Rozwiązywanie problemów i identyfikowanie wolnych zapytań w usłudze Azure Database for PostgreSQL — serwer elastyczny
DOTYCZY:  Azure Database for PostgreSQL — serwer elastyczny
Azure Database for PostgreSQL — serwer elastyczny
W tym artykule opisano sposób identyfikowania i diagnozowania głównej przyczyny powolnych zapytań.
W tym artykule możesz dowiedzieć się:
- Jak identyfikować wolno działające zapytania.
- Jak zidentyfikować procedurę wolno działającą wraz z nią. Zidentyfikuj wolne zapytanie wśród listy zapytań, które należą do tej samej wolno działającej procedury składowanej.
Wymagania wstępne
Włącz przewodniki rozwiązywania problemów, wykonując kroki opisane w przewodnikach rozwiązywania problemów.
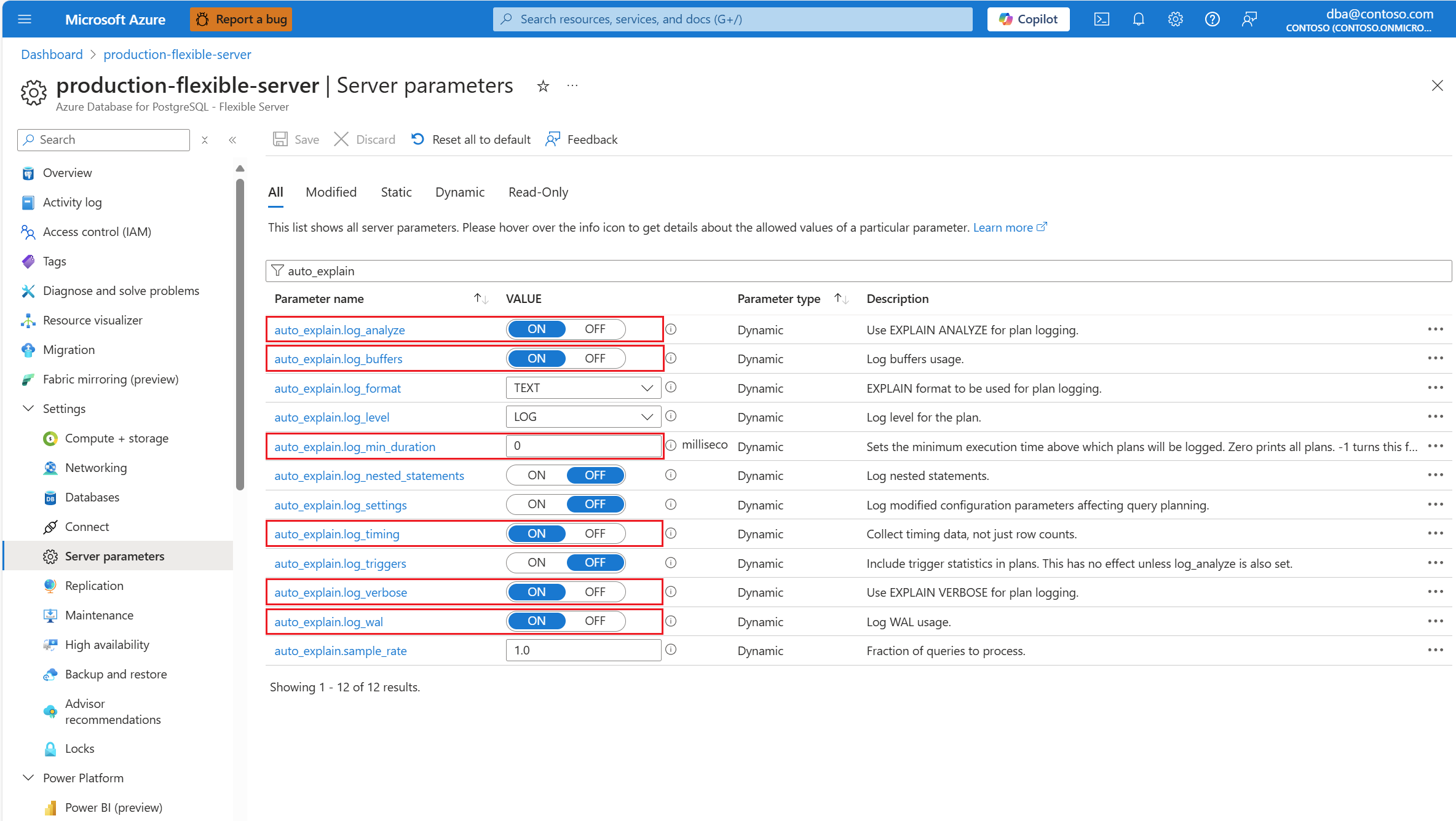
auto_explainSkonfiguruj rozszerzenie, podając listę dozwolonych i ładując rozszerzenie.Po skonfigurowaniu
auto_explainrozszerzenia zmień następujące parametry serwera, które kontrolują zachowanie rozszerzenia:auto_explain.log_analyzedoON.auto_explain.log_buffersdoON.auto_explain.log_min_durationzgodnie z tym, co jest uzasadnione w twoim scenariuszu.auto_explain.log_timingdoON.auto_explain.log_verbosedoON.

