Samouczek: optymalizowanie indeksowania przy użyciu interfejsu API wypychania
Usługa Azure AI Search obsługuje dwa podstawowe podejścia do importowania danych do indeksu wyszukiwania: wypychanie danych do indeksu programowo lub ściąganie danych przez wskazanie indeksatora usługi Azure AI Search w obsługiwanym źródle danych.
W tym samouczku wyjaśniono, jak efektywnie indeksować dane przy użyciu modelu wypychania, wsadując żądania i stosując strategię wycofywania wykładniczego. Możesz pobrać i uruchomić przykładową aplikację. W tym artykule wyjaśniono kluczowe aspekty aplikacji i czynniki, które należy wziąć pod uwagę podczas indeksowania danych.
W tym samouczku użyto języka C# i biblioteki Azure.Search.Documents z zestawu Azure SDK dla platformy .NET w celu wykonania następujących zadań:
- Tworzenie indeksu
- Testowanie różnych rozmiarów partii w celu określenia najbardziej wydajnego rozmiaru
- Indeksowanie wsadowe asynchronicznie
- Używanie wielu wątków do zwiększania szybkości indeksowania
- Użyj strategii ponawiania prób wycofywania wykładniczego, aby ponowić próbę niepowodzenia dokumentów
Wymagania wstępne
Na potrzeby tego samouczka wymagane są następujące usługi i narzędzia.
Subskrypcja Azure. Jeśli nie masz, możesz utworzyć bezpłatne konto.
Visual Studio, dowolna wersja. Przykładowy kod i instrukcje zostały przetestowane w bezpłatnej wersji Community.
Pobieranie plików
Kod źródłowy tego samouczka znajduje się w folderze optimize-data-indexing/v11 w repozytorium GitHub Azure-Samples/azure-search-dotnet-scale .
Najważniejsze zagadnienia
Poniżej wymieniono czynniki wpływające na szybkość indeksowania. Aby dowiedzieć się więcej, zobacz Indeksowanie dużych zestawów danych.
- Warstwa usługi i liczba partycji/replik: dodawanie partycji lub uaktualnianie warstwy zwiększa szybkość indeksowania.
- Złożoność schematu indeksu: dodawanie pól i właściwości pól zmniejsza szybkość indeksowania. Mniejsze indeksy są szybsze do indeksowania.
- Rozmiar partii: optymalny rozmiar partii różni się w zależności od schematu indeksu i zestawu danych.
- Liczba wątków/procesów roboczych: pojedynczy wątek nie korzysta z pełnych zalet indeksowania szybkości.
- Strategia ponawiania prób: Strategia ponawiania prób wykładniczego wycofywania jest najlepszym rozwiązaniem dla optymalnego indeksowania.
- Szybkość transferu danych sieciowych: szybkość transferu danych może być czynnikiem ograniczającym. Indeksowanie danych z poziomu środowiska platformy Azure w celu zwiększenia szybkości transferu danych.
Krok 1. Tworzenie usługa wyszukiwania sztucznej inteligencji platformy Azure
Aby ukończyć ten samouczek, potrzebujesz usługa wyszukiwania usługi Azure AI, którą można utworzyć w witrynie Azure Portal lub znaleźć istniejącą usługę w ramach bieżącej subskrypcji. Zalecamy użycie tej samej warstwy, która ma być używana w środowisku produkcyjnym, aby umożliwić dokładne testowanie i optymalizowanie szybkości indeksowania.
