Zwiększanie szybkości punktu kontrolnego i obniżanie kosztów dzięki mgławicy
Dowiedz się, jak zwiększyć szybkość punktu kontrolnego i zmniejszyć koszt punktu kontrolnego dla dużych modeli trenowania usługi Azure Machine Learning przy użyciu mgławicy.
Omówienie
Mgławica to szybkie, proste, bez dysku narzędzie punktu kontrolnego obsługującego model w usłudze Azure Container for PyTorch (ACPT). Mgławica oferuje proste, szybkie rozwiązanie do tworzenia punktów kontrolnych dla rozproszonych zadań trenowania modelu na dużą skalę przy użyciu rozwiązania PyTorch. Korzystając z najnowszych technologii przetwarzania rozproszonego, mgławica może skrócić czasy punktu kontrolnego od godzin do sekund — potencjalnie oszczędzając 95% do 99,9% czasu. Zadania szkoleniowe na dużą skalę mogą znacznie korzystać z wydajności mgławicy.
Aby udostępnić mgławicę dla zadań szkoleniowych, zaimportuj pakiet języka Python do skryptu nebulaml . Mgławica ma pełną zgodność z różnymi rozproszonymi strategiami trenowania PyTorch, w tym PyTorch Lightning, DeepSpeed i nie tylko. Interfejs API mgławicy oferuje prosty sposób monitorowania i wyświetlania cykli życia punktów kontrolnych. Interfejsy API obsługują różne typy modeli i zapewniają spójność i niezawodność punktów kontrolnych.
Ważne
Pakiet nebulaml nie jest dostępny w publicznym indeksie pakietów PyPI języka Python. Jest ona dostępna tylko w środowisku nadzorowanych usługi Azure Container for PyTorch (ACPT) w usłudze Azure Machine Learning. Aby uniknąć problemów, nie próbuj instalować nebulaml z interfejsu pip PyPI ani za pomocą polecenia .
W tym dokumencie dowiesz się, jak używać mgławicy z funkcją ACPT w usłudze Azure Machine Learning, aby szybko wskazać punkty kontrolne zadań trenowania modelu. Ponadto dowiesz się, jak wyświetlać dane punktu kontrolnego mgławic i zarządzać nimi. Dowiesz się również, jak wznowić zadania trenowania modelu z ostatniego dostępnego punktu kontrolnego, jeśli występują przerwy, awarie lub zakończenie usługi Azure Machine Learning.
Dlaczego optymalizacja punktu kontrolnego w przypadku trenowania dużych modeli ma znaczenie
W miarę zwiększania się ilości danych, a formaty danych stają się bardziej złożone, modele uczenia maszynowego również stają się bardziej zaawansowane. Trenowanie tych złożonych modeli może być trudne ze względu na limity pojemności pamięci procesora GPU i długie czasy trenowania. W związku z tym trenowanie rozproszone jest często używane podczas pracy z dużymi zestawami danych i złożonymi modelami. Jednak architektury rozproszone mogą wystąpić nieoczekiwane błędy i awarie węzłów, co może stać się coraz bardziej problematyczne w miarę wzrostu liczby węzłów w modelu uczenia maszynowego.
Punkty kontrolne mogą pomóc w rozwiązaniu tych problemów, okresowo zapisując migawkę kompletnego stanu modelu w danym momencie. W przypadku awarii tej migawki można użyć do ponownego skompilowania modelu do jego stanu w momencie migawki, aby trenowanie można było wznowić od tego momentu.
Gdy duże operacje trenowania modelu występują błędy lub zakończenia, analitycy danych i naukowcy mogą przywrócić proces trenowania z wcześniej zapisanego punktu kontrolnego. Jednak wszelkie postępy między punktem kontrolnym a zakończeniem zostaną utracone, ponieważ obliczenia muszą zostać ponownie wykonane w celu odzyskania niezapisanych wyników pośrednich. Krótsze interwały punktów kontrolnych mogą pomóc zmniejszyć tę utratę. Diagram ilustruje czas zmarnowany między procesem trenowania z punktów kontrolnych a zakończeniem:

Jednak proces zapisywania samych punktów kontrolnych może generować znaczne obciążenie. Zapisywanie punktu kontrolnego o rozmiarze TB często może stać się wąskim gardłem w procesie trenowania, a zsynchronizowany proces punktu kontrolnego blokuje trenowanie przez wiele godzin. Średnio koszty związane z punktami kontrolnymi mogą odpowiadać za 12% całkowitego czasu trenowania i mogą wzrosnąć do aż 43% (Maeng i in., 2021).
Podsumowując, duże zarządzanie punktami kontrolnymi modelu obejmuje duże obciążenie magazynu i czas odzyskiwania zadania. Częste zapisywanie punktów kontrolnych w połączeniu z wznowieniami zadań szkoleniowych z najnowszych dostępnych punktów kontrolnych staje się wielkim wyzwaniem.
