komunikatów lub jest wręcz niedostępny. Przyczyną może być to, że baza danych, która obsługuje proces konsumenta, może być niska lub niedostępna. Ten wzorzec działa z prostymi kolejkami i subskrypcjami tematów.
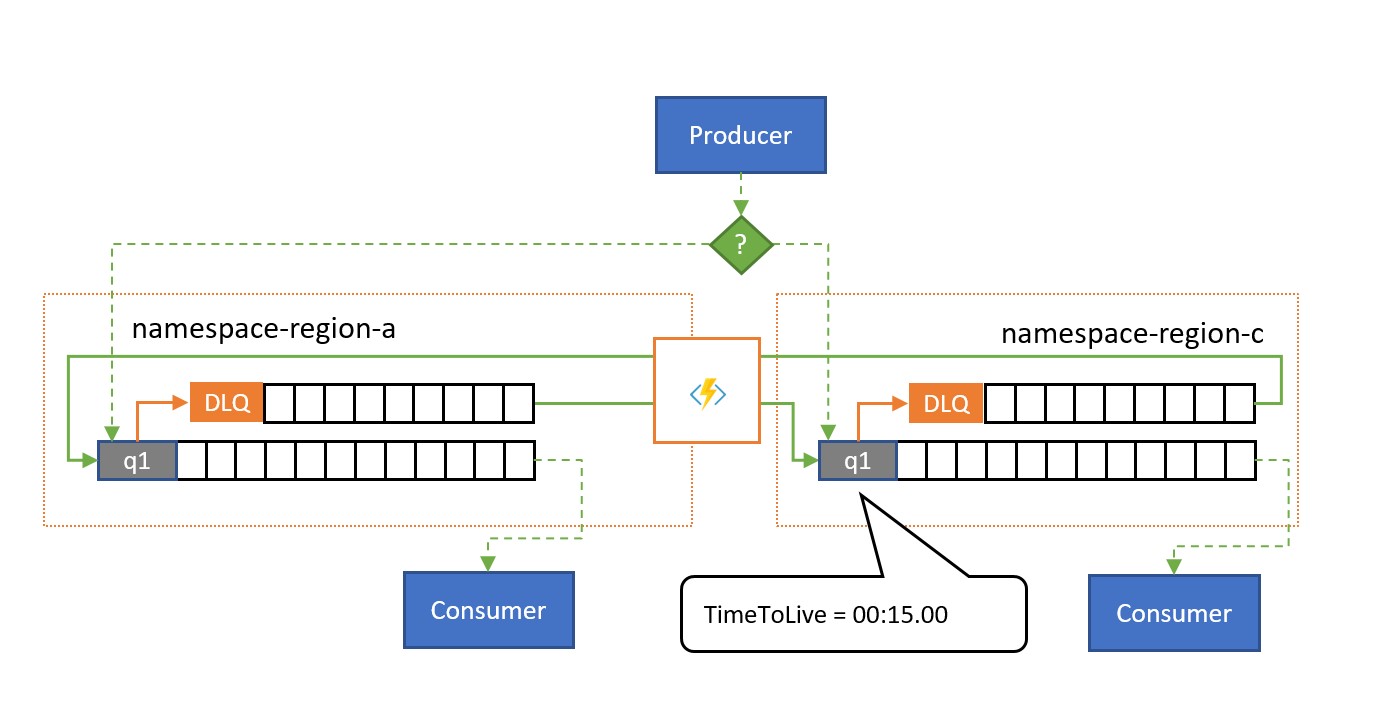
Jak pokazano na ilustracji, wzorzec replikacji rozlania replikuje komunikaty ze skojarzonej kolejki kolejki lub subskrypcji do sparowanej kolejki lub tematu w innej przestrzeni nazw.