Uwaga
Jeśli ustawisz wartość auto_explain.log_min_duration 0, rozszerzenie rozpocznie rejestrowanie wszystkich zapytań wykonywanych na serwerze. Może to mieć wpływ na wydajność bazy danych. Należy zapewnić odpowiednią staranność, aby uzyskać wartość, która jest uznawana za powolną na serwerze. Jeśli na przykład wszystkie zapytania zostaną ukończone w mniej niż 30 sekund i jest to akceptowalne dla aplikacji, zaleca się zaktualizowanie parametru do 30000 milisekund. Spowoduje to zarejestrowanie dowolnego zapytania, które trwa dłużej niż 30 sekund.
Identyfikowanie wolnych zapytań
W przewodnikach rozwiązywania problemów i auto_explain rozszerzeniu opisano scenariusz z pomocą przykładu.
Mamy scenariusz, w którym wzrost wykorzystania procesora CPU do 90% i chcemy określić przyczynę skoku. Aby debugować scenariusz, wykonaj następujące kroki:
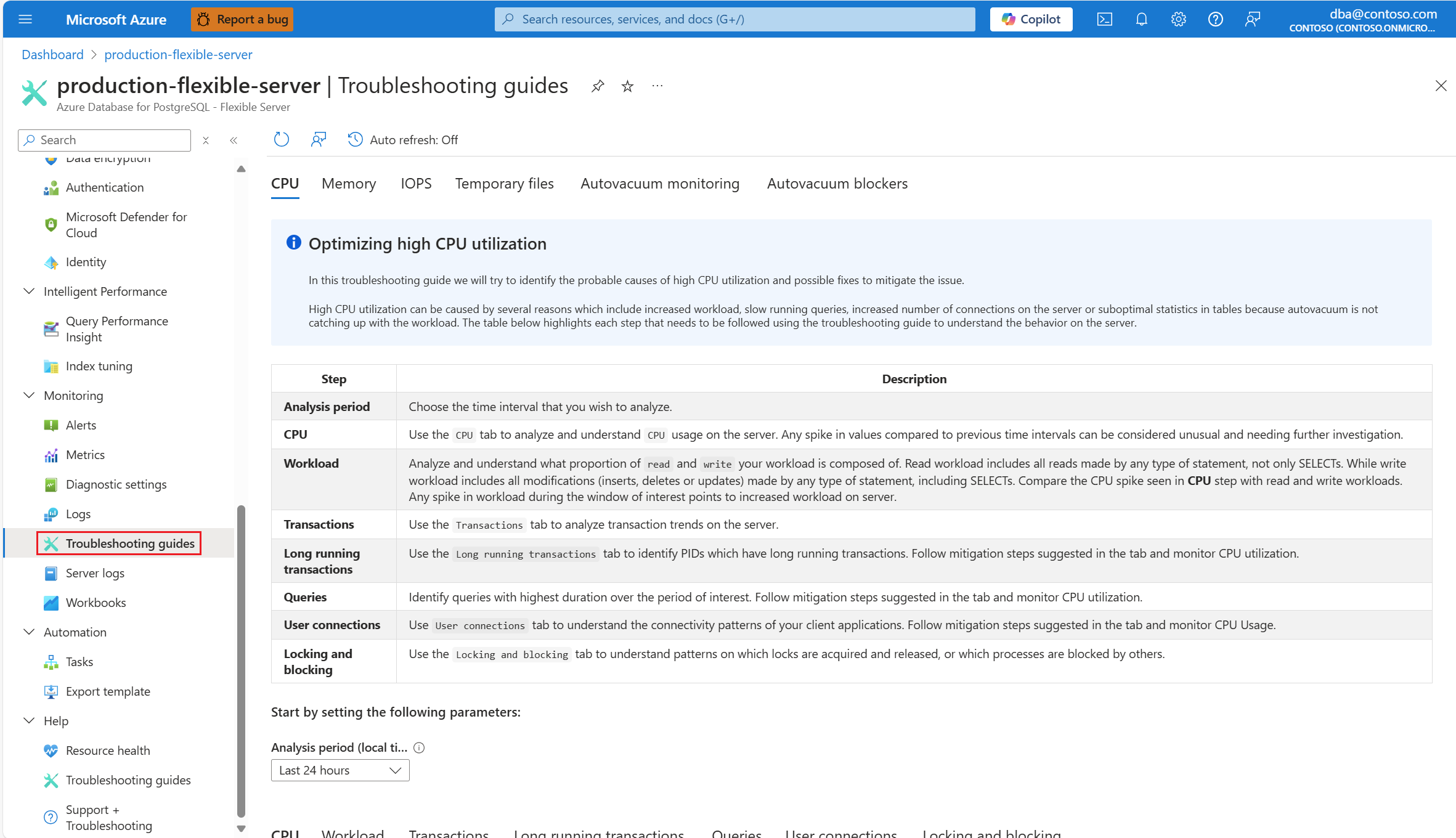
Gdy tylko otrzymasz alerty dotyczące scenariusza procesora CPU, w menu zasobów wystąpienia usługi Azure Database for PostgreSQL — serwer elastyczny, w sekcji Monitorowanie wybierz pozycję Przewodniki rozwiązywania problemów.
