Samouczek: indeksowanie zagnieżdżonych obiektów blob języka Markdown z usługi Azure Storage przy użyciu interfejsu REST
Uwaga
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie jest zalecana w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Usługa Azure AI Search może indeksować dokumenty i tablice markdown w usłudze Azure Blob Storage przy użyciu indeksatora, który wie, jak odczytywać dane języka Markdown.
W tym samouczku pokazano, jak indeksować pliki markdown indeksowane przy użyciu oneToMany trybu analizowania języka Markdown. Używa klienta REST i interfejsów API REST wyszukiwania do wykonywania następujących zadań:
- Konfigurowanie przykładowych danych i konfigurowanie
azureblobźródła danych - Tworzenie indeksu usługi Azure AI Search zawierającego zawartość z możliwością wyszukiwania
- Tworzenie i uruchamianie indeksatora w celu odczytania kontenera i wyodrębnienia zawartości z możliwością wyszukiwania
- Przeszukać utworzony indeks
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Program Visual Studio Code z klientem REST.
Azure AI Search. Utwórz lub znajdź istniejący zasób usługi Azure AI Search w ramach bieżącej subskrypcji.
Uwaga
W tym samouczku możesz skorzystać z bezpłatnej usługi. Bezpłatna usługa wyszukiwania ogranicza do trzech indeksów, trzech indeksatorów i trzech źródeł danych. W ramach tego samouczka tworzony jest jeden element każdego z tych typów. Przed rozpoczęciem upewnij się, że masz pokój w usłudze, aby zaakceptować nowe zasoby.
Tworzenie dokumentu markdown
Skopiuj i wklej następujący kod Markdown do pliku o nazwie sample_markdown.md. Przykładowe dane to pojedynczy plik markdown zawierający różne elementy języka Markdown. Wybraliśmy jeden plik Markdown, aby pozostać w granicach magazynu warstwy Bezpłatna.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
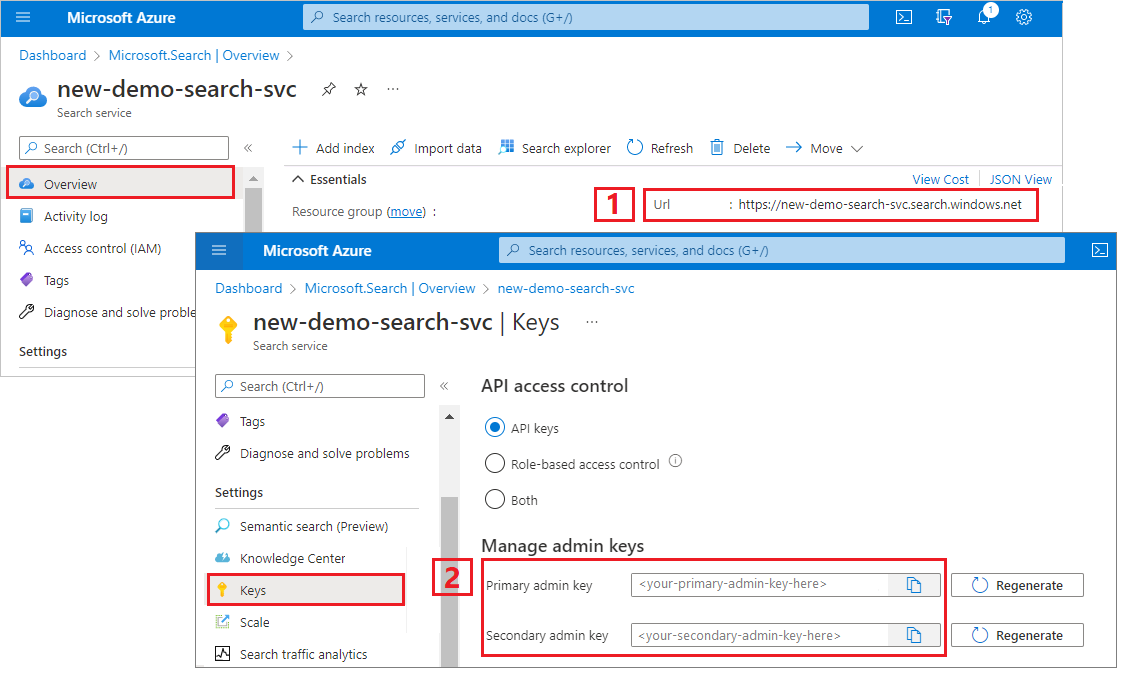
Kopiowanie adresu URL usługi wyszukiwania i klucza interfejsu API
Na potrzeby tego samouczka połączenia z usługą Azure AI Search wymagają punktu końcowego i klucza interfejsu API. Te wartości można uzyskać w witrynie Azure Portal. Aby zapoznać się z alternatywnymi metodami połączenia, zobacz tożsamości zarządzane.