Bez wystąpienia awarii dwie przestrzenie nazw są używane równolegle, z których każdy otrzymuje jakiś podzbiór ogólnego ruchu komunikatów i skojarzonych z nimi odbiorców obsługujących ten podzbiór. Gdy jeden z konsumentów zacznie wykazywać wysokie wskaźniki niepowodzeń lub zatrzymuje się wprost, odpowiednie komunikaty trafią do kolejki utraconych komunikatów przez przekroczenie liczby dostaw lub wygaśnięcie. Zadania replikacji będą następnie pobierać je i ponownie kolejkować je w sparowanej kolejce, gdzie są następnie prezentowane w możliwej dobrej kondycji konsumenta.
Jeśli przetwarzanie musi nastąpić w określonym terminie, TimeToLive dla kolejki i/lub komunikatów należy ustawić tak, że przetwarzanie może nadal występować w czasie przez pomocniczą operację rozlania, na przykład TimeToLive może zostać ustawiona na połowę dozwolonego czasu.
Podobnie jak w przypadku wzorca all-active, aplikacja może dodać wskaźnik do komunikatu, czy komunikat został już zreplikowany raz, tak aby nie odbijał się między parą kolejek, ale są raczej publikowane w kolejce pomocniczej, która działa jako kolejka utraconych komunikatów dla wzorca złożonego.