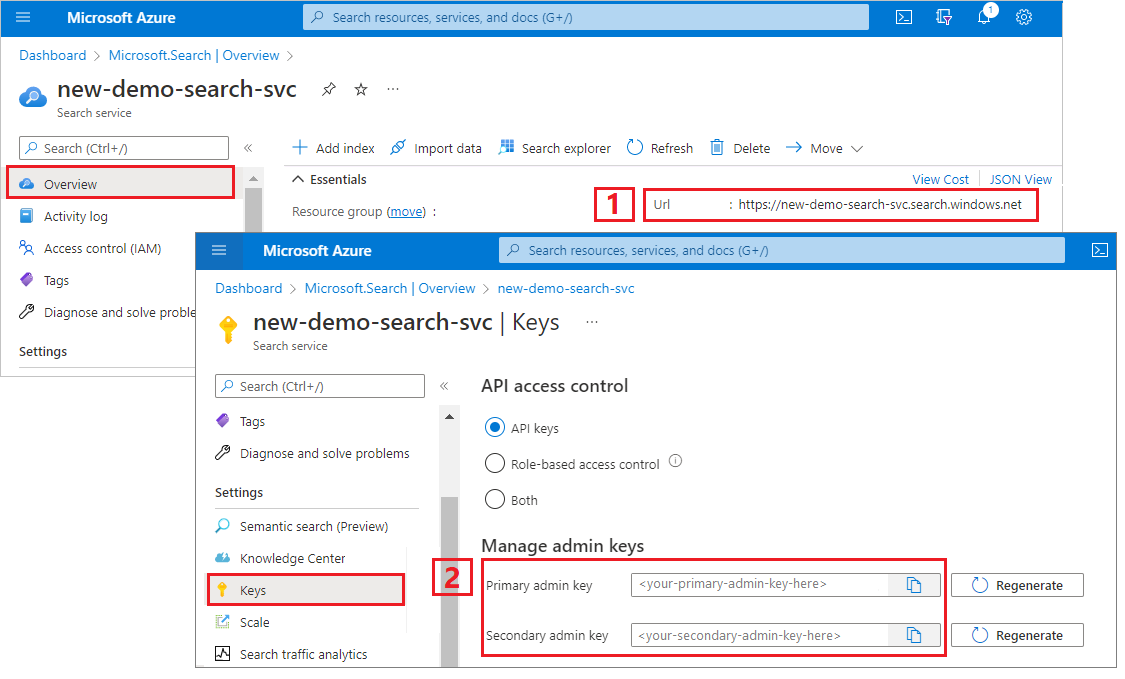
Uzyskiwanie klucza administratora i adresu URL usługi Azure AI Search
W tym samouczku jest używane uwierzytelnianie oparte na kluczach. Skopiuj klucz interfejsu API administratora, aby wkleić go do pliku appsettings.json .
Zaloguj się w witrynie Azure Portal. Pobierz adres URL punktu końcowego ze strony Przegląd usługi wyszukiwania. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Klucze ustawień>uzyskaj klucz administratora dla pełnych praw w usłudze. Istnieją dwa zamienne klucze administratora, które zapewniają ciągłość działania na wypadek konieczności przerzucania jednego. Możesz użyć klucza podstawowego lub pomocniczego na żądaniach dodawania, modyfikowania i usuwania obiektów.
Krok 2. Konfigurowanie środowiska
Uruchom program Visual Studio i otwórz OptimizeDataIndexing.sln.
W Eksplorator rozwiązań otwórz appsettings.json, aby udostępnić informacje o połączeniu usługi.
{
"SearchServiceUri": "https://{service-name}.search.windows.net",
"SearchServiceAdminApiKey": "",
"SearchIndexName": "optimize-indexing"
}
Krok 3. Eksplorowanie kodu
Po zaktualizowaniu appsettings.json przykładowy program w OptimizeDataIndexing.sln powinien być gotowy do skompilowania i uruchomienia.
Ten kod pochodzi z sekcji języka C# przewodnika Szybki start: wyszukiwanie pełnotekstowe przy użyciu zestawów SDK platformy Azure. Więcej szczegółowych informacji na temat pracy z zestawem .NET SDK można znaleźć w tym artykule.
Ta prosta aplikacja konsolowa C#/.NET wykonuje następujące zadania:
- Tworzy nowy indeks na podstawie struktury danych klasy C#
Hotel(która również odwołuje się doAddressklasy) - Testuje różne rozmiary partii w celu określenia najbardziej wydajnego rozmiaru
- Asynchronicznie indeksuje dane
- Używanie wielu wątków do zwiększania szybkości indeksowania
- Używanie strategii ponawiania prób wycofywania wykładniczego w celu ponawiania próby niepomyślnych elementów
Przed uruchomieniem programu pośmiń minutę na zbadanie kodu i definicji indeksu dla tego przykładu. Odpowiedni kod znajduje się w kilku plikach:
- Hotel.cs i Address.cs zawierają schemat definiujący indeks
- DataGenerator.cs zawiera prostą klasę, aby ułatwić tworzenie dużych ilości danych hotelowych
- ExponentialBackoff.cs zawiera kod umożliwiający optymalizację procesu indeksowania zgodnie z opisem w tym artykule
- Program.cs zawiera funkcje, które tworzą i usuwają indeks usługi Azure AI Search, indeksuje partie danych i testuje różne rozmiary partii
Tworzenie indeksu
Ten przykładowy program używa zestawu Azure SDK dla platformy .NET do definiowania i tworzenia indeksu usługi Azure AI Search.
