Używanie zadań równoległych w potokach
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W tym artykule wyjaśniono, jak używać interfejsu wiersza polecenia w wersji 2 i zestawu Python SDK w wersji 2 do uruchamiania zadań równoległych w potokach usługi Azure Machine Learning. Zadania równoległe przyspieszają wykonywanie zadań, dystrybuując powtarzające się zadania w zaawansowanych klastrach obliczeniowych z wieloma węzłami.
Inżynierowie uczenia maszynowego zawsze mają wymagania dotyczące skalowania w swoich zadaniach szkoleniowych lub wnioskowania. Na przykład gdy analityk danych udostępnia pojedynczy skrypt do trenowania modelu przewidywania sprzedaży, inżynierowie uczenia maszynowego muszą zastosować to zadanie szkoleniowe do poszczególnych magazynów danych. Wyzwania związane z tym procesem skalowania w poziomie obejmują długie czasy wykonywania, które powodują opóźnienia, oraz nieoczekiwane problemy wymagające interwencji ręcznej w celu utrzymania działania zadania.
Podstawowym zadaniem równoległości usługi Azure Machine Learning jest podzielenie pojedynczego zadania szeregowego na minisady i wysłanie tych minisadów do wielu obliczeń w celu równoległego wykonania. Zadania równoległe znacznie zmniejszają czas kompleksowego wykonywania, a także automatycznie obsługują błędy. Rozważ użycie zadania równoległego usługi Azure Machine Learning, aby wytrenować wiele modeli na podstawie partycjonowanych danych lub przyspieszyć zadania wnioskowania wsadowego na dużą skalę.
Na przykład w scenariuszu, w którym uruchamiasz model wykrywania obiektów na dużym zestawie obrazów, równoległe zadania usługi Azure Machine Learning umożliwiają łatwe dystrybuowanie obrazów w celu równoległego uruchamiania niestandardowego kodu w określonym klastrze obliczeniowym. Równoległe może znacznie zmniejszyć koszt czasu. Zadania równoległe usługi Azure Machine Learning mogą również uprościć i zautomatyzować proces, aby uczynić go bardziej wydajnym.
Wymagania wstępne
- Posiadanie konta i obszaru roboczego usługi Azure Machine Learning.
- Omówienie potoków usługi Azure Machine Learning.
- Zainstaluj interfejs wiersza polecenia platformy
mlAzure i rozszerzenie. Aby uzyskać więcej informacji, zobacz Instalowanie, konfigurowanie i używanie interfejsu wiersza polecenia (wersja 2).mlRozszerzenie automatycznie instaluje polecenie po raz pierwszyaz ml. - Dowiedz się, jak tworzyć i uruchamiać potoki i składniki usługi Azure Machine Learning za pomocą interfejsu wiersza polecenia w wersji 2.
Tworzenie i uruchamianie potoku za pomocą kroku zadania równoległego
Równoległe zadanie usługi Azure Machine Learning może być używane tylko jako krok w zadaniu potoku.
Poniższe przykłady pochodzą z artykułu Uruchamianie zadania potoku przy użyciu zadania równoległego w potoku w repozytorium przykładów usługi Azure Machine Learning.
Przygotowanie do przetwarzania równoległego
Ten krok zadania równoległego wymaga przygotowania. Potrzebny jest skrypt wejściowy, który implementuje wstępnie zdefiniowane funkcje. Należy również ustawić atrybuty w definicji zadania równoległego, które:
- Zdefiniuj i powiąż dane wejściowe.
- Ustaw metodę dzielenia danych.
- Konfigurowanie zasobów obliczeniowych.
- Wywołaj skrypt wejścia.
W poniższych sekcjach opisano sposób przygotowywania zadania równoległego.
Deklarowanie ustawienia danych wejściowych i dzielenia danych
Zadanie równoległe wymaga podzielenia i przetworzenia jednego głównego danych wejściowych. Głównym formatem danych wejściowych może być dane tabelaryczne lub lista plików.
