Wysoka dostępność platformy SAP HANA skalowana w górę za pomocą usługi Azure NetApp Files w systemie RHEL
W tym artykule opisano sposób konfigurowania replikacji systemu SAP HANA we wdrożeniu skalowalnym w górę, gdy systemy plików HANA są instalowane za pośrednictwem systemu plików NFS przy użyciu usługi Azure NetApp Files. W przykładowych konfiguracjach i poleceniach instalacji używane są wystąpienia o numerze 03 i identyfikatorze systemu HANA HN1 . Replikacja systemu SAP HANA składa się z jednego węzła podstawowego i co najmniej jednego węzła pomocniczego.
Gdy kroki w tym dokumencie są oznaczone następującymi prefiksami, znaczenie jest następujące:
- [A]: Krok dotyczy wszystkich węzłów
- [1]: Krok dotyczy tylko węzła Node1
- [2]: Krok dotyczy tylko węzła Node2
Wymagania wstępne
Najpierw przeczytaj następujące uwagi i dokumenty SAP:
- 1928533 sap Note, które mają następujące elementy:
- Lista rozmiarów maszyn wirtualnych platformy Azure obsługiwanych na potrzeby wdrażania oprogramowania SAP.
- Ważne informacje o pojemności dla rozmiarów maszyn wirtualnych platformy Azure.
- Obsługiwane kombinacje oprogramowania SAP i systemu operacyjnego (OS) i bazy danych.
- Wymagana wersja jądra SAP dla systemów Windows i Linux na platformie Microsoft Azure.
- Program SAP Note 2015553 zawiera listę wymagań wstępnych dotyczących wdrożeń oprogramowania SAP obsługiwanych przez oprogramowanie SAP na platformie Azure.
- Program SAP Note 405827 zawiera listę zalecanych systemów plików dla środowisk HANA.
- Program SAP Note 2002167 ma zalecane ustawienia systemu operacyjnego dla systemu Red Hat Enterprise Linux.
- Oprogramowanie SAP Note 2009879 zawiera wytyczne dotyczące oprogramowania SAP HANA dla systemu Red Hat Enterprise Linux.
- Program SAP Note 3108302 zawiera wytyczne dotyczące oprogramowania SAP HANA dla systemu Red Hat Enterprise Linux 9.x.
- Program SAP Note 2178632 zawiera szczegółowe informacje o wszystkich metrykach monitorowania zgłoszonych dla oprogramowania SAP na platformie Azure.
- Program SAP Note 2191498 ma wymaganą wersję agenta hosta SAP dla systemu Linux na platformie Azure.
- Program SAP Note 2243692 zawiera informacje o licencjonowaniu oprogramowania SAP w systemie Linux na platformie Azure.
- Program SAP Note 1999351 zawiera więcej informacji dotyczących rozwiązywania problemów z rozszerzeniem rozszerzonego monitorowania platformy Azure dla oprogramowania SAP.
- Witryna SAP Community Wiki zawiera wszystkie wymagane uwagi SAP dla systemu Linux.
- Planowanie i implementacja usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux
- Wdrażanie usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux
- Wdrażanie systemu SAP w systemie Linux w usłudze Azure Virtual Machines DBMS
- Replikacja systemu SAP HANA w klastrze Pacemaker
- Ogólna dokumentacja systemu Red Hat Enterprise Linux (RHEL):
- Dokumentacja systemu RHEL specyficzna dla platformy Azure:
- Zasady obsługi klastrów wysokiej dostępności RHEL — Maszyny wirtualne platformy Microsoft Azure jako elementy członkowskie klastra
- Instalowanie i konfigurowanie klastra wysokiej dostępności systemu Red Hat Enterprise Linux 7.4 (i nowszych) na platformie Microsoft Azure
- Konfigurowanie replikacji systemu SAP HANA w górę w klastrze Pacemaker, gdy systemy plików HANA znajdują się w udziałach NFS
- Woluminy NFS 4.1 w usłudze Azure NetApp Files dla platformy SAP HANA
Omówienie
Tradycyjnie w środowisku skalowalnym w górę wszystkie systemy plików platformy SAP HANA są instalowane z magazynu lokalnego. Konfigurowanie wysokiej dostępności replikacji systemu SAP HANA w systemie Red Hat Enterprise Linux jest publikowane w temacie Konfigurowanie replikacji systemu SAP HANA w systemie RHEL.
Aby osiągnąć wysoką dostępność oprogramowania SAP HANA systemu skalowania w górę w udziałach NFS usługi Azure NetApp Files , potrzebujemy więcej konfiguracji zasobów w klastrze, aby zasoby platformy HANA można było odzyskać, gdy jeden węzeł utraci dostęp do udziałów NFS w usłudze Azure NetApp Files. Klaster zarządza instalacjami systemu plików NFS, umożliwiając monitorowanie kondycji zasobów. Zależności między instalacjami systemu plików a zasobami sap HANA są wymuszane.