FieldBuilder Korzysta z klasy, aby wygenerować strukturę indeksu na podstawie klasy modelu danych języka C#.
Model danych jest definiowany przez klasę Hotel , która zawiera również odwołania do Address klasy. Obiekt FieldBuilder przechodzi do szczegółów wielu definicji klas, aby wygenerować złożoną strukturę danych dla indeksu. Tagi metadanych służą do definiowania atrybutów każdego pola, takich jak możliwość wyszukiwania lub sortowania.
Poniższe fragmenty kodu z pliku Hotel.cs pokazują, jak można określić jedno pole i odwołanie do innej klasy modelu danych.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
W pliku Program.cs indeks jest definiowany z nazwą i kolekcją pól wygenerowaną przez FieldBuilder.Build(typeof(Hotel)) metodę, a następnie utworzoną w następujący sposób:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Generuj dane
Prosta klasa jest implementowana w pliku DataGenerator.cs w celu wygenerowania danych na potrzeby testowania. Jedynym celem tej klasy jest ułatwienie generowania dużej liczby dokumentów o unikatowym identyfikatorze indeksowania.
Aby uzyskać listę 100 000 hoteli z unikatowymi identyfikatorami, uruchom następujące wiersze kodu:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
W tym przykładzie dostępne są dwa rozmiary hoteli: małe i duże.
Schemat indeksu ma wpływ na szybkość indeksowania. Z tego powodu warto przekonwertować tę klasę na generowanie danych najlepiej pasujących do zamierzonego schematu indeksu po wykonaniu tego samouczka.
Krok 4. Testowanie rozmiarów partii
Usługa Azure AI Search obsługuje następujące interfejsy API do ładowania pojedynczych lub wielu dokumentów do indeksu:
Indeksowanie dokumentów w partiach znacznie poprawia wydajność indeksowania. Te partie mogą mieć maksymalnie 1000 dokumentów lub maksymalnie 16 MB na partię.
Określenie optymalnego rozmiaru partii danych jest kluczowym składnikiem optymalizacji szybkości indeksowania. Dwa podstawowe czynniki wpływające na optymalny rozmiar partii to:
- Schemat indeksu
- Rozmiar danych
Ponieważ optymalny rozmiar partii zależy od indeksu i danych, najlepszym rozwiązaniem jest przetestowanie różnych rozmiarów partii w celu określenia wyników najszybszych szybkości indeksowania dla danego scenariusza.
Poniższa funkcja przedstawia proste podejście do testowania rozmiarów partii.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Ponieważ nie wszystkie dokumenty mają ten sam rozmiar (chociaż znajdują się w tym przykładzie), szacujemy rozmiar danych wysyłanych do usługi wyszukiwania. Można to zrobić przy użyciu następującej funkcji, która najpierw konwertuje obiekt na format json, a następnie określa jego rozmiar w bajtach. Ta technika pozwala nam określić, które rozmiary partii są najbardziej wydajne pod względem szybkości indeksowania MB/s.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Funkcja wymaga SearchClient plus liczby prób, które chcesz przetestować dla każdego rozmiaru partii. Ze względu na to, że może istnieć zmienność czasów indeksowania dla każdej partii, spróbuj wykonać każdą partię trzy razy, aby wyniki były bardziej statystycznie znaczące.