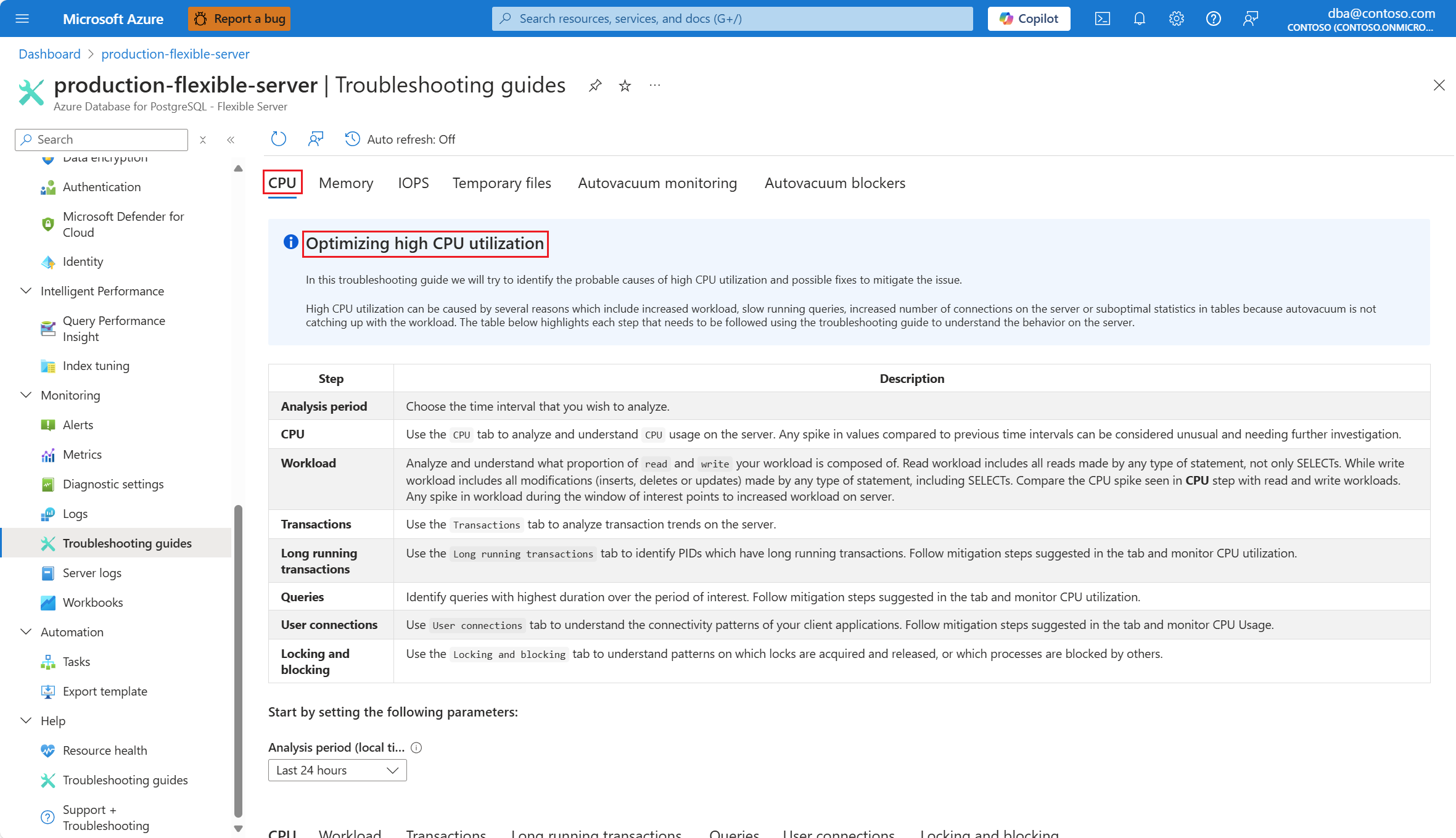
Wybierz kartę Procesor CPU . Zostanie otwarty przewodnik rozwiązywania problemów z optymalizowaniem wysokiego wykorzystania procesora CPU.