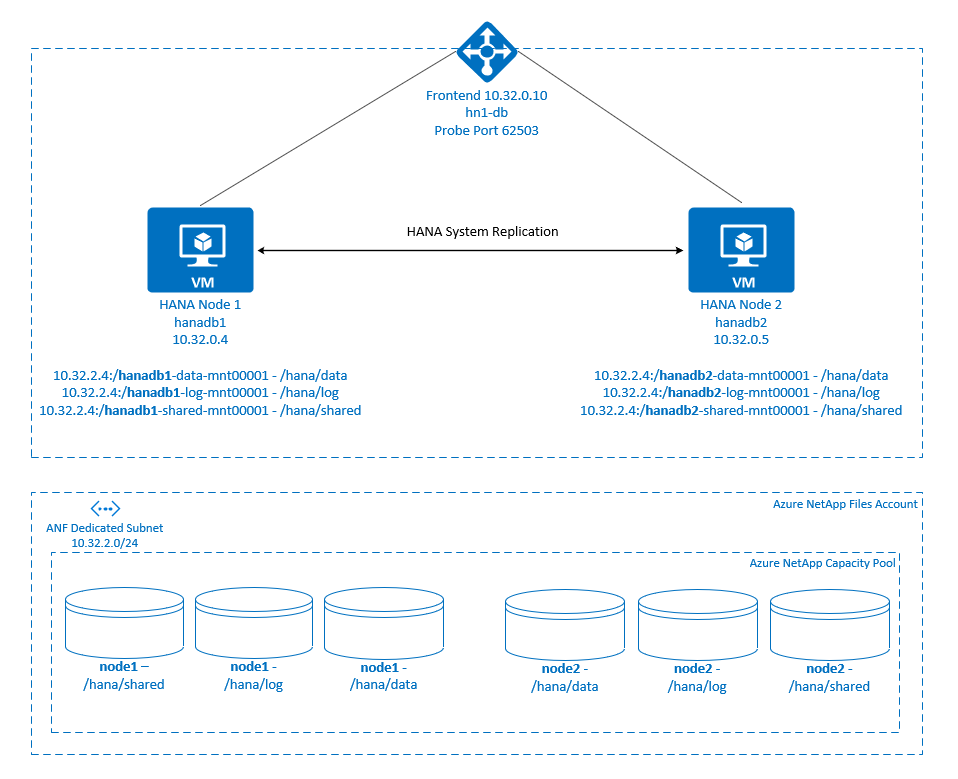 .
.
Systemy plików SAP HANA są instalowane w udziałach NFS przy użyciu usługi Azure NetApp Files w każdym węźle. Systemy /hana/dataplików , /hana/logi /hana/shared są unikatowe dla każdego węzła.
Zainstalowane w węźle Node1 (hanadb1):
- 10.32.2.4:/hanadb1-data-mnt00001 na /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 w witrynie /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 w witrynie /hana/shared
Zainstalowane w węźle Node2 (hanadb2):
- 10.32.2.4:/hanadb2-data-mnt00001 na /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 w witrynie /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 w witrynie /hana/shared
Uwaga
Systemy /hana/sharedplików , /hana/datai /hana/log nie są współużytkowane między dwoma węzłami. Każdy węzeł klastra ma własne oddzielne systemy plików.
Konfiguracja replikacji systemu SAP HANA używa dedykowanej wirtualnej nazwy hosta i wirtualnych adresów IP. Na platformie Azure moduł równoważenia obciążenia jest wymagany do korzystania z wirtualnego adresu IP. Konfiguracja pokazana tutaj zawiera moduł równoważenia obciążenia z:
- Adres IP frontonu: 10.32.0.10 dla hn1-db
- Port sondy: 62503
Konfigurowanie infrastruktury usługi Azure NetApp Files
Przed przystąpieniem do konfigurowania infrastruktury usługi Azure NetApp Files zapoznaj się z dokumentacją usługi Azure NetApp Files.
Usługa Azure NetApp Files jest dostępna w kilku regionach świadczenia usługi Azure. Sprawdź, czy wybrany region platformy Azure oferuje usługę Azure NetApp Files.
Aby uzyskać informacje na temat dostępności usługi Azure NetApp Files według regionu platformy Azure, zobacz Dostępność usługi Azure NetApp Files według regionu świadczenia usługi Azure.
Ważne uwagi
Podczas tworzenia woluminów usługi Azure NetApp Files dla systemów skalowania sap HANA w górę należy pamiętać o ważnych zagadnieniach opisanych w woluminach NFS w wersji 4.1 w usłudze Azure NetApp Files for SAP HANA.
Ustalanie rozmiaru bazy danych HANA w usłudze Azure NetApp Files
Przepływność woluminu usługi Azure NetApp Files jest funkcją rozmiaru woluminu i poziomu usługi, zgodnie z opisem w artykule Poziom usługi dla usługi Azure NetApp Files.