await TestBatchSizesAsync(searchClient, numTries: 3);
Po uruchomieniu funkcji w konsoli powinny zostać wyświetlone dane wyjściowe podobne do następującego przykładu:
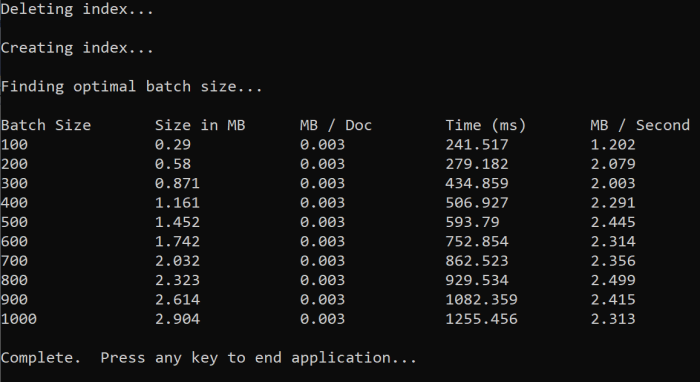
Zidentyfikuj, który rozmiar partii jest najbardziej wydajny, a następnie użyj tego rozmiaru partii w następnym kroku samouczka. Możesz zobaczyć plateau w MB/s w różnych rozmiarach partii.
Krok 5. Indeksowanie danych
Po zidentyfikowaniu rozmiaru partii, którego zamierzasz użyć, następnym krokiem jest rozpoczęcie indeksowania danych. Aby efektywnie indeksować dane, ten przykład:
- używa wielu wątków/procesów roboczych
- implementuje strategię wycofywania wykładniczego ponawiania prób
Usuń komentarz wiersze od 41 do 49, a następnie uruchom ponownie program. W tym przebiegu przykład generuje i wysyła partie dokumentów do 100 000, jeśli uruchamiasz kod bez zmiany parametrów.
Używanie wielu wątków/procesów roboczych
Aby w pełni wykorzystać szybkość indeksowania usługi Azure AI Search, użyj wielu wątków do wysyłania żądań indeksowania wsadowego współbieżnie do usługi.
Kilka kluczowych zagadnień, o których wspomniano wcześniej, może mieć wpływ na optymalną liczbę wątków. Możesz zmodyfikować ten przykład i przetestować z różnymi liczbami wątków, aby określić optymalną liczbę wątków dla danego scenariusza. Jednak tak długo, jak masz kilka wątków uruchomionych jednocześnie, powinno być możliwe wykorzystanie większości zysków wydajności.
Podczas zwiększania liczby żądań osiąganych przez usługę wyszukiwania mogą wystąpić kody stanu HTTP wskazujące, że żądanie nie powiodło się w pełni. Podczas indeksowania dwa typowe kody stanu HTTP to:
- 503 Usługa niedostępna: ten błąd oznacza, że system jest obciążony dużym obciążeniem i nie można w tej chwili przetworzyć żądania.
- 207 Stan wielokrotny: ten błąd oznacza, że niektóre dokumenty zakończyły się pomyślnie, ale co najmniej jeden błąd.
Implementowanie strategii ponawiania prób wykładniczego wycofywania
Jeśli wystąpi awaria, żądania powinny zostać ponowione przy użyciu strategii ponawiania prób wykładniczego.
Zestaw .NET SDK usługi Azure AI Search automatycznie ponawia próby 503 i inne żądania, które zakończyły się niepowodzeniem, ale należy zaimplementować własną logikę, aby ponowić próbę 207s. Narzędzia typu open source, takie jak Polly , mogą być przydatne w strategii ponawiania prób.
W tym przykładzie zaimplementujemy własną strategię wycofywania wykładniczego ponawiania prób. Zaczynamy od zdefiniowania niektórych zmiennych, w tym maxRetryAttempts i początkowego delay żądania, które zakończyło się niepowodzeniem:
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Wyniki operacji indeksowania są przechowywane w zmiennej IndexDocumentResult result. Ta zmienna jest ważna, ponieważ umożliwia sprawdzenie, czy jakiekolwiek dokumenty w partii nie powiodły się, jak pokazano w poniższym przykładzie. Jeśli wystąpi awaria częściowa, zostanie utworzona nowa partia na podstawie identyfikatora dokumentów, które zakończyły się niepowodzeniem.
RequestFailedException wyjątki powinny być również przechwytywane, ponieważ wskazują, że żądanie nie powiodło się całkowicie i należy je również ponowić.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Z tego miejsca zawijaj kod wycofywania wykładniczego do funkcji, aby można było ją łatwo wywołać.