Ten wzorzec jest odpowiedni w scenariuszach, w których głównym problemem jest obrona przed problemami z dostępnością w użytkownikach lub zasobach, na których polegają konsumenci, a także ponowne dystrybuowanie skoków ruchu w jednej z sparowanych kolejek. Zapewnia również ochronę przed jedną z przestrzeni nazw, które stają się niedostępne, jeśli konsumenci odczytują z obu kolejek, ale opóźnienie replikacji nałożone przez
TimeToLivewygaśnięcie może spowodować, że komunikaty w tym przedziale czasu utkną w niedostępnej przestrzeni nazw.
Optymalizacja opóźnienia
Tematy są używane do rozpowszechniania informacji dla wielu użytkowników. W niektórych przypadkach, zwłaszcza odbiorców z szeroką dystrybucją geograficzną, korzystne może być replikowanie komunikatów z tematu do tematu w pomocniczej przestrzeni nazw bliżej odbiorców.
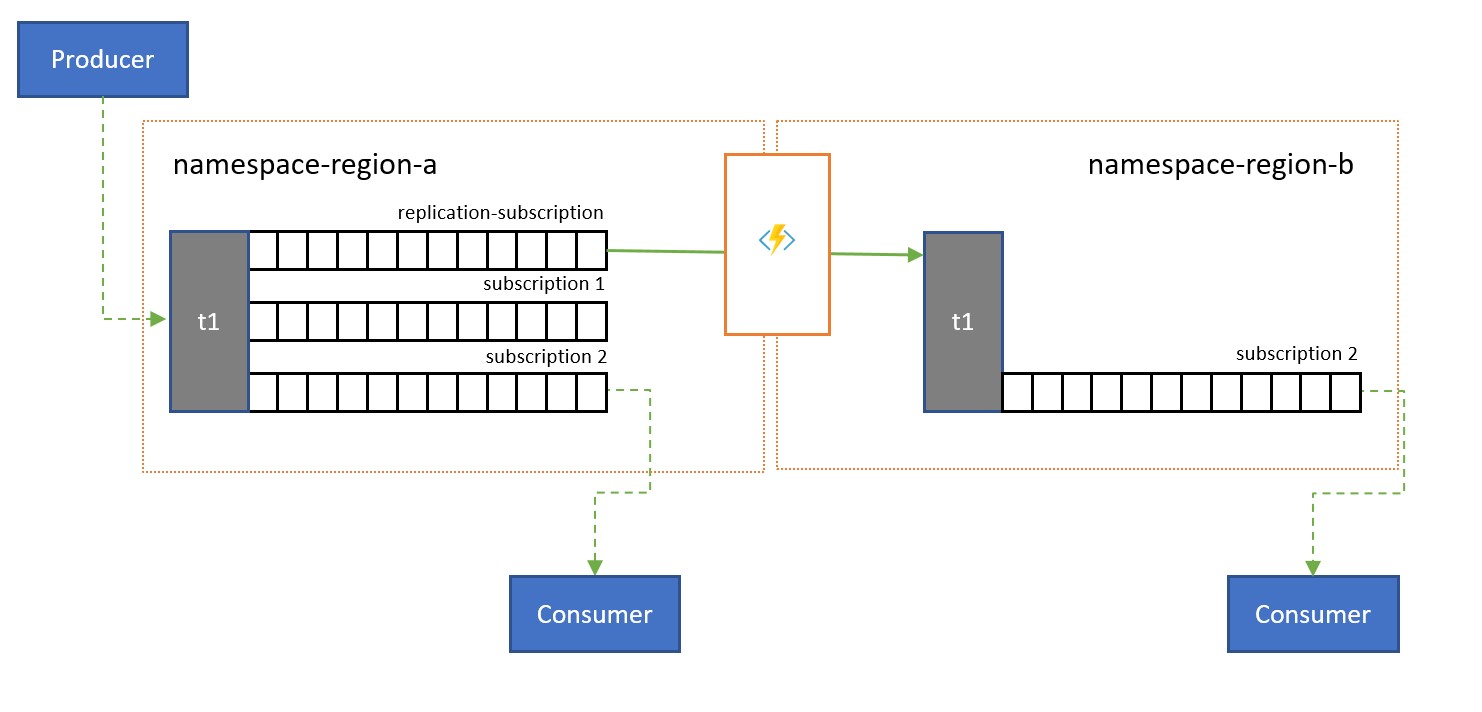
Na przykład w przypadku udostępniania danych między regionalnymi, kontynentalnymi koncentratorami bardziej wydajne jest przesyłanie informacji tylko raz między centrami i uzyskanie kopii danych z tych centrów przez użytkowników.
Transfery replikacji można wykonywać w partiach, które użytkownicy często uzyskują i rozliczają komunikaty pojedynczo. Z opóźnieniem sieci podstawowej 100 ms między, powiedzmy, Ameryka Północna i Europie, każdy komunikat trwa 200 ms dłużej, aby przetworzyć dwa rundy do jednostki zdalnej na potrzeby uzyskiwania i rozliczania komunikatów, w porównaniu z jednostką w tym samym regionie.