Podczas projektowania infrastruktury dla platformy SAP HANA na platformie Azure przy użyciu usługi Azure NetApp Files należy pamiętać o zaleceniach w woluminach NFS w wersji 4.1 w usłudze Azure NetApp Files for SAP HANA.
Konfiguracja w tym artykule jest przedstawiona z prostymi woluminami usługi Azure NetApp Files.
Ważne
W przypadku systemów produkcyjnych, w których wydajność jest kluczem, zalecamy ocenę i rozważenie użycia grupy woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA.
Wdrażanie zasobów usługi Azure NetApp Files
W poniższych instrukcjach założono, że sieć wirtualna platformy Azure została już wdrożona. Zasoby i maszyny wirtualne usługi Azure NetApp Files, w których zostaną zainstalowane zasoby usługi Azure NetApp Files, muszą zostać wdrożone w tej samej sieci wirtualnej platformy Azure lub w równorzędnych sieciach wirtualnych platformy Azure.
Utwórz konto usługi NetApp w wybranym regionie platformy Azure, postępując zgodnie z instrukcjami w temacie Tworzenie konta usługi NetApp.
Skonfiguruj pulę pojemności usługi Azure NetApp Files, postępując zgodnie z instrukcjami w temacie Konfigurowanie puli pojemności usługi Azure NetApp Files.
Architektura platformy HANA przedstawiona w tym artykule używa pojedynczej puli pojemności usługi Azure NetApp Files na poziomie usługi Ultra . W przypadku obciążeń HANA na platformie Azure zalecamy użycie warstwy Azure NetApp Files Ultra lub Premium.
Delegowanie podsieci do usługi Azure NetApp Files zgodnie z opisem w instrukcjach w temacie Delegowanie podsieci do usługi Azure NetApp Files.
Wdróż woluminy usługi Azure NetApp Files, postępując zgodnie z instrukcjami w temacie Tworzenie woluminu NFS dla usługi Azure NetApp Files.
Podczas wdrażania woluminów pamiętaj, aby wybrać wersję NFSv4.1. Wdróż woluminy w wyznaczonej podsieci usługi Azure NetApp Files. Adresy IP woluminów usługi Azure NetApp są przypisywane automatycznie.
Należy pamiętać, że zasoby usługi Azure NetApp Files i maszyny wirtualne platformy Azure muszą znajdować się w tej samej sieci wirtualnej platformy Azure lub w równorzędnych sieciach wirtualnych platformy Azure. Na przykład
hanadb1-data-mnt00001ihanadb1-log-mnt00001są nazwami woluminów infs://10.32.2.4/hanadb1-data-mnt00001nfs://10.32.2.4/hanadb1-log-mnt00001ścieżkami plików dla woluminów usługi Azure NetApp Files.W bazie danych hanadb1:
- Volume hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
W bazie danych hanadb2:
- Volume hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Uwaga
Wszystkie polecenia do zainstalowania /hana/shared w tym artykule są prezentowane dla woluminów NFSv4.1 /hana/shared .
Jeśli woluminy /hana/shared zostały wdrożone jako woluminy /hana/shared NFSv3, nie zapomnij dostosować poleceń instalacji dla systemu plików NFSv3.
Przygotowywanie infrastruktury
Witryna Azure Marketplace zawiera obrazy kwalifikowane dla platformy SAP HANA z dodatkiem wysokiej dostępności, którego można użyć do wdrażania nowych maszyn wirtualnych przy użyciu różnych wersji oprogramowania Red Hat.
Ręczne wdrażanie maszyn wirtualnych z systemem Linux za pośrednictwem witryny Azure Portal
W tym dokumencie założono, że grupa zasobów, sieć wirtualna platformy Azure i podsieć zostały już wdrożone.
Wdrażanie maszyn wirtualnych dla platformy SAP HANA. Wybierz odpowiedni obraz systemu RHEL obsługiwany przez system HANA. Maszynę wirtualną można wdrożyć w dowolnej z opcji dostępności: zestawu skalowania maszyn wirtualnych, strefy dostępności lub zestawu dostępności.
Ważne
Upewnij się, że wybrany system operacyjny ma certyfikat SAP dla platformy SAP HANA na określonych typach maszyn wirtualnych, które mają być używane we wdrożeniu. Możesz wyszukać typy maszyn wirtualnych z certyfikatem SAP HANA i ich wersje systemu operacyjnego na platformach IaaS certyfikowanych na platformie SAP HANA. Upewnij się, że zapoznasz się ze szczegółami typu maszyny wirtualnej, aby uzyskać pełną listę wersji systemu operacyjnego obsługiwanych przez platformę SAP HANA dla określonego typu maszyny wirtualnej.
