Niezawodność w usłudze Microsoft Fabric
W tym artykule opisano obsługę niezawodności w usłudze Microsoft Fabric oraz odporność regionalną ze strefami dostępności oraz odzyskiwaniem między regionami i ciągłością działalności biznesowej. Aby uzyskać bardziej szczegółowe omówienie niezawodności na platformie Azure, zobacz Niezawodność platformy Azure.
Obsługa strefy dostępności
Strefy dostępności są fizycznie oddzielnymi grupami centrów danych w każdym regionie świadczenia usługi Azure. Gdy jedna strefa ulegnie awarii, usługi mogą przejść w tryb failover do jednej z pozostałych stref.
Aby uzyskać więcej informacji na temat stref dostępności na platformie Azure, zobacz Co to są strefy dostępności?
Sieć szkieletowa wykonuje uzasadnione komercyjnie wysiłki w celu obsługi strefowo nadmiarowych stref dostępności, w których zasoby są automatycznie replikowane między strefami bez konieczności konfigurowania ani konfigurowania.
Wymagania wstępne
- Sieć szkieletowa obecnie zapewnia obsługę częściowej strefy dostępności w ograniczonej liczbie regionów. Ta częściowa obsługa strefy dostępności obejmuje środowiska (i/lub niektóre funkcje w środowisku).
- Środowiska takie jak strumienie zdarzeń nie obsługują stref dostępności.
- Inżynieria danych obsługuje strefy dostępności, jeśli używasz usługi OneLake. Jeśli używasz innych źródeł danych, takich jak ADLS Gen2, upewnij się, że magazyn strefowo nadmiarowy (ZRS) jest włączony.
- Dostępność strefy może lub nie jest dostępna dla środowisk sieci szkieletowej i/lub funkcji/funkcji, które są dostępne w wersji zapoznawczej.
- Bramy lokalne i duże modele semantyczne w usłudze Power BI nie obsługują stref dostępności.
- Usługa Data Factory (potoki) obsługuje strefy dostępności w regionie Europa Zachodnia, ale w przypadku awarii strefy mogą zakończyć się niepowodzeniem w przypadku awarii nowych lub przychodzących potoków.
Obsługiwane regiony
Sieć szkieletowa wykonuje uzasadnione komercyjnie wysiłki w celu zapewnienia obsługi stref dostępności w różnych regionach w następujący sposób:
| Ameryka Północna i Południowa | Power BI | Magazyny danych | Magazyny danych | Analiza w czasie rzeczywistym | Data Factory (potoki) | inżynierowie danych | SQL Database |
|---|---|---|---|---|---|---|---|
| Brazylia Południowa | |||||||
| Kanada Środkowa | |||||||
| Central US | |||||||
| East US | |||||||
| Wschodnie stany USA 2 | |||||||
| South Central US | |||||||
| Zachodnie stany USA 2 | |||||||
| Zachodnie stany USA 3 | |||||||
| Europa | Power BI | Magazyny danych | Magazyny danych | Analiza w czasie rzeczywistym | Data Factory (potoki) | inżynierowie danych | SQL Database |
| Francja Środkowa | |||||||
| Niemcy Środkowo-Zachodnie | |||||||
| Włochy Północne | |||||||
| Europa Północna | |||||||
| Norwegia Wschodnia | |||||||
| Polska Środkowa | |||||||
| Południowe Zjednoczone Królestwo | |||||||
| West Europe | |||||||
| Szwecja Środkowa | |||||||
| Bliski Wschód | Power BI | Magazyny danych | Magazyny danych | Analiza w czasie rzeczywistym | Data Factory (potoki) | inżynierowie danych | SQL Database |
| Katar Środkowy | |||||||
| Izrael Centralny | |||||||
| Afryka | Power BI | Magazyny danych | Magazyny danych | Analiza w czasie rzeczywistym | Data Factory (potoki) | inżynierowie danych | SQL Database |
| Północna Republika Południowej Afryki | |||||||
| Azja i Pacyfik | Power BI | Magazyny danych | Magazyny danych | Analiza w czasie rzeczywistym | Data Factory (potoki) | inżynierowie danych | SQL Database |
| Australia Wschodnia | |||||||
| Japonia Wschodnia | |||||||
| Southeast Asia |
Środowisko strefowe w dół
Podczas awarii całej strefy nie jest wymagana żadna akcja podczas odzyskiwania strefy. Możliwości sieci szkieletowej w regionach wymienionych w obsługiwanych regionach są automatycznie automatycznie przywracane i ponownie równoważące, aby korzystać ze strefy w dobrej kondycji. Uruchamianie zadań platformy Spark może zakończyć się niepowodzeniem, jeśli węzeł główny znajduje się w strefie niepowodzenia. W takim przypadku należy ponownie przesłać zadania.