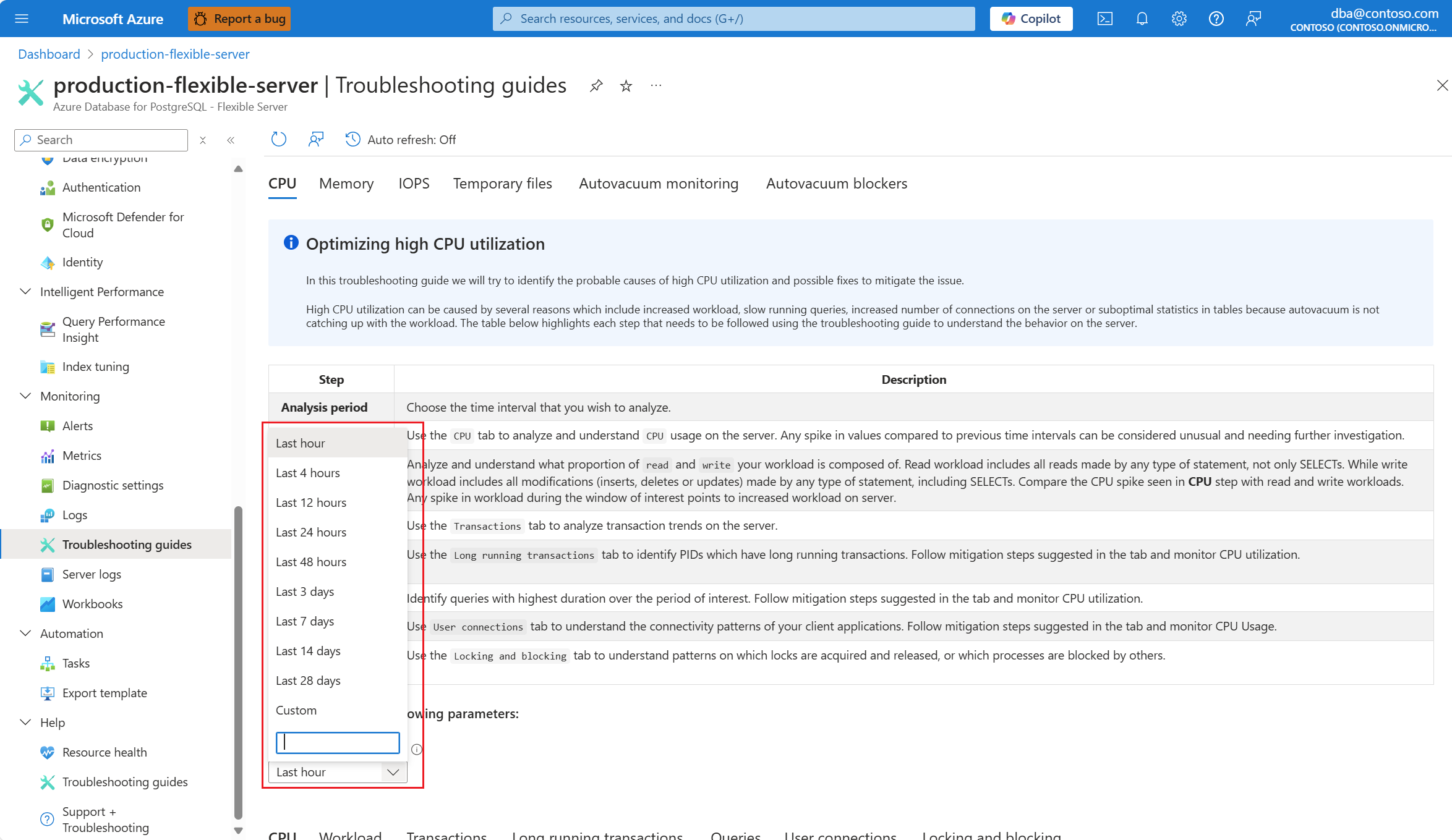
Z listy rozwijanej Okres analizy (czas lokalny) wybierz zakres czasu, dla którego chcesz skoncentrować analizę.
Wybierz kartę Zapytania . Zawiera on szczegółowe informacje o wszystkich zapytaniach uruchomionych w interwale, w którym zaobserwowano 90% użycia procesora CPU. Z migawki wygląda na to, że zapytanie o najwolniejszym średnim czasie wykonywania w interwale czasu wynosiło ok. 2,6 minut, a zapytanie zostało uruchomione 22 razy w interwale. To zapytanie jest najprawdopodobniej przyczyną skoków użycia procesora CPU.