Konfigurowanie modułu równoważenia obciążenia platformy Azure
Podczas konfigurowania maszyny wirtualnej masz możliwość utworzenia lub wybrania wyjścia z modułu równoważenia obciążenia w sekcji dotyczącej sieci. Wykonaj poniższe kroki, aby skonfigurować standardowy moduł równoważenia obciążenia na potrzeby konfiguracji bazy danych HANA o wysokiej dostępności.
Wykonaj kroki opisane w temacie Tworzenie modułu równoważenia obciążenia, aby skonfigurować standardowy moduł równoważenia obciążenia dla systemu SAP o wysokiej dostępności przy użyciu witryny Azure Portal. Podczas konfigurowania modułu równoważenia obciążenia należy wziąć pod uwagę następujące kwestie:
- Konfiguracja adresu IP frontonu: utwórz adres IP frontonu. Wybierz tę samą sieć wirtualną i nazwę podsieci co maszyny wirtualne bazy danych.
- Pula zaplecza: utwórz pulę zaplecza i dodaj maszyny wirtualne bazy danych.
- Reguły ruchu przychodzącego: utwórz regułę równoważenia obciążenia. Wykonaj te same kroki dla obu reguł równoważenia obciążenia.
- Adres IP frontonu: wybierz adres IP frontonu.
- Pula zaplecza: wybierz pulę zaplecza.
- Porty wysokiej dostępności: wybierz tę opcję.
- Protokół: wybierz pozycję TCP.
- Sonda kondycji: utwórz sondę kondycji z następującymi szczegółami:
- Protokół: wybierz pozycję TCP.
- Port: na przykład 625<instance-no.>.
- Interwał: wprowadź wartość 5.
- Próg sondy: wprowadź wartość 2.
- Limit czasu bezczynności (w minutach): wprowadź wartość 30.
- Włącz pływający adres IP: wybierz tę opcję.
Uwaga
Właściwość numberOfProbeskonfiguracji sondy kondycji , inaczej znana jako próg złej kondycji w portalu, nie jest uwzględniana. Aby kontrolować liczbę pomyślnych lub zakończonych niepowodzeniem kolejnych sond, ustaw właściwość probeThreshold na 2wartość . Obecnie nie można ustawić tej właściwości przy użyciu witryny Azure Portal, dlatego użyj interfejsu wiersza polecenia platformy Azure lub polecenia programu PowerShell.
Aby uzyskać więcej informacji na temat wymaganych portów dla platformy SAP HANA, przeczytaj rozdział Połączenia z bazami danych dzierżawy w przewodniku Bazy danych dzierżaw sap HANA lub Uwaga sap 2388694.
Uwaga
Jeśli maszyny wirtualne bez publicznych adresów IP są umieszczane w puli zaplecza wewnętrznego (bez publicznego adresu IP) wystąpienia usługi Azure Load Balancer w warstwie Standardowa, nie ma wychodzącej łączności z Internetem, chyba że zostanie wykonana więcej konfiguracji, aby umożliwić routing do publicznych punktów końcowych. Aby uzyskać więcej informacji na temat uzyskiwania łączności wychodzącej, zobacz Publiczna łączność punktu końcowego dla maszyn wirtualnych przy użyciu usługi Azure Load Balancer w warstwie Standardowa w scenariuszach wysokiej dostępności oprogramowania SAP.
Ważne
Nie włączaj sygnatur czasowych PROTOKOŁU TCP na maszynach wirtualnych platformy Azure umieszczonych za usługą Azure Load Balancer. Włączenie sygnatur czasowych protokołu TCP może spowodować niepowodzenie sond kondycji. Ustaw parametr net.ipv4.tcp_timestamps na wartość 0. Aby uzyskać więcej informacji, zobacz Load Balancer health probes (Sondy kondycji usługi Load Balancer) i SAP Note 2382421.
Instalowanie woluminu usługi Azure NetApp Files
[A] Tworzenie punktów instalacji dla woluminów bazy danych HANA.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Sprawdź ustawienie domeny NFS. Upewnij się, że domena jest skonfigurowana jako domyślna domena usługi Azure NetApp Files, czyli defaultv4iddomain.com, a mapowanie jest ustawione na nikogo.
sudo cat /etc/idmapd.confPrzykładowe wyjście:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyWażne
Upewnij się, że domena NFS na
/etc/idmapd.confmaszynie wirtualnej jest zgodna z domyślną konfiguracją domeny w usłudze Azure NetApp Files: defaultv4iddomain.com. Jeśli istnieje niezgodność między konfiguracją domeny na kliencie NFS (czyli maszyną wirtualną) i serwerem NFS (czyli konfiguracją usługi Azure NetApp Files), wówczas uprawnienia do plików na woluminach usługi Azure NetApp Files zainstalowanych na maszynach wirtualnych są wyświetlane jakonobody.[1] Zainstaluj woluminy specyficzne dla węzła w węźle 1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Zainstaluj woluminy specyficzne dla węzła w węźle Node2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Sprawdź, czy wszystkie woluminy HANA są zainstalowane przy użyciu protokołu NFS w wersji NFSv4.