Walidacja, redukcja i wzbogacanie
Komunikaty mogą być przesyłane do kolejki lub tematu usługi Service Bus przez klientów spoza własnego rozwiązania.
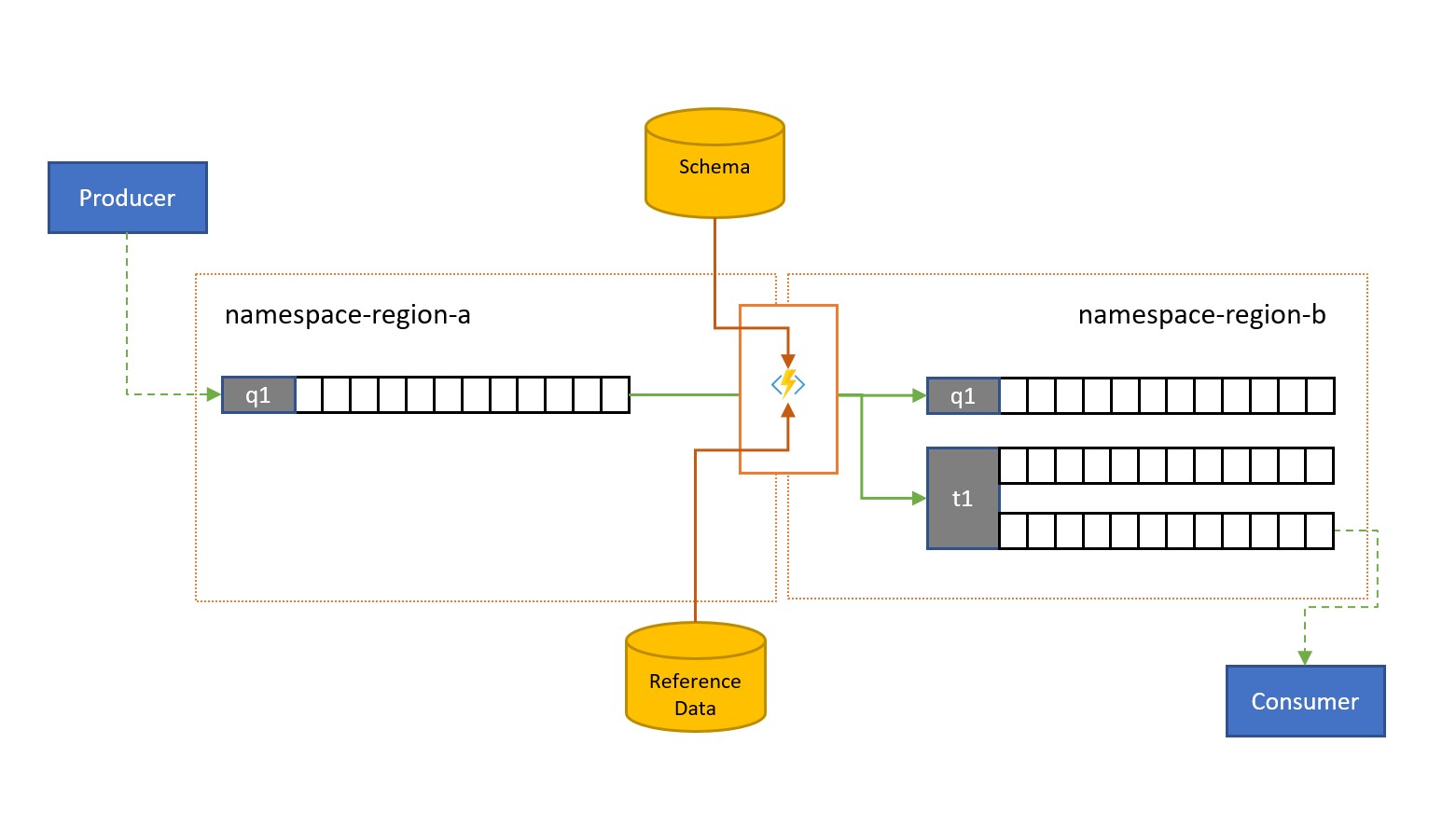
Takie komunikaty mogą wymagać sprawdzania zgodności z danym schematem oraz w celu usunięcia lub usunięcia niezgodnych komunikatów lub utraconych wiadomości. Niektóre komunikaty mogą być ograniczone w złożoności przez pominięcie danych, a niektóre mogą być wzbogacone przez dodanie danych na podstawie odnośników danych referencyjnych. Operacje można wykonywać za pomocą niestandardowych funkcji w zadaniu replikacji.
Replikacja strumienia do kolejki
Usługa Azure Event Hubs to idealne rozwiązanie do obsługi ekstremalnych woluminów zdarzeń przychodzących. Jednak ani usługa Event Hubs, ani podobne aparaty, takie jak Apache Kafka, nie zapewniają konkurencyjnego modelu konsumenta zarządzanego przez usługę, w którym wielu konsumentów może obsługiwać komunikaty z tego samego źródła jednocześnie bez ryzyka zduplikowanego przetwarzania, a na koniec rozstrzygnąć te komunikaty po ich przetworzeniu.
