Wymagania dotyczące routera wnioskowania i łączności w usłudze Azure Machine Learning
Router wnioskowania usługi Azure Machine Learning jest kluczowym składnikiem wnioskowania w czasie rzeczywistym z klastrem Kubernetes. W tym artykule możesz dowiedzieć się więcej o:
- Co to jest router wnioskowania usługi Azure Machine Learning
- Jak działa skalowanie automatyczne
- Jak skonfigurować i spełnić wydajność żądań wnioskowania (liczba żądań na sekundę i opóźnienie)
- Wymagania dotyczące łączności dla klastra wnioskowania usługi AKS
Co to jest router wnioskowania usługi Azure Machine Learning
Router wnioskowania usługi Azure Machine Learning to składnik frontonu (azureml-fe), który jest wdrażany w klastrze AKS lub Arc Kubernetes w czasie wdrażania rozszerzenia usługi Azure Machine Learning. Ma następujące funkcje:
- Kieruje przychodzące żądania wnioskowania z modułu równoważenia obciążenia klastra lub kontrolera ruchu przychodzącego do odpowiednich zasobników modelu.
- Równoważenie obciążenia wszystkich przychodzących żądań wnioskowania przy użyciu inteligentnego skoordynowanego routingu.
- Zarządza automatycznym skalowaniem zasobników modelu.
- Możliwość odpornego na uszkodzenia i trybu failover, zapewniając, że żądania wnioskowania są zawsze obsługiwane dla krytycznej aplikacji biznesowej.
Poniżej przedstawiono sposób przetwarzania żądań przez fronton:
- Klient wysyła żądanie do modułu równoważenia obciążenia.
- Moduł równoważenia obciążenia wysyła do jednego z frontonów.
- Fronton lokalizuje router usługi (wystąpienie frontonu działające jako koordynator) dla usługi.
- Router usługi wybiera zaplecze i zwraca go do frontonu.
- Fronton przekazuje żądanie do zaplecza.
- Po przetworzeniu żądania zaplecze wysyła odpowiedź do składnika frontonu.
- Fronton propaguje odpowiedź z powrotem do klienta.
- Fronton informuje router usługi, że zaplecze zakończyło przetwarzanie i jest dostępne dla innych żądań.
Na poniższym diagramie przedstawiono ten przepływ:
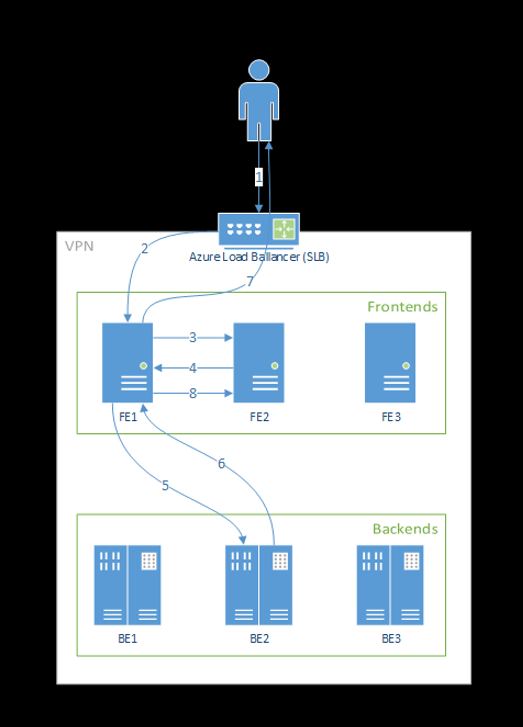
Jak widać na powyższym diagramie, domyślnie 3 azureml-fe wystąpienia są tworzone podczas wdrażania rozszerzenia usługi Azure Machine Learning, jedno wystąpienie działa jako rola koordynująca, a inne wystąpienia obsługują przychodzące żądania wnioskowania. Wystąpienie koordynujące zawiera wszystkie informacje o zasobnikach modelu i podejmuje decyzję o tym, który zasobnik modelu obsługuje przychodzące żądanie, podczas gdy wystąpienia obsługujące azureml-fe są odpowiedzialne za kierowanie żądania do wybranego zasobnika modelu i propagowanie odpowiedzi z powrotem do oryginalnego użytkownika.
Skalowanie automatyczne
Router wnioskowania usługi Azure Machine Learning obsługuje skalowanie automatyczne dla wszystkich wdrożeń modelu w klastrze Kubernetes. Ponieważ wszystkie żądania wnioskowania przechodzą przez nie, mają niezbędne dane do automatycznego skalowania wdrożonych modeli.
Ważne
Nie należy włączać narzędzia Kubernetes Horizontal Pod Autoscaler (HPA) dla wdrożeń modelu. W ten sposób dwa składniki automatycznego skalowania będą konkurować ze sobą. Usługa Azureml-fe jest przeznaczona do automatycznego skalowania modeli wdrożonych przez usługę Azure Machine Learning, gdzie hpA musi odgadnąć lub przybliżone wykorzystanie modelu z ogólnej metryki, takiej jak użycie procesora CPU lub niestandardowa konfiguracja metryki.
Usługa Azureml-fe nie skaluje liczby węzłów w klastrze usługi AKS, ponieważ może to prowadzić do nieoczekiwanego wzrostu kosztów. Zamiast tego skaluje liczbę replik modelu w granicach klastra fizycznego. Jeśli musisz skalować liczbę węzłów w klastrze, możesz ręcznie skalować klaster lub skonfigurować skalowanie automatyczne klastra usługi AKS.
Skalowanie automatyczne może być kontrolowane przez scale_settings właściwość we wdrożeniu YAML. W poniższym przykładzie pokazano, jak włączyć skalowanie automatyczne:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
Decyzja o skalowaniu w górę lub w dół opiera się na wartości utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Jeśli ta liczba przekroczy target_utilization_percentagewartość , zostanie utworzonych więcej replik. Jeśli jest niższa, repliki zostaną zmniejszone. Domyślnie użycie docelowe wynosi 70%.
Decyzje dotyczące dodawania replik są chętne i szybkie (około 1 sekundy). Decyzje o usunięciu replik są konserwatywne (około 1 minuta).
Jeśli na przykład chcesz wdrożyć usługę modelu i chcesz wiedzieć, że wiele wystąpień (zasobników/replik) należy skonfigurować dla żądań docelowych na sekundę (RPS) i docelowy czas odpowiedzi. Wymagane repliki można obliczyć przy użyciu następującego kodu:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Wydajność usługi azureml-fe
Może azureml-fe osiągnąć 5 K żądań na sekundę (QPS) z dobrym opóźnieniem, mając obciążenie nie przekraczające średnio 3 ms i 15 ms przy 99% percentylu.
Uwaga
Jeśli masz wymagania dotyczące usługi RPS wyższe niż 10 000, rozważ następujące opcje:
- Zwiększ liczbę żądań/limitów zasobów dla
azureml-fezasobników. Domyślnie ma ona 2 procesory wirtualne i limity zasobów pamięci 1,2G. - Zwiększ liczbę wystąpień dla elementu
azureml-fe. Domyślnie usługa Azure Machine Learning tworzy 3 lub 1azureml-fewystąpienia na klaster.- Ta liczba wystąpień zależy od konfiguracji
inferenceRouterHArozszerzenia usługi Azure Machine Learning. - Nie można utrwalić zwiększonej liczby wystąpień, ponieważ zostanie zastąpiona skonfigurowaną wartością po uaktualnieniu rozszerzenia.
- Ta liczba wystąpień zależy od konfiguracji
- Skontaktuj się z ekspertami firmy Microsoft, aby uzyskać pomoc.
Informacje o wymaganiach dotyczących łączności dla klastra wnioskowania usługi AKS
Klaster usługi AKS jest wdrażany przy użyciu jednego z następujących dwóch modeli sieciowych:
- Sieć Kubenet — zasoby sieciowe są zwykle tworzone i konfigurowane jako klaster usługi AKS jest wdrażany.
- Sieć usługi Azure Container Networking Interface (CNI) — klaster usługi AKS jest połączony z istniejącym zasobem i konfiguracjami sieci wirtualnej.
W przypadku sieci Kubenet sieć jest tworzona i prawidłowo skonfigurowana dla usługi Azure Machine Learning Service. W przypadku sieci CNI należy zrozumieć wymagania dotyczące łączności i zapewnić rozpoznawanie nazw DNS i łączność wychodzącą na potrzeby wnioskowania usługi AKS. Na przykład możesz wymagać dodatkowych kroków, jeśli używasz zapory do blokowania ruchu sieciowego.
Na poniższym diagramie przedstawiono wymagania dotyczące łączności dla wnioskowania usługi AKS. Czarne strzałki reprezentują rzeczywistą komunikację, a niebieskie strzałki reprezentują nazwy domen. Może być konieczne dodanie wpisów dla tych hostów do zapory lub do niestandardowego serwera DNS.