Mgławica na ratunek
Aby efektywnie trenować duże modele rozproszone, ważne jest, aby mieć niezawodny i wydajny sposób zapisywania i wznawiania postępu trenowania, które minimalizuje utratę danych i marnotrawstwo zasobów. Mgławica pomaga skrócić czas zapisywania punktów kontrolnych i wymagania dotyczące godzin procesora GPU w przypadku zadań trenowania usługi Azure Machine Learning w dużym modelu, zapewniając szybsze i łatwiejsze zarządzanie punktami kontrolnymi.
Mgławica umożliwia:
Zwiększ szybkość punktu kontrolnego nawet o 1000 razy , korzystając z prostego interfejsu API, który działa asynchronicznie z procesem trenowania. Mgławica może skrócić czasy punktu kontrolnego od godzin do sekund — potencjalna redukcja 95% do 99%.
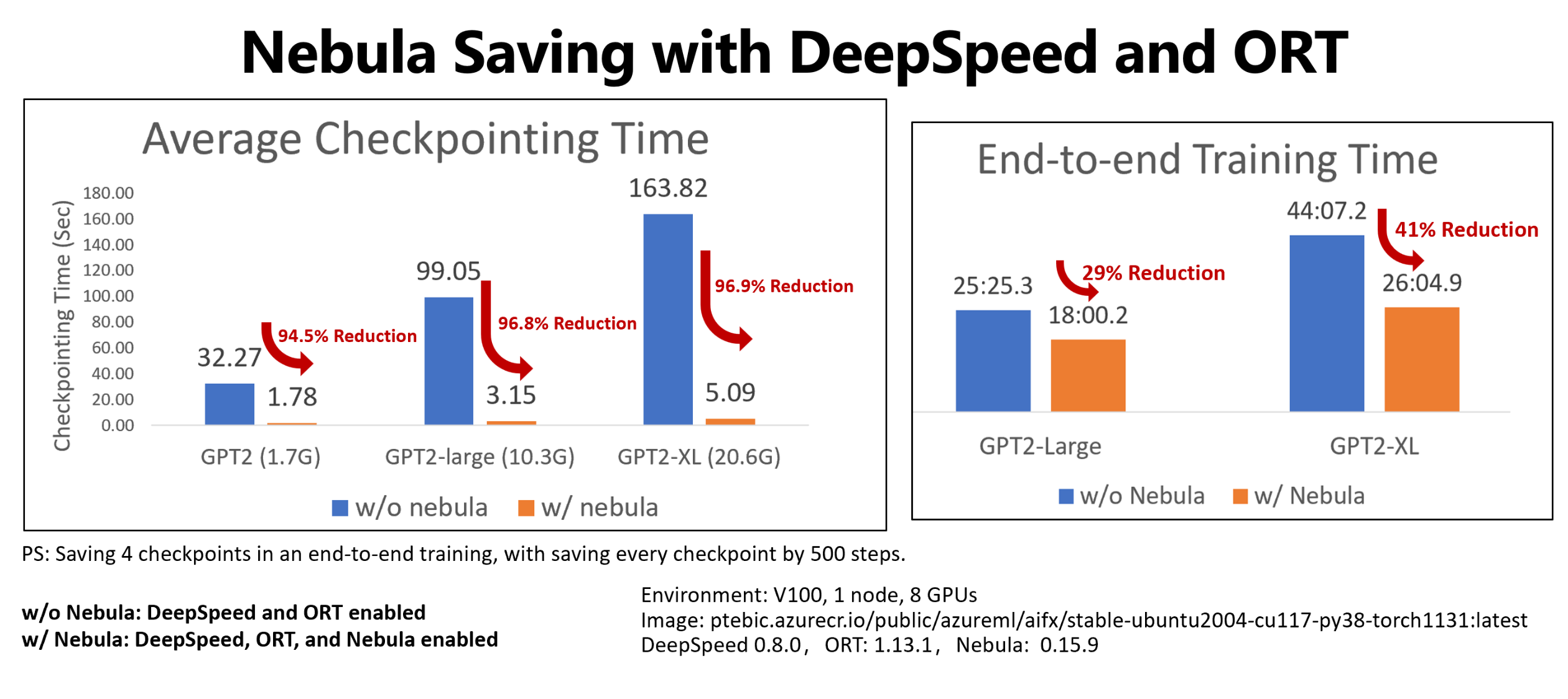
W tym przykładzie pokazano punkt kontrolny i kompleksową redukcję czasu trenowania dla czterech punktów kontrolnych oszczędzających zadania szkoleniowe Hugging Face GPT2, GPT2-Large i GPT-XL. Dla średniej wielkości Hugging Face GPT2-XL punkt kontrolny zapisuje (20,6 GB), mgławica osiągnęła 96,9% redukcji czasu dla jednego punktu kontrolnego.