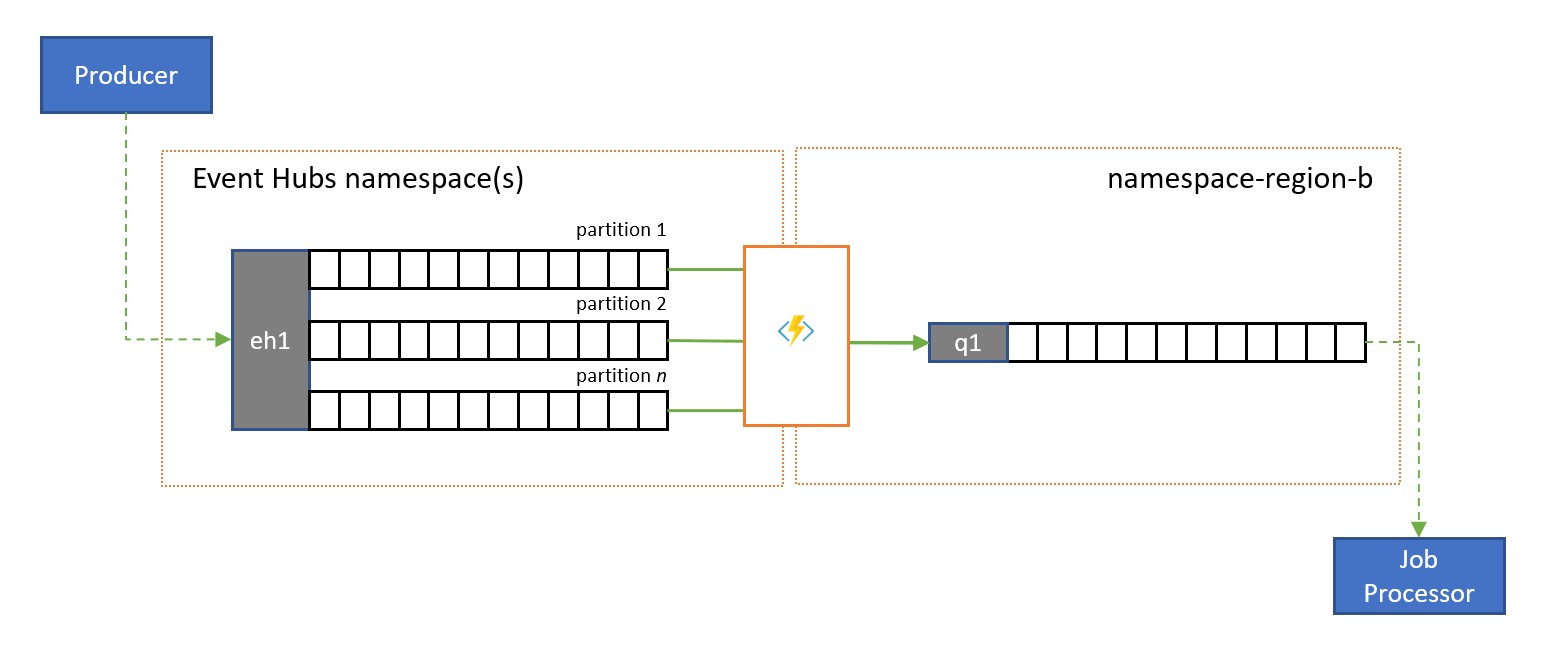
Strumień do kolejki replikacji transferuje zawartość pojedynczej partycji centrum zdarzeń lub zawartość pełnego centrum zdarzeń do kolejki usługi Service Bus, z której komunikaty mogą być bezpiecznie przetwarzane, transakcyjnie i z konkurencyjnymi użytkownikami. Ta replikacja umożliwia również korzystanie ze wszystkich innych funkcji usługi Service Bus dla tych komunikatów, w tym routingu z tematami i demultiplexing opartym na sesji.
Konsolidacja i normalizacja
Globalne rozwiązania często składają się z regionalnych śladów, które są w dużej mierze niezależne, w tym mają własne możliwości przetwarzania, ale ponad regionalne i globalne perspektywy będą wymagały integracji danych, a zatem centralna konsolidacja tych samych danych komunikatów, które są oceniane w odpowiednich regionalnych śladach dla perspektywy lokalnej.
