Dostrajanie wydajności i obsługi baz danych w usłudze Azure Database for MySQL — serwer elastyczny przy użyciu sys_schema
Performance_schema MySQL, pierwszy dostępny w programie MySQL 5.5, zapewnia instrumentację dla wielu ważnych zasobów serwera, takich jak alokacja pamięci, przechowywane programy, blokowanie metadanych itp. Jednak performance_schema zawiera więcej niż 80 tabel, a uzyskanie niezbędnych informacji często wymaga łączenia tabel w performance_schema i tabel z information_schema. Bazując zarówno na performance_schema, jak i information_schema, sys_schema udostępnia zaawansowaną kolekcję widoków przyjaznych dla użytkownika w bazie danych tylko do odczytu i jest w pełni włączona w usłudze Azure Database for MySQL — serwer elastyczny w wersji 5.7.
W sys_schema znajduje się 52 widoki, a każdy widok ma jeden z następujących prefiksów:
- Host_summary lub we/wy: opóźnienia związane z we/wy.
- InnoDB: stan i blokady buforu InnoDB.
- Pamięć: użycie pamięci przez hosta i użytkowników.
- Schemat: informacje dotyczące schematu, takie jak automatyczne zwiększanie, indeksy itp.
- Instrukcja: informacje na temat instrukcji SQL; Może to być instrukcja, która spowodowała pełne skanowanie tabeli lub długi czas zapytania.
- Użytkownik: zasoby używane i grupowane przez użytkowników. Przykłady to we/wy plików, połączenia i pamięć.
- Czekaj: Zdarzenia oczekiwania pogrupowane według hosta lub użytkownika.
Teraz przyjrzyjmy się niektórym typowym wzorom użycia sys_schema. Na początek pogrupujemy wzorce użycia w dwie kategorie: Dostrajanie wydajności i konserwacja bazy danych.
Dostrajanie wydajności
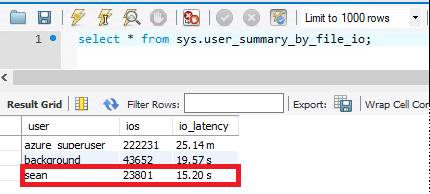
sys.user_summary_by_file_io
Operacje we/wy to najdroższa operacja w bazie danych. Średnie opóźnienie operacji we/wy można znaleźć, wykonując zapytanie dotyczące widoku sys.user_summary_by_file_io . W przypadku domyślnego 125 GB aprowizowanego magazynu opóźnienie operacji we/wy wynosi około 15 sekund.
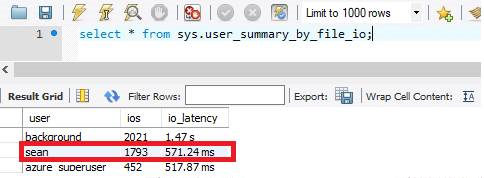
Ponieważ serwer elastyczny usługi Azure Database for MySQL skaluje we/wy w odniesieniu do magazynu, po zwiększeniu aprowizowanego magazynu do 1 TB opóźnienie operacji we/wy zmniejsza się do 571 ms.
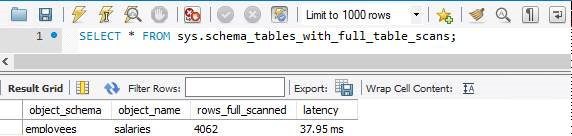
sys.schema_tables_with_full_table_scans
Pomimo starannego planowania wiele zapytań nadal może spowodować pełne skanowanie tabeli. Aby uzyskać więcej informacji o typach indeksów i sposobie ich optymalizacji, zapoznaj się z tym artykułem: Wydajność zapytań profilów w usłudze Azure Database for MySQL — serwer elastyczny przy użyciu funkcji WYJAŚNIJ. Pełne skanowania tabel są intensywnie obciążane zasobami i obniżają wydajność bazy danych. Najszybszym sposobem znajdowania tabel z pełnym skanowaniem tabel jest wykonywanie zapytań dotyczących widoku sys.schema_tables_with_full_table_scans .
sys.user_summary_by_statement_type
Aby rozwiązać problemy z wydajnością bazy danych, przydatne może być zidentyfikowanie zdarzeń występujących w bazie danych, a użycie widoku sys.user_summary_by_statement_type może po prostu wykonać ten problem.