sudo nfsstat -mSprawdź, czy flaga
versjest ustawiona na 4.1. Przykład z bazy danych hanadb1:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Sprawdź nfs4_disable_idmapping. Powinna być ustawiona wartość Y. Aby utworzyć strukturę katalogów, w której znajduje się nfs4_disable_idmapping , uruchom polecenie instalacji. Nie można ręcznie utworzyć katalogu w obszarze
/sys/modules, ponieważ dostęp jest zarezerwowany dla jądra i sterowników.Sprawdź element
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingJeśli musisz ustawić wartość
nfs4_disable_idmappingna:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingUstaw konfigurację na stałą.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confAby uzyskać więcej informacji na temat zmiany parametru
nfs_disable_idmapping, zobacz Bazę wiedzy Red Hat.
Instalacja oprogramowania SAP HANA
[A] Skonfiguruj rozpoznawanie nazw hostów dla wszystkich hostów.
Możesz użyć serwera DNS lub zmodyfikować
/etc/hostsplik na wszystkich węzłach. W tym przykładzie pokazano, jak używać/etc/hostspliku. Zastąp adres IP i nazwę hosta w następujących poleceniach:sudo vi /etc/hostsWstaw następujące wiersze w
/etc/hostspliku. Zmień adres IP i nazwę hosta, aby pasować do twojego środowiska.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Przygotowanie systemu operacyjnego do uruchamiania oprogramowania SAP HANA w usłudze Azure NetApp z systemem plików NFS zgodnie z opisem w temacie SAP Note 3024346 — Linux Kernel Settings for NetApp NFS (Ustawienia jądra systemu Linux dla systemu plików NetApp NFS). Utwórz plik
/etc/sysctl.d/91-NetApp-HANA.confkonfiguracji dla ustawień konfiguracji usługi NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confDodaj następujące wpisy w pliku konfiguracji.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Utwórz plik
/etc/sysctl.d/ms-az.confkonfiguracji z bardziej ustawieniami optymalizacji.sudo vi /etc/sysctl.d/ms-az.confDodaj następujące wpisy w pliku konfiguracji.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Napiwek
Unikaj ustawiania
net.ipv4.ip_local_port_rangeinet.ipv4.ip_local_reserved_portsjawnegosysctlw plikach konfiguracji, aby umożliwić agentowi hosta SAP zarządzanie zakresami portów. Aby uzyskać więcej informacji, zobacz sap Note 2382421.[A] Dostosuj
sunrpcustawienia zgodnie z zaleceniami w temacie SAP Note 3024346 — Ustawienia jądra systemu Linux dla systemu plików NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confWstaw następujący wiersz:
options sunrpc tcp_max_slot_table_entries=128[A] Wykonaj konfigurację systemu operacyjnego RHEL dla platformy HANA.
Skonfiguruj system operacyjny zgodnie z opisem w następujących informacjach SAP na podstawie wersji systemu RHEL:
- 2292690 — SAP HANA DB: zalecane ustawienia systemu operacyjnego dla RHEL 7
- 2777782 — SAP HANA DB: zalecane ustawienia systemu operacyjnego dla systemu RHEL 8
- 2455582 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 6.x
- 2593824 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 7.x
- 2886607 — Linux: uruchamianie aplikacji SAP skompilowanych przy użyciu biblioteki GCC 9.x
[A] Zainstaluj oprogramowanie SAP HANA.
Począwszy od wersji HANA 2.0 SPS 01, mdC jest opcją domyślną. Podczas instalowania systemu HANA system SYSTEMDB i dzierżawa z tym samym identyfikatorem SID są tworzone razem. W niektórych przypadkach nie chcesz, aby dzierżawa domyślna. Jeśli nie chcesz tworzyć dzierżawy początkowej wraz z instalacją, możesz skorzystać z 2629711 SAP Note.
Uruchom program hdblcm z dysku DVD HANA. Wprowadź następujące wartości w wierszu polecenia:
- Wybierz pozycję Instalacja: wprowadź wartość 1 (w przypadku instalacji).
- Wybierz więcej składników do instalacji: wprowadź wartość 1.
- Wprowadź ścieżkę instalacji [/hana/shared]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź nazwę hosta lokalnego [..]: Wybierz Enter, aby zaakceptować wartość domyślną. Czy chcesz dodać dodatkowe hosty do systemu? (y/n) [n]: n.
- Wprowadź identyfikator systemu SAP HANA: wprowadź wartość HN1.
- Wprowadź numer wystąpienia [00]: wprowadź wartość 03.
- Wybierz pozycję Tryb bazy danych / Wprowadź indeks [1]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wybierz pozycję Użycie systemu / Wprowadź indeks [4]: wprowadź wartość 4 (dla ustawienia niestandardowego).
- Wprowadź lokalizację woluminów danych [/hana/data]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź lokalizację woluminów dziennika [/hana/log]: wybierz Enter, aby zaakceptować wartość domyślną.