Różne formaty danych mają różne typy danych wejściowych, tryby wejściowe i metody dzielenia danych. W poniższej tabeli opisano opcje:
| Format danych | Input type | Tryb wprowadzania | Metoda dzielenia danych |
|---|---|---|---|
| Lista plików | mltable lub uri_folder |
ro_mount lub download |
Według rozmiaru (liczby plików) lub według partycji |
| Dane tabelaryczne | mltable |
direct |
Według rozmiaru (szacowany rozmiar fizyczny) lub według partycji |
Uwaga
Jeśli używasz tabelarycznych mltable danych wejściowych jako głównych danych wejściowych, musisz:
- Zainstaluj bibliotekę
mltablew środowisku, tak jak w wierszu 9 tego pliku conda. - Plik specyfikacji TABELI MLTable w określonej ścieżce zawiera wypełnioną sekcję
transformations: - read_delimited:. Aby zapoznać się z przykładami, zobacz Tworzenie zasobów danych i zarządzanie nimi.
Główne dane wejściowe można zadeklarować za pomocą atrybutu input_data w równoległym zadaniu YAML lub Python i powiązać dane ze zdefiniowanym input zadaniem równoległym przy użyciu polecenia ${{inputs.<input name>}}. Następnie zdefiniuj atrybut dzielenia danych dla głównych danych wejściowych w zależności od metody dzielenia danych.
| Metoda dzielenia danych | Attribute name | Typ atrybutu | Przykład zadania |
|---|---|---|---|
| Według rozmiaru | mini_batch_size |
string | Przewidywanie partii irysów |
| Według partycji | partition_keys |
lista ciągów | Przewidywanie sprzedaży soku pomarańczowego |
Konfigurowanie zasobów obliczeniowych na potrzeby przetwarzania równoległego
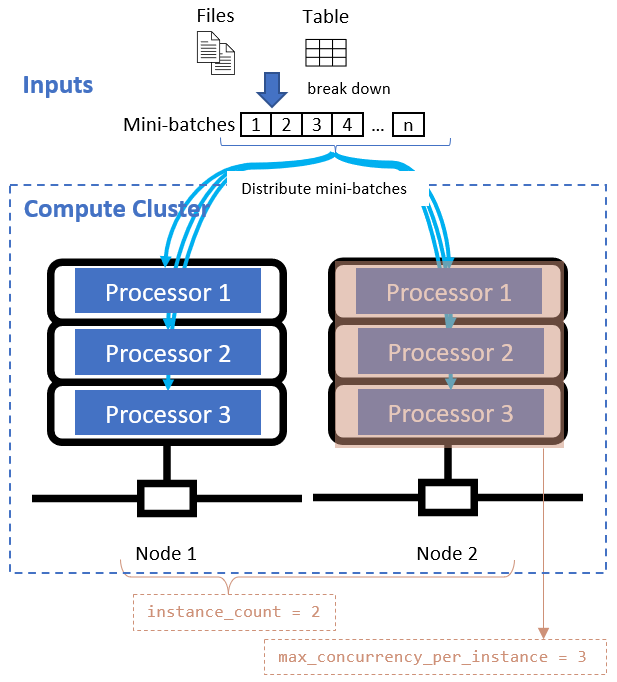
Po zdefiniowaniu atrybutu dzielenia danych skonfiguruj zasoby obliczeniowe na potrzeby przetwarzania równoległego, ustawiając instance_count atrybuty i max_concurrency_per_instance .
| Attribute name | Type | Opis | Domyślna wartość |
|---|---|---|---|
instance_count |
integer | Liczba węzłów do użycia dla zadania. | 1 |
max_concurrency_per_instance |
integer | Liczba procesorów w każdym węźle. | W przypadku obliczeń procesora GPU: 1. W przypadku obliczeń procesora CPU: liczba rdzeni. |
Te atrybuty współpracują z określonym klastrem obliczeniowym, jak pokazano na poniższym diagramie:
Wywoływanie skryptu wejścia
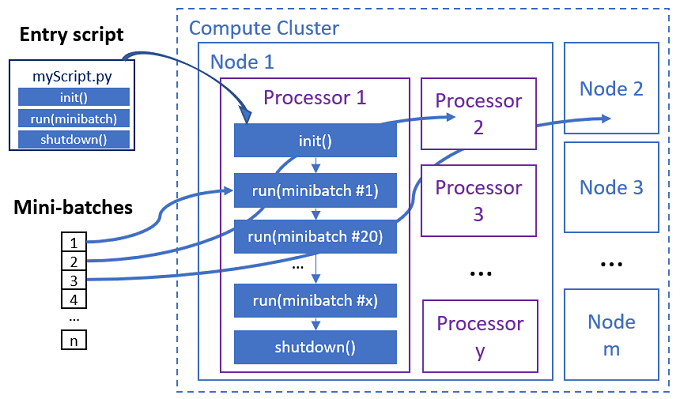
Skrypt wejściowy to pojedynczy plik w języku Python, który implementuje następujące trzy wstępnie zdefiniowane funkcje z kodem niestandardowym.