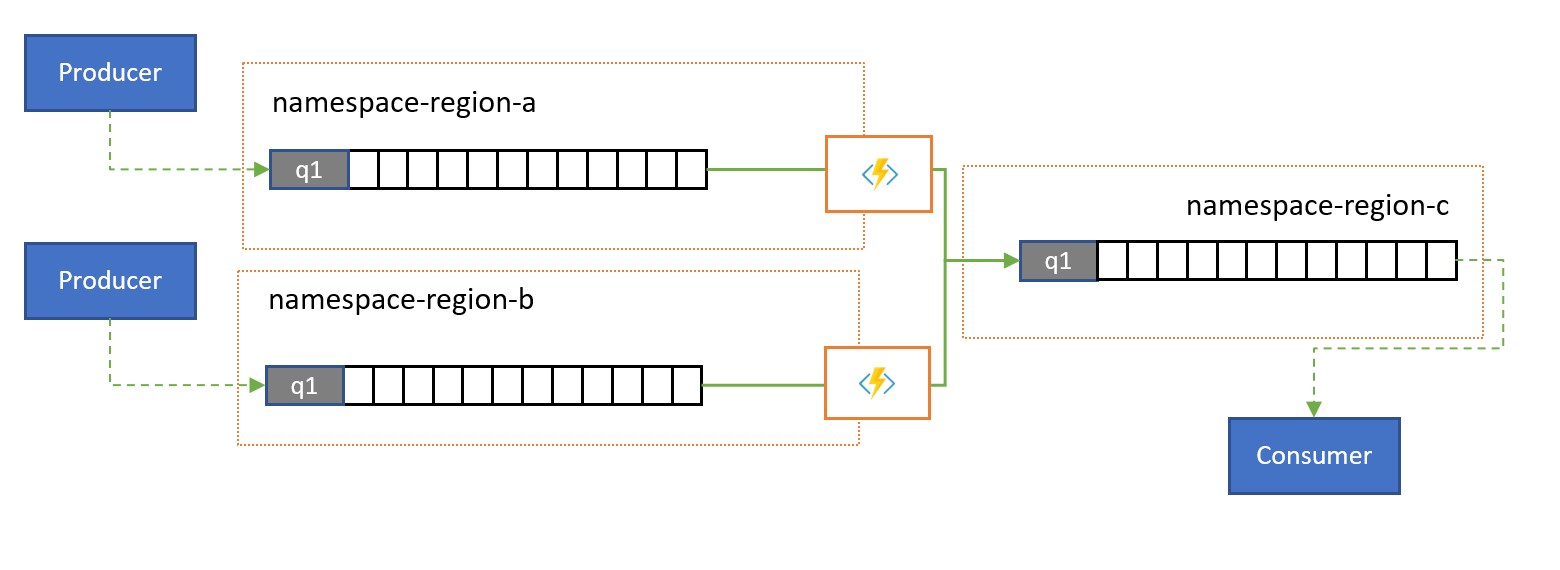
Normalizacja to odmiana scenariusza konsolidacji, w którym co najmniej dwie sekwencje przychodzące komunikatów zawierają takie same informacje, ale z różnymi strukturami lub różnymi kodowaniem, a komunikaty muszą być transkodowane lub przekształcane, zanim będą mogły być używane.
Normalizacja może również obejmować działanie kryptograficzne, takie jak odszyfrowywanie kompleksowych zaszyfrowanych ładunków i ponowne szyfrowanie go przy użyciu różnych kluczy i algorytmów dla odbiorców podrzędnych.
Dzielenie i routing
Tematy usługi Service Bus i ich reguły subskrypcji są często używane do filtrowania strumienia komunikatów dla określonych odbiorców, a następnie odbiorcy uzyskali filtrowany zestaw z subskrypcji.
