Używanie usługi Azure Machine Learning z pakietem open source Fairlearn w celu oceny sprawiedliwości modeli uczenia maszynowego (wersja zapoznawcza)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
W tym przewodniku z instrukcjami dowiesz się, jak używać pakietu Języka Python typu open source Fairlearn z usługą Azure Machine Learning do wykonywania następujących zadań:
- Oceń uczciwość prognoz modelu. Aby dowiedzieć się więcej na temat sprawiedliwości w uczeniu maszynowym, zobacz artykuł Sprawiedliwość w uczeniu maszynowym.
- Przekazywanie, wyświetlanie i pobieranie szczegółowych informacji dotyczących oceny sprawiedliwości do/z usługi Azure Machine Learning Studio.
- Zobacz pulpit nawigacyjny oceny sprawiedliwości w usłudze Azure Machine Learning Studio, aby wchodzić w interakcje ze szczegółowymi informacjami dotyczącymi sprawiedliwości modeli.
Uwaga
Ocena sprawiedliwości nie jest czysto technicznym ćwiczeniem. Ten pakiet może pomóc ocenić sprawiedliwość modelu uczenia maszynowego, ale tylko ty możesz konfigurować i podejmować decyzje dotyczące sposobu działania modelu. Chociaż ten pakiet pomaga zidentyfikować metryki ilościowe w celu oceny sprawiedliwości, deweloperzy modeli uczenia maszynowego muszą również przeprowadzić analizę jakościową, aby ocenić sprawiedliwość własnych modeli.
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Azure Machine Learning Fairness SDK
Zestaw SDK fairness usługi Azure Machine Learning integruje azureml-contrib-fairnesspakiet języka Python typu open source Fairlearn w usłudze Azure Machine Learning. Aby dowiedzieć się więcej na temat integracji rozwiązania Fairlearn w usłudze Azure Machine Learning, zapoznaj się z tymi przykładowymi notesami. Aby uzyskać więcej informacji na temat programu Fairlearn, zobacz przykładowy przewodnik i przykładowe notesy.
Użyj następujących poleceń, aby zainstalować azureml-contrib-fairness pakiety i fairlearn :
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
Nowsze wersje programu Fairlearn powinny również działać w poniższym przykładowym kodzie.
Przekazywanie szczegółowych informacji o sprawiedliwości dla pojedynczego modelu
W poniższym przykładzie pokazano, jak używać pakietu sprawiedliwości. Przekażemy wgląd w sprawiedliwość modelu do usługi Azure Machine Learning i zobaczymy pulpit nawigacyjny oceny sprawiedliwości w usłudze Azure Machine Learning Studio.
Trenowanie przykładowego modelu w notesie Jupyter Notebook.
W przypadku zestawu danych używamy dobrze znanego zestawu danych spisu dla dorosłych, który pobieramy z biblioteki OpenML. Udamy, że mamy problem z decyzją o pożyczki z etykietą wskazującą, czy osoba spłaciła poprzednią pożyczkę. Wytrenujemy model, aby przewidzieć, czy wcześniej niezasiądne osoby będą spłacać pożyczkę. Taki model może być używany w podejmowaniu decyzji dotyczących pożyczki.
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})Zaloguj się do usługi Azure Machine Learning i zarejestruj model.
Pulpit nawigacyjny sprawiedliwości może integrować się z zarejestrowanymi lub niezarejestrowanym modelem. Zarejestruj model w usłudze Azure Machine Learning, wykonując następujące czynności:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)Prekompiluj metryki sprawiedliwości.
Utwórz słownik pulpitu nawigacyjnego przy użyciu pakietu Fairlearn
metrics. Metoda_create_group_metric_setma argumenty podobne do konstruktora pulpitu nawigacyjnego, z tą różnicą, że poufne funkcje są przekazywane jako słownik (aby upewnić się, że nazwy są dostępne). Musimy również określić typ przewidywania (klasyfikacja binarna w tym przypadku) podczas wywoływania tej metody.# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Przekaż wstępnie skompilowane metryki sprawiedliwości.