| Nazwa funkcji | Wymagania | Popis | Dane wejściowe | Powrót |
|---|---|---|---|---|
Init() |
Y | Typowe przygotowanie przed rozpoczęciem uruchamiania minisadów. Na przykład użyj tej funkcji, aby załadować model do obiektu globalnego. | -- | -- |
Run(mini_batch) |
Y | Implementuje główną logikę wykonywania dla mini-partii. | mini_batch to ramka danych biblioteki pandas, jeśli dane wejściowe są danymi tabelarycznymi lub listą ścieżek plików, jeśli dane wejściowe są katalogiem. |
Ramka danych, lista lub krotka. |
Shutdown() |
N | Opcjonalna funkcja do wykonania oczyszczania niestandardowego przed zwróceniem obliczeń do puli. | -- | -- |
Ważne
Aby uniknąć wyjątków podczas analizowania argumentów w Init() funkcji lubRun(mini_batch), użyj zamiast parse_args.parse_known_args Zobacz iris_score przykładowy skrypt wpisu z analizatorem argumentów.
Ważne
Funkcja Run(mini_batch) wymaga zwrócenia ramki danych, listy lub elementu krotki. Zadanie równoległe używa liczby tego powrotu, aby zmierzyć elementy sukcesu w tej minisadowej partii. Liczba minisadów powinna być równa liczbie zwracanych list, jeśli wszystkie elementy zostały przetworzone.
Zadanie równoległe wykonuje funkcje w każdym procesorze, jak pokazano na poniższym diagramie.
Zobacz następujące przykłady skryptów wejściowych:
Aby wywołać skrypt wejściowy, ustaw następujące dwa atrybuty w definicji zadania równoległego:
| Attribute name | Type | opis |
|---|---|---|
code |
string | Ścieżka lokalna do katalogu kodu źródłowego w celu przekazania i użycia dla zadania. |
entry_script |
string | Plik języka Python zawierający implementację wstępnie zdefiniowanych funkcji równoległych. |
Przykład kroku zadania równoległego
Poniższy krok zadania równoległego deklaruje typ danych wejściowych, tryb i metodę dzielenia danych, wiąże dane wejściowe, konfiguruje obliczenia i wywołuje skrypt wejściowy.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Rozważ ustawienia automatyzacji
Równoległe zadanie usługi Azure Machine Learning uwidacznia wiele ustawień opcjonalnych, które mogą automatycznie kontrolować zadanie bez interwencji ręcznej. W poniższej tabeli opisano te ustawienia.
| Klucz | Type | Opis | Dozwolone wartości | Domyślna wartość | Ustaw w atrybucie lub argumencie programu |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Liczba nieudanych minisadów do zignorowania w tym zadaniu równoległym. Jeśli liczba nieudanych minisadów jest większa niż ten próg, zadanie równoległe zostanie oznaczone jako niepowodzenie. Mini-batch jest oznaczony jako niepowodzenie, jeśli: - Liczba zwrotów z run() jest mniejsza niż liczba danych wejściowych mini-partii.— Wyjątki są przechwytywane w kodzie niestandardowym run() . |
[-1, int.max] |
-1, co oznacza ignorowanie wszystkich nieudanych minisadów |
Atrybut mini_batch_error_threshold |
mini_batch_max_retries |
integer | Liczba ponownych prób w przypadku niepowodzenia lub limitu czasu minisadowania. Jeśli wszystkie ponawianie prób nie powiedzie się, minisada zostanie oznaczona jako niepowodzenie zgodnie z obliczeniami mini_batch_error_threshold . |
[0, int.max] |
2 |
Atrybut retry_settings.max_retries |
mini_batch_timeout |
integer | Limit czasu w sekundach wykonywania funkcji niestandardowej run() . Jeśli czas wykonywania jest wyższy niż ten próg, mini-batch zostanie przerwany i oznaczony jako nie można wyzwolić ponawiania próby. |
(0, 259200] |
60 |
Atrybut retry_settings.timeout |
item_error_threshold |
integer | Próg elementów, które zakończyły się niepowodzeniem. Elementy, które zakończyły się niepowodzeniem, są liczone przez lukę liczbową między danymi wejściowymi i zwracanymi z każdej minisadowej partii. Jeśli suma elementów, które zakończyły się niepowodzeniem, jest wyższa niż ten próg, zadanie równoległe jest oznaczone jako niepowodzenie. | [-1, int.max] |