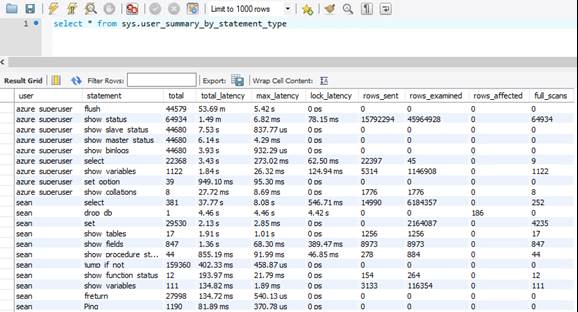
W tym przykładzie usługa Azure Database for MySQL — elastyczny serwer spędził 53 minuty opróżniając dziennik wolnych zapytań 44579 razy. To długi czas i wiele obiektów we/wy. Możesz zmniejszyć to działanie, wyłączając dziennik wolnych zapytań lub zmniejszając częstotliwość wolnych logowań zapytań w witrynie Azure Portal.
Konserwacja bazy danych
sys.innodb_buffer_stats_by_table
[! WAŻNE]
Wykonywanie zapytań dotyczących tego widoku może mieć wpływ na wydajność. Zaleca się wykonanie tego rozwiązywania problemów w godzinach pracy poza szczytem.
Pula InnoDB znajduje się w pamięci i jest głównym mechanizmem pamięci podręcznej między systemem DBMS i magazynem. Rozmiar puli InnoDB jest powiązany z warstwą wydajności i nie można go zmienić, chyba że zostanie wybrana inna jednostka SKU produktu. Podobnie jak w przypadku pamięci w systemie operacyjnym, stare strony są zamieniane, aby zapewnić miejsce na świeższe dane. Aby dowiedzieć się, które tabele zużywają większość pamięci puli InnoDB, możesz wykonać zapytanie dotyczące widoku sys.innodb_buffer_stats_by_table .
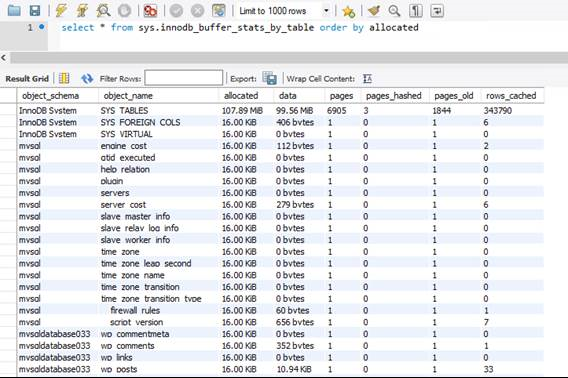
Na powyższej ilustracji widać, że inne niż tabele i widoki systemowe, każda tabela w bazie danych mysqldatabase033, która hostuje jedną z witryn WordPress, zajmuje 16 KB lub 1 stronę danych w pamięci.
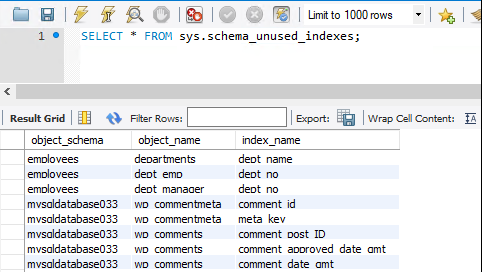
Sys.schema_unused_indexes i sys.schema_redundant_indexes
Indeksy są doskonałymi narzędziami zwiększającymi wydajność odczytu, ale generują dodatkowe koszty wstawiania i magazynu. Sys.schema_unused_indexes i sys.schema_redundant_indexes zapewniają wgląd w nieużywane lub zduplikowane indeksy.

Podsumowanie
Podsumowując, sys_schema to doskonałe narzędzie do dostrajania wydajności i konserwacji bazy danych. Pamiętaj, aby skorzystać z tej funkcji w wystąpieniu serwera elastycznego usługi Azure Database for MySQL.