Następnie jest tworzona inna funkcja do zarządzania aktywnymi wątkami. Dla uproszczenia ta funkcja nie jest tutaj dołączona, ale można znaleźć w ExponentialBackoff.cs. Funkcję można wywołać za pomocą następującego polecenia, w którym hotels są dane, które chcemy przekazać, 1000 to rozmiar partii i 8 liczba współbieżnych wątków:
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Po uruchomieniu funkcji powinny zostać wyświetlone dane wyjściowe:
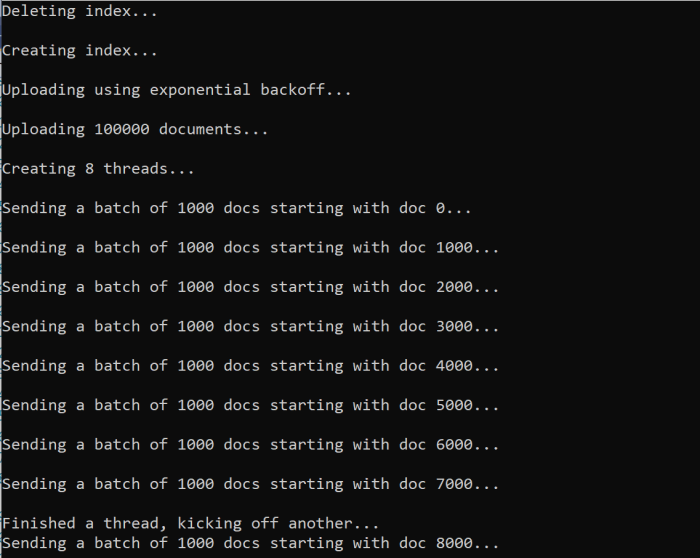
Gdy partia dokumentów zakończy się niepowodzeniem, zostanie wydrukowany błąd wskazujący błąd i że partia jest ponawiana:
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Po zakończeniu działania funkcji można sprawdzić, czy wszystkie dokumenty zostały dodane do indeksu.
Krok 6. Eksplorowanie indeksu
Możesz eksplorować wypełniony indeks wyszukiwania po uruchomieniu programu programowo lub za pomocą Eksploratora wyszukiwania w witrynie Azure Portal.
Programowo
Istnieją dwie główne opcje sprawdzania liczby dokumentów w indeksie: interfejs API zliczanie dokumentów i interfejs API pobierania statystyk indeksu. Obie ścieżki wymagają czasu na przetworzenie, więc nie należy się martwić, jeśli liczba zwróconych dokumentów jest początkowo niższa niż oczekiwano.
Liczba dokumentów
Operacja Liczba dokumentów pobiera liczbę dokumentów w indeksie wyszukiwania:
long indexDocCount = await searchClient.GetDocumentCountAsync();
Pobieranie statystyk indeksu
Operacja Pobierz statystykę indeksu zwraca liczbę dokumentów dla bieżącego indeksu oraz użycie magazynu. Aktualizowanie statystyk indeksu trwa dłużej niż liczba dokumentów.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure Portal
W witrynie Azure Portal w okienku nawigacji po lewej stronie znajdź indeks optymalizacji indeksowania na liście Indeksy .

Liczba dokumentów i rozmiar magazynu są oparte na interfejsie API pobierania statystyk indeksu i aktualizacja może potrwać kilka minut.
Resetowanie i ponowne uruchamianie
Na wczesnym etapie eksperymentalnym programowania najbardziej praktycznym podejściem do iteracji projektowej jest usunięcie obiektów z usługi Azure AI Search i umożliwienie ponownego kompilowania kodu. Nazwy zasobów są unikatowe. Usunięcie obiektu umożliwia jego ponowne utworzenie przy użyciu tej samej nazwy.
Przykładowy kod tego samouczka sprawdza istniejące indeksy i usuwa je, aby można było ponownie uruchomić kod.
Możesz również użyć witryny Azure Portal do usunięcia indeksów.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w witrynie Azure Portal i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Następny krok
Aby dowiedzieć się więcej na temat indeksowania dużych ilości danych, wypróbuj poniższy samouczek.