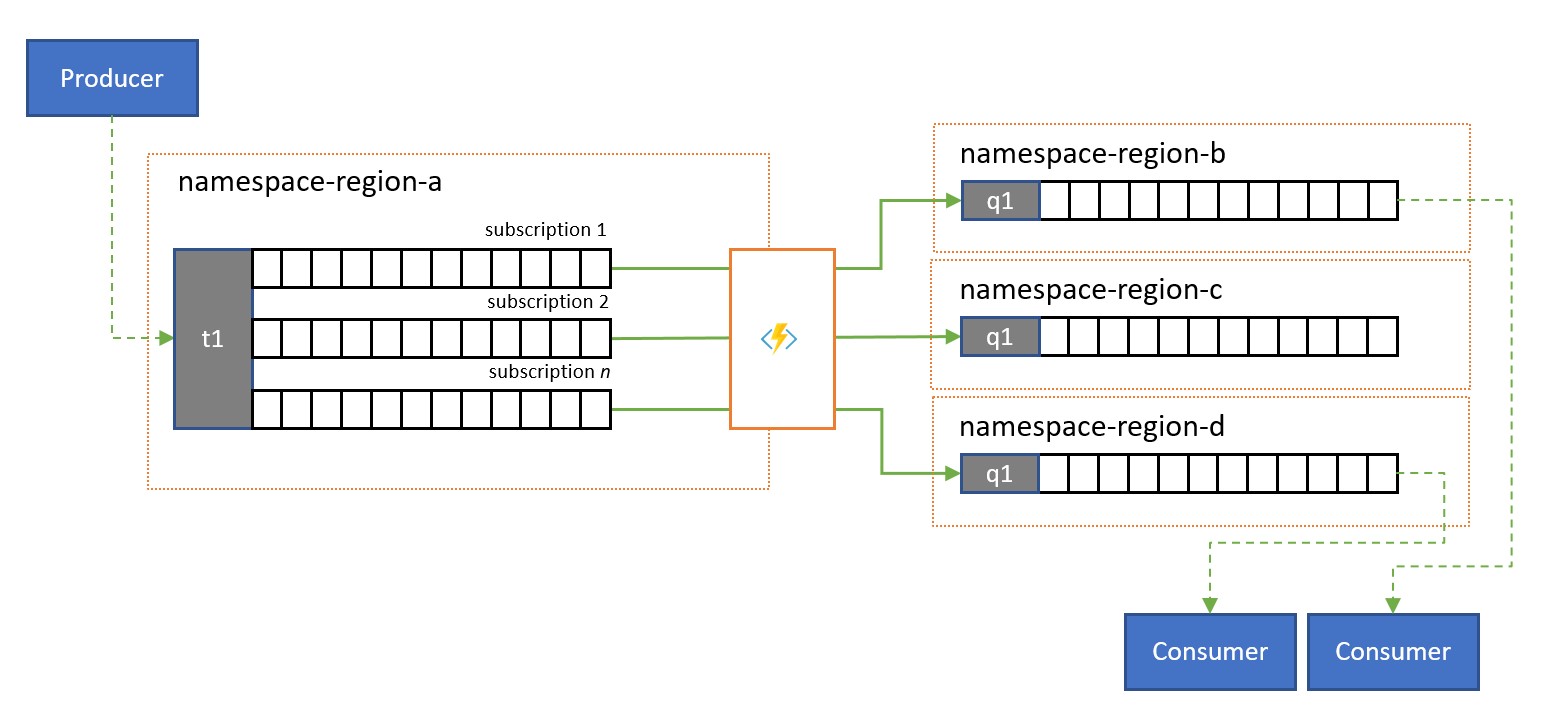
W systemie globalnym, w którym odbiorcy tych komunikatów są globalnie dystrybuowani lub należą do różnych aplikacji, replikacja może służyć do transferu komunikatów z takiej subskrypcji do kolejki lub tematu w innej przestrzeni nazw, od której są używane.