Ważne
Chociaż firma Microsoft stara się zapewnić jednolitą i spójną obsługę strefy dostępności, w niektórych przypadkach awarii strefy dostępności pojemności sieci szkieletowej znajdujące się w regionach platformy Azure z wyższymi wahaniami zapotrzebowania klientów mogą wystąpić wyższe niż normalne opóźnienie.
Odzyskiwanie po awarii między regionami i ciągłość działania
Odzyskiwanie po awarii dotyczy odzyskiwania po wystąpieniu zdarzeń o dużym wpływie, takich jak klęski żywiołowe lub nieudane wdrożenia, które powodują przestoje i utratę danych. Niezależnie od przyczyny najlepszym rozwiązaniem dla awarii jest dobrze zdefiniowany i przetestowany plan odzyskiwania po awarii oraz projekt aplikacji, który aktywnie obsługuje odzyskiwanie po awarii. Zanim zaczniesz myśleć o tworzeniu planu odzyskiwania po awarii, zobacz Zalecenia dotyczące projektowania strategii odzyskiwania po awarii.
Jeśli chodzi o odzyskiwanie po awarii, firma Microsoft korzysta z modelu wspólnej odpowiedzialności. W modelu wspólnej odpowiedzialności firma Microsoft zapewnia dostępność infrastruktury bazowej i usług platformy. Jednocześnie wiele usług platformy Azure nie replikuje automatycznie danych ani nie wraca z regionu, w którym wystąpił błąd, aby przeprowadzić replikację krzyżową do innego regionu z włączoną obsługą. W przypadku tych usług odpowiadasz za skonfigurowanie planu odzyskiwania po awarii, który działa dla obciążenia. Większość usług uruchamianych na platformie Azure jako usługa (PaaS) oferuje funkcje i wskazówki dotyczące obsługi odzyskiwania po awarii. Funkcje specyficzne dla usługi umożliwiają szybkie odzyskiwanie w celu ułatwienia opracowania planu odzyskiwania po awarii.
W tej sekcji opisano plan odzyskiwania po awarii dla sieci szkieletowej, który ma pomóc organizacji w zachowaniu bezpieczeństwa danych i dostępności po wystąpieniu nieplanowanej awarii regionalnej. Plan obejmuje następujące tematy:
Replikacja między regionami: sieć szkieletowa oferuje replikację między regionami dla danych przechowywanych w usłudze OneLake. Możesz zrezygnować z tej funkcji lub zrezygnować z tej funkcji w zależności od wymagań.
Dostęp do danych po awarii: w regionalnym scenariuszu awarii sieć szkieletowa gwarantuje dostęp do danych z pewnymi ograniczeniami. Chociaż tworzenie lub modyfikowanie nowych elementów jest ograniczone po przejściu w tryb failover, głównym celem jest zapewnienie, że istniejące dane pozostają dostępne i nienaruszone.
Wskazówki dotyczące odzyskiwania: sieć szkieletowa zawiera ustrukturyzowany zestaw instrukcji, który przeprowadzi Cię przez proces odzyskiwania. Wskazówki ustrukturyzowane ułatwiają przejście z powrotem do regularnych operacji.