- Czy ograniczyć maksymalną alokację pamięci? [n]: Wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź nazwę hosta certyfikatu dla hosta "..." : wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź hasło użytkownika agenta hosta SAP (sapadm): wprowadź hasło użytkownika agenta hosta.
- Potwierdź hasło użytkownika agenta hosta SAP (sapadm): wprowadź ponownie hasło użytkownika agenta hosta, aby potwierdzić.
- Wprowadź hasło administratora systemu (hn1adm): wprowadź hasło administratora systemu.
- Potwierdź hasło administratora systemu (hn1adm): wprowadź ponownie hasło administratora systemu, aby potwierdzić.
- Wprowadź katalog główny administratora systemu [/usr/sap/HN1/home]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź wartość Powłoka logowania administratora systemu [/bin/sh]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź identyfikator użytkownika administratora systemu [1001]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź identyfikator grupy użytkowników (sapsys) [79]: wybierz Enter, aby zaakceptować wartość domyślną.
- Wprowadź hasło użytkownika bazy danych (SYSTEM): wprowadź hasło użytkownika bazy danych.
- Potwierdź hasło użytkownika bazy danych (SYSTEM): wprowadź ponownie hasło użytkownika bazy danych, aby potwierdzić.
- Uruchom ponownie system po ponownym uruchomieniu maszyny? [n]: Wybierz Enter, aby zaakceptować wartość domyślną.
- Czy chcesz kontynuować? (y/n): Zweryfikuj podsumowanie. Wprowadź y , aby kontynuować.
[A] Uaktualnij agenta hosta SAP.
Pobierz najnowsze archiwum agenta hosta SAP z centrum oprogramowania SAP i uruchom następujące polecenie, aby uaktualnić agenta. Zastąp ścieżkę do archiwum, aby wskazać pobrany plik:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Konfigurowanie zapory.
Utwórz regułę zapory dla portu sondy usługi Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
Konfigurowanie replikacji systemu SAP HANA
Wykonaj kroki opisane w temacie Konfigurowanie replikacji systemu SAP HANA w celu skonfigurowania replikacji systemu SAP HANA.
Konfiguracja klastra
W tej sekcji opisano kroki wymagane do bezproblemowego działania klastra, gdy platforma SAP HANA jest zainstalowana w udziałach NFS przy użyciu usługi Azure NetApp Files.
Tworzenie klastra Pacemaker
Wykonaj kroki opisane w temacie Konfigurowanie programu Pacemaker w systemie Red Hat Enterprise Linux na platformie Azure, aby utworzyć podstawowy klaster Pacemaker dla tego serwera HANA.
Ważne
Za pomocą systemowego programu SAP Startup Framework wystąpienia SAP HANA mogą być teraz zarządzane przez systemd. Minimalna wymagana wersja systemu Red Hat Enterprise Linux (RHEL) to RHEL 8 dla systemu SAP. Jak opisano w artykule SAP Note 3189534, wszelkie nowe instalacje oprogramowania SAP HANA SPS07 w wersji 70 lub nowszej albo aktualizacje systemów HANA do wersji HANA 2.0 SPS07 w wersji 70 lub nowszej, platforma SAP Startup framework zostanie automatycznie zarejestrowana w systemie.
W przypadku korzystania z rozwiązań wysokiej dostępności do zarządzania replikacją systemu SAP HANA w połączeniu z wystąpieniami sap HANA z obsługą systemu (zapoznaj się z artykułem SAP Note 3189534), należy wykonać dodatkowe kroki, aby zapewnić, że klaster wysokiej dostępności może zarządzać wystąpieniem SAP bez ingerencji systemu. Dlatego w przypadku systemu SAP HANA zintegrowanego z systemem dodatkowe kroki opisane w artykule Red Hat KBA 7029705 muszą być wykonywane we wszystkich węzłach klastra.
Implementowanie przypinania replikacji systemu python SAPHanaSR
Ten krok jest ważny, aby zoptymalizować integrację z klastrem i poprawić wykrywanie, gdy potrzebny jest tryb failover klastra. Zdecydowanie zalecamy skonfigurowanie haka języka Python SAPHanaSR. Wykonaj kroki opisane w temacie Implement the Python system replication hook SAPHanaSR(Implement the Python system replication hook SAPHanaSR).
Konfigurowanie zasobów systemu plików
W tym przykładzie każdy węzeł klastra ma własne systemy /hana/sharedplików NFS HANA , /hana/datai /hana/log.
[1] Przełącz klaster w tryb konserwacji.
sudo pcs property set maintenance-mode=true[1] Utwórz zasoby systemu plików dla instalacji hanadb1 .
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Utwórz zasoby systemu plików dla instalacji hanadb2 .