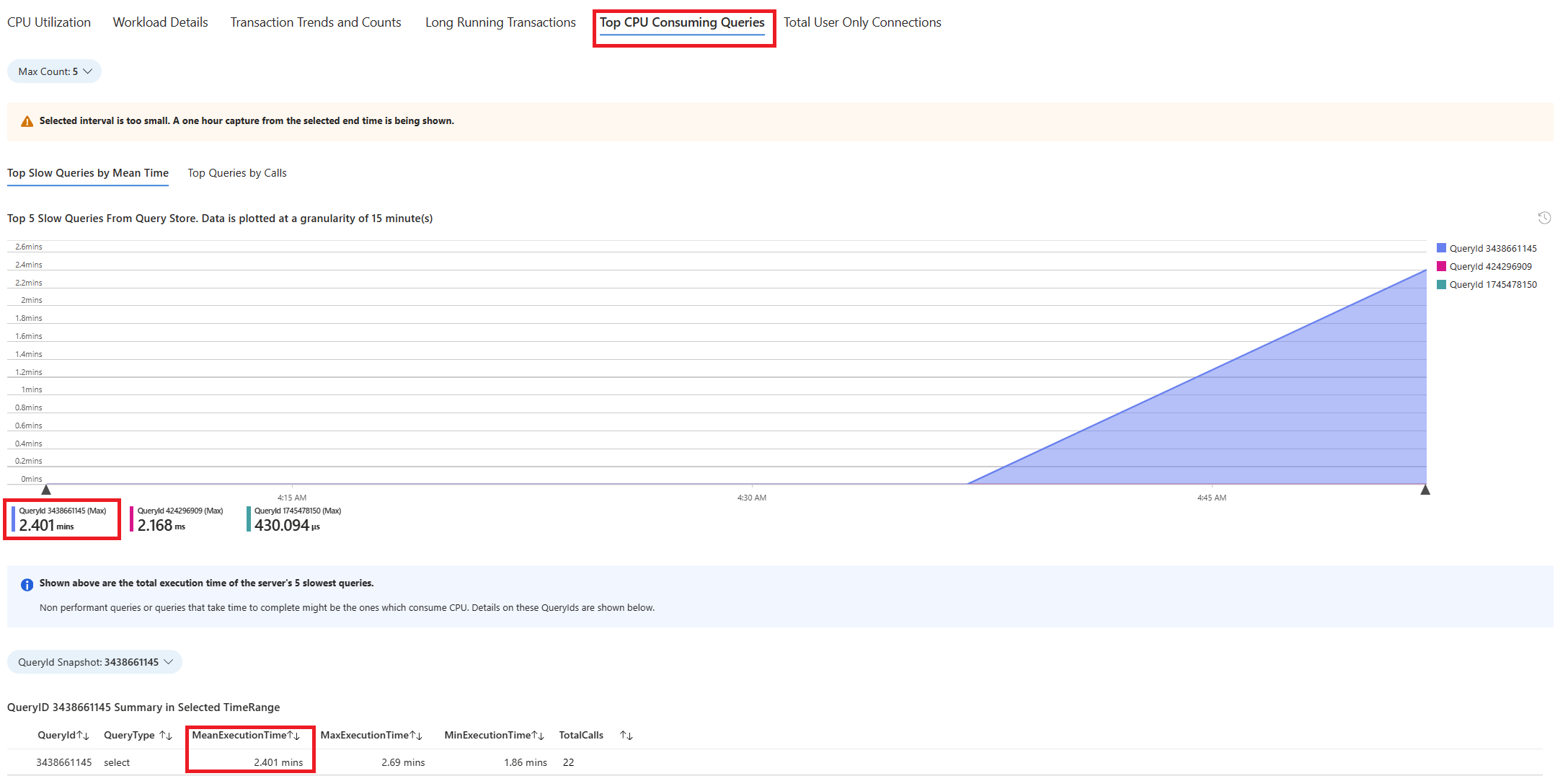
Aby pobrać rzeczywisty tekst zapytania, połącz się z bazą
azure_sysdanych i wykonaj następujące zapytanie.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- W przykładzie, które zostało uznane za powolne, zapytanie było następujące:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Aby zrozumieć, jaki dokładny plan objaśnienia został wygenerowany, użyj dzienników serwera elastycznego usługi Azure Database for PostgreSQL. Za każdym razem, gdy zapytanie zakończyło wykonywanie w tym przedziale czasu,
auto_explainrozszerzenie powinno zapisać wpis w dziennikach. W menu zasobów w sekcji Monitorowanie wybierz pozycję Dzienniki.
Wybierz zakres czasu, w którym znaleziono 90% wykorzystania procesora CPU.