Zaloguj się do witryny Azure Portal, przejdź do strony Przegląd usługi wyszukiwania i skopiuj adres URL. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Klucze ustawień>skopiuj klucz administratora. Klucze administracyjne służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
Konfigurowanie pliku REST
Uruchom program Visual Studio Code i utwórz nowy plik.
Podaj wartości zmiennych używanych w żądaniu:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREZapisz plik przy użyciu
.restrozszerzenia lub.http.
Zobacz Szybki start: wyszukiwanie tekstu przy użyciu interfejsu REST , jeśli potrzebujesz pomocy dotyczącej klienta REST.
Utwórz źródło danych
Utwórz źródło danych (REST) tworzy połączenie ze źródłem danych, które określa, jakie dane mają być indeksowane.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Wyślij żądanie. Odpowiedź powinna wyglądać następująco:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Tworzenie indeksu
Tworzenie indeksu (REST) powoduje utworzenie indeksu wyszukiwania w usłudze wyszukiwania. Indeks określa wszystkie pola i ich atrybuty.
W analizowaniu "jeden do wielu" dokument wyszukiwania definiuje stronę "wiele" relacji. Pola określone w indeksie określają strukturę dokumentu wyszukiwania.
Potrzebne są tylko pola elementów języka Markdown, które obsługuje analizator. Wysyłane mogą być następujące pola:
content: ciąg zawierający nieprzetworzone znaczniki Markdown znalezione w określonej lokalizacji na podstawie metadanych nagłówka w tym momencie dokumentu.sections: obiekt zawierający pola podrzędne metadanych nagłówka do żądanego poziomu nagłówka. Na przykład gdymarkdownHeaderDepthjest ustawiona wartośćh3, zawiera pola ciągówh1,h2ih3. Te pola są indeksowane przez dublowanie tej struktury w indeksie lub mapowania pól w formacie/sections/h1,sections/h2itp. Zobacz konfiguracje indeksu i indeksatora w poniższych przykładach, aby zapoznać się z przykładami w kontekście. Zawarte pola podrzędne to:-
h1- Ciąg zawierający wartość nagłówka h1. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie. - (Opcjonalnie)
h2- Ciąg zawierający wartość nagłówka h2. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie. - (Opcjonalnie)
h3- Ciąg zawierający wartość nagłówka h3. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie. - (Opcjonalnie)
h4- Ciąg zawierający wartość nagłówka h4. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie. - (Opcjonalnie)
h5- Ciąg zawierający wartość nagłówka h5. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie. - (Opcjonalnie)
h6- Ciąg zawierający wartość nagłówka h6. Pusty ciąg, jeśli nie zostanie ustawiony w tym momencie w dokumencie.
-
ordinal_position: wartość całkowita wskazująca położenie sekcji w hierarchii dokumentów. To pole służy do porządkowania sekcji w oryginalnej sekwencji, gdy pojawiają się w dokumencie, począwszy od porządkowego położenia 1 i przyrostowego sekwencyjnie dla każdego bloku zawartości.
Ta implementacja wykorzystuje mapowania pól w indeksatorze do mapowania ze wzbogaconej zawartości do indeksu. Aby uzyskać więcej informacji na temat analizowanej struktury dokumentów jeden do wielu, zobacz indeksowanie obiektów blob markdown.