Przyrost szybkości punktu kontrolnego może nadal zwiększać się wraz z rozmiarem modelu i liczbami procesorów GPU. Na przykład testowanie punktu kontrolnego punktu szkoleniowego zapisuje 97 GB na 128 A100 procesorów GPU firmy Nvidia może zmniejszyć się z 20 minut do 1 sekundy.
Zmniejsz czas kompleksowego trenowania i koszty obliczeń dla dużych modeli , minimalizując obciążenie punktu kontrolnego i zmniejszając liczbę godzin przetwarzania procesora GPU w odzyskiwaniu zadań. Mgławica zapisuje punkty kontrolne asynchronicznie i odblokuje proces trenowania, aby zmniejszyć czas kompleksowego trenowania. Umożliwia również częstsze zapisywanie punktów kontrolnych. Dzięki temu możesz wznowić szkolenie z najnowszego punktu kontrolnego po każdej przerwie oraz zaoszczędzić czas i pieniądze zmarnowane na odzyskiwaniu zadań i godzinach trenowania procesora GPU.
Zapewnienie pełnej zgodności z usługą PyTorch. Mgławica zapewnia pełną zgodność z rozwiązaniem PyTorch i oferuje pełną integrację z rozproszonymi strukturami treningowymi, w tym DeepSpeed (>=0.7.3) i PyTorch Lightning (>=1.5.0). Można go również używać z różnymi celami obliczeniowymi usługi Azure Machine Learning, takimi jak azure Machine Learning Compute lub AKS.
Łatwe zarządzanie punktami kontrolnymi przy użyciu pakietu języka Python, który ułatwia wyświetlanie listy, pobieranie, zapisywanie i ładowanie punktów kontrolnych. Aby wyświetlić cykl życia punktu kontrolnego, mgławica udostępnia również kompleksowe dzienniki w usłudze Azure Machine Learning Studio. Możesz zapisać punkty kontrolne w lokalizacji magazynu lokalnego lub zdalnego
- Azure Blob Storage
- Azure Data Lake Storage
- NFS
dostęp do nich w dowolnym momencie za pomocą kilku wierszy kodu.

Wymagania wstępne
- Subskrypcja platformy Azure i obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat tworzenia zasobów obszaru roboczego, zobacz Tworzenie zasobów obszaru roboczego
- Docelowy obiekt obliczeniowy usługi Azure Machine Learning. Zobacz Zarządzanie trenowania i wdrażanie zasobów obliczeniowych , aby dowiedzieć się więcej o tworzeniu docelowego obiektu obliczeniowego
- Skrypt szkoleniowy korzystający z biblioteki PyTorch.
- Środowisko ACPT-curated (Azure Container for PyTorch). Zobacz Wyselekcjonowane środowiska, aby uzyskać obraz ACPT. Dowiedz się, jak używać wyselekcjonowanych środowisk
Jak używać mgławicy
Mgławica zapewnia szybkie, łatwe środowisko punktu kontrolnego, bezpośrednio w istniejącym skry skrycie szkoleniowym. Kroki, które należy wykonać, aby szybko rozpocząć mgławicę, obejmują:
- Korzystanie ze środowiska ACPT
- Inicjowanie mgławicy
- Wywoływanie interfejsów API w celu zapisywania i ładowania punktów kontrolnych
Korzystanie ze środowiska ACPT
Kontener platformy Azure dla PyTorch (ACPT) — wyselekcjonowane środowisko do trenowania modelu PyTorch, obejmuje mgławicę jako wstępnie zainstalowany, zależny pakiet języka Python. Zobacz Azure Container for PyTorch (ACPT), aby wyświetlić wyselekcjonowane środowisko i Włączanie uczenia głębokiego za pomocą usługi Azure Container for PyTorch w usłudze Azure Machine Learning , aby dowiedzieć się więcej o obrazie ACPT.
Inicjowanie mgławicy
Aby włączyć mgławicę ze środowiskiem ACPT, wystarczy zmodyfikować skrypt trenowania w celu zaimportowania nebulaml pakietu, a następnie wywołać interfejsy API mgławic w odpowiednich miejscach. Możesz uniknąć modyfikacji zestawu AZURE Machine Learning SDK lub interfejsu wiersza polecenia. Można również uniknąć modyfikacji innych kroków trenowania dużego modelu na platformie Azure Machine Learning Platform.
