Konfigurowanie trenowania automatycznego uczenia maszynowego przy użyciu języka Python
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Z tego przewodnika dowiesz się, jak skonfigurować zautomatyzowane uczenie maszynowe, rozwiązanie AutoML, trenowanie uruchamiane przy użyciu zestawu SDK języka Python usługi Azure Machine Learning przy użyciu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Learning. Zautomatyzowane uczenie maszynowe wybiera algorytm i hiperparametry dla Ciebie i generuje model gotowy do wdrożenia. Ten przewodnik zawiera szczegółowe informacje o różnych opcjach, których można użyć do konfigurowania eksperymentów zautomatyzowanego uczenia maszynowego.
Aby zapoznać się z przykładem kompleksowego, zobacz Samouczek: model regresji trenowania automatycznego uczenia maszynowego.
Jeśli wolisz środowisko bez kodu, możesz również skonfigurować trenowanie automatycznego uczenia maszynowego bez kodu w usłudze Azure Machine Learning Studio.
Wymagania wstępne
Na potrzeby tego artykułu potrzebne są następujące elementy:
Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz Tworzenie zasobów obszaru roboczego.
Zainstalowany zestaw SDK języka Python usługi Azure Machine Learning. Aby zainstalować zestaw SDK, możesz wykonać jedną z następujących czynności:
Utwórz wystąpienie obliczeniowe, które automatycznie instaluje zestaw SDK i jest wstępnie skonfigurowane dla przepływów pracy uczenia maszynowego. Aby uzyskać więcej informacji, zobacz Tworzenie wystąpienia obliczeniowego usługi Azure Machine Learning i zarządzanie nim.
Zainstaluj pakiet
automlsamodzielnie, który obejmuje domyślną instalację zestawu SDK.
Ważne
Polecenia języka Python w tym artykule wymagają najnowszej
azureml-train-automlwersji pakietu.- Zainstaluj najnowszy
azureml-train-automlpakiet w środowisku lokalnym. - Aby uzyskać szczegółowe informacje na temat najnowszego
azureml-train-automlpakietu, zobacz informacje o wersji.
Ostrzeżenie
Język Python 3.8 nie jest zgodny z .
automl
Wybieranie typu eksperymentu
Przed rozpoczęciem eksperymentu należy określić rodzaj rozwiązywanego problemu uczenia maszynowego. Zautomatyzowane uczenie maszynowe obsługuje typy classificationzadań , regressioni forecasting. Dowiedz się więcej o typach zadań.
Uwaga
Obsługa zadań przetwarzania języka naturalnego (NLP): klasyfikacja obrazów (wiele klas i wiele etykiet) oraz rozpoznawanie nazwanych jednostek jest dostępne w publicznej wersji zapoznawczej. Dowiedz się więcej o zadaniach nlp w zautomatyzowanym uczeniu maszynowym.
Te funkcje w wersji zapoznawczej są udostępniane bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą nie być obsługiwane lub mogą mieć ograniczone funkcje. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Poniższy kod używa parametru task w konstruktorze AutoMLConfig , aby określić typ eksperymentu jako classification.
from azureml.train.automl import AutoMLConfig
# task can be one of classification, regression, forecasting
automl_config = AutoMLConfig(task = "classification")
Źródło i format danych
Zautomatyzowane uczenie maszynowe obsługuje dane, które znajdują się na komputerze lokalnym lub w chmurze, na przykład w usłudze Azure Blob Storage. Dane można odczytywać w ramce danych pandas lub zestawie danych tabelarycznych usługi Azure Machine Learning. Dowiedz się więcej o zestawach danych.
Wymagania dotyczące danych szkoleniowych w uczeniu maszynowym:
- Dane muszą być w formie tabelarycznej.
- Wartość, która ma być przewidywana, kolumna docelowa, musi znajdować się w danych.
Ważne
Eksperymenty zautomatyzowanego uczenia maszynowego nie obsługują trenowania przy użyciu zestawów danych korzystających z dostępu do danych opartych na tożsamościach.