Aplikacje replikacji w usłudze Azure Functions
Zaimplementowanie powyższych wzorców wymaga skalowalnego i niezawodnego środowiska wykonywania dla zadań replikacji, które chcesz skonfigurować i uruchomić. Na platformie Azure środowisko uruchomieniowe, które najlepiej nadaje się do zadań bezstanowych, to usługa Azure Functions.
Usługa Azure Functions może działać w ramach tożsamości zarządzanej platformy Azure, tak aby zadania replikacji mogły zostać zintegrowane z regułami kontroli dostępu opartej na rolach usług źródłowych i docelowych bez konieczności zarządzania wpisami tajnymi wzdłuż ścieżki replikacji. W przypadku źródeł replikacji i obiektów docelowych, które wymagają jawnych poświadczeń, usługa Azure Functions może przechowywać wartości konfiguracji dla tych poświadczeń w ściśle kontrolowanym magazynie w usłudze Azure Key Vault.
Ponadto usługa Azure Functions umożliwia bezpośrednie integrowanie zadań replikacji z sieciami wirtualnymi i punktami końcowymi usługi platformy Azure dla wszystkich usług obsługi komunikatów platformy Azure i jest łatwo zintegrowane z usługą Azure Monitor.
Co najważniejsze, usługa Azure Functions ma wstępnie utworzone, skalowalne wyzwalacze i powiązania wyjściowe dla usług Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid i Azure Queue Storage, niestandardowe rozszerzenia dla oprogramowania RabbitMQ i Apache Kafka. Większość wyzwalaczy dynamicznie dostosowuje się do potrzeb przepływności, skalując liczbę współbieżnych wystąpień w górę i w dół na podstawie udokumentowanych metryk.
Dzięki planowi zużycia usługi Azure Functions wstępnie utworzone wyzwalacze mogą nawet być skalowane w dół do zera, podczas gdy żadne komunikaty nie są dostępne do replikacji, co oznacza, że nie ponosisz żadnych kosztów związanych z utrzymywaniem konfiguracji gotowej do skalowania kopii zapasowej w górę. Kluczową wadą korzystania z planu zużycia jest to, że opóźnienie zadań replikacji "przebudzenie" z tego stanu jest znacznie wyższe niż w przypadku planów hostingu, w których infrastruktura jest nadal uruchomiona.
W przeciwieństwie do tego wszystkiego najczęściej używane aparaty replikacji do obsługi komunikatów i zdarzeń, takie jak MirrorMaker platformy Apache Kafka, wymagają samodzielnego udostępnienia środowiska hostingu i skalowania aparatu replikacji. Obejmuje to konfigurowanie i integrowanie funkcji zabezpieczeń i sieci oraz ułatwianie przepływu danych monitorowania, a następnie nadal nie masz możliwości wstrzykiwania niestandardowych zadań replikacji do przepływu.
Zadania replikacji za pomocą usługi Azure Logic Apps
Alternatywą dla niekodowania replikacji przy użyciu usługi Functions byłoby użycie usługi Logic Apps . Usługa Logic Apps ma wstępnie zdefiniowane zadania replikacji dla usługi Service Bus. Mogą one pomóc w konfigurowaniu replikacji między różnymi wystąpieniami i można je dostosować w celu dalszego dostosowywania.
Następne kroki
W tym artykule omówiliśmy szereg wzorców federacji i wyjaśniliśmy rolę usługi Azure Functions jako środowiska uruchomieniowego replikacji zdarzeń i komunikatów na platformie Azure.
Następnie możesz przeczytać, jak skonfigurować aplikację replikatora za pomocą usługi Azure Functions, a następnie jak replikować przepływy zdarzeń między usługą Event Hubs i różnymi innymi systemami obsługi zdarzeń i komunikatów: