Uzdatnianie danych za pomocą pul platformy Apache Spark (przestarzałe)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Ostrzeżenie
Integracja usługi Azure Synapse Analytics z usługą Azure Machine Learning dostępna w zestawie PYTHON SDK w wersji 1 jest przestarzała. Użytkownicy nadal mogą używać obszaru roboczego usługi Synapse zarejestrowanego w usłudze Azure Machine Learning jako połączonej usługi. Nowy obszar roboczy usługi Synapse nie może być już jednak zarejestrowany w usłudze Azure Machine Learning jako połączona usługa. Zalecamy korzystanie z bezserwerowych pul platformy Spark i dołączonych pul platformy Synapse Spark dostępnych w interfejsie wiersza polecenia w wersji 2 i zestawu Python SDK w wersji 2. Aby uzyskać więcej informacji, zobacz https://aka.ms/aml-spark.
Z tego artykułu dowiesz się, jak interaktywnie wykonywać zadania uzdatniania danych w ramach dedykowanej sesji usługi Synapse obsługiwanej przez usługę Azure Synapse Analytics w notesie Jupyter. Te zadania opierają się na zestawie SDK języka Python usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat potoków usługi Azure Machine Learning, odwiedź stronę How to use Apache Spark (powered by Azure Synapse Analytics) in your machine learning pipeline (preview) (Jak używać platformy Apache Spark (obsługiwanej przez usługę Azure Synapse Analytics) w potoku uczenia maszynowego (wersja zapoznawcza). Aby uzyskać więcej informacji na temat korzystania z usługi Azure Synapse Analytics z obszarem roboczym usługi Synapse, odwiedź serię rozpoczynania pracy z usługą Azure Synapse Analytics.
Integracja usług Azure Machine Learning i Azure Synapse Analytics
Dzięki integracji usługi Azure Synapse Analytics z usługą Azure Machine Learning (wersja zapoznawcza) możesz dołączyć pulę Platformy Apache Spark wspieraną przez usługę Azure Synapse w celu interaktywnej eksploracji i przygotowywania danych. Dzięki tej integracji możesz mieć dedykowany zasób obliczeniowy na potrzeby uzdatniania danych na dużą skalę, a wszystko to w tym samym notesie języka Python używanym do trenowania modeli uczenia maszynowego.
Wymagania wstępne
Skonfiguruj środowisko programistyczne, aby zainstalować zestaw SDK usługi Azure Machine Learning lub użyć wystąpienia obliczeniowego usługi Azure Machine Learning z już zainstalowanym zestawem SDK