-1, co oznacza ignorowanie wszystkich niepowodzeń podczas równoległego zadania |
Argument programu--error_threshold |
allowed_failed_percent |
integer | Podobnie jak mini_batch_error_thresholdw przypadku metody , ale używa procentu nieudanych minisadów zamiast liczby. |
[0, 100] |
100 |
Argument programu--allowed_failed_percent |
overhead_timeout |
integer | Limit czasu w sekundach na potrzeby inicjowania każdej minisady. Na przykład załaduj dane minisadowe i przekaż je do run() funkcji. |
(0, 259200] |
600 |
Argument programu--task_overhead_timeout |
progress_update_timeout |
integer | Limit czasu w sekundach monitorowania postępu wykonywania minisadowego. Jeśli w tym ustawieniu limitu czasu nie zostaną odebrane żadne aktualizacje postępu, zadanie równoległe zostanie oznaczone jako niepowodzenie. | (0, 259200] |
Dynamicznie obliczane przez inne ustawienia | Argument programu--progress_update_timeout |
first_task_creation_timeout |
integer | Limit czasu w sekundach na monitorowanie czasu między uruchomieniem zadania a uruchomieniem pierwszej mini-partii. | (0, 259200] |
600 |
Argument programu--first_task_creation_timeout |
logging_level |
string | Poziom dzienników do zrzutu do plików dziennika użytkownika. | INFO, WARNING lub DEBUG |
INFO |
Atrybut logging_level |
append_row_to |
string | Zagreguj wszystkie zwroty z każdego przebiegu mini-partii i wyprowadź je do tego pliku. Może odwoływać się do jednego z danych wyjściowych zadania równoległego przy użyciu wyrażenia ${{outputs.<output_name>}} |
Atrybut task.append_row_to |
||
copy_logs_to_parent |
string | Opcja logiczna, czy skopiować postęp zadania, przegląd i dzienniki do nadrzędnego zadania potoku. | True lub False |
False |
Argument programu--copy_logs_to_parent |
resource_monitor_interval |
integer | Interwał czasu w sekundach do zrzutu użycia zasobów węzła (na przykład procesora CPU lub pamięci) do folderu dziennika w ścieżce dzienników/sys/perf . Uwaga: Częste dzienniki zasobów zrzutu nieco powolna szybkość wykonywania. Ustaw tę wartość na wartość , aby 0 zatrzymać dumping użycia zasobów. |
[0, int.max] |
600 |
Argument programu--resource_monitor_interval |
Poniższy przykładowy kod aktualizuje następujące ustawienia:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Tworzenie potoku za pomocą kroku zadania równoległego
W poniższym przykładzie pokazano pełne zadanie potoku z wbudowanym krokiem zadania równoległego:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Przesyłanie zadania potoku
Prześlij zadanie potoku z równoległym krokiem za pomocą polecenia interfejsu az ml job create wiersza polecenia:
az ml job create --file pipeline.yml
Sprawdzanie kroku równoległego w interfejsie użytkownika programu Studio
Po przesłaniu zadania potoku zestaw SDK lub widżet interfejsu wiersza polecenia udostępnia link internetowy do grafu potoku w interfejsie użytkownika usługi Azure Machine Learning Studio.
Aby wyświetlić wyniki zadań równoległych, kliknij dwukrotnie krok równoległy na wykresie potoku, wybierz kartę Ustawienia w panelu szczegółów, rozwiń węzeł Ustawienia uruchamiania, a następnie rozwiń sekcję Równoległe.

Aby debugować błąd zadania równoległego, wybierz kartę Dane wyjściowe i dzienniki, rozwiń folder logs i sprawdź job_result.txt, aby dowiedzieć się, dlaczego zadanie równoległe zakończyło się niepowodzeniem. Aby uzyskać informacje o strukturze rejestrowania zadań równoległych, zobacz readme.txt w tym samym folderze.