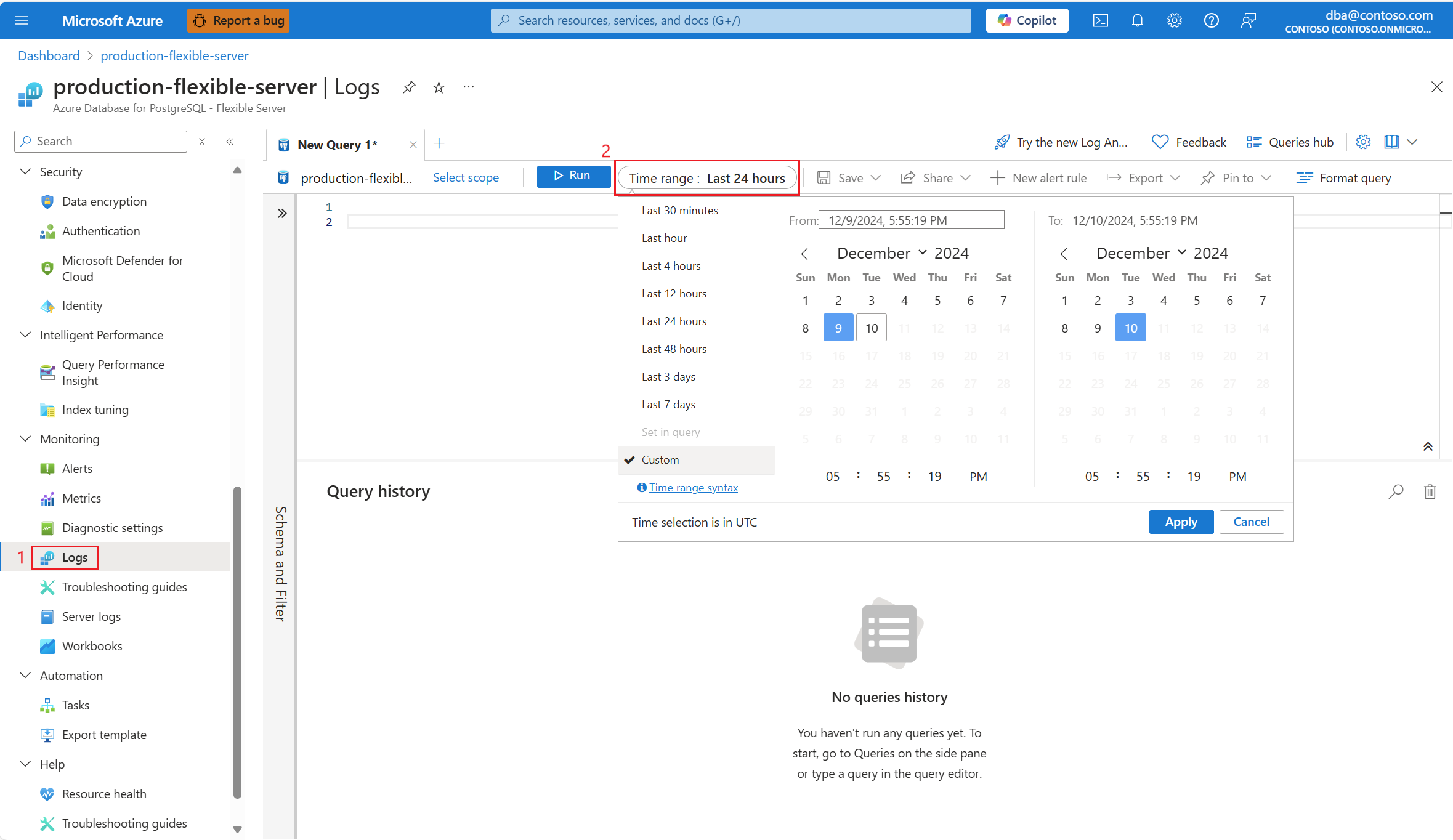
Wykonaj następujące zapytanie, aby pobrać dane wyjściowe funkcji EXPLAIN ANALYZE dla zidentyfikowanego zapytania.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Kolumna komunikatu przechowuje plan wykonania, jak pokazano w poniższych danych wyjściowych:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Zapytanie zostało uruchomione przez około 2,5 minuty, jak pokazano w przewodniku rozwiązywania problemów. Pobrana duration wartość 150692.864 ms z pobranych danych wyjściowych planu wykonania potwierdza. Użyj danych wyjściowych funkcji EXPLAIN ANALYZE, aby rozwiązać problemy i dostroić zapytanie.
Uwaga
Obserwator, że zapytanie zostało uruchomione 22 razy w interwale, a wyświetlane dzienniki zawierają jeden z takich wpisów przechwyconych w interwale.
Identyfikowanie wolno działającego zapytania w procedurze składowanej
W przewodnikach rozwiązywania problemów i rozszerzeniu auto_explain objaśniamy scenariusz za pomocą przykładu.
Mamy scenariusz, w którym wzrost wykorzystania procesora CPU do 90% i chcemy określić przyczynę skoku. Aby debugować scenariusz, wykonaj następujące kroki:
Gdy tylko otrzymasz alerty dotyczące scenariusza procesora CPU, w menu zasobów wystąpienia usługi Azure Database for PostgreSQL — serwer elastyczny, w sekcji Monitorowanie wybierz pozycję Przewodniki rozwiązywania problemów.