Instalowanie zestawu SDK języka Python usługi Azure Machine Learning
Tworzenie obszaru roboczego usługi Synapse w witrynie Azure Portal
Zainstaluj pakiet (wersja zapoznawcza) przy
azureml-synapseużyciu następującego kodu:pip install azureml-synapseŁączenie obszaru roboczego usługi Azure Machine Learning i obszaru roboczego usługi Azure Synapse Analytics przy użyciu zestawu SDK języka Python usługi Azure Machine Learning lub usługi Azure Machine Learning Studio
Dołączanie puli platformy Spark usługi Synapse jako celu obliczeniowego
Uruchamianie puli platformy Spark usługi Synapse na potrzeby zadań uzdatniania danych
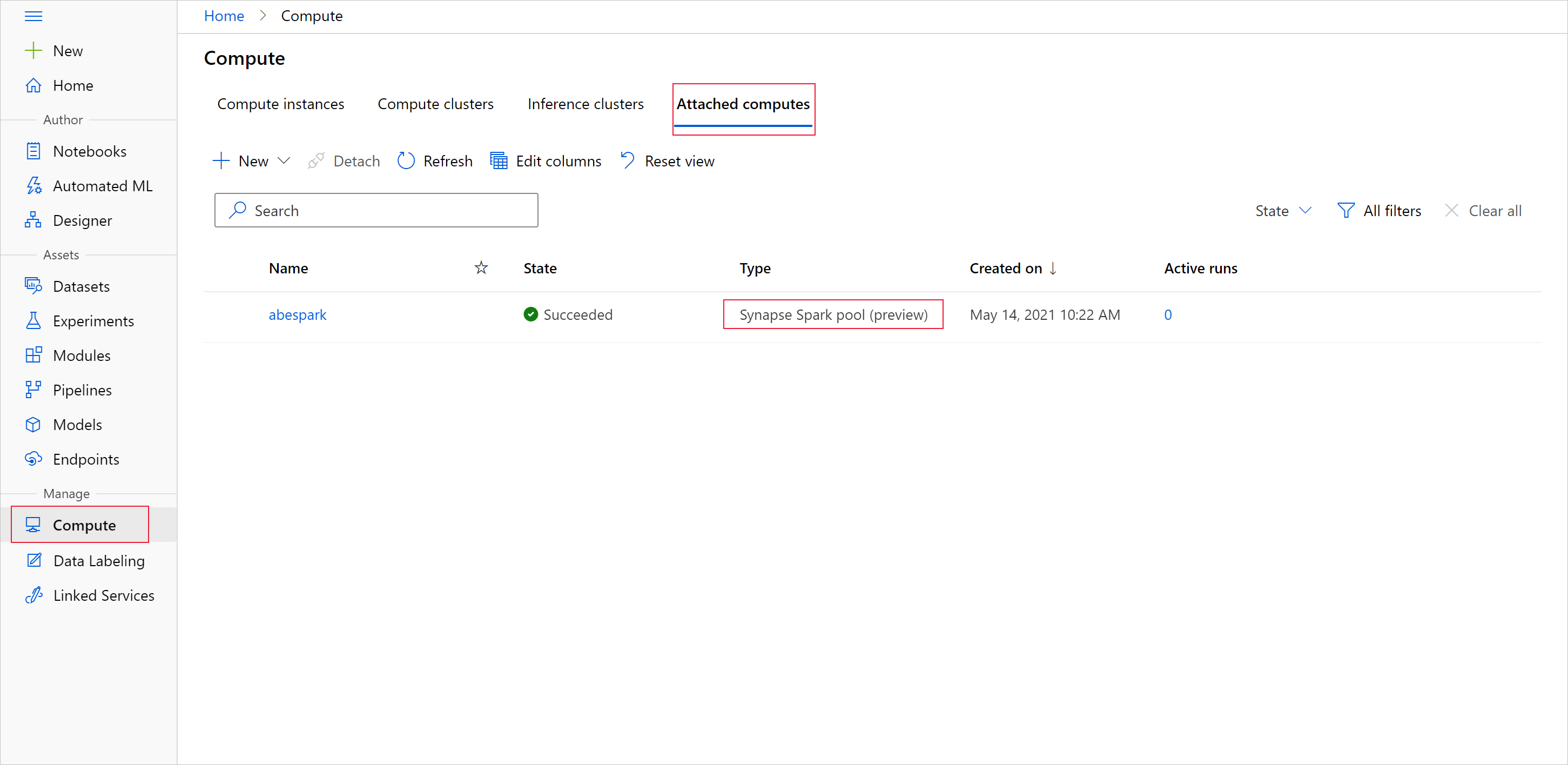
Aby rozpocząć przygotowywanie danych z pulą platformy Apache Spark, określ dołączoną nazwę obliczeniową spark Synapse. Tę nazwę można znaleźć w usłudze Azure Machine Learning Studio na karcie Dołączone obliczenia.
Ważne
Aby kontynuować korzystanie z puli platformy Apache Spark, musisz wskazać, który zasób obliczeniowy ma być używany w ramach zadań uzdatniania danych. Użyj polecenia %synapse dla pojedynczych wierszy kodu i %%synapse dla wielu wierszy:
%synapse start -c SynapseSparkPoolAlias
Po rozpoczęciu sesji można sprawdzić metadane sesji:
%synapse meta
Środowisko usługi Azure Machine Learning można określić do użycia podczas sesji platformy Apache Spark. Zostaną zastosowane tylko zależności Conda określone w środowisku. Obrazy platformy Docker nie są obsługiwane.
Ostrzeżenie
Zależności języka Python określone w zależnościach środowiska Conda nie są obsługiwane w pulach platformy Apache Spark. Obecnie obsługiwane są tylko stałe wersje języka Python Dołączanie sys.version_info do skryptu w celu sprawdzenia wersji języka Python
Ten kod tworzy zmiennąmyenv środowiskową, aby zainstalować azureml-core wersję 1.20.0 i numpy wersję 1.17.0 przed rozpoczęciem sesji. Następnie możesz uwzględnić to środowisko w instrukcji sesji platformy start Apache Spark.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Aby rozpocząć przygotowywanie danych z pulą Platformy Apache Spark w środowisku niestandardowym, określ zarówno nazwę puli platformy Apache Spark, jak i środowisko do użycia podczas sesji platformy Apache Spark. Możesz podać identyfikator subskrypcji, grupę zasobów obszaru roboczego uczenia maszynowego oraz nazwę obszaru roboczego uczenia maszynowego.