Teraz zaimportuj
azureml.contrib.fairnesspakiet do wykonania przekazywania:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idUtwórz eksperyment, a następnie uruchom i przekaż do niego pulpit nawigacyjny:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Sprawdzanie pulpitu nawigacyjnego sprawiedliwości w usłudze Azure Machine Learning Studio
Jeśli wykonasz poprzednie kroki (przekazywanie wygenerowanych szczegółowych informacji o sprawiedliwości do usługi Azure Machine Learning), możesz wyświetlić pulpit nawigacyjny sprawiedliwości w usłudze Azure Machine Learning Studio. Ten pulpit nawigacyjny jest tym samym pulpitem nawigacyjnym wizualizacji podanym w usłudze Fairlearn, co umożliwia analizowanie różnic między podgrupami funkcji poufnych (np. mężczyzną a kobietą). Wykonaj jedną z tych ścieżek, aby uzyskać dostęp do pulpitu nawigacyjnego wizualizacji w usłudze Azure Machine Learning Studio:
- Okienko Zadania (wersja zapoznawcza)
- Wybierz pozycję Zadania w okienku po lewej stronie, aby wyświetlić listę eksperymentów uruchomionych w usłudze Azure Machine Learning.
- Wybierz konkretny eksperyment, aby wyświetlić wszystkie przebiegi w tym eksperymencie.
- Wybierz przebieg, a następnie kartę Sprawiedliwość na pulpicie nawigacyjnym wizualizacji wyjaśnienia.
- Po przejściu na kartę Sprawiedliwość kliknij identyfikator sprawiedliwości z menu po prawej stronie.
- Skonfiguruj pulpit nawigacyjny, wybierając poufny atrybut, metrykę wydajności i metrykę sprawiedliwości, aby wylądować na stronie oceny sprawiedliwości.
- Przełącz typ wykresu między sobą, aby zaobserwować zarówno szkody alokacji , jak i jakość szkód w usłudze .
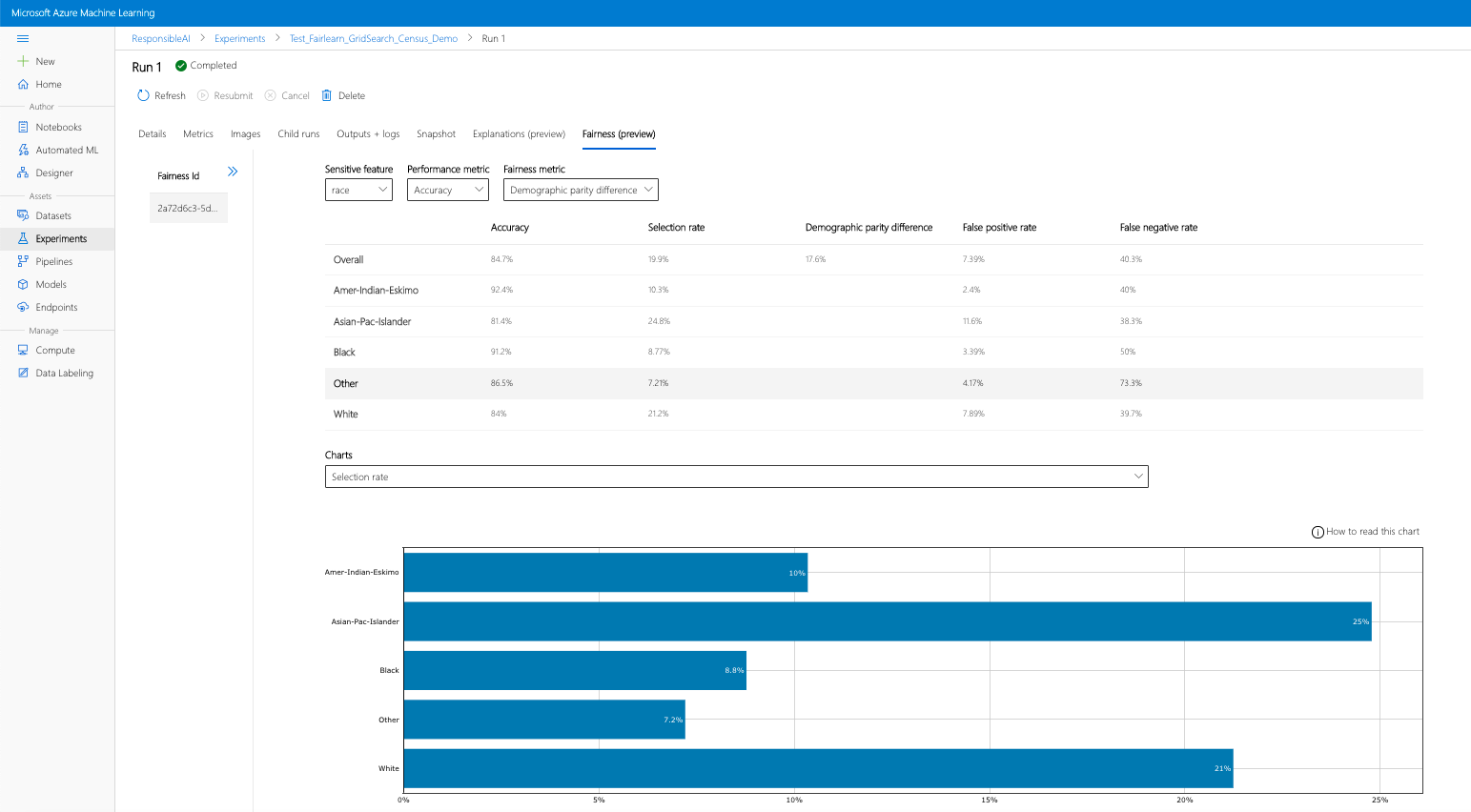
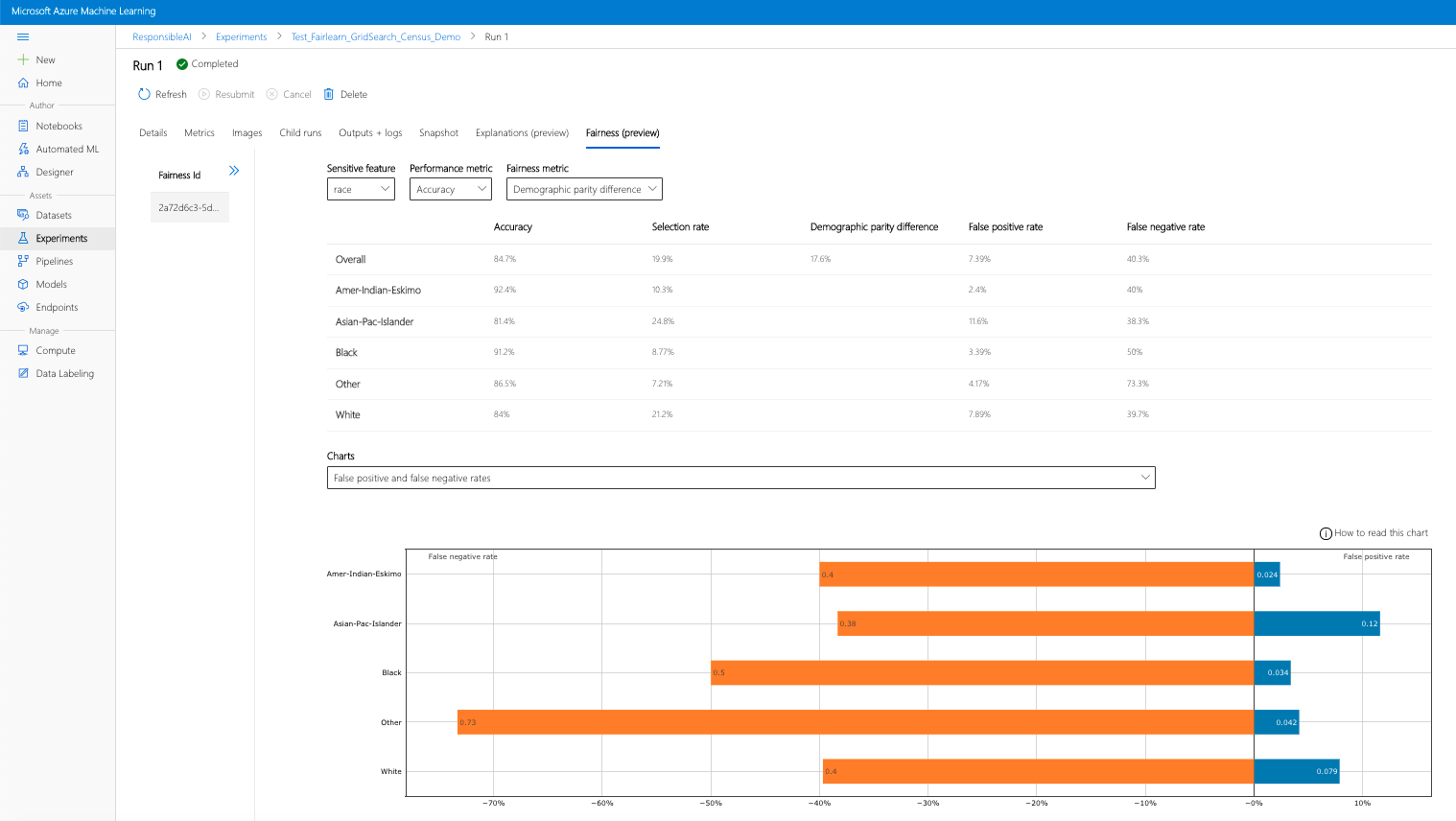
- Okienko Modele
- Jeśli zarejestrowano oryginalny model, wykonując poprzednie kroki, możesz wybrać pozycję Modele w okienku po lewej stronie, aby go wyświetlić.
- Wybierz model, a następnie kartę Sprawiedliwość , aby wyświetlić pulpit nawigacyjny wizualizacji objaśnień.
Aby dowiedzieć się więcej na temat pulpitu nawigacyjnego wizualizacji i jego zawartości, zapoznaj się z podręcznikiem użytkownika usługi Fairlearn.


Przekazywanie szczegółowych informacji o sprawiedliwości dla wielu modeli
Aby porównać wiele modeli i zobaczyć, jak różnią się oceny uczciwości, możesz przekazać więcej niż jeden model do pulpitu nawigacyjnego wizualizacji i porównać kompromisy w zakresie sprawiedliwości wydajności.
Trenowanie modeli:
Teraz utworzymy drugi klasyfikator na podstawie narzędzia do szacowania maszyny wektorów nośnych i przekażemy słownik pulpitu nawigacyjnego sprawiedliwości przy użyciu pakietu Fairlearn.
metricsZakładamy, że wcześniej wytrenowany model jest nadal dostępny.# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)Rejestrowanie modeli
Następnie zarejestruj oba modele w usłudze Azure Machine Learning. Dla wygody wyniki są przechowywane w słowniku, który mapuje
idzarejestrowany model (ciąg wname:versionformacie) na sam predyktor:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictorLokalne ładowanie pulpitu nawigacyjnego Fairness
Przed przekazaniem wglądu w sprawiedliwość w usłudze Azure Machine Learning możesz sprawdzić te przewidywania na lokalnym pulpicie nawigacyjnym fairness.
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)Prekompiluj metryki sprawiedliwości.
Utwórz słownik pulpitu nawigacyjnego przy użyciu pakietu Fairlearn
metrics.sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')Przekaż wstępnie skompilowane metryki sprawiedliwości.
Teraz zaimportuj
azureml.contrib.fairnesspakiet do wykonania przekazywania:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_idUtwórz eksperyment, a następnie uruchom i przekaż do niego pulpit nawigacyjny:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()Podobnie jak w poprzedniej sekcji, możesz postępować zgodnie z jedną z opisanych powyżej ścieżek (za pośrednictwem eksperymentów lub modeli) w usłudze Azure Machine Learning Studio, aby uzyskać dostęp do pulpitu nawigacyjnego wizualizacji i porównać dwa modele pod względem sprawiedliwości i wydajności.
Przekazywanie niezaciągniętych i skorygowanych szczegółowych informacji o sprawiedliwości
Algorytmy ograniczania ryzyka usługi Fairlearn można użyć, porównać wygenerowane przez nieuprawnione modele do oryginalnego, niezaciągnionego modelu i nawigować po kompromisach wydajności/sprawiedliwości między porównywanymi modelami.
Aby zobaczyć przykład, który demonstruje użycie algorytmu ograniczania ryzyka wyszukiwania siatki (który tworzy kolekcję zniwelowanych modeli z różnymi kompromisami w zakresie sprawiedliwości i wydajności), zapoznaj się z tym przykładowym notesem.
Przekazywanie szczegółowych informacji o sprawiedliwości wielu modeli w jednym przebiegu umożliwia porównanie modeli pod kątem sprawiedliwości i wydajności. Możesz kliknąć dowolny z modeli wyświetlanych na wykresie porównawczym modelu, aby wyświetlić szczegółowe szczegółowe informacje o sprawiedliwości określonego modelu.

Następne kroki
Dowiedz się więcej o sprawiedliwości modelu
Zapoznaj się z przykładowymi notesami fairness usługi Azure Machine Learning