Usługa Power BI, obecnie część sieci szkieletowej, ma stały system odzyskiwania po awarii i oferuje następujące funkcje:
Domyślna opcja BCDR: usługa Power BI automatycznie uwzględnia możliwości odzyskiwania po awarii w domyślnej ofercie. Nie musisz wybierać ani aktywować tej funkcji oddzielnie.
Replikacja między regionami: usługa Power BI używa replikacji geograficznie nadmiarowej usługi Azure Storage i replikacji geograficznie nadmiarowej usługi Azure SQL w celu zagwarantowania, że wystąpienia kopii zapasowych istnieją w innych regionach i mogą być używane. Oznacza to, że dane są zduplikowane w różnych regionach, zwiększając ich dostępność i zmniejszając ryzyko związane z awariami regionalnymi.
Ciągłe usługi i dostęp po awarii: nawet podczas zakłóceń elementy usługi Power BI pozostają dostępne w trybie tylko do odczytu. Elementy obejmują semantyczne modele, raporty i pulpity nawigacyjne, dzięki czemu firmy mogą kontynuować procesy analizy i podejmowania decyzji bez znaczących przeszkód.
Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące wysokiej dostępności, trybu failover i odzyskiwania po awarii w usłudze Power BI
Ważne
W przypadku klientów, których regiony macierzyste nie mają regionu pary platformy Azure i mają wpływ na awarię, możliwość korzystania z pojemności sieci szkieletowej może zostać naruszona — nawet jeśli dane w tych pojemnościach zostaną zreplikowane. To ograniczenie jest powiązane z infrastrukturą regionu macierzystego, co jest niezbędne do działania pojemności.
Funkcje regionu macierzystego i pojemności
Efektywne planowanie odzyskiwania po awarii ma kluczowe znaczenie dla zrozumienia relacji między regionem macierzyscznym a lokalizacjami pojemności. Zrozumienie lokalizacji regionów domowych i pojemności ułatwia dokonanie strategicznych wyborów regionów pojemności, a także odpowiednich procesów replikacji i odzyskiwania.
Region domowy dzierżawy i magazynu danych organizacji jest ustawiony na lokalizację adresu rozliczeniowego pierwszego użytkownika, który się zarejestruje. Aby uzyskać więcej informacji na temat konfigurowania dzierżawy, zobacz Planowanie implementacji usługi Power BI: Konfiguracja dzierżawy. Podczas tworzenia nowych pojemności magazyn danych jest domyślnie ustawiony na region macierzysny. Jeśli chcesz zmienić region przechowywania danych na inny region, musisz włączyć funkcję Multi-Geo, czyli sieć szkieletową Premium.
Ważne
Wybranie innego regionu dla pojemności nie powoduje całkowitego przeniesienia wszystkich danych do tego regionu. Niektóre elementy danych nadal pozostają przechowywane w regionie macierzystym. Aby sprawdzić, które dane pozostają w regionie macierzysym i które dane są przechowywane w regionie z włączoną obsługą funkcji Multi-Geo, zobacz Konfigurowanie obsługi funkcji Multi-Geo dla sieci szkieletowej Premium.
W przypadku regionu macierzystego, który nie ma sparowanego regionu, pojemności w dowolnym regionie z włączoną obsługą wielu regionów geograficznych mogą napotkać problemy operacyjne, jeśli region macierzyscy napotka awarię, ponieważ podstawowa funkcjonalność usługi jest połączona z regionem macierzystym.
W przypadku wybrania regionu z obsługą wielu regionów geograficznych w UE gwarantuje się, że dane są przechowywane w granicach danych UE.
Aby dowiedzieć się, jak zidentyfikować region macierzysty, zobacz Znajdowanie regionu macierzystego usługi Fabric.