W tym przykładzie przedstawiono przykłady sposobu indeksowania danych zarówno przy użyciu mapowań pól, jak i bez. W tym przypadku wiemy, że h1 zawiera tytuł dokumentu, więc możemy zamapować go na pole o nazwie title. Będziemy również mapować h2 pola i h3 odpowiednio na h2_subheader i h3_subheader . Pola content i ordinal_position nie wymagają mapowania, ponieważ są wyodrębniane z języka Markdown bezpośrednio do pól przy użyciu tych nazw. Aby zapoznać się z przykładem pełnego schematu indeksu, który nie wymaga mapowań pól, zobacz koniec tej sekcji.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Schemat indeksu w konfiguracji bez mapowań pól
Mapowania pól umożliwiają manipulowanie i filtrowanie wzbogaconej zawartości w celu dopasowania ich do żądanego kształtu indeksu, ale możesz po prostu chcieć bezpośrednio pobrać wzbogaconą zawartość. W takim przypadku schemat będzie wyglądać następująco:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Aby powtórzyć, mamy pola podrzędne do h3 w obiekcie sekcji, ponieważ markdownHeaderDepth jest ustawiona na h3wartość .
Jeśli zdecydujesz się użyć tego schematu, pamiętaj, aby odpowiednio dostosować późniejsze żądania. Będzie to wymagało usunięcia mapowań pól z konfiguracji indeksatora i zaktualizowania zapytań wyszukiwania w celu używania odpowiednich nazw pól.
Tworzenie i uruchamianie indeksatora
Tworzenie indeksatora tworzy indeksator w usłudze wyszukiwania. Indeksator łączy się ze źródłem danych, ładuje i indeksuje dane, a opcjonalnie udostępnia harmonogram automatyzowania odświeżania danych.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Kluczowe punkty:
Indeksator analizuje tylko nagłówki do
h3. Wszystkie nagłówki niższego poziomu (h4,h5,h6) będą traktowane jako zwykły tekst i wyświetlane wcontentpolu. Dlatego mapowania indeksów i pól istnieją tylko do głębokościh3.Pola
contentiordinal_positionnie wymagają mapowania pól, ponieważ istnieją z tymi nazwami w wzbogaconej zawartości.
Uruchamianie zapytań
Możesz rozpocząć wyszukiwanie zaraz po załadowaniu pierwszego dokumentu.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Wyślij żądanie. Jest to nieokreślone zapytanie wyszukiwania pełnotekstowego, które zwraca wszystkie pola oznaczone jako możliwe do pobrania w indeksie wraz z liczbą dokumentów. Odpowiedź powinna wyglądać następująco:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
search Dodaj parametr do wyszukiwania w ciągu.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Wyślij żądanie. Odpowiedź powinna wyglądać następująco:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Kluczowe punkty:
Ponieważ parametr
markdownHeaderDepthjest ustawiony nah3,h4nagłówki ,h5ih6są traktowane jako zwykły tekst, więc są wyświetlane wcontentpolu.Pozycja porządkowa w tym miejscu to
4. Ta zawartość jest wyświetlana na czwartym z 22 sekcji całkowitej zawartości.
Dodaj parametr, select aby ograniczyć wyniki do mniejszej liczby pól. Dodaj element , filter aby jeszcze bardziej zawęzić wyszukiwanie.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
W przypadku filtrów można również używać operatorów logicznych (i, a nie) i operatorów porównania (eq, ne, gt, lt, ge, le). W porównaniach ciągów jest rozróżniana wielkość liter. Aby uzyskać więcej informacji i przykładów, zobacz Tworzenie zapytania.
Uwaga
Parametr $filter działa tylko na polach oznaczonych jako filtrowalne podczas tworzenia indeksu.
Resetowanie i ponowne uruchamianie
Indeksatory można resetować, czyścić historię wykonywania, co umożliwia pełne ponowne uruchamianie. Następujące żądania GET są przeznaczone do resetowania, a następnie ponownie uruchamiane.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Za pomocą witryny Azure Portal można usuwać indeksy, indeksatory i źródła danych.
Następne kroki
Teraz, gdy znasz już podstawy indeksowania obiektów blob platformy Azure, przyjrzyjmy się bliżej konfiguracji indeksatora dla obiektów blob języka Markdown w usłudze Azure Storage.