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsAtrybut
OCF_CHECK_LEVEL=20jest dodawany do operacji monitorowania, dzięki czemu każdy monitor wykonuje test odczytu/zapisu w systemie plików. Bez tego atrybutu operacja monitorowania sprawdza tylko, czy system plików jest zainstalowany. Może to być problem, ponieważ w przypadku utraty łączności system plików może pozostać zainstalowany, mimo że jest niedostępny.Atrybut
on-fail=fencejest również dodawany do operacji monitorowania. W przypadku tej opcji, jeśli operacja monitorowania zakończy się niepowodzeniem w węźle, ten węzeł jest natychmiast ogrodzony. Bez tej opcji domyślne zachowanie polega na zatrzymaniu wszystkich zasobów, które zależą od zasobu, którego działanie zakończyło się niepowodzeniem, ponowne uruchomienie zasobu, a następnie uruchomienie wszystkich zasobów, które zależą od zasobu, który zakończył się niepowodzeniem.Nie tylko to zachowanie może trwać długo, gdy zasób SAPHana zależy od zasobu, który zakończył się niepowodzeniem, ale może również całkowicie zakończyć się niepowodzeniem. Zasób SAPHana nie może zakończyć się pomyślnie, jeśli serwer NFS, na którym znajdują się pliki wykonywalne HANA, jest niedostępny.
Sugerowane wartości limitu czasu umożliwiają zasobom klastra wytrzymanie wstrzymania specyficznego dla protokołu związanego z odnawianiem dzierżawy NFSv4.1. Aby uzyskać więcej informacji, zobacz Artykuł NFS in NetApp Best practices (Najlepsze rozwiązanie dotyczące systemu plików NFS w usłudze NetApp). Przekroczenia limitu czasu w poprzedniej konfiguracji mogą być dostosowane do określonej konfiguracji sap.
W przypadku obciążeń wymagających wyższej przepływności rozważ użycie
nconnectopcji instalacji zgodnie z opisem w woluminach NFS w wersji 4.1 w usłudze Azure NetApp Files dla platformy SAP HANA. Sprawdź, czynconnectusługa Azure NetApp Files jest obsługiwana w wersji systemu Linux.[1] Konfigurowanie ograniczeń lokalizacji.
Skonfiguruj ograniczenia lokalizacji, aby upewnić się, że zasoby, które zarządzają unikatowymi instalacjami hanadb1, nigdy nie mogą działać w bazie danych hanadb2 i odwrotnie.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1Opcja jest ustawiona
resource-discovery=never, ponieważ unikatowe instalacji dla każdego węzła współużytkuje ten sam punkt instalacji. Na przykładhana_data1używa punktu/hana/datainstalacji , ahana_data2także używa punktu/hana/datainstalacji . Współużytkowanie tego samego punktu instalacji może spowodować wynik fałszywie dodatni dla operacji sondy, gdy stan zasobu jest sprawdzany podczas uruchamiania klastra, co z kolei może spowodować niepotrzebne zachowanie odzyskiwania. Aby uniknąć tego scenariusza, ustaw wartośćresource-discovery=never.[1] Konfigurowanie zasobów atrybutów.
Konfigurowanie zasobów atrybutów. Te atrybuty są ustawione na wartość true, jeśli są zainstalowane wszystkie instalacji systemu plików NFS węzła (
/hana/data,/hana/log, i/hana/data). W przeciwnym razie są one ustawione na wartość false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Konfigurowanie ograniczeń lokalizacji.
Skonfiguruj ograniczenia lokalizacji, aby upewnić się, że zasób atrybutu hanadb1 nigdy nie działa w bazie danych hanadb2 i odwrotnie.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Tworzenie ograniczeń kolejności.
Skonfiguruj ograniczenia porządkowania, aby zasoby atrybutów węzła uruchamiały się dopiero po zainstalowaniu wszystkich instalacji systemu plików NFS węzła.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeNapiwek
Jeśli konfiguracja obejmuje systemy plików, poza grupą
hanadb1_nfslubhanadb2_nfs, dołączsequential=falseopcję , aby nie było zależności porządkowania między systemami plików. Wszystkie systemy plików muszą zaczynać się przedhana_nfs1_active, ale nie muszą uruchamiać się w żadnej kolejności względem siebie. Aby uzyskać więcej informacji, zobacz Jak mogę konfigurowanie replikacji systemu SAP HANA w skalowaniu w górę w klastrze Pacemaker, gdy systemy plików HANA znajdują się w udziałach NFS
Konfigurowanie zasobów klastra SAP HANA
Wykonaj kroki opisane w temacie Tworzenie zasobów klastra SAP HANA, aby utworzyć zasoby sap HANA w klastrze. Po utworzeniu zasobów platformy SAP HANA należy utworzyć ograniczenie reguły lokalizacji między zasobami sap HANA i systemami plików (NFS mounts).
[1] Konfigurowanie ograniczeń między zasobami sap HANA a instalacjami systemu plików NFS.
