Jak używać modeli platformy Open Source wyselekcjonowanych przez usługę Azure Machine Learning
Z tego artykułu dowiesz się, jak dostosować, ocenić i wdrożyć modele podstawowe w katalogu modeli.
Możesz szybko przetestować dowolny wstępnie wytrenowany model przy użyciu formularza przykładowego wnioskowania na karcie modelu, podając własne przykładowe dane wejściowe do przetestowania wyniku. Ponadto karta modelu dla każdego modelu zawiera krótki opis modelu i linki do przykładów na potrzeby wnioskowania na podstawie kodu, dostrajania i oceny modelu.
Jak oceniać modele podstawowe przy użyciu własnych danych testowych
Możesz ocenić model foundation względem zestawu danych testowego przy użyciu formularza Evaluate UI (Ocena interfejsu użytkownika) lub przy użyciu przykładów opartych na kodzie połączonych z kartą modelu.
Ocenianie przy użyciu programu Studio
Formularz Ocena modelu można wywołać, wybierając przycisk Oceń na karcie modelu dla dowolnego modelu podstawowego.
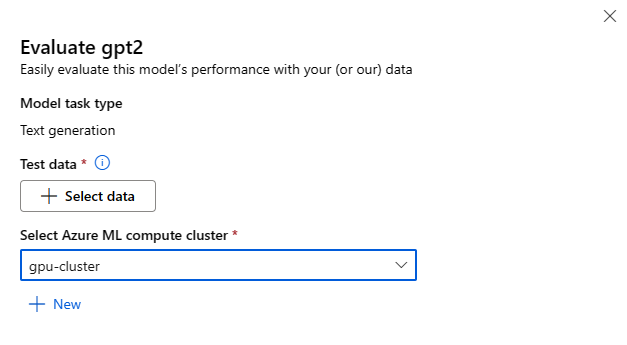
Każdy model można ocenić pod kątem określonego zadania wnioskowania, dla którego będzie używany model.
Dane testowe:
- Przekaż dane testowe, których chcesz użyć do oceny modelu. Możesz przekazać plik lokalny (w formacie JSONL) lub wybrać istniejący zarejestrowany zestaw danych z obszaru roboczego.
- Po wybraniu zestawu danych należy zamapować kolumny z danych wejściowych na podstawie schematu potrzebnego do wykonania zadania. Na przykład zamapuj nazwy kolumn, które odpowiadają kluczom "zdanie" i "etykieta" dla klasyfikacji tekstu

Obliczenia:
Podaj klaster obliczeniowy usługi Azure Machine Learning, którego chcesz użyć do dostrajania modelu. Ocena musi być uruchamiana na obliczeniach procesora GPU. Upewnij się, że masz wystarczający limit przydziału zasobów obliczeniowych dla jednostek SKU obliczeniowych, których chcesz użyć.
Wybierz pozycję Zakończ w formularzu Ocena, aby przesłać zadanie oceny. Po zakończeniu zadania można wyświetlić metryki oceny dla modelu. Na podstawie metryk oceny możesz zdecydować, czy chcesz dostosować model przy użyciu własnych danych treningowych. Ponadto możesz zdecydować, czy chcesz zarejestrować model i wdrożyć go w punkcie końcowym.
Ocenianie przy użyciu przykładów opartych na kodzie
Aby umożliwić użytkownikom szybkie rozpoczęcie pracy z dostosowaniem, opublikowaliśmy przykłady (zarówno notesy języka Python, jak i przykłady CLI) dla każdego zadania w repozytorium Przykłady oceny git azureml-examples. Każda karta modelu zawiera również łącza do przykładów oceny dla odpowiednich zadań
Jak dostosować modele podstaw przy użyciu własnych danych treningowych
Aby zwiększyć wydajność modelu w obciążeniu, warto dostosować model podstawowy przy użyciu własnych danych treningowych. Możesz łatwo dostosować te modele podstawowe przy użyciu ustawień dostrojenia w studio lub przy użyciu przykładów opartych na kodzie połączonych z karty modelu.
Dostrajanie przy użyciu studia
Formularz ustawień dostrajania można wywołać, wybierając przycisk Dostosuj dopasuj na karcie modelu dla dowolnego modelu podstawowego.
Dostosuj ustawienia:
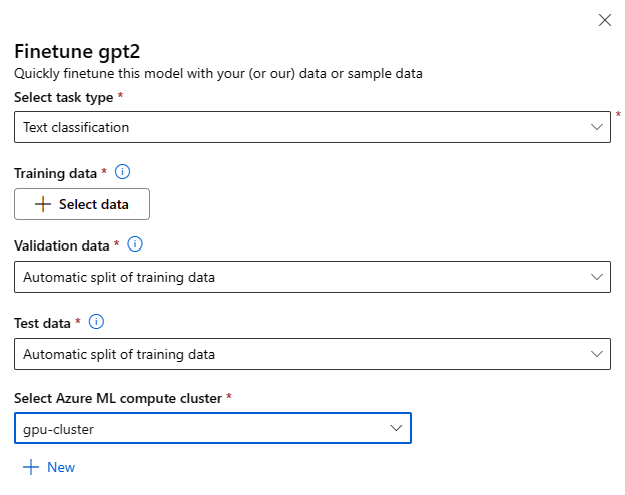
Dostrajanie typu zadania
- Każdy wstępnie wytrenowany model z wykazu modeli można dostosować do określonego zestawu zadań (na przykład: klasyfikacja tekstu, klasyfikacja tokenów, odpowiadanie na pytania). Wybierz zadanie, którego chcesz użyć z listy rozwijanej.
Dane szkoleniowe
Przekaż dane szkoleniowe, których chcesz użyć, aby dostosować model. Możesz przekazać plik lokalny (w formacie JSONL, CSV lub TSV) albo wybrać istniejący zarejestrowany zestaw danych z obszaru roboczego.
Po wybraniu zestawu danych należy zmapować kolumny z danych wejściowych na podstawie schematu potrzebnego do wykonania zadania. Na przykład: mapowanie nazw kolumn odpowiadających kluczom "zdanie" i "etykieta" dla klasyfikacji tekstu

- Dane weryfikacji: przekaż dane, których chcesz użyć do zweryfikowania modelu. Wybranie opcji Automatyczne dzielenie powoduje automatyczne podzielenie danych treningowych na potrzeby walidacji. Alternatywnie możesz podać inny zestaw danych weryfikacji.
- Dane testowe: przekaż dane testowe, których chcesz użyć, aby ocenić dostosowany model. Wybranie opcji Automatyczne dzielenie powoduje rezerwowanie automatycznego podziału danych treningowych na potrzeby testu.
- Obliczenia: podaj klaster obliczeniowy usługi Azure Machine Learning, którego chcesz użyć do dostrajania modelu. Dostrajanie musi być uruchamiane na obliczeniach procesora GPU. Zalecamy używanie jednostek SKU obliczeniowych z procesorami GPU A100/V100 podczas dostrajania. Upewnij się, że masz wystarczający limit przydziału zasobów obliczeniowych dla jednostek SKU obliczeniowych, których chcesz użyć.
- Wybierz pozycję Zakończ w formularzu dostrajania, aby przesłać zadanie dostrajania. Po zakończeniu zadania można wyświetlić metryki oceny dla dostosowanego modelu. Następnie możesz zarejestrować dostosowane dane wyjściowe modelu przez zadanie dostrajania i wdrożyć ten model w punkcie końcowym na potrzeby wnioskowania.
Dostosowywanie przy użyciu przykładów opartych na kodzie
Obecnie usługa Azure Machine Learning obsługuje dostrajanie modeli dla następujących zadań językowych:
- Klasyfikacja tekstu
- klasyfikacja tokenów
- Odpowiadanie na pytania
- Podsumowanie
- Tłumaczenie
Aby umożliwić użytkownikom szybkie rozpoczęcie pracy z dostrajaniem, opublikowaliśmy przykłady (zarówno notesy języka Python, jak i przykłady interfejsu wiersza polecenia) dla każdego zadania w repozytorium git azureml-examples. Każda karta modelu zawiera również linki do przykładów dostosowania do obsługiwanych zadań dostosowania.
Wdrażanie modeli podstawowych w punktach końcowych na potrzeby wnioskowania
Modele podstawowe (zarówno wstępnie wytrenowane modele z katalogu modeli, jak i dostosowane modele, po zarejestrowaniu ich w obszarze roboczym) można wdrożyć w punkcie końcowym, który może być następnie używany do wnioskowania. Wdrażanie zarówno bezserwerowych interfejsów API, jak i zarządzanych zasobów obliczeniowych jest obsługiwane. Te modele można wdrożyć przy użyciu kreatora Wdrażanie interfejsu użytkownika lub przy użyciu przykładów opartych na kodzie połączonych z kartą modelu.
Wdrażanie przy użyciu programu Studio
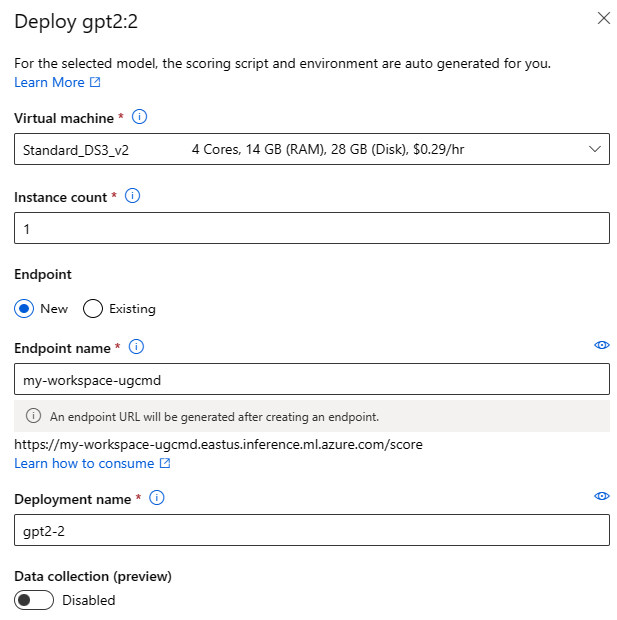
Formularz Deploy UI (Wdrażanie interfejsu użytkownika) można wywołać, wybierając przycisk Deploy (Wdróż ) na karcie modelu dla dowolnego modelu podstawowego i wybierając pozycję Bezserwerowy interfejs API z zabezpieczeniami zawartości usługi Azure AI lub zarządzanymi obliczeniami bez bezpieczeństwa zawartości usługi Azure AI

Ustawienia wdrażania
Ponieważ skrypt oceniania i środowisko są automatycznie dołączane do modelu podstawowego, wystarczy określić jednostkę SKU maszyny wirtualnej do użycia, liczbę wystąpień i nazwę punktu końcowego do użycia na potrzeby wdrożenia.
Przydział udostępniony
Jeśli wdrażasz model Llama-2, Phi, Nemotron, Mistral, Dolly lub Deci-DeciLM z katalogu modeli, ale nie masz wystarczającego limitu przydziału dostępnego dla wdrożenia, usługa Azure Machine Learning umożliwia korzystanie z limitu przydziału z udostępnionej puli przydziałów przez ograniczony czas. Aby uzyskać więcej informacji na temat przydziału współużytkowanego, zobacz Udostępniony limit przydziału Azure Machine Learning.

Wdrażanie przy użyciu przykładów opartych na kodzie
Aby umożliwić użytkownikom szybkie rozpoczęcie wdrażania i wnioskowania, opublikowaliśmy przykłady w przykładach wnioskowania w repozytorium git azureml-examples. Opublikowane przykłady obejmują notesy języka Python i przykłady interfejsu wiersza polecenia. Każda karta modelu łączy się również z przykładami wnioskowania w czasie rzeczywistym i wnioskowaniem w usłudze Batch.
Importowanie modeli podstawowych
Jeśli chcesz użyć modelu open source, który nie jest uwzględniony w wykazie modeli, możesz zaimportować model z obszaru roboczego Hugging Face do obszaru roboczego usługi Azure Machine Learning. Hugging Face to biblioteka typu open source do przetwarzania języka naturalnego (NLP), która udostępnia wstępnie wytrenowane modele dla popularnych zadań NLP. Obecnie import modelu obsługuje importowanie modeli dla następujących zadań, o ile model spełnia wymagania wymienione w notesie importu modelu:
- wypełnianie maski
- klasyfikacja tokena
- odpowiadanie na pytania
- podsumowanie
- generowanie tekstu
- klasyfikacja tekstu
- tłumaczenie
- klasyfikacja obrazów
- tekst na obraz
Uwaga
Modele z funkcji Hugging Face podlegają postanowieniom licencyjnym innych firm dostępnym na stronie szczegółów modelu rozpoznawania twarzy Hugging. Użytkownik ponosi odpowiedzialność za przestrzeganie postanowień licencyjnych modelu.
Możesz wybrać przycisk Importuj w prawym górnym rogu wykazu modeli, aby użyć notesu importu modelu.
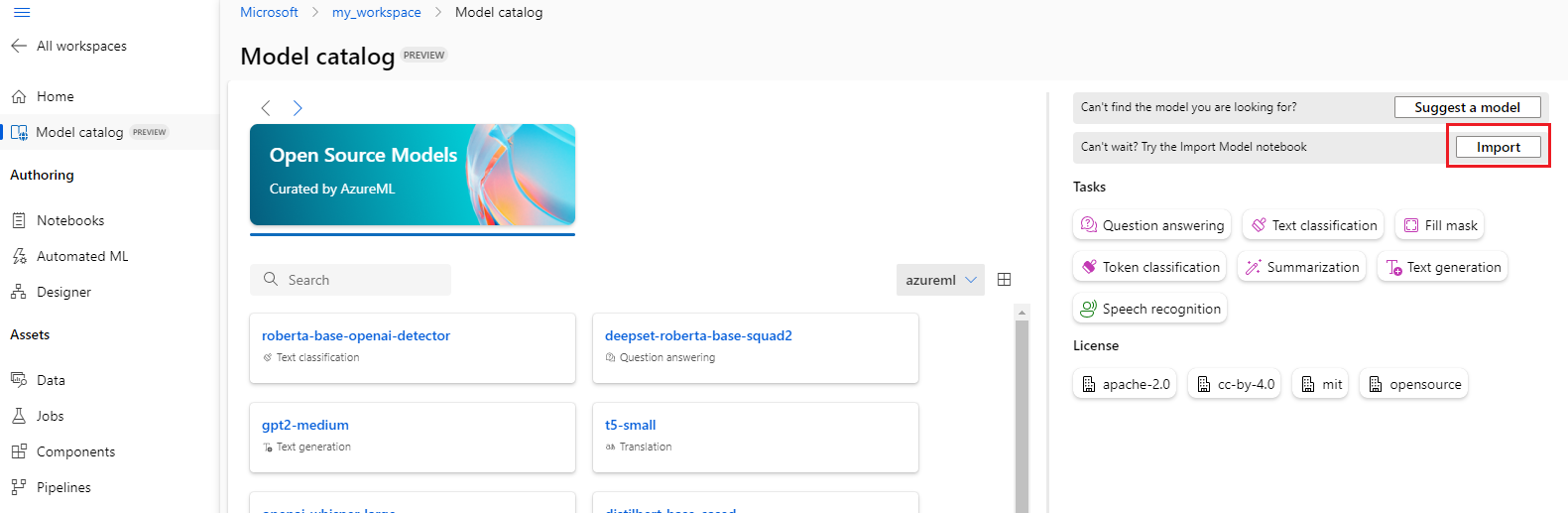
Notes importu modelu jest również zawarty w repozytorium azureml-examples git repo tutaj.
Aby zaimportować model, musisz przekazać MODEL_ID model, który chcesz zaimportować z funkcji Hugging Face. Przeglądaj modele w centrum hugging Face i zidentyfikuj model do zaimportowania. Upewnij się, że typ zadania modelu należy do obsługiwanych typów zadań. Skopiuj identyfikator modelu, który jest dostępny w identyfikatorze URI strony lub można skopiować przy użyciu ikony kopiowania obok nazwy modelu. Przypisz ją do zmiennej "MODEL_ID" w notesie importu modelu. Na przykład:
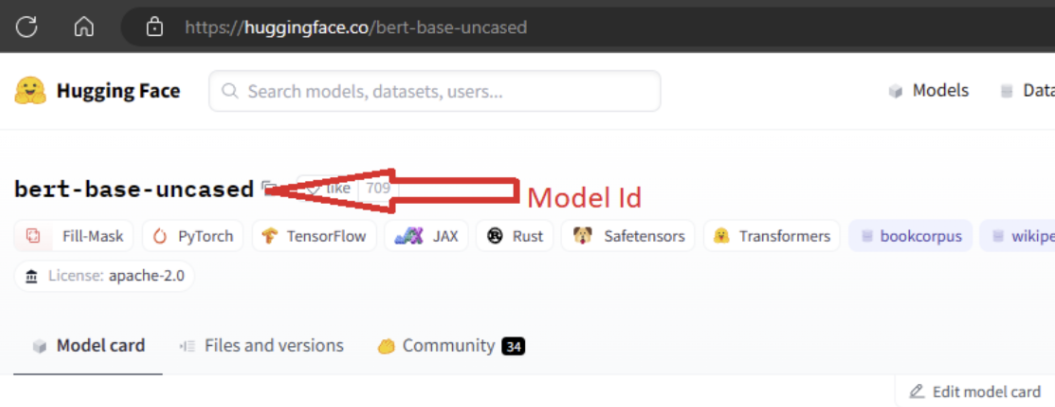
Aby można było uruchomić importowanie modelu, należy podać zasoby obliczeniowe. Uruchomienie importu modelu powoduje zaimportowanie określonego modelu z funkcji Hugging Face i zarejestrowanego w obszarze roboczym usługi Azure Machine Learning. Następnie można dostosować ten model lub wdrożyć go w punkcie końcowym na potrzeby wnioskowania.
Dowiedz się więcej
- Zapoznaj się z wykazem modeli w usłudze Azure Machine Learning Studio. Potrzebujesz obszaru roboczego usługi Azure Machine Learning, aby eksplorować katalog.
- Eksplorowanie wykazu modeli i kolekcji