Wdrażanie modeli MLflow w punktach końcowych online
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Z tego artykułu dowiesz się, jak wdrożyć model MLflow w punkcie końcowym online na potrzeby wnioskowania w czasie rzeczywistym. Podczas wdrażania modelu MLflow w punkcie końcowym online nie trzeba określać skryptu oceniania ani środowiska — ta funkcja jest znana jako wdrożenie bez kodu.
W przypadku wdrożenia bez kodu usługa Azure Machine Learning:
- Dynamicznie instaluje pakiety języka Python udostępniane w
conda.yamlpliku. W związku z tym zależności są instalowane podczas wykonywania kontenera. - Udostępnia podstawowy obraz/wyselekcjonowane środowisko MLflow zawierające następujące elementy:
azureml-inference-server-httpmlflow-skinny- Skrypt oceniania na potrzeby wnioskowania.
Napiwek
Obszary robocze bez dostępu do sieci publicznej: przed wdrożeniem modeli MLflow w punktach końcowych online bez łączności wychodzącej należy spakować modele (wersja zapoznawcza). Korzystając z tworzenia pakietów modeli, można uniknąć potrzeby połączenia internetowego, którego usługa Azure Machine Learning w przeciwnym razie wymagałaby dynamicznego instalowania niezbędnych pakietów języka Python dla modeli MLflow.
Informacje o przykładzie
W przykładzie pokazano, jak wdrożyć model MLflow w punkcie końcowym online w celu wykonania przewidywań. W przykładzie użyto modelu MLflow opartego na zestawie danych Diabetes. Ten zestaw danych zawiera 10 zmiennych bazowych: wiek, płeć, wskaźnik masy ciała, średnie ciśnienie krwi i sześć pomiarów krwi uzyskanych od 442 pacjentów z cukrzycą. Zawiera również odpowiedź zainteresowania, ilościową miarę progresji choroby jeden rok po linii bazowej.
Model został wytrenowany przy użyciu scikit-learn regresji, a wszystkie wymagane wstępne przetwarzanie zostało spakowane jako potok, dzięki czemu ten model będzie gotowy potokiem, który przechodzi od nieprzetworzonych danych do przewidywań.
Informacje przedstawione w tym artykule są oparte na przykładach kodu zawartych w repozytorium azureml-examples . Aby uruchomić polecenia lokalnie bez konieczności kopiowania/wklejania kodu YAML i innych plików, sklonuj repozytorium, a następnie zmień katalogi na cli, jeśli używasz interfejsu wiersza polecenia platformy Azure. Jeśli używasz zestawu AZURE Machine Learning SDK dla języka Python, zmień katalogi na sdk/python/endpoints/online/mlflow.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Postępuj zgodnie z instrukcjami w notesie Jupyter Notebook
Możesz wykonać kroki dotyczące korzystania z zestawu SDK języka Python usługi Azure Machine Learning, otwierając notes Deploy MLflow model to online endpoints (Wdrażanie modelu MLflow do punktów końcowych online) w sklonowanym repozytorium.
Wymagania wstępne
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Kontrola dostępu na podstawie ról platformy Azure (Azure RBAC): jest używana do udzielania dostępu do operacji w usłudze Azure Machine Learning. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę właściciela lub współautora dla obszaru roboczego usługi Azure Machine Learning lub rolę niestandardową zezwalającą na
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*korzystanie z usługi . Aby uzyskać więcej informacji na temat ról, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Learning.Musisz mieć model MLflow zarejestrowany w obszarze roboczym. W tym artykule zarejestrowano model przeszkolony dla zestawu danych Diabetes w obszarze roboczym.
Ponadto należy wykonać następujące czynności:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
- Zainstaluj interfejs wiersza polecenia platformy Azure i
mlrozszerzenie do interfejsu wiersza polecenia platformy Azure. Aby uzyskać więcej informacji na temat instalowania interfejsu wiersza polecenia, zobacz Instalowanie i konfigurowanie interfejsu wiersza polecenia (wersja 2).
Nawiązywanie połączenia z obszarem roboczym
Najpierw połącz się z obszarem roboczym usługi Azure Machine Learning, w którym będziesz pracować.
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Rejestrowanie modelu
Zarejestrowane modele można wdrażać tylko w punktach końcowych online. W takim przypadku masz już lokalną kopię modelu w repozytorium, więc wystarczy opublikować model w rejestrze w obszarze roboczym. Ten krok można pominąć, jeśli model, który próbujesz wdrożyć, jest już zarejestrowany.
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
MODEL_NAME='sklearn-diabetes'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "endpoints/online/ncd/sklearn-diabetes/model"

Co zrobić, jeśli model został zarejestrowany wewnątrz przebiegu?
Jeśli model został zarejestrowany wewnątrz przebiegu, możesz zarejestrować go bezpośrednio.
Aby zarejestrować model, musisz znać lokalizację, w której jest przechowywany. Jeśli używasz funkcji platformy autolog MLflow, ścieżka do modelu zależy od typu i struktury modelu. Należy sprawdzić dane wyjściowe zadań, aby zidentyfikować nazwę folderu modelu. Ten folder zawiera plik o nazwie MLModel.
Jeśli używasz metody do ręcznego log_model rejestrowania modeli, przekaż ścieżkę do modelu jako argument do metody . Jeśli na przykład rejestrujesz model przy użyciu mlflow.sklearn.log_model(my_model, "classifier")metody , ścieżka, w której jest przechowywany model, nosi nazwę classifier.
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Użyj interfejsu wiersza polecenia usługi Azure Machine Learning w wersji 2, aby utworzyć model na podstawie danych wyjściowych zadania trenowania. W poniższym przykładzie model o nazwie $MODEL_NAME jest zarejestrowany przy użyciu artefaktów zadania o identyfikatorze $RUN_ID. Ścieżka, w której jest przechowywany model, to $MODEL_PATH.
az ml model create --name $MODEL_NAME --path azureml://jobs/$RUN_ID/outputs/artifacts/$MODEL_PATH
Uwaga
Ścieżka $MODEL_PATH to lokalizacja, w której model został zapisany w przebiegu.

Wdrażanie modelu MLflow w punkcie końcowym online
Skonfiguruj punkt końcowy, w którym zostanie wdrożony model. W poniższym przykładzie skonfigurowana jest nazwa i tryb uwierzytelniania punktu końcowego:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Ustaw nazwę punktu końcowego, uruchamiając następujące polecenie (zastąp
YOUR_ENDPOINT_NAMEelement unikatową nazwą):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Konfigurowanie punktu końcowego:
create-endpoint.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json name: my-endpoint auth_mode: keyUtwórz punkt końcowy:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/ncd/create-endpoint.yamlSkonfiguruj wdrożenie. Wdrożenie to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie.
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
sklearn-deployment.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-deployment endpoint_name: my-endpoint model: name: mir-sample-sklearn-ncd-model version: 2 path: sklearn-diabetes/model type: mlflow_model instance_type: Standard_DS3_v2 instance_count: 1Uwaga
Autogeneracja elementów
scoring_scriptienvironmentjest obsługiwana tylko w przypadkupyfuncodmiany modelu. Aby użyć innego wariantu modelu, zobacz Dostosowywanie wdrożeń modelu MLflow.Utwórz wdrożenie:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az ml online-deployment create --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficJeśli punkt końcowy nie ma łączności wychodzącej, użyj pakietu modelu (wersja zapoznawcza), dołączając flagę
--with-package:az ml online-deployment create --with-package --name sklearn-deployment --endpoint $ENDPOINT_NAME -f endpoints/online/ncd/sklearn-deployment.yaml --all-trafficPrzypisz cały ruch do wdrożenia. Do tej pory punkt końcowy ma jedno wdrożenie, ale żaden z jego ruchu nie jest przypisany do niego.
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Ten krok nie jest wymagany w interfejsie wiersza polecenia platformy Azure, ponieważ użyto flagi
--all-trafficpodczas tworzenia. Jeśli musisz zmienić ruch, możesz użyć poleceniaaz ml online-endpoint update --traffic. Aby uzyskać więcej informacji na temat aktualizowania ruchu, zobacz Postępowe aktualizowanie ruchu.Zaktualizuj konfigurację punktu końcowego:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Ten krok nie jest wymagany w interfejsie wiersza polecenia platformy Azure, ponieważ użyto flagi
--all-trafficpodczas tworzenia. Jeśli musisz zmienić ruch, możesz użyć poleceniaaz ml online-endpoint update --traffic. Aby uzyskać więcej informacji na temat aktualizowania ruchu, zobacz Postępowe aktualizowanie ruchu.


Wywoływanie punktu końcowego
Gdy wdrożenie będzie gotowe, możesz użyć go do obsługi żądania. Jednym ze sposobów testowania wdrożenia jest użycie wbudowanej funkcji wywołania w używanym kliencie wdrażania. Poniższy kod JSON to przykładowe żądanie wdrożenia.
sample-request-sklearn.json
{"input_data": {
"columns": [
"age",
"sex",
"bmi",
"bp",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6"
],
"data": [
[ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ],
[ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0]
],
"index": [0,1]
}}
Uwaga
input_data Jest używany w tym przykładzie, a nie inputs jest używany w usłudze MLflow. Dzieje się tak, ponieważ usługa Azure Machine Learning wymaga innego formatu danych wejściowych, aby umożliwić automatyczne generowanie kontraktów struktury Swagger dla punktów końcowych. Aby uzyskać więcej informacji na temat oczekiwanych formatów wejściowych, zobacz Różnice między modelami wdrożonym w usłudze Azure Machine Learning i wbudowanym serwerze MLflow.
Prześlij żądanie do punktu końcowego w następujący sposób:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.json
Odpowiedź będzie podobna do następującego tekstu:
[
11633.100167144921,
8522.117402884991
]
Ważne
W przypadku wdrożenia bez kodu platformy MLflow testowanie za pośrednictwem lokalnych punktów końcowych nie jest obecnie obsługiwane.
Dostosowywanie wdrożeń modelu MLflow
Nie musisz określać skryptu oceniania w definicji wdrożenia modelu MLflow do punktu końcowego online. Możesz jednak zdecydować się na to i dostosować sposób wykonywania wnioskowania.
Zazwyczaj należy dostosować wdrożenie modelu MLflow, gdy:
- Model nie ma na
PyFuncnim smaku. - Musisz dostosować sposób uruchamiania modelu, na przykład, aby użyć konkretnej odmiany do załadowania modelu przy użyciu polecenia
mlflow.<flavor>.load_model(). - Należy wykonać przetwarzanie wstępne/końcowe w procedurze oceniania, gdy nie jest on wykonywany przez sam model.
- Dane wyjściowe modelu nie mogą być ładnie reprezentowane w danych tabelarycznych. Na przykład jest to tensor reprezentujący obraz.
Ważne
Jeśli zdecydujesz się określić skrypt oceniania dla wdrożenia modelu MLflow, musisz również określić środowisko, w którym zostanie uruchomione wdrożenie.
Kroki
Aby wdrożyć model MLflow za pomocą niestandardowego skryptu oceniania:
Zidentyfikuj folder, w którym znajduje się model MLflow.
a. Przejdź do usługi Azure Machine Learning Studio.
b. Przejdź do sekcji Modele .
c. Wybierz model, który próbujesz wdrożyć, i przejdź do karty Artefakty .
d. Zanotuj wyświetlany folder. Ten folder został określony podczas rejestrowania modelu.
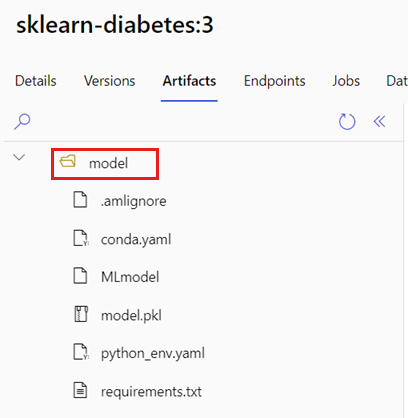
Utwórz skrypt oceniania. Zwróć uwagę, że nazwa
modelfolderu, który został wcześniej zidentyfikowany, jest uwzględniona winit()funkcji.Napiwek
Poniższy skrypt oceniania jest dostarczany jako przykład sposobu wnioskowania z modelem MLflow. Ten skrypt można dostosować do swoich potrzeb lub zmienić dowolny z jego części, aby odzwierciedlał twój scenariusz.
score.py
import logging import os import json import mlflow from io import StringIO from mlflow.pyfunc.scoring_server import infer_and_parse_json_input, predictions_to_json def init(): global model global input_schema # "model" is the path of the mlflow artifacts when the model was registered. For automl # models, this is generally "mlflow-model". model_path = os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model") model = mlflow.pyfunc.load_model(model_path) input_schema = model.metadata.get_input_schema() def run(raw_data): json_data = json.loads(raw_data) if "input_data" not in json_data.keys(): raise Exception("Request must contain a top level key named 'input_data'") serving_input = json.dumps(json_data["input_data"]) data = infer_and_parse_json_input(serving_input, input_schema) predictions = model.predict(data) result = StringIO() predictions_to_json(predictions, result) return result.getvalue()Ostrzeżenie
Porady dotyczące platformy MLflow 2.0: Udostępniony skrypt oceniania będzie działał zarówno z MLflow 1.X, jak i MLflow 2.X. Należy jednak pamiętać, że oczekiwane formaty danych wejściowych/wyjściowych w tych wersjach mogą się różnić. Sprawdź definicję środowiska używaną w celu upewnienia się, że używasz oczekiwanej wersji platformy MLflow. Zwróć uwagę, że platforma MLflow 2.0 jest obsługiwana tylko w języku Python 3.8 lub nowszym.
Utwórz środowisko, w którym można wykonać skrypt oceniania. Ponieważ model jest modelem MLflow, wymagania conda są również określone w pakiecie modelu. Aby uzyskać więcej informacji na temat plików zawartych w modelu MLflow, zobacz Format MLmodel. Następnie skompilujesz środowisko przy użyciu zależności conda z pliku. Należy jednak uwzględnić również pakiet
azureml-inference-server-http, który jest wymagany do wdrożeń online w usłudze Azure Machine Learning.Plik definicji conda jest następujący:
conda.yml
channels: - conda-forge dependencies: - python=3.9 - pip - pip: - mlflow - scikit-learn==1.2.2 - cloudpickle==2.2.1 - psutil==5.9.4 - pandas==2.0.0 - azureml-inference-server-http name: mlflow-envUwaga
Pakiet
azureml-inference-server-httpzostał dodany do oryginalnego pliku zależności conda.Użyjesz tego pliku zależności conda, aby utworzyć środowisko:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Środowisko zostanie utworzone w tekście w konfiguracji wdrożenia.
Utwórz wdrożenie:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
Utwórz plik konfiguracji wdrożenia deployment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json name: sklearn-diabetes-custom endpoint_name: my-endpoint model: azureml:sklearn-diabetes@latest environment: image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04 conda_file: sklearn-diabetes/environment/conda.yml code_configuration: code: sklearn-diabetes/src scoring_script: score.py instance_type: Standard_F2s_v2 instance_count: 1Utwórz wdrożenie:
az ml online-deployment create -f deployment.ymlPo zakończeniu wdrażania można przystąpić do obsługi żądań. Jednym ze sposobów testowania wdrożenia jest użycie przykładowego pliku żądania wraz z
invokemetodą .sample-request-sklearn.json
{"input_data": { "columns": [ "age", "sex", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6" ], "data": [ [ 1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0 ], [ 10.0,2.0,9.0,8.0,7.0,6.0,5.0,4.0,3.0,2.0] ], "index": [0,1] }}Prześlij żądanie do punktu końcowego w następujący sposób:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/ncd/sample-request-sklearn.jsonOdpowiedź będzie podobna do następującego tekstu:
{ "predictions": [ 11633.100167144921, 8522.117402884991 ] }Ostrzeżenie
Porady dotyczące platformy MLflow 2.0: W systemie MLflow 1.X
predictionsbrakuje klucza.



Czyszczenie zasobów
Po zakończeniu korzystania z punktu końcowego usuń skojarzone z nim zasoby:
- Interfejs wiersza polecenia platformy Azure
- Python (Zestaw SDK usługi Azure Machine Learning)
- Python (zestaw MLflow SDK)
- Studio
az ml online-endpoint delete --name $ENDPOINT_NAME --yes