Ograniczenia reguły lokalizacji są ustawiane tak, aby zasoby SAP HANA mogły być uruchamiane w węźle tylko wtedy, gdy są zainstalowane wszystkie instalacji systemu plików NFS węzła.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueW systemie RHEL 7.x:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueW systemie RHEL 8.x/9.x:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne true[1] Skonfiguruj ograniczenia kolejności, tak aby zasoby SAP w węźle zatrzymały się przed zatrzymaniem dla dowolnego z instalacji systemu plików NFS.
pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb2_nfsW systemie RHEL 7.x:
pcs constraint order stop SAPHana_HN1_03-master then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-master then stop hanadb2_nfsW systemie RHEL 8.x/9.x:
pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb2_nfsWyjmij klaster z trybu konserwacji.
sudo pcs property set maintenance-mode=falseSprawdź stan klastra i wszystkie zasoby.
Uwaga
Ten artykuł zawiera odwołania do terminu, którego firma Microsoft już nie używa. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
sudo pcs statusPrzykładowe wyjście:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Konfigurowanie replikacji systemu z obsługą aktywnego/odczytu platformy HANA w klastrze Pacemaker
Począwszy od platformy SAP HANA 2.0 SPS 01, oprogramowanie SAP umożliwia aktywne/odczytu konfiguracje replikacji systemu SAP HANA, gdzie pomocnicze systemy replikacji systemu SAP HANA mogą być aktywnie używane do obsługi obciążeń intensywnie działających w trybie odczytu. Aby obsługiwać taką konfigurację w klastrze, wymagany jest drugi wirtualny adres IP, który umożliwia klientom dostęp do pomocniczej bazy danych SAP HANA z obsługą odczytu.
Aby upewnić się, że lokacja replikacji dodatkowej będzie nadal dostępna po przejęciu, klaster musi przenieść wirtualny adres IP wokół z pomocniczym zasobem SAPHana.
Dodatkowa konfiguracja, która jest wymagana do zarządzania replikacją systemu z obsługą aktywnego/odczytu platformy HANA w klastrze Red Hat HA z drugim wirtualnym adresem IP, jest opisana w temacie Konfigurowanie replikacji systemu z obsługą aktywnego/odczytu platformy HANA w klastrze Pacemaker.
Przed kontynuowaniem upewnij się, że w pełni skonfigurowany klaster red Hat High Availability Cluster zarządzający bazą danych SAP HANA zgodnie z opisem w poprzednich sekcjach dokumentacji.
Testowanie konfiguracji klastra
W tej sekcji opisano sposób testowania konfiguracji.
Przed rozpoczęciem testu upewnij się, że program Pacemaker nie ma żadnej akcji nieudanej (za pośrednictwem stanu pcs), nie ma żadnych nieoczekiwanych ograniczeń lokalizacji (na przykład pozostawienia testu migracji) i że replikacja systemu HANA jest w stanie synchronizacji, na przykład za pomocą polecenia
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Sprawdź konfigurację klastra pod kątem scenariusza awarii, gdy węzeł utraci dostęp do udziału NFS (
/hana/shared).Agenci zasobów SAP HANA zależą od plików binarnych przechowywanych
/hana/sharedw celu wykonywania operacji podczas pracy w trybie failover. System/hana/sharedplików jest instalowany za pośrednictwem systemu plików NFS w przedstawionym scenariuszu.Trudno jest zasymulować awarię, w której jeden z serwerów traci dostęp do udziału NFS. Jako test można ponownie zainstalować system plików jako tylko do odczytu. To podejście sprawdza, czy klaster może przejść w tryb failover, jeśli dostęp do
/hana/sharedzostanie utracony w aktywnym węźle.Oczekiwany wynik: Podczas tworzenia
/hana/sharedjako systemu plików tylko do odczytu atrybut zasobuhana_shared1,OCF_CHECK_LEVELktóry wykonuje operacje odczytu/zapisu w systemach plików, kończy się niepowodzeniem. Nie można zapisać niczego w systemie plików i wykonać tryb failover zasobu HANA. Ten sam wynik jest oczekiwany, gdy węzeł HANA utraci dostęp do udziałów NFS.Stan zasobu przed rozpoczęciem testu:
sudo pcs statusPrzykładowe wyjście:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1Możesz umieścić
/hana/sharedw trybie tylko do odczytu w aktywnym węźle klastra, używając następującego polecenia:sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbspowoduje ponowne uruchomienie lub wyłączenie zasilania w oparciu o akcję ustawioną nastonith(pcs property show stonith-action). Gdy serwer (hanadb1) nie działa, zasób platformy HANA zostanie przeniesiony dohanadb2. Stan klastra można sprawdzić z poziomuhanadb2.sudo pcs statusPrzykładowe wyjście:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2Zalecamy dokładne przetestowanie konfiguracji klastra SAP HANA, wykonując również testy opisane w temacie Konfigurowanie replikacji systemu SAP HANA w systemie RHEL.