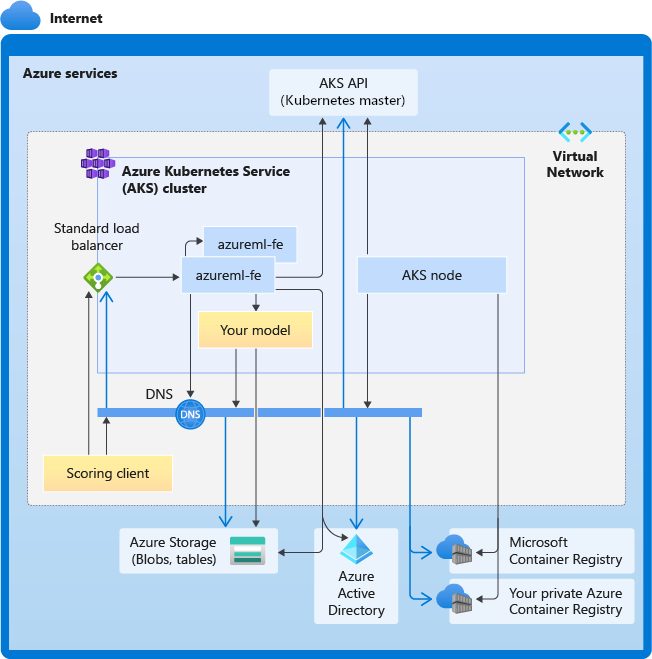
Aby uzyskać ogólne wymagania dotyczące łączności z usługą AKS, zobacz Kontrolowanie ruchu wychodzącego dla węzłów klastra w usłudze Azure Kubernetes Service.
Aby uzyskać dostęp do usług Azure Machine Learning za zaporą, zobacz Konfigurowanie ruchu sieciowego przychodzącego i wychodzącego.
Ogólne wymagania dotyczące rozpoznawania nazw DNS
Rozpoznawanie nazw DNS w istniejącej sieci wirtualnej jest pod Twoją kontrolą. Na przykład zapora lub niestandardowy serwer DNS. Następujące hosty muszą być dostępne:
| Nazwa hosta | Używana przez |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Serwer interfejsu API usługi AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Twoja usługa Azure Container Registry (ACR) |
<account>.blob.core.windows.net |
Konto usługi Azure Storage (magazyn obiektów blob) |
api.azureml.ms |
Uwierzytelnianie Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Punkt końcowy usługi Kusto na potrzeby przekazywania danych telemetrycznych |
Wymagania dotyczące łączności w kolejności chronologicznej: od utworzenia klastra do wdrożenia modelu
Zaraz po wdrożeniu usługi azureml-fe podejmie próbę uruchomienia i wymaga to wykonania następujących czynności:
- Rozpoznawanie nazw DNS dla serwera interfejsu API usługi AKS
- Wykonywanie zapytań względem serwera interfejsu API usługi AKS w celu odnalezienia innych wystąpień samego (jest to usługa z wieloma zasobnikami)
- Nawiązywanie połączenia z innymi wystąpieniami samego siebie
Po uruchomieniu polecenia azureml-fe wymagane jest następujące połączenie, aby działać prawidłowo:
- Nawiązywanie połączenia z usługą Azure Storage w celu pobrania konfiguracji dynamicznej
- Rozpoznawanie nazw DNS dla serwera uwierzytelniania Entra firmy Microsoft api.azureml.ms i komunikowanie się z nim, gdy wdrożona usługa używa uwierzytelniania Firmy Microsoft Entra.
- Wykonywanie zapytań względem serwera interfejsu API usługi AKS w celu odnajdywania wdrożonych modeli
- Komunikacja z wdrożonym modelem POD
W czasie wdrażania modelu w przypadku pomyślnego wdrożenia modelu węzeł usługi AKS powinien mieć następujące możliwości:
- Rozpoznawanie nazw DNS dla usługi ACR klienta
- Pobieranie obrazów z usługi ACR klienta
- Rozpoznawanie nazw DNS dla obiektów BLOB platformy Azure, w których jest przechowywany model
- Pobieranie modeli z usługi Azure BLOBs
Po wdrożeniu modelu i uruchomieniu usługi usługa azureml-fe automatycznie odnajdzie go przy użyciu interfejsu API usługi AKS i będzie gotowy do kierowania żądania do niego. Musi być w stanie komunikować się z modelami POD.
Uwaga
Jeśli wdrożony model wymaga łączności (np. wykonywania zapytań względem zewnętrznej bazy danych lub innej usługi REST, pobierania obiektu BLOB itp.), należy włączyć zarówno rozpoznawanie nazw DNS, jak i komunikację wychodzącą dla tych usług.