Wybierz kartę Procesor CPU . Zostanie otwarty przewodnik rozwiązywania problemów z optymalizowaniem wysokiego wykorzystania procesora CPU.
Z listy rozwijanej Okres analizy (czas lokalny) wybierz zakres czasu, dla którego chcesz skoncentrować analizę.
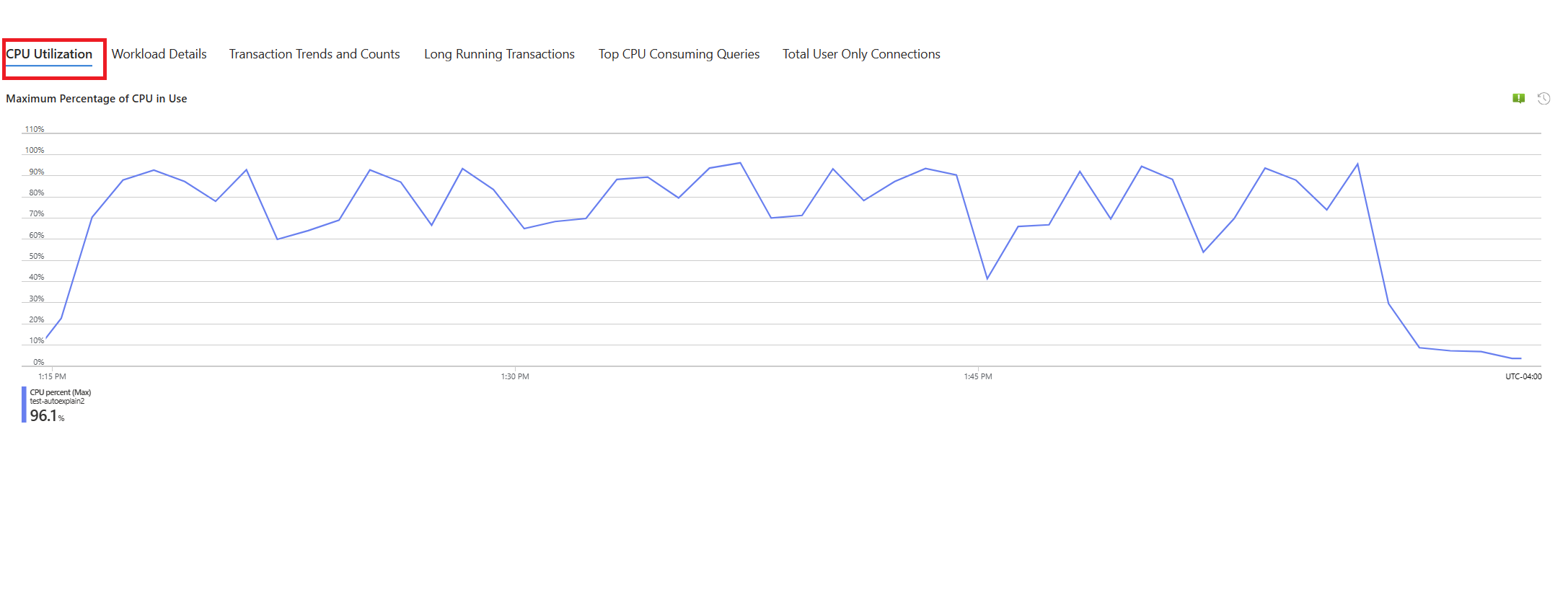
Wybierz kartę Zapytania . Zawiera on szczegółowe informacje o wszystkich zapytaniach uruchomionych w interwale, w którym zaobserwowano 90% użycia procesora CPU. Z migawki wygląda na to, że zapytanie o najwolniejszym średnim czasie wykonywania w interwale czasu wynosiło ok. 2,6 minut, a zapytanie zostało uruchomione 22 razy w interwale. To zapytanie jest najprawdopodobniej przyczyną skoków użycia procesora CPU.