Mgławica wymaga zainicjowania w celu uruchomienia skryptu szkoleniowego. W fazie inicjowania określ zmienne, które określają lokalizację i częstotliwość zapisywania punktu kontrolnego, jak pokazano w tym fragmencie kodu:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Mgławica została zintegrowana z DeepSpeed i PyTorch Lightning. W rezultacie inicjowanie staje się proste i łatwe. W tych przykładach pokazano, jak zintegrować mgławicę ze skryptami treningowymi.
Ważne
Zapisywanie punktów kontrolnych za pomocą mgławicy wymaga pewnej pamięci do przechowywania punktów kontrolnych. Upewnij się, że pamięć jest większa niż co najmniej trzy kopie punktów kontrolnych.
Jeśli pamięć nie wystarczy do przechowywania punktów kontrolnych, zaleca się skonfigurowanie zmiennej NEBULA_MEMORY_BUFFER_SIZE środowiskowej w poleceniu w celu ograniczenia użycia pamięci dla każdego węzła podczas zapisywania punktów kontrolnych. Podczas ustawiania tej zmiennej mgławica będzie używać tej pamięci jako buforu do zapisywania punktów kontrolnych. Jeśli użycie pamięci nie jest ograniczone, mgławica będzie używać pamięci jak najwięcej do przechowywania punktów kontrolnych.
Jeśli wiele procesów jest uruchomionych w tym samym węźle, maksymalna ilość pamięci do zapisywania punktów kontrolnych będzie połowę limitu podzielonego przez liczbę procesów. Mgławica będzie używać drugiej połowy do koordynacji wieloprocesowej. Jeśli na przykład chcesz ograniczyć użycie pamięci dla każdego węzła do 200 MB, możesz ustawić zmienną środowiskową jako export NEBULA_MEMORY_BUFFER_SIZE=200000000 (w bajtach około 200 MB) w poleceniu . W takim przypadku mgławica będzie używać tylko pamięci 200 MB do przechowywania punktów kontrolnych w każdym węźle. Jeśli w tym samym węźle działa 4 procesy, mgławica będzie używać 25 MB pamięci na każdy proces do przechowywania punktów kontrolnych.
Wywoływanie interfejsów API w celu zapisywania i ładowania punktów kontrolnych
Mgławica udostępnia interfejsy API do obsługi zapisywania punktów kontrolnych. Te interfejsy API można używać w skryptach szkoleniowych, podobnie jak w przypadku interfejsu API PyTorch torch.save() . W tych przykładach pokazano, jak używać mgławicy w skryptach szkoleniowych.
Wyświetlanie historii punktów kontrolnych
Po zakończeniu zadania szkoleniowego przejdź do okienka Zadanie Name> Outputs + logs . W panelu po lewej stronie rozwiń folder Mgławica i wybierz, checkpointHistories.csv aby wyświetlić szczegółowe informacje o zapisach punktu kontrolnego mgławicy — czas trwania, przepływność i rozmiar punktu kontrolnego.

Przykłady
W tych przykładach pokazano, jak używać mgławicy z różnymi typami struktury. Możesz wybrać przykład najlepiej pasujący do skryptu szkoleniowego.
- Korzystanie z biblioteki PyTorch natywnie
- Korzystanie z funkcji DeepSpeed
- Korzystanie z pioruna PyTorch
Aby włączyć pełną zgodność mgławicy ze skryptami treningowymi opartymi na protokole PyTorch, zmodyfikuj skrypt trenowania zgodnie z potrzebami.
Najpierw zaimportuj wymagany
nebulamlpakiet:# Import the Nebula package for fast-checkpointing import nebulaml as nmAby zainicjować mgławicę, wywołaj
nm.init()funkcję wmain()metodzie , jak pokazano poniżej:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)Aby zapisać punkty kontrolne, zastąp oryginalną
torch.save()instrukcję , aby zapisać punkt kontrolny mgławicą. Upewnij się, że wystąpienie punktu kontrolnego zaczyna się od ciągu "global_step", takiego jak "global_step500" lub "global_step1000":checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Uwaga
<'CKPT_TAG_NAME'>jest unikatowym identyfikatorem punktu kontrolnego. Tag jest zwykle liczbą kroków, numerem epoki lub dowolną nazwą zdefiniowaną przez użytkownika. Opcjonalny opcjonalny<'NUM_OF_FILES'>parametr określa numer stanu, który można zapisać dla tego tagu.Załaduj najnowszy prawidłowy punkt kontrolny, jak pokazano poniżej:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Ponieważ punkt kontrolny lub migawka może zawierać wiele plików, można załadować jeden lub więcej z nich według nazwy. Przy użyciu najnowszego punktu kontrolnego stan trenowania można przywrócić do stanu zapisanego przez ostatni punkt kontrolny.
Inne interfejsy API mogą obsługiwać zarządzanie punktami kontrolnymi
- wyświetlanie listy wszystkich punktów kontrolnych
- pobieranie najnowszych punktów kontrolnych
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)