Ustawienie pojemności odzyskiwania po awarii
Sieć szkieletowa udostępnia przełącznik odzyskiwania po awarii na stronie ustawień pojemności. Jest ona dostępna, gdy pary regionalne platformy Azure są zgodne z obecnością usługi Fabric. Oto specyfika tego przełącznika:
Dostęp do roli: tylko użytkownicy z rolą administratora pojemności lub nowszą mogą używać tego przełącznika.
Stopień szczegółowości: Stopień szczegółowości przełącznika to poziom pojemności. Jest ona dostępna zarówno dla pojemności Premium, jak i Sieci szkieletowej.
Zakres danych: przełącznik odzyskiwania po awarii dotyczy konkretnie danych usługi OneLake, w tym danych usługi Lakehouse i Warehouse. Przełącznik nie ma wpływu na dane przechowywane poza usługą OneLake.
Ciągłość bcDR dla usługi Power BI: podczas gdy odzyskiwanie po awarii dla danych usługi OneLake może być włączone i wyłączone, funkcja BCDR dla usługi Power BI jest zawsze obsługiwana, niezależnie od tego, czy przełącznik jest włączony, czy wyłączony.
Częstotliwość: po zmianie ustawienia pojemności odzyskiwania po awarii należy poczekać 30 dni, zanim będzie można go zmienić ponownie. Okres oczekiwania jest ustawiony w celu utrzymania stabilności i zapobiegania ciągłemu przełączaniu,
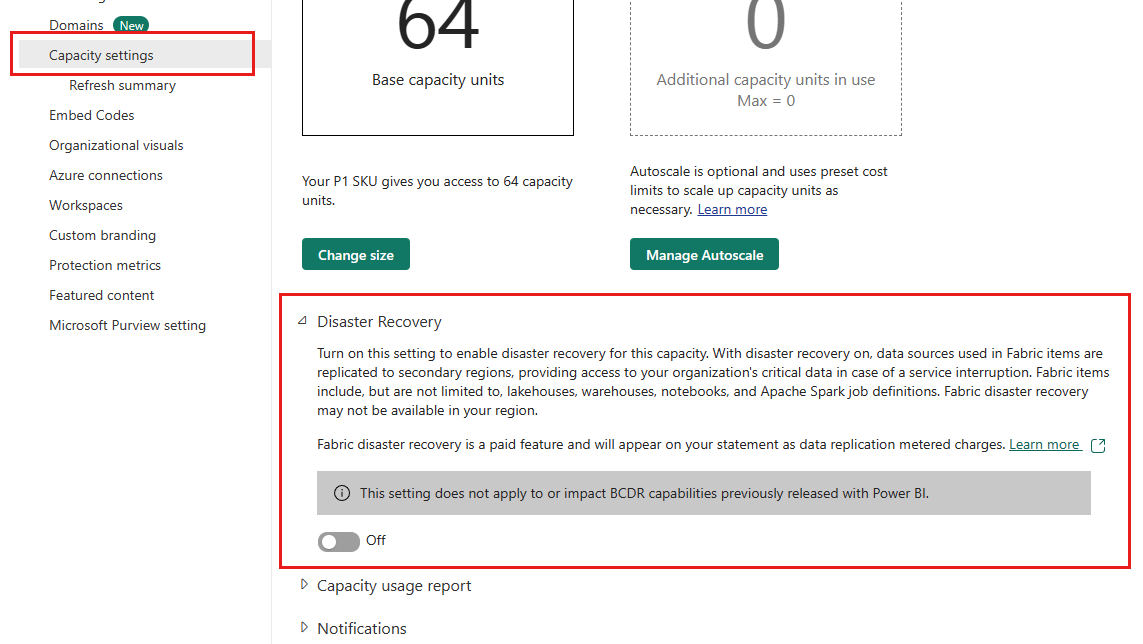
Uwaga
Po włączeniu ustawienia pojemności odzyskiwania po awarii może upłynąć do jednego tygodnia, aby dane zaczęły replikować.
Replikacja danych
Po włączeniu ustawienia pojemności odzyskiwania po awarii replikacja między regionami jest włączona jako funkcja odzyskiwania po awarii dla danych usługi OneLake. Platforma sieć szkieletowa jest zgodna z regionami platformy Azure, aby aprowizować pary nadmiarowości geograficznej. Jednak niektóre regiony nie mają regionu pary platformy Azure lub region pary nie obsługuje sieci szkieletowej. W przypadku tych regionów replikacja danych nie jest dostępna. Aby uzyskać więcej informacji, zobacz Regiony ze strefami dostępności i brak par regionów i dostępność regionu sieci szkieletowej.
Uwaga
Chociaż usługa Fabric oferuje rozwiązanie replikacji danych w usłudze OneLake do obsługi odzyskiwania po awarii, istnieją istotne ograniczenia. Na przykład dane baz danych KQL i zestawów zapytań są przechowywane zewnętrznie w usłudze OneLake, co oznacza, że potrzebne jest oddzielne podejście do odzyskiwania po awarii. Zapoznaj się z resztą tego dokumentu, aby uzyskać szczegółowe informacje na temat podejścia odzyskiwania po awarii dla każdego elementu sieci szkieletowej.
Rozliczenia
Funkcja odzyskiwania po awarii w sieci szkieletowej umożliwia replikację geograficzną danych w celu zwiększenia bezpieczeństwa i niezawodności. Ta funkcja zużywa więcej miejsca do magazynowania i transakcji, które są rozliczane odpowiednio jako operacje BCDR Storage i BCDR. Możesz monitorować te koszty i zarządzać nimi w aplikacji Metryki pojemności usługi Microsoft Fabric, gdzie są one wyświetlane jako oddzielne elementy wiersza.
Aby uzyskać wyczerpujący podział wszystkich powiązanych kosztów odzyskiwania po awarii, aby ułatwić odpowiednie planowanie i budżet, zobacz OneLake compute and storage consumption (Zużycie zasobów obliczeniowych i magazynu w usłudze OneLake).
Konfigurowanie odzyskiwania po awarii
Chociaż sieć szkieletowa udostępnia funkcje odzyskiwania po awarii w celu zapewnienia odporności danych, należy wykonać pewne czynności ręczne, aby przywrócić usługę podczas zakłóceń. Ta sekcja zawiera szczegółowe informacje o akcjach, które należy podjąć, aby przygotować się do potencjalnych zakłóceń.
Faza 1. Przygotowanie
Aktywuj ustawienia pojemności odzyskiwania po awarii: regularnie sprawdzaj i ustawiaj ustawienia pojemności odzyskiwania po awarii, aby upewnić się, że spełniają one wymagania dotyczące ochrony i wydajności.
Tworzenie kopii zapasowych danych: skopiuj dane krytyczne przechowywane poza usługą OneLake do innego regionu w sposób dostosowany do planu odzyskiwania po awarii.
Faza 2. Tryb failover po awarii
Gdy poważna awaria spowoduje, że region podstawowy będzie nieodwracalny, usługa Microsoft Fabric inicjuje regionalną pracę w trybie failover. Dostęp do portalu sieci szkieletowej jest niedostępny do momentu ukończenia trybu failover i opublikowania powiadomienia na stronie pomocy technicznej usługi Microsoft Fabric.
Czas potrzebny na ukończenie pracy w trybie failover może się różnić, chociaż zazwyczaj trwa to mniej niż jedną godzinę. Po zakończeniu pracy w trybie failover możesz się spodziewać:
Portal sieci szkieletowej: możesz uzyskać dostęp do portalu i operacje odczytu, takie jak przeglądanie istniejących obszarów roboczych i elementów, nadal działają. Wszystkie operacje zapisu, takie jak tworzenie lub modyfikowanie obszaru roboczego, są wstrzymane.
Power BI: możesz wykonywać operacje odczytu, takie jak wyświetlanie pulpitów nawigacyjnych i raportów. Operacje odświeżania, operacje publikowania raportów, modyfikacje pulpitu nawigacyjnego i raportu oraz inne operacje, które wymagają zmian metadanych, nie są obsługiwane.
Lakehouse/Warehouse: nie można otworzyć tych elementów, ale dostęp do plików można uzyskać za pośrednictwem interfejsów API usługi OneLake lub narzędzi.
Definicja zadania platformy Spark: nie można otwierać definicji zadań platformy Spark, ale można uzyskać dostęp do plików kodu za pośrednictwem interfejsów API lub narzędzi usługi OneLake. Wszystkie metadane lub konfiguracja zostaną zapisane po przejściu w tryb failover.
Notes: nie można otworzyć notesów, a zawartość kodu nie zostanie zapisana po awarii.
Model uczenia maszynowego/eksperyment: nie można otwierać modeli uczenia maszynowego ani eksperymentów. Zawartość kodu i metadane, takie jak metryki uruchamiania i konfiguracje, nie zostaną zapisane po awarii.
Dataflow Gen2/Pipeline/Eventstream: nie można otworzyć tych elementów, ale możesz użyć obsługiwanych miejsc docelowych odzyskiwania po awarii (lakehouses lub warehouses), aby chronić dane.
KQL Database/Queryset: nie będzie można uzyskać dostępu do baz danych KQL i zestawów zapytań po przejściu w tryb failover. Aby chronić dane w bazach danych KQL i zestawach zapytań, wymagane są dalsze kroki wymagań wstępnych.
W scenariuszu awarii portal sieci szkieletowej i usługa Power BI są w trybie tylko do odczytu, a inne elementy sieci szkieletowej są niedostępne, można uzyskać dostęp do ich danych przechowywanych w usłudze OneLake przy użyciu interfejsów API lub narzędzi innych firm. Zarówno portal, jak i usługa Power BI zachowują możliwość wykonywania operacji odczytu i zapisu na tych danych. Ta możliwość zapewnia dostępność i modyfikowanie krytycznych danych oraz zmniejsza potencjalne zakłócenia operacji biznesowych.
Dane usługi OneLake pozostają dostępne za pośrednictwem wielu kanałów:
Interfejs API usługi OneLake ADLS Gen2: zobacz Nawiązywanie połączenia z usługą Microsoft OneLake
Przykłady narzędzi, które mogą łączyć się z danymi usługi OneLake:
Eksplorator usługi Azure Storage: Zobacz Integrowanie usługi OneLake z usługą Eksplorator usługi Azure Storage
OneLake Eksplorator plików: zobacz Uzyskiwanie dostępu do danych sieci szkieletowej przy użyciu Eksploratora plików OneLake
Faza 3. Plan odzyskiwania
Sieć szkieletowa zapewnia, że dane pozostają dostępne po awarii, ale można również wykonać działania w celu pełnego przywrócenia ich usług do stanu przed zdarzeniem. Ta sekcja zawiera szczegółowy przewodnik, który ułatwia proces odzyskiwania.
Kroki odzyskiwania
Utwórz nową pojemność sieci szkieletowej w dowolnym regionie po awarii. Biorąc pod uwagę wysokie zapotrzebowanie podczas takich zdarzeń, zalecamy wybranie regionu spoza podstawowego obszaru geograficznego w celu zwiększenia prawdopodobieństwa dostępności usługi obliczeniowej. Aby uzyskać informacje na temat tworzenia pojemności, zobacz Kupowanie subskrypcji usługi Microsoft Fabric.
Utwórz obszary robocze w nowo utworzonej pojemności. W razie potrzeby użyj tych samych nazw co stare obszary robocze.
Utwórz elementy o takich samych nazwach jak te, które chcesz odzyskać. Ten krok jest ważny, jeśli używasz skryptu niestandardowego do odzyskiwania magazynów i magazynów.
Przywróć elementy. Dla każdego elementu postępuj zgodnie z odpowiednią sekcją w wskazówki dotyczące odzyskiwania po awarii specyficzne dla środowiska, aby przywrócić element.