Ważne
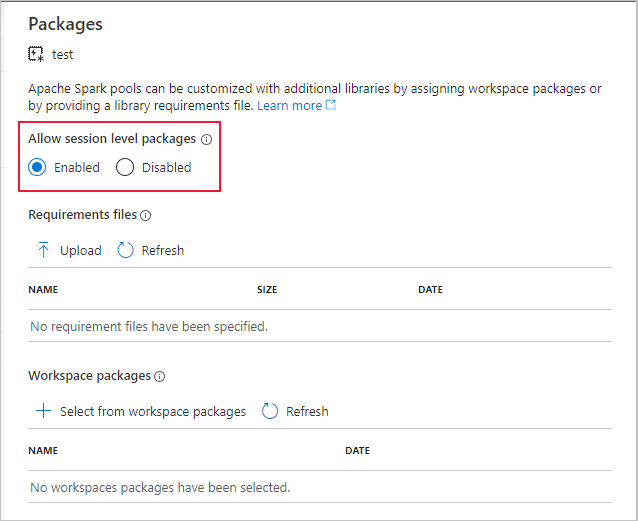
Pamiętaj, aby włączyć opcję Zezwalaj na pakiety na poziomie sesji w połączonym obszarze roboczym usługi Synapse.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Ładowanie danych z magazynu
Po rozpoczęciu sesji platformy Apache Spark przeczytaj dane, które chcesz przygotować. Ładowanie danych jest obsługiwane w przypadku usług Azure Blob Storage i Azure Data Lake Storage Generations 1 i 2.
Dostępne są dwie opcje ładowania danych z tych usług magazynu:
Bezpośrednie ładowanie danych z magazynu przy użyciu ścieżki rozproszonego systemu plików Hadoop (HDFS)
Odczytywanie danych z istniejącego zestawu danych usługi Azure Machine Learning
Aby uzyskać dostęp do tych usług magazynu, potrzebne są uprawnienia Czytelnik danych obiektu blob usługi Storage. Aby zapisywać dane z powrotem do tych usług magazynu, musisz mieć uprawnienia Współautor danych obiektu blob usługi Storage. Dowiedz się więcej o uprawnieniach i rolach magazynu.
Ładowanie danych za pomocą ścieżki rozproszonego systemu plików Hadoop (HDFS)
Aby załadować i odczytać dane z magazynu z odpowiednią ścieżką systemu plików HDFS, potrzebne są dostępne poświadczenia uwierzytelniania dostępu do danych. Te poświadczenia różnią się w zależności od typu magazynu. W tym przykładzie kodu pokazano, jak odczytywać dane z usługi Azure Blob Storage do ramki danych platformy Spark przy użyciu tokenu sygnatury dostępu współdzielonego (SAS) lub klucza dostępu:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
W tym przykładzie kodu pokazano, jak odczytywać dane z usługi Azure Data Lake Storage Generation 1 (ADLS Gen 1) przy użyciu poświadczeń jednostki usługi:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
W tym przykładzie kodu pokazano, jak odczytywać dane z usługi Azure Data Lake Storage Generation 2 (ADLS Gen 2) przy użyciu poświadczeń jednostki usługi:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Odczytywanie danych z zarejestrowanych zestawów danych
Możesz również umieścić istniejący zarejestrowany zestaw danych w obszarze roboczym i wykonać na nim przygotowywanie danych, jeśli przekonwertujesz go na ramkę danych platformy Spark. W tym przykładzie uwierzytelnia się w obszarze roboczym, uzyskuje zarejestrowany zestaw danych tabelarycznych —blob_dset odwołujący się do plików w magazynie obiektów blob i konwertuje ten zestaw danych Tabelaryczny na ramkę danych platformy Spark. Podczas konwertowania zestawów danych na ramki danych platformy Spark można użyć pyspark bibliotek eksploracji i przygotowywania danych.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Wykonywanie zadań uzdatniania danych
Po pobraniu i eksplorowaniu danych możesz wykonywać zadania rozmieszczania danych. Ten przykładowy kod rozszerza przykład systemu plików HDFS w poprzedniej sekcji. Na podstawie kolumny Survivor filtruje dane w ramce df danych platformy Spark i grupach, które są wyświetlane według wieku:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Zapisywanie danych w magazynie i zatrzymywanie sesji platformy Spark
Po zakończeniu eksploracji i przygotowania danych zapisz przygotowane dane do późniejszego użycia na koncie magazynu na platformie Azure. W tym przykładzie kodu przygotowane dane są zapisywane z powrotem w usłudze Azure Blob Storage, zastępując oryginalny Titanic.csv plik w training_data katalogu. Aby zapisywać z powrotem do magazynu, potrzebne są uprawnienia Współautor danych obiektu blob usługi Storage. Aby uzyskać więcej informacji, zobacz Przypisywanie roli platformy Azure w celu uzyskania dostępu do danych obiektów blob.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
Po zakończeniu przygotowywania danych i zapisaniu przygotowanych danych do magazynu zakończ korzystanie z puli platformy Apache Spark za pomocą następującego polecenia:
%synapse stop
Tworzenie zestawu danych w celu reprezentowania przygotowanych danych
Gdy wszystko będzie gotowe do użycia przygotowanych danych na potrzeby trenowania modelu, połącz się z magazynem danych usługi Azure Machine Learning i określ plik lub plik, którego chcesz użyć z zestawem danych usługi Azure Machine Learning.