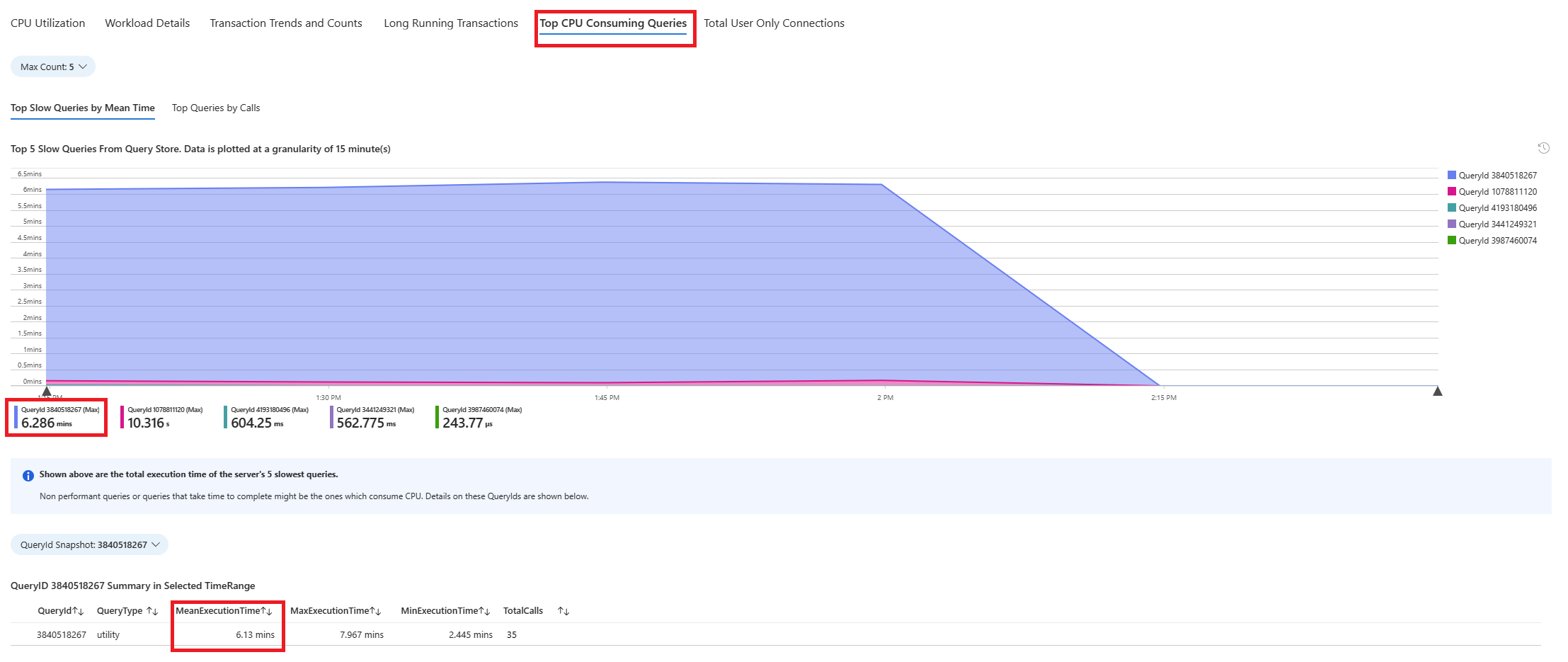
Połącz się z bazą danych azure_sys i wykonaj zapytanie, aby pobrać rzeczywisty tekst zapytania przy użyciu poniższego skryptu.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- W przykładzie, które zostało uznane za powolne, zapytanie było procedurą składowaną:
call autoexplain_test ();
- Aby zrozumieć, jaki dokładny plan objaśnienia został wygenerowany, użyj dzienników serwera elastycznego usługi Azure Database for PostgreSQL. Za każdym razem, gdy zapytanie zakończyło wykonywanie w tym przedziale czasu,
auto_explainrozszerzenie powinno zapisać wpis w dziennikach. W menu zasobów w sekcji Monitorowanie wybierz pozycję Dzienniki. Następnie w obszarze Zakres czasu wybierz przedział czasu, w którym chcesz skoncentrować analizę.

- Wykonaj następujące zapytanie, aby pobrać wyjaśnij dane wyjściowe analizy zidentyfikowanego zapytania.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Procedura zawiera wiele zapytań, które zostały wyróżnione poniżej. Dane wyjściowe analizy wyjaśnień dla każdego zapytania używanego w procedurze składowanej są rejestrowane w celu dalszej analizy i rozwiązywania problemów. Czas wykonywania zarejestrowanych zapytań może służyć do identyfikowania najwolniejszych zapytań, które są częścią procedury składowanej.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Uwaga
W celach demonstracyjnych są wyświetlane dane wyjściowe EXPLAIN ANALYZE tylko kilku zapytań używanych w procedurze. Chodzi o to, że można zebrać dane wyjściowe EXPLAIN ANALYZE wszystkich zapytań z dzienników i zidentyfikować najwolniejsze z nich i spróbować je dostroić.
Powiązana zawartość
- Rozwiązywanie problemów z wysokim użyciem procesora w usłudze Azure Database for PostgreSQL — serwer elastyczny.
- Rozwiązywanie problemów z wysokim użyciem operacji we/wy na sekundę w usłudze Azure Database for PostgreSQL — serwer elastyczny.
- Rozwiązywanie problemów z wysokim wykorzystaniem pamięci w usłudze Azure Database for PostgreSQL — serwer elastyczny.
- Parametry serwera w usłudze Azure Database for PostgreSQL — serwer elastyczny.
- Dostrajanie automatycznego czyszczenia w usłudze Azure Database for PostgreSQL — serwer elastyczny.