Samouczek: tworzenie modeli na stacji roboczej w chmurze
Dowiedz się, jak opracować skrypt szkoleniowy przy użyciu notesu na stacji roboczej w chmurze usługi Azure Machine Learning. W tym samouczku omówiono podstawowe informacje potrzebne do rozpoczęcia pracy:
- Konfigurowanie i konfigurowanie stacji roboczej w chmurze. Twoja stacja robocza w chmurze jest obsługiwana przez wystąpienie obliczeniowe usługi Azure Machine Learning, które jest wstępnie skonfigurowane ze środowiskami do obsługi różnych potrzeb związanych z tworzeniem modeli.
- Używaj środowisk deweloperskich opartych na chmurze.
- Użyj biblioteki MLflow, aby śledzić metryki modelu — wszystko z poziomu notesu.
Wymagania wstępne
Aby korzystać z usługi Azure Machine Learning, potrzebny jest obszar roboczy. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
Ważne
Jeśli obszar roboczy usługi Azure Machine Learning jest skonfigurowany z zarządzaną siecią wirtualną, może być konieczne dodanie reguł ruchu wychodzącego w celu umożliwienia dostępu do publicznych repozytoriów pakietów języka Python. Aby uzyskać więcej informacji, zobacz Scenariusz: Uzyskiwanie dostępu do publicznych pakietów uczenia maszynowego.
Rozpoczynanie pracy z obliczeniami
Sekcja Obliczenia w obszarze roboczym umożliwia tworzenie zasobów obliczeniowych. Wystąpienie obliczeniowe to w pełni zarządzana przez usługę Azure Machine Learning stacja robocza oparta na chmurze. W tej serii samouczków jest używane wystąpienie obliczeniowe. Można go również użyć do uruchamiania własnego kodu oraz do tworzenia i testowania modeli.
- Zaloguj się do usługi Azure Machine Learning Studio.
- Wybierz obszar roboczy, jeśli nie został jeszcze otwarty.
- W obszarze nawigacji po lewej stronie wybierz pozycję Obliczenia.
- Jeśli nie masz wystąpienia obliczeniowego, zobaczysz pozycję Nowy w środku ekranu. Wybierz pozycję Nowy i wypełnij formularz. Możesz użyć wszystkich wartości domyślnych.
- Jeśli masz wystąpienie obliczeniowe, wybierz je z listy. Jeśli został zatrzymany, wybierz pozycję Uruchom.
Otwórz program Visual Studio Code (VS Code)
Po uruchomieniu wystąpienia obliczeniowego można uzyskać do niego dostęp na różne sposoby. W tym samouczku pokazano, jak używać wystąpienia obliczeniowego z programu VS Code. Program VS Code zapewnia pełne zintegrowane środowisko projektowe (IDE) z możliwościami zasobów usługi Azure Machine Learning.
Na liście wystąpień obliczeniowych wybierz link VS Code (Web) lub VS Code (Desktop) dla wystąpienia obliczeniowego, którego chcesz użyć. Jeśli wybierzesz program VS Code (desktop), może pojawić się wyskakujące okienko z pytaniem, czy chcesz otworzyć aplikację.

To wystąpienie programu VS Code jest dołączone do wystąpienia obliczeniowego i systemu plików obszaru roboczego. Nawet jeśli otworzysz go na pulpicie, widoczne pliki są plikami w obszarze roboczym.
Konfigurowanie nowego środowiska do tworzenia prototypów (opcjonalnie)
Aby skrypt został uruchomiony, należy pracować w środowisku skonfigurowanym z zależnościami i bibliotekami oczekiwanymi przez kod. Ta sekcja ułatwia tworzenie środowiska dostosowanego do kodu. Aby utworzyć nowe jądro Jupyter, z którym nawiązuje połączenie notes, użyjesz pliku YAML definiującego zależności.
Przekaż plik.
Przekazane pliki są przechowywane w udziale plików platformy Azure, a te pliki są instalowane w każdym wystąpieniu obliczeniowym i udostępniane w obszarze roboczym.
Pobierz ten plik środowiska conda, workstation_env.yml na komputer przy użyciu przycisku Pobierz nieprzetworzonego pliku w prawym górnym rogu.
Przeciągnij plik z komputera do okna programu VS Code. Plik jest przekazywany do obszaru roboczego.
Przenieś plik w folderze nazwy użytkownika.
Wybierz ten plik, aby wyświetlić podgląd i zobaczyć, jakie zależności określa. Zobaczysz zawartość podobną do następującej:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibUtwórz jądro.
Teraz użyj terminalu, aby utworzyć nowe jądro Jupyter na podstawie pliku workstation_env.yml .
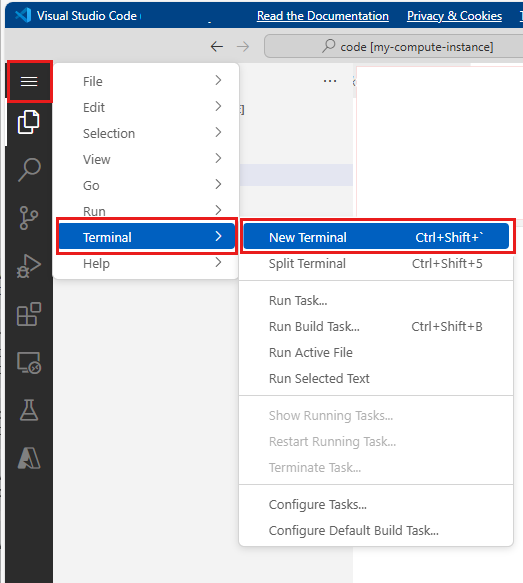
Na górnym pasku menu wybierz pozycję Terminal > Nowy terminal.
Wyświetl bieżące środowiska conda. Aktywne środowisko jest oznaczone znakiem *.
conda env listcddo folderu, w którym przekazano plik workstation_env.yml . Jeśli na przykład przekazano go do folderu użytkownika:cd Users/myusernameUpewnij się, że workstation_env.yml znajduje się w tym folderze.
lsUtwórz środowisko na podstawie dostarczonego pliku conda. Skompilowanie tego środowiska zajmuje kilka minut.
conda env create -f workstation_env.ymlAktywuj nowe środowisko.
conda activate workstation_envUwaga
Jeśli widzisz błąd CommandNotFoundError, postępuj zgodnie z instrukcjami, aby uruchomić
conda init bashpolecenie , zamknąć terminal i otworzyć nowy. Następnie spróbuj ponownie wykonaćconda activate workstation_envpolecenie.Sprawdź, czy prawidłowe środowisko jest aktywne, ponownie wyszukując środowisko oznaczone znakiem *.
conda env listUtwórz nowe jądro Jupyter na podstawie aktywnego środowiska.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Zamknij okno terminalu.
Masz teraz nowe jądro. Następnie otworzysz notes i użyjesz tego jądra.
Tworzenie notesu
- Na górnym pasku menu wybierz pozycję Plik > nowy plik.
- Nadaj nowemu plikowi nazwę develop-tutorial.ipynb (lub wprowadź preferowaną nazwę). Upewnij się, że używasz rozszerzenia .ipynb .
Ustawianie jądra
- W prawym górnym rogu wybierz pozycję Wybierz jądro.
- Wybierz pozycję Wystąpienie obliczeniowe usługi Azure ML (computeinstance-name).
- Wybierz utworzone jądro Tutorial Workstation Env. Jeśli go nie widzisz, wybierz narzędzie Odśwież w prawym górnym rogu.
Opracowywanie skryptu szkoleniowego
W tej sekcji utworzysz skrypt szkoleniowy języka Python, który przewiduje domyślne płatności kart kredytowych przy użyciu przygotowanych zestawów danych testowych i szkoleniowych z zestawu danych UCI.
Ten kod służy sklearn do trenowania i biblioteki MLflow do rejestrowania metryk.
Zacznij od kodu, który importuje pakiety i biblioteki, których będziesz używać w skry skrycie szkoleniowym.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitNastępnie załaduj i przetwórz dane dla tego eksperymentu. W tym samouczku odczytujesz dane z pliku w Internecie.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Przygotuj dane do szkolenia:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesDodaj kod, aby rozpocząć automatyczne rejestrowanie za pomocą
MLflowpolecenia , aby można było śledzić metryki i wyniki. Dzięki iteracyjnej charakterowi opracowywaniaMLflowmodelu pomaga rejestrować parametry i wyniki modelu. Wróć do tych przebiegów, aby porównać i zrozumieć, jak działa model. Dzienniki zapewniają również kontekst, gdy wszystko będzie gotowe do przejścia z fazy programowania do fazy trenowania przepływów pracy w usłudze Azure Machine Learning.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Trenowanie modelu.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Uwaga
Możesz zignorować ostrzeżenia mlflow. Nadal będziesz otrzymywać wszystkie wyniki, które są śledzone.
Powtarzanie
Teraz, gdy masz wyniki modelu, możesz zmienić coś i spróbować ponownie. Na przykład wypróbuj inną technikę klasyfikatora:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Uwaga
Możesz zignorować ostrzeżenia mlflow. Nadal będziesz otrzymywać wszystkie wyniki, które są śledzone.
Sprawdzanie wyników
Po wypróbowaniu dwóch różnych modeli użyj wyników śledzonych przez MLFfow usługę , aby zdecydować, który model jest lepszy. Możesz odwoływać się do metryk, takich jak dokładność lub inne wskaźniki, które mają największe znaczenie dla Twoich scenariuszy. Więcej szczegółowych informacji na temat tych wyników można uzyskać, przeglądając zadania utworzone przez MLflowprogram .
Wróć do obszaru roboczego w usłudze Azure Machine Learning Studio.
W obszarze nawigacji po lewej stronie wybierz pozycję Zadania.
Wybierz link do samouczka Dotyczącego tworzenia aplikacji w chmurze.
Istnieją dwa różne zadania, po jednym dla każdego z modeli, które próbowano wykonać. Te nazwy są generowane automatycznie. Po umieszczeniu wskaźnika myszy na nazwie użyj narzędzia ołówka obok nazwy, jeśli chcesz zmienić jego nazwę.
Wybierz link dla pierwszego zadania. Nazwa jest wyświetlana u góry. Możesz również zmienić jego nazwę w tym miejscu za pomocą narzędzia ołówka.
Na stronie przedstawiono szczegóły zadania, takie jak właściwości, dane wyjściowe, tagi i parametry. W obszarze Tagi zobaczysz estimator_name, która opisuje typ modelu.
Wybierz kartę Metryki , aby wyświetlić metryki zarejestrowane przez
MLflowusługę . (Oczekujesz, że wyniki będą się różnić, ponieważ masz inny zestaw treningowy).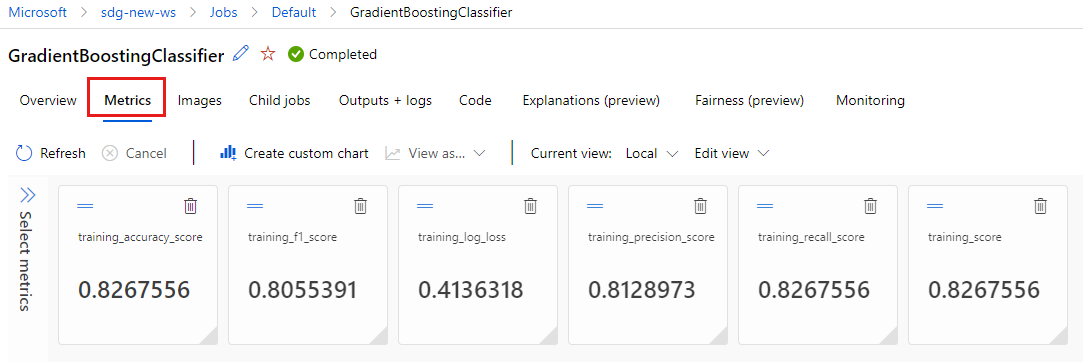
Wybierz kartę Obrazy, aby wyświetlić obrazy wygenerowane przez
MLflowprogram .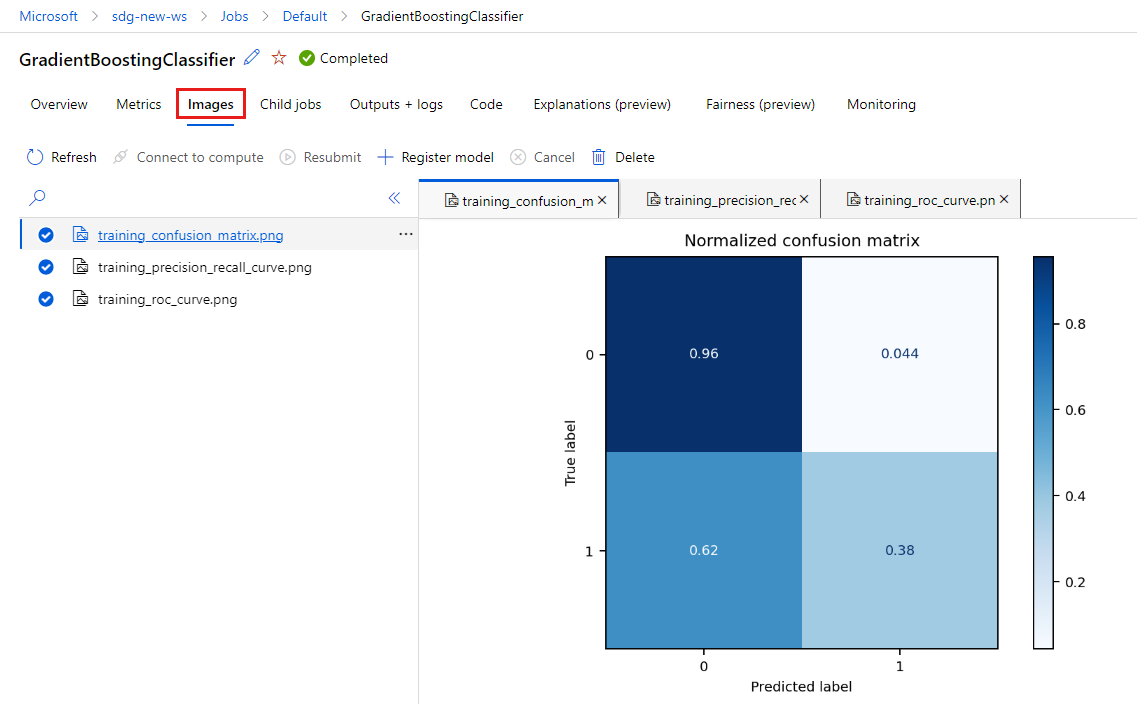
Wróć i przejrzyj metryki i obrazy dla innego modelu.
Tworzenie skryptu w języku Python
Teraz utwórz skrypt języka Python na podstawie notesu na potrzeby trenowania modelu.
W oknie programu VS Code kliknij prawym przyciskiem myszy nazwę pliku notesu i wybierz polecenie Importuj notes do skryptu.
Użyj menu Plik > Zapisz , aby zapisać ten nowy plik skryptu. Nazwij go train.py.
Przejrzyj ten plik i usuń kod, którego nie chcesz użyć w skryfcie szkoleniowym. Na przykład zachowaj kod dla modelu, którego chcesz użyć, i usuń kod dla modelu, którego nie chcesz.
- Upewnij się, że zachowasz kod, który uruchamia automatyczne rejestrowanie (
mlflow.sklearn.autolog()). - Po interaktywnym uruchomieniu skryptu języka Python (tak jak w tym miejscu), możesz zachować wiersz definiujący nazwę eksperymentu (
mlflow.set_experiment("Develop on cloud tutorial")). Możesz nawet podać inną nazwę, aby zobaczyć ją jako inny wpis w sekcji Zadania . Jednak gdy przygotowujesz skrypt do zadania szkoleniowego, ten wiersz nie ma zastosowania i powinien zostać pominięty — definicja zadania zawiera nazwę eksperymentu. - Podczas trenowania pojedynczego modelu wiersze do uruchamiania i kończenia przebiegu (
mlflow.start_run()imlflow.end_run()) również nie są konieczne (nie będą miały żadnego efektu), ale mogą pozostać w lewo, jeśli chcesz.
- Upewnij się, że zachowasz kod, który uruchamia automatyczne rejestrowanie (
Po zakończeniu edycji zapisz plik.
Masz teraz skrypt języka Python do użycia na potrzeby trenowania preferowanego modelu.
Uruchamianie skryptu języka Python
Na razie uruchamiasz ten kod w wystąpieniu obliczeniowym, czyli środowisku deweloperskim usługi Azure Machine Learning. Samouczek: trenowanie modelu pokazuje, jak uruchomić skrypt szkoleniowy w bardziej skalowalny sposób na bardziej zaawansowane zasoby obliczeniowe.
Wybierz środowisko utworzone wcześniej w tym samouczku jako wersję języka Python (workstations_env). W prawym dolnym rogu notesu zobaczysz nazwę środowiska. Wybierz je, a następnie wybierz środowisko na środku ekranu.
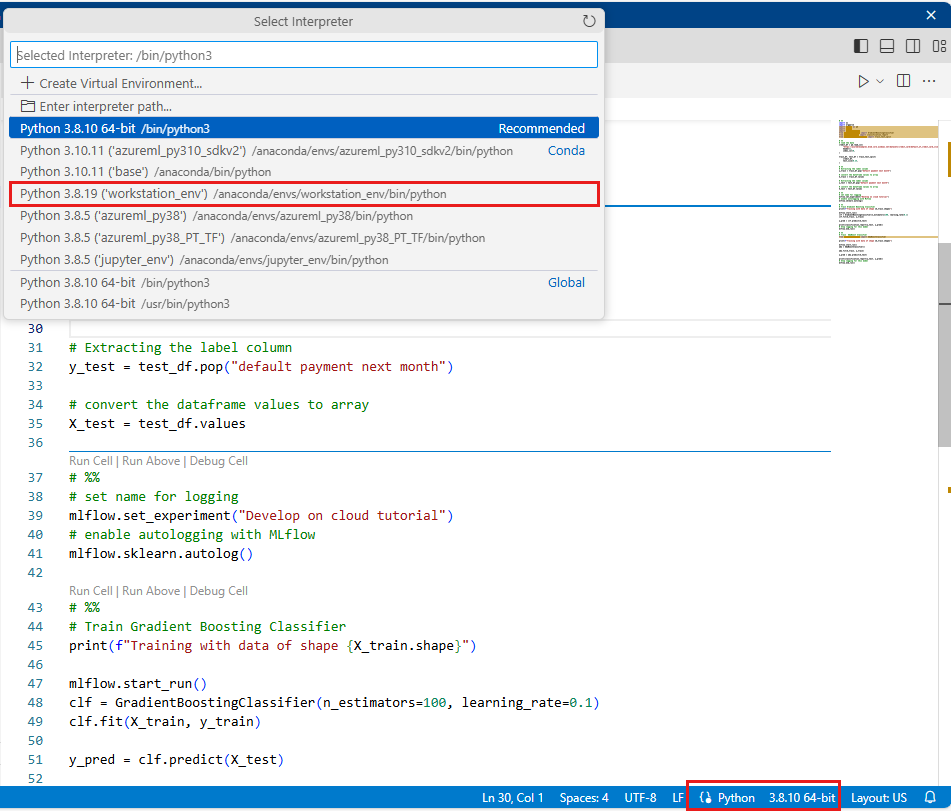
Teraz uruchom skrypt języka Python. Użyj narzędzia Uruchom plik języka Python w prawym górnym rogu.
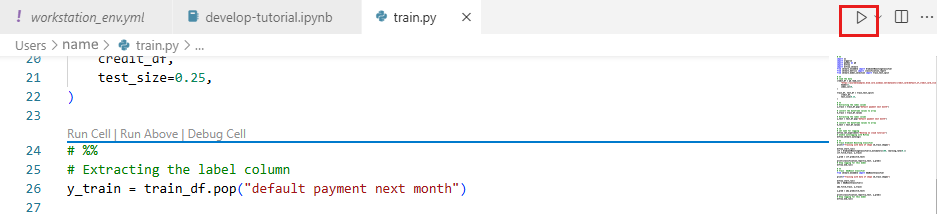
Uwaga
Możesz zignorować ostrzeżenia mlflow. Nadal będziesz pobierać wszystkie metryki i obrazy z automatycznego rejestrowania.
Sprawdzanie wyników skryptu
Wróć do obszaru roboczego w usłudze Azure Machine Learning Studio, aby wyświetlić wyniki skryptu szkoleniowego. Należy pamiętać, że dane treningowe zmieniają się wraz z każdym podziałem, więc wyniki różnią się również między przebiegami.
Czyszczenie zasobów
Jeśli planujesz kontynuować korzystanie z innych samouczków, przejdź do sekcji Następne kroki.
Zatrzymywanie wystąpienia obliczeniowego
Jeśli nie zamierzasz go teraz używać, zatrzymaj wystąpienie obliczeniowe:
- W programie Studio w obszarze nawigacji po lewej stronie wybierz pozycję Obliczenia.
- Na pierwszych kartach wybierz pozycję Wystąpienia obliczeniowe
- Wybierz wystąpienie obliczeniowe na liście.
- Na górnym pasku narzędzi wybierz pozycję Zatrzymaj.
Usuwanie wszystkich zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Learning i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal w polu wyszukiwania wprowadź ciąg Grupy zasobów i wybierz je z wyników.
Z listy wybierz utworzoną grupę zasobów.
Na stronie Przegląd wybierz pozycję Usuń grupę zasobów.
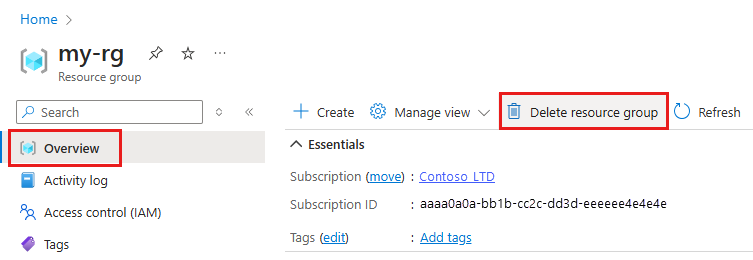
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
Dowiedz się więcej na następujące tematy:
- Z artefaktów do modeli w MLflow
- Using Git with Azure Machine Learning (Używanie usługi Git z usługą Azure Machine Learning)
- Uruchamianie notesów Jupyter w obszarze roboczym
- Praca z terminalem wystąpienia obliczeniowego w obszarze roboczym
- Zarządzanie sesjami notesu i terminalu
W tym samouczku przedstawiono wczesne kroki tworzenia modelu, tworzenia prototypów na tej samej maszynie, na której znajduje się kod. Na potrzeby szkolenia produkcyjnego dowiedz się, jak używać tego skryptu szkoleniowego na bardziej zaawansowanych zasobach obliczeniowych zdalnych: