Konfigurowanie metodyki MLOps za pomocą usługi Azure DevOps
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Usługa Azure Machine Learning umożliwia integrację z potokiem usługi Azure DevOps w celu zautomatyzowania cyklu życia uczenia maszynowego. Niektóre operacje, które można zautomatyzować, to:
- Wdrażanie infrastruktury usługi Azure Machine Learning
- Przygotowywanie danych (wyodrębnianie, przekształcanie, operacje ładowania)
- Trenowanie modeli uczenia maszynowego przy użyciu skalowania na żądanie i skalowania w górę
- Wdrażanie modeli uczenia maszynowego jako publicznych lub prywatnych usług internetowych
- Monitorowanie wdrożonych modeli uczenia maszynowego (na przykład na potrzeby analizy wydajności)
W tym artykule dowiesz się, jak za pomocą usługi Azure Machine Learning skonfigurować pełny potok MLOps, który uruchamia regresję liniową w celu przewidywania opłat za taksówkę w Nowym Jorku. Potok składa się ze składników, z których każda obsługuje różne funkcje, które można zarejestrować w obszarze roboczym, wersjonowanym i ponownie używanym przy użyciu różnych danych wejściowych i wyjściowych. Zamierzasz używać zalecanej architektury platformy Azure dla metodyki MLOps i akceleratora rozwiązań AzureMLOps (wersja 2), aby szybko skonfigurować projekt MLOps w usłudze Azure Machine Learning.
Napiwek
Zalecamy zapoznanie się z niektórymi z zalecanych architektur platformy Azure dla metodyki MLOps przed wdrożeniem dowolnego rozwiązania. Musisz wybrać najlepszą architekturę dla danego projektu uczenia maszynowego.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
- Obszar roboczy usługi Azure Machine Learning.
- Usługa Git uruchomiona na komputerze lokalnym.
- Organizacja w usłudze Azure DevOps.
- Projekt usługi Azure DevOps, który będzie hostować repozytoria źródłowe i potoki.
- Rozszerzenie Terraform dla usługi Azure DevOps, jeśli używasz usługi Azure DevOps i narzędzia Terraform do uruchamiania infrastruktury
Uwaga
Wymagana jest usługa Git w wersji 2.27 lub nowszej. Aby uzyskać więcej informacji na temat instalowania polecenia Git, zobacz https://git-scm.com/downloads i wybierz system operacyjny
Ważne
Polecenia interfejsu wiersza polecenia w tym artykule zostały przetestowane przy użyciu powłoki Bash. Jeśli używasz innej powłoki, mogą wystąpić błędy.
Konfigurowanie uwierzytelniania za pomocą platformy Azure i usługi DevOps
Przed skonfigurowaniem projektu MLOps za pomocą usługi Azure Machine Learning należy skonfigurować uwierzytelnianie dla usługi Azure DevOps.
Tworzenie jednostki usługi
Aby korzystać z pokazu, wymagane jest utworzenie jednej lub dwóch zasad usługi, w zależności od liczby środowisk, na których chcesz pracować (Deweloperzy lub Prod lub Oba). Te zasady można utworzyć przy użyciu jednej z następujących metod:
Uruchom usługę Azure Cloud Shell.
Napiwek
Po pierwszym uruchomieniu usługi Cloud Shell zostanie wyświetlony monit o utworzenie konta magazynu dla usługi Cloud Shell.
Jeśli zostanie wyświetlony monit, wybierz pozycję Bash jako środowisko używane w usłudze Cloud Shell. Możesz również zmienić środowiska na liście rozwijanej na górnym pasku nawigacyjnym
Skopiuj następujące polecenia powłoki bash na komputer i zaktualizuj zmienne projectName, subscriptionId i środowiskowe przy użyciu wartości projektu. Jeśli tworzysz zarówno środowisko deweloperskie, jak i prod, musisz uruchomić ten skrypt raz dla każdego środowiska, tworząc jednostkę usługi dla każdego z nich. To polecenie przyzna również rolę Współautor jednostce usługi w podanej subskrypcji. Jest to wymagane, aby usługa Azure DevOps prawidłowo korzystała z zasobów w tej subskrypcji.
projectName="<your project name>" roleName="Contributor" subscriptionId="<subscription Id>" environment="<Dev|Prod>" #First letter should be capitalized servicePrincipalName="Azure-ARM-${environment}-${projectName}" # Verify the ID of the active subscription echo "Using subscription ID $subscriptionID" echo "Creating SP for RBAC with name $servicePrincipalName, with role $roleName and in scopes /subscriptions/$subscriptionId" az ad sp create-for-rbac --name $servicePrincipalName --role $roleName --scopes /subscriptions/$subscriptionId echo "Please ensure that the information created here is properly save for future use."Skopiuj edytowane polecenia do usługi Azure Shell i uruchom je (Ctrl + Shift + v).
Po uruchomieniu tych poleceń zostaną wyświetlone informacje dotyczące jednostki usługi. Zapisz te informacje w bezpiecznej lokalizacji. Zostanie ona użyta w dalszej części pokazu w celu skonfigurowania usługi Azure DevOps.
{ "appId": "<application id>", "displayName": "Azure-ARM-dev-Sample_Project_Name", "password": "<password>", "tenant": "<tenant id>" }Powtórz krok 3 , jeśli tworzysz jednostki usługi dla środowisk deweloperskich i prod. W tym pokazie utworzymy tylko jedno środowisko, czyli Prod.
Zamknij usługę Cloud Shell po utworzeniu jednostek usługi.
Konfigurowanie usług Azure DevOps
Przejdź do usługi Azure DevOps.
Wybierz pozycję Utwórz nowy projekt (nadaj projektowi
mlopsv2nazwę dla tego samouczka).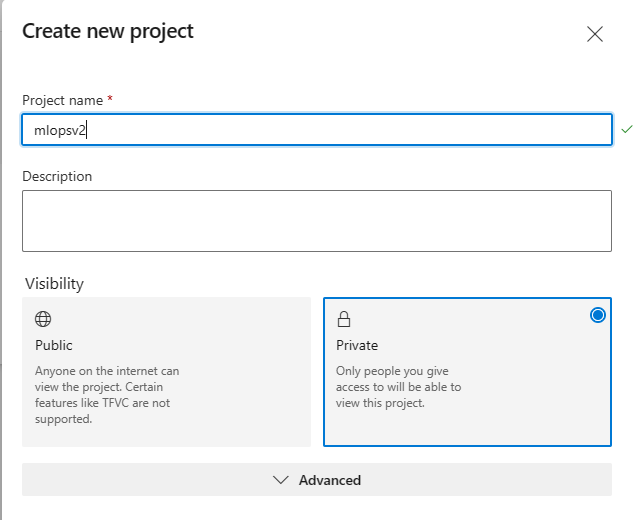
W projekcie w obszarze Ustawienia projektu (w lewym dolnym rogu strony projektu) wybierz pozycję Połączenia usługi.
Wybierz pozycję Utwórz połączenie z usługą.
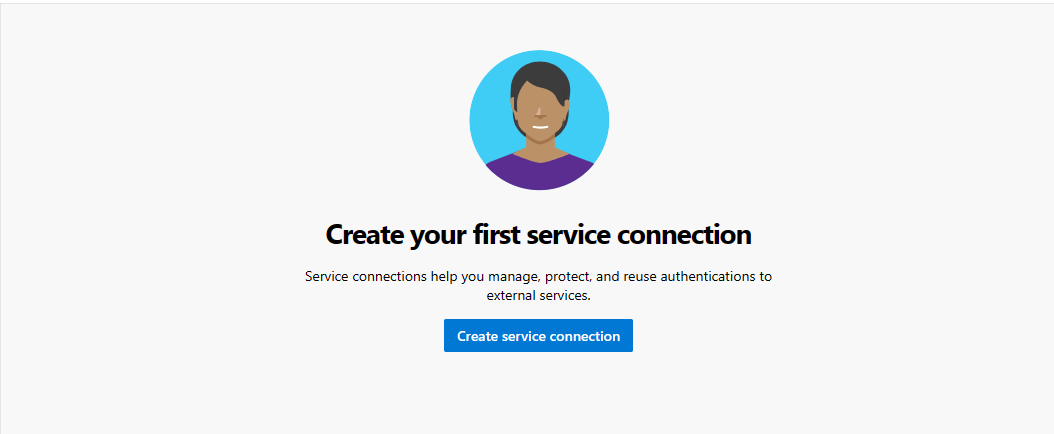
Wybierz pozycję Azure Resource Manager, wybierz pozycję Dalej, wybierz pozycję Jednostka usługi (ręcznie), wybierz pozycję Dalej i wybierz subskrypcję poziomu zakresu.
- Nazwa subskrypcji — użyj nazwy subskrypcji, w której jest przechowywana jednostka usługi.
- Identyfikator subskrypcji — użyj
subscriptionIddanych wejściowych w kroku 1 jako identyfikatora subskrypcji - Identyfikator jednostki usługi — użyj danych wyjściowych
appIdz kroku 1 jako identyfikatora jednostki usługi - Klucz jednostki usługi — użyj danych wyjściowych
passwordz kroku 1 jako klucza jednostki usługi - Identyfikator dzierżawy — użyj danych wyjściowych
tenantz kroku 1 jako identyfikatora dzierżawy
Nadaj połączeniu usługi nazwę Azure-ARM-Prod.
Wybierz pozycję Udziel uprawnień dostępu do wszystkich potoków, a następnie wybierz pozycję Weryfikuj i Zapisz.
Konfiguracja usługi Azure DevOps została zakończona pomyślnie.
Konfigurowanie repozytorium źródłowego za pomocą usługi Azure DevOps
Otwieranie projektu utworzonego w usłudze Azure DevOps
Otwórz sekcję Repozytoria i wybierz pozycję Importuj repozytorium
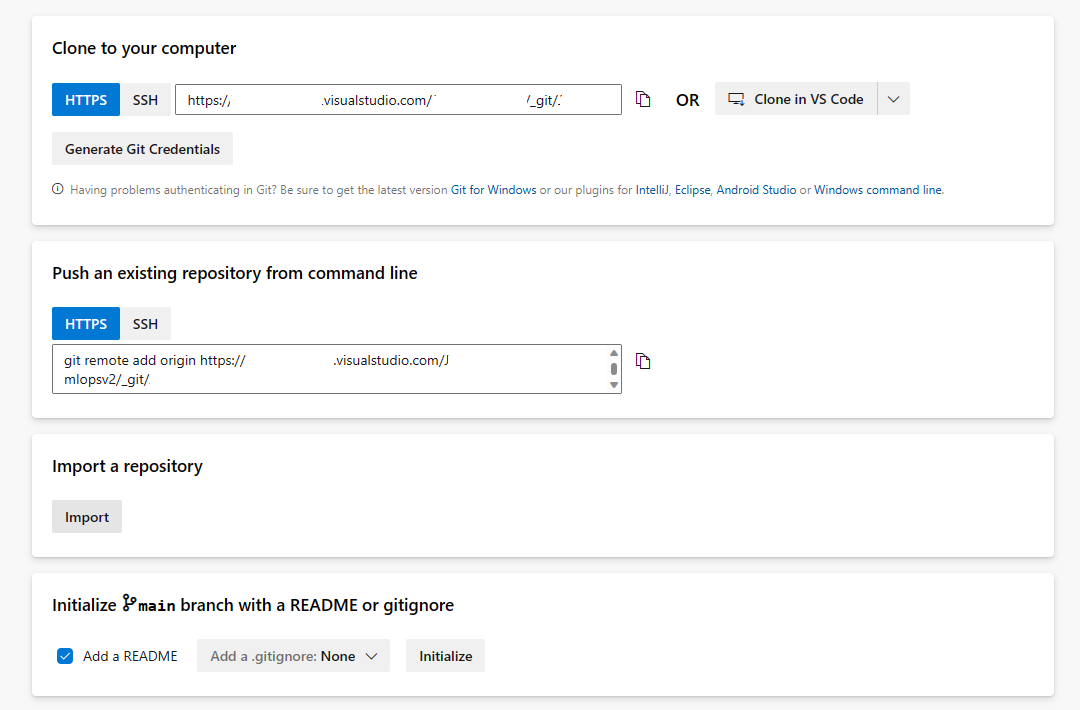
Wprowadź https://github.com/Azure/mlops-v2-ado-demo wartość w polu Klonuj adres URL. Wybierz pozycję Importuj w dolnej części strony
Otwórz ustawienia projektu w dolnej części okienka nawigacji po lewej stronie
W sekcji Repozytoria wybierz pozycję Repozytoria. Wybierz repozytorium utworzone w poprzednim kroku Wybierz kartę Zabezpieczenia
W sekcji Uprawnienia użytkownika wybierz użytkownika usługi kompilacji mlopsv2. Zmień uprawnienie Współtworzenie uprawnienia Zezwalaj i Utwórz gałąź na Zezwalaj.
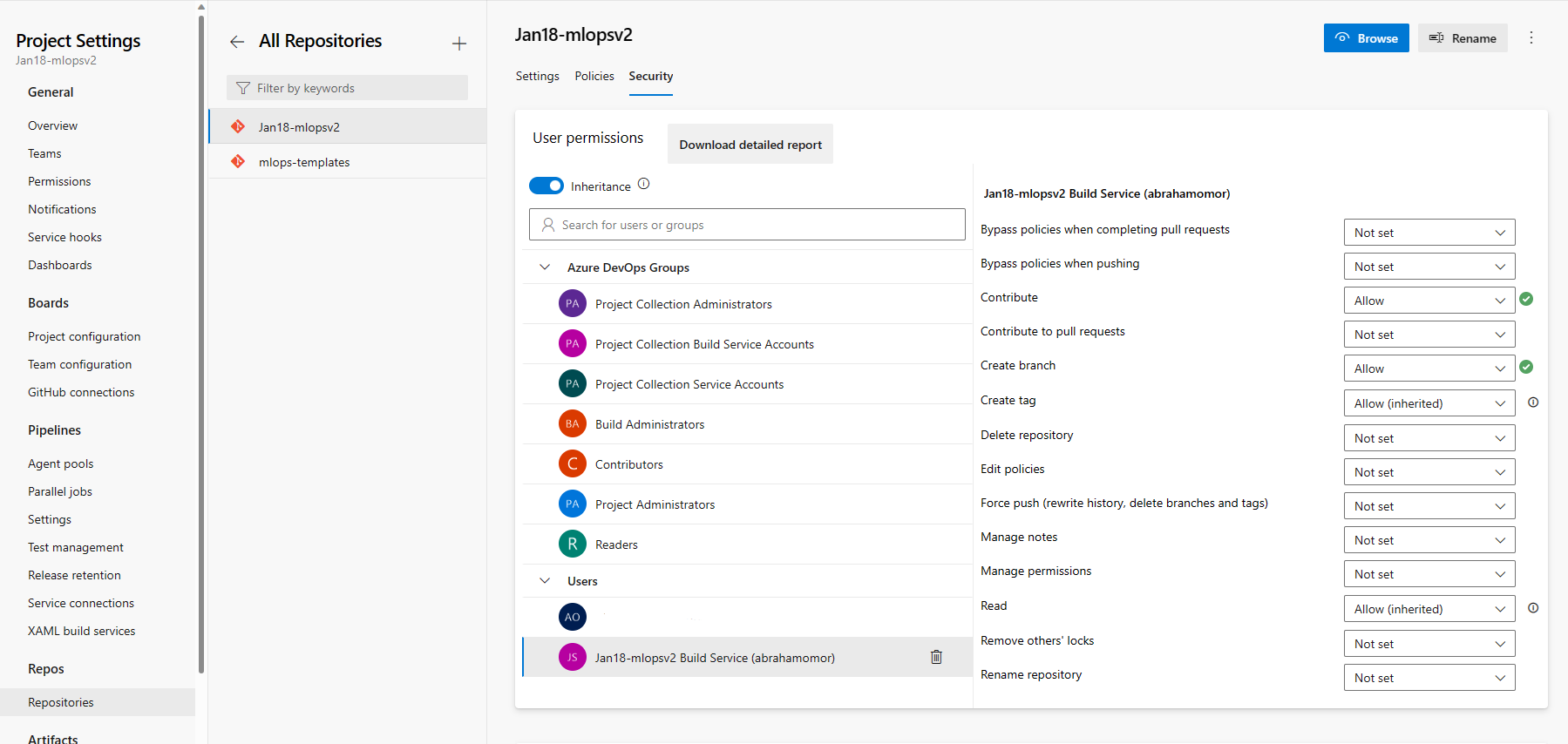
Otwórz sekcję Potoki w okienku nawigacji po lewej stronie i wybierz 3 pionowe kropki obok przycisku Utwórz potoki . Wybierz pozycję Zarządzaj zabezpieczeniami
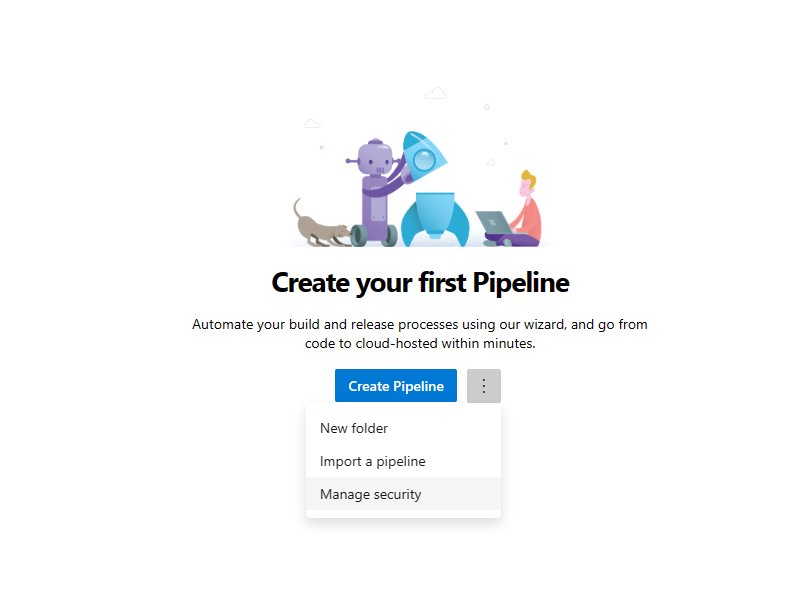
Wybierz konto usługi mlopsv2 Build Service dla projektu w sekcji Użytkownicy. Zmień uprawnienie Edytuj potok kompilacji na Zezwalaj
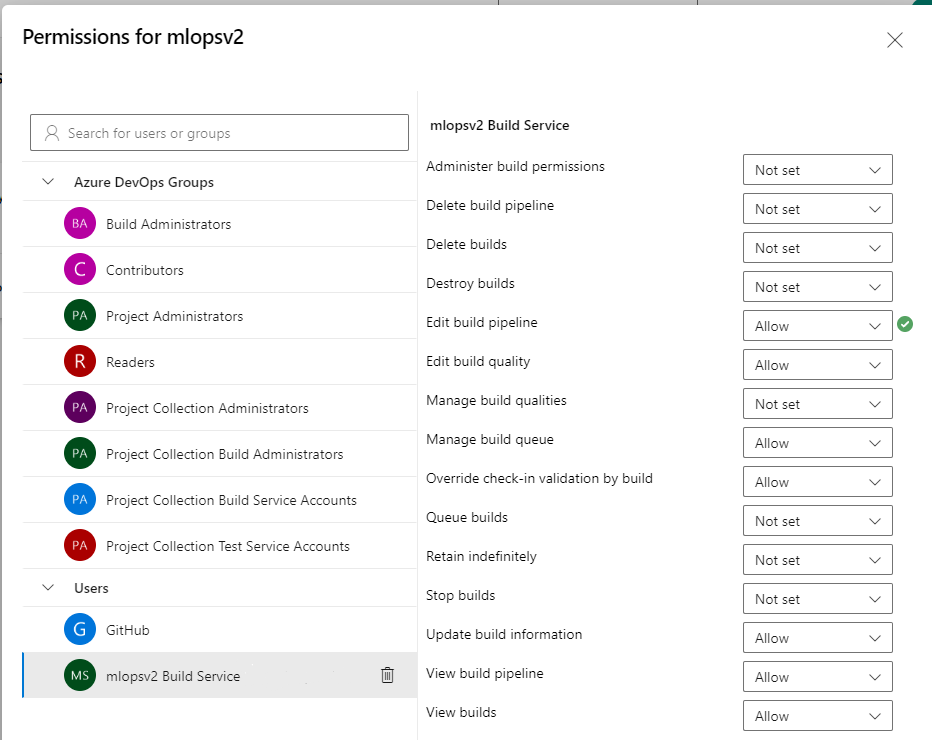
Uwaga
Spowoduje to zakończenie sekcji wymagań wstępnych i odpowiednie wdrożenie akceleratora rozwiązania.
Wdrażanie infrastruktury za pośrednictwem usługi Azure DevOps
Ten krok umożliwia wdrożenie potoku trenowania w obszarze roboczym usługi Azure Machine Learning utworzonym w poprzednich krokach.
Napiwek
Przed wyewidencjonowania repozytorium MLOps w wersji 2 i wdrożenia infrastruktury upewnij się, że rozumiesz wzorce architektury akceleratora rozwiązań. W przykładach użyjesz klasycznego typu projektu uczenia maszynowego.
Uruchamianie potoku infrastruktury platformy Azure
Przejdź do repozytorium ,
mlops-v2-ado-demoa następnie wybierz plik config-infra-prod.yml .Ważne
Upewnij się, że wybrano gałąź główną repozytorium.
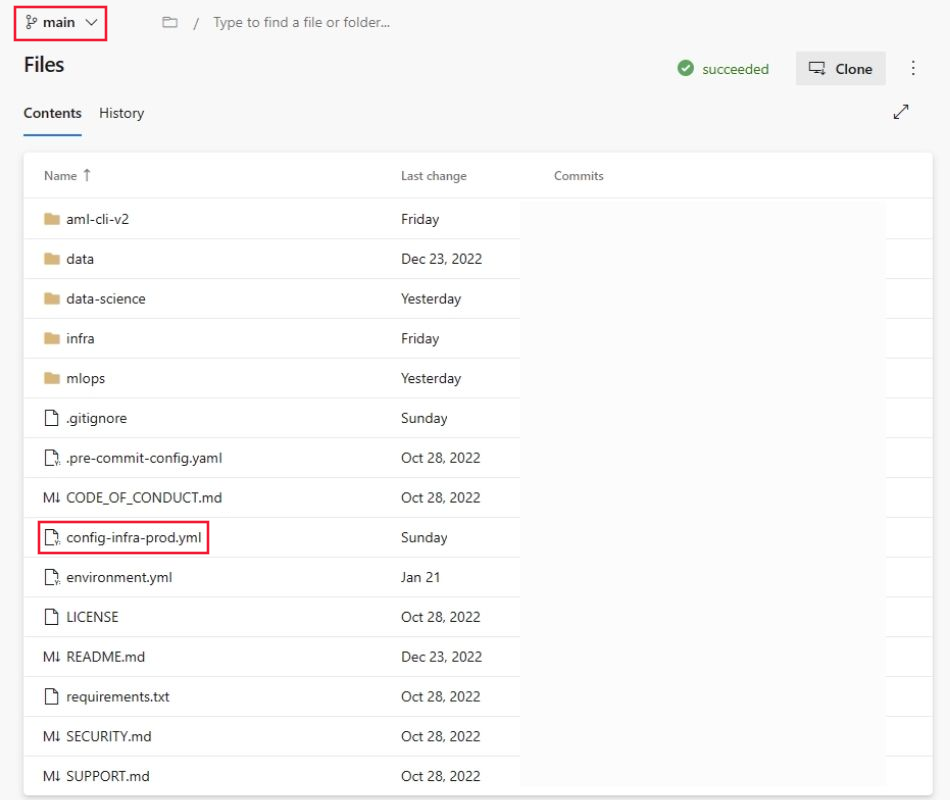
Ten plik konfiguracji używa przestrzeni nazw i wartości postfiksów nazw artefaktów w celu zapewnienia unikatowości. Zaktualizuj następującą sekcję w konfiguracji, aby polubić użytkownika.
namespace: [5 max random new letters] postfix: [4 max random new digits] location: eastusUwaga
Jeśli korzystasz z obciążenia uczenia głębokiego, takiego jak CV lub NLP, upewnij się, że zasoby obliczeniowe procesora GPU są dostępne w strefie wdrożenia.
Wybierz pozycję Zatwierdź i wypchnij kod, aby pobrać te wartości do potoku.
Przejdź do sekcji Potoki
Wybierz pozycję Utwórz potok.
Wybierz pozycję Azure Repos Git.
Wybierz repozytorium sklonowane w poprzedniej sekcji
mlops-v2-ado-demoWybieranie istniejącego pliku YAML usługi Azure Pipelines
mainWybierz gałąź i wybierz pozycjęmlops/devops-pipelines/cli-ado-deploy-infra.yml, a następnie wybierz pozycję Kontynuuj.Uruchamianie potoku; ukończenie tego zadania potrwa kilka minut. Potok powinien utworzyć następujące artefakty:
- Grupa zasobów dla obszaru roboczego, w tym konto magazynu, rejestr kontenerów, usługa Application Insights, usługa Keyvault i sam obszar roboczy usługi Azure Machine Learning.
- W obszarze roboczym jest również utworzony klaster obliczeniowy.
Teraz wdrażana jest infrastruktura projektu MLOps.
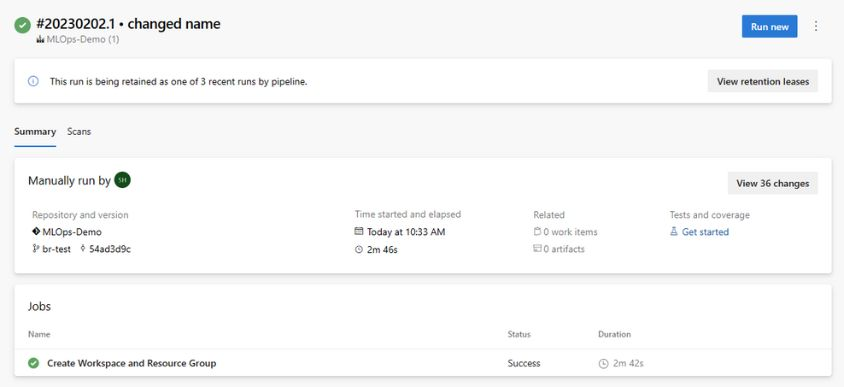
Uwaga
Nie można przenieść istniejącego repozytorium i użyć go ponownie do wymaganych ostrzeżeń dotyczących lokalizacji , mogą być ignorowane.
Przykładowy scenariusz trenowania i wdrażania
Akcelerator rozwiązań zawiera kod i dane dla kompleksowego potoku uczenia maszynowego, który uruchamia regresję liniową w celu przewidywania opłat za taksówkę w Nowym Jorku. Potok składa się ze składników, z których każda obsługuje różne funkcje, które można zarejestrować w obszarze roboczym, wersjonowanym i ponownie używanym przy użyciu różnych danych wejściowych i wyjściowych. Przykładowe potoki i przepływy pracy dla scenariuszy przetwarzanie obrazów i NLP będą miały różne kroki i kroki wdrażania.
Ten potok trenowania zawiera następujące kroki:
Przygotowywanie danych
- Ten składnik pobiera wiele zestawów danych taksówek (żółty i zielony) oraz scala/filtruje dane oraz przygotowuje zestawy danych train/val i evaluation.
- Dane wejściowe: dane lokalne w obszarze ./data/ (wiele plików .csv)
- Dane wyjściowe: pojedynczy przygotowany zestaw danych (.csv) i zestawy danych train/val/test.
Train Model (Trenuj model)
- Ten składnik trenuje regresję liniową z zestawem treningowym.
- Dane wejściowe: zestaw danych trenowania
- Dane wyjściowe: Wytrenowany model (format pickle)
Ocena modelu
- Ten składnik używa wytrenowanego modelu do przewidywania opłat za taksówkę w zestawie testowym.
- Dane wejściowe: model uczenia maszynowego i testowy zestaw danych
- Dane wyjściowe: Wydajność modelu i flaga wdrażania, czy wdrożyć.
- Ten składnik porównuje wydajność modelu ze wszystkimi poprzednimi wdrożonymi modelami w nowym zestawie danych testowych i decyduje, czy promować lub nie model do środowiska produkcyjnego. Promowanie modelu w środowisku produkcyjnym odbywa się przez zarejestrowanie modelu w obszarze roboczym AML.
Rejestrowanie modelu
- Ten składnik ocenia model na podstawie dokładności przewidywań w zestawie testowym.
- Dane wejściowe: wytrenowany model i flaga wdrażania.
- Dane wyjściowe: Zarejestrowany model w usłudze Azure Machine Learning.
Wdrażanie potoku trenowania modelu
Przejdź do potoków ADO
Wybierz pozycję Nowy potok.

Wybierz pozycję Azure Repos Git.
Wybierz repozytorium sklonowane w poprzedniej sekcji
mlopsv2Wybieranie istniejącego pliku YAML usługi Azure Pipelines
Wybierz
mainjako gałąź, a następnie wybierz pozycję/mlops/devops-pipelines/deploy-model-training-pipeline.yml, a następnie wybierz pozycję Kontynuuj.Zapisywanie i uruchamianie potoku
Uwaga
W tym momencie infrastruktura jest skonfigurowana i wdrożona jest pętla tworzenia prototypów architektury MLOps. Wszystko jest gotowe do przejścia do naszego wytrenowanego modelu do środowiska produkcyjnego.
Wdrażanie wytrenowanego modelu
Ten scenariusz obejmuje wstępnie utworzone przepływy pracy dla dwóch metod wdrażania wytrenowanego modelu, oceniania wsadowego lub wdrażania modelu w punkcie końcowym na potrzeby oceniania w czasie rzeczywistym. Możesz uruchomić oba te przepływy pracy, aby przetestować wydajność modelu w obszarze roboczym usługi Azure ML. W tym przykładzie będziemy używać oceniania w czasie rzeczywistym.
Wdrażanie punktu końcowego modelu uczenia maszynowego
Przejdź do potoków ADO
Wybierz pozycję Nowy potok.
Wybierz pozycję Azure Repos Git.
Wybierz repozytorium sklonowane w poprzedniej sekcji
mlopsv2Wybieranie istniejącego pliku YAML usługi Azure Pipelines
Wybierz
mainjako gałąź i wybierz pozycję Zarządzany punkt końcowy/mlops/devops-pipelines/deploy-online-endpoint-pipeline.ymlonline, a następnie wybierz pozycję Kontynuuj.Nazwy punktów końcowych online muszą być unikatowe, więc zmień
taxi-online-$(namespace)$(postfix)$(environment)na inną unikatową nazwę, a następnie wybierz pozycję Uruchom. Nie trzeba zmieniać wartości domyślnej, jeśli nie ulegnie awarii.
Ważne
Jeśli przebieg zakończy się niepowodzeniem z powodu istniejącej nazwy punktu końcowego online, utwórz ponownie potok zgodnie z opisem wcześniej i zmień wartość [nazwa punktu końcowego] na [nazwa punktu końcowego (liczba losowa)]
Po zakończeniu przebiegu zobaczysz dane wyjściowe podobne do poniższego obrazu:
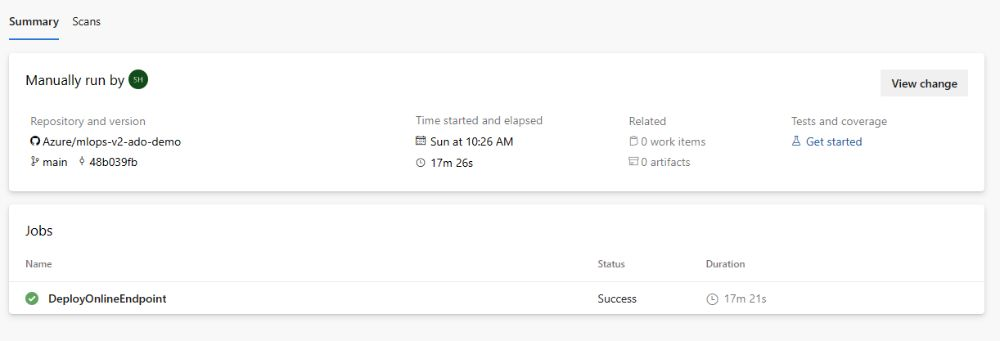
Aby przetestować to wdrożenie, przejdź do karty Punkty końcowe w obszarze roboczym usługi AzureML, wybierz punkt końcowy i kliknij kartę Testuj. Aby przetestować punkt końcowy, możesz użyć przykładowych danych wejściowych znajdujących się w sklonowanym repozytorium
/data/taxi-request.json.
Czyszczenie zasobów
- Jeśli nie zamierzasz nadal używać potoku, usuń projekt usługi Azure DevOps.
- W witrynie Azure Portal usuń grupę zasobów i wystąpienie usługi Azure Machine Learning.
Następne kroki
- Instalowanie i konfigurowanie zestawu Python SDK w wersji 2
- Instalowanie i konfigurowanie interfejsu wiersza polecenia języka Python w wersji 2
- Akcelerator rozwiązań usługi Azure MLOps (wersja 2) w usłudze GitHub
- Kurs szkoleniowy dotyczący metodyki MLOps za pomocą uczenia maszynowego
- Dowiedz się więcej o usłudze Azure Pipelines za pomocą usługi Azure Machine Learning
- Dowiedz się więcej o funkcji GitHub Actions za pomocą usługi Azure Machine Learning
- Wdrażanie metodyki MLOps na platformie Azure w mniej niż godzinę — wideo dotyczące akceleratora uczenia maszynowego społeczności w wersji 2