Ten przykład kodu
- Przyjęto założenie, że utworzono już magazyn danych, który łączy się z usługą magazynu, w której zapisano przygotowane dane
- Pobiera istniejący magazyn danych —
mydatastorez obszaru roboczegowsza pomocą metody get(). - Tworzy zestaw plików FileDataset,
train_ds, w celu odwoływania się do przygotowanych plików danych znajdujących się wmydatastoretraining_datakatalogu - Tworzy zmienną
input1. W późniejszym czasie ta zmienna może udostępnić plikitrain_dsdanych zestawu danych do docelowego obiektu obliczeniowego dla zadań szkoleniowych.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Przesyłanie przebiegu eksperymentu do puli platformy Synapse Spark przy użyciu elementu a ScriptRunConfig
Jeśli wszystko jest gotowe do automatyzacji i produkcji zadań uzdatniania danych, możesz przesłać przebieg eksperymentu do dołączonej puli Platformy Spark usługi Synapse przy użyciu obiektu ScriptRunConfig . W podobny sposób, jeśli masz potok usługi Azure Machine Learning, możesz użyć kroku SynapseSparkStep, aby określić pulę platformy Synapse Spark jako docelowy obiekt obliczeniowy dla kroku przygotowywania danych w potoku. Dostępność danych w puli platformy Synapse Spark zależy od typu zestawu danych.
- W przypadku zestawu FileDataset można użyć
as_hdfs()metody . Po przesłaniu przebiegu zestaw danych zostanie udostępniony puli Platformy Spark usługi Synapse jako rozproszony system plików Hadoop (HFDS) - W przypadku zestawu tabularDataset można użyć
as_named_input()metody
Poniższy przykładowy kod
- Tworzy zmienną
input2na podstawie elementu FileDatasettrain_dsutworzonego w poprzednim przykładzie kodu - Tworzy zmienną
outputz klasąHDFSOutputDatasetConfiguration. Po zakończeniu przebiegu ta klasa umożliwia zapisanie danych wyjściowych przebiegu jako zestawu danychtestwmydatastoremagazynie danych. W obszarze roboczymtestusługi Azure Machine Learning zestaw danych jest zarejestrowany pod nazwąregistered_dataset - Konfiguruje ustawienia, których przebieg powinien używać do wykonania w puli platformy Synapse Spark
- Definiuje parametry ScriptRunConfig do
- Użyj skryptu
dataprep.pydo uruchomienia - Określ dane, które mają być używane jako dane wejściowe i jak udostępnić te dane w puli usługi Synapse Spark
- Określanie miejsca przechowywania danych wyjściowych
output
- Użyj skryptu
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Aby uzyskać więcej informacji na temat run_config.spark.configuration i ogólnej konfiguracji platformy Spark, odwiedź stronę SparkConfiguration Class (Klasa Spark) i dokumentację konfiguracji platformy Apache Spark.
Po skonfigurowaniu ScriptRunConfig obiektu możesz przesłać przebieg.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Aby uzyskać więcej informacji, w tym informacje na temat skryptu użytego dataprep.py w tym przykładzie, zobacz przykładowy notes.
Po przygotowaniu danych możesz użyć ich jako danych wejściowych dla zadań szkoleniowych. W powyższym przykładzie kodu określisz registered_dataset jako dane wejściowe dla zadań szkoleniowych.
Przykładowe notesy
Przejrzyj te przykładowe notesy, aby uzyskać więcej pojęć i pokazów możliwości integracji usługi Azure Synapse Analytics i Azure Machine Learning:
- Uruchom interaktywną sesję platformy Spark z notesu w obszarze roboczym usługi Azure Machine Learning.
- Prześlij przebieg eksperymentu usługi Azure Machine Learning z pulą platformy Synapse Spark jako obiektem docelowym obliczeń.
Następne kroki
- Trenowanie modelu.
- Trenowanie przy użyciu zestawu danych usługi Azure Machine Learning.