W przypadku eksperymentów zdalnych dane szkoleniowe muszą być dostępne ze zdalnych obliczeń. Zautomatyzowane uczenie maszynowe akceptuje tylko zestawy danych tabelarycznych usługi Azure Machine Learning podczas pracy nad zdalnym obliczeniami.
Zestawy danych usługi Azure Machine Learning udostępniają następujące funkcje:
- Łatwe przesyłanie danych ze statycznych plików lub źródeł adresów URL do obszaru roboczego.
- Udostępnianie danych dla skryptów szkoleniowych w przypadku korzystania z zasobów obliczeniowych w chmurze. Zobacz How to train with datasets (Jak trenować przy użyciu zestawów danych), aby zapoznać się z przykładem używania
Datasetklasy do instalowania danych w zdalnym obiekcie docelowym obliczeniowym.
Poniższy kod tworzy tabelaryczny zestaw danych na podstawie adresu URL sieci Web. Zobacz Tworzenie zestawu danych tabelarycznych, aby zapoznać się z przykładami kodu dotyczącymi tworzenia zestawów danych z innych źródeł, takich jak pliki lokalne i magazyny danych.
from azureml.core.dataset import Dataset
data = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv"
dataset = Dataset.Tabular.from_delimited_files(data)
W przypadku lokalnych eksperymentów obliczeniowych zalecamy użycie ramek danych biblioteki pandas w celu szybszego przetwarzania.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("your-local-file.csv")
train_data, test_data = train_test_split(df, test_size=0.1, random_state=42)
label = "label-col-name"
Trenowanie, walidacja i testowanie danych
Możesz określić oddzielne dane treningowe i zestawy danych weryfikacji bezpośrednio w konstruktorze AutoMLConfig . Dowiedz się więcej na temat konfigurowania trenowania, walidacji, krzyżowego sprawdzania poprawności i testowania danych dla eksperymentów rozwiązania AutoML.
Jeśli nie określisz jawnie parametru validation_data lub n_cross_validation , zautomatyzowane uczenie maszynowe stosuje domyślne techniki w celu określenia sposobu wykonywania walidacji. Ta determinacja zależy od liczby wierszy w zestawie danych przypisanym do parametru training_data .
| Rozmiar danych treningowych | Technika walidacji |
|---|---|
| Więcej niż 20 000 wierszy | Zastosowano podział danych trenowania/walidacji. Wartość domyślna to 10% początkowego zestawu danych treningowych jako zestawu weryfikacji. Z kolei ten zestaw weryfikacji jest używany do obliczania metryk. |
| Mniejsze niż 20 000 wierszy | Zastosowano podejście do krzyżowego sprawdzania poprawności. Domyślna liczba składań zależy od liczby wierszy. Jeśli zestaw danych jest mniejszy niż 1000 wierszy, używane jest 10 razy. Jeśli wiersze mają od 1000 do 20 000, używane są trzy razy. |
Napiwek
Możesz przekazać dane testowe (wersja zapoznawcza), aby ocenić modele wygenerowane przez zautomatyzowane uczenie maszynowe. Te funkcje są eksperymentalnymi funkcjami w wersji zapoznawczej i mogą ulec zmianie w dowolnym momencie. Instrukcje:
- Przekaż dane testowe do obiektu AutoMLConfig.
- Przetestuj modele zautomatyzowanego uczenia maszynowego wygenerowanego dla eksperymentu.
Jeśli wolisz środowisko bez kodu, zobacz krok 12 w temacie Konfigurowanie rozwiązania AutoML przy użyciu interfejsu użytkownika programu Studio
Duże dane
Zautomatyzowane uczenie maszynowe obsługuje ograniczoną liczbę algorytmów szkoleniowych na dużych danych, które mogą pomyślnie tworzyć modele danych big data na małych maszynach wirtualnych. Zautomatyzowane algorytmy heurystyczne uczenia maszynowego zależą od właściwości, takich jak rozmiar danych, rozmiar pamięci maszyny wirtualnej, limit czasu eksperymentu i ustawienia cechowania, aby określić, czy te duże algorytmy danych powinny być stosowane. Dowiedz się więcej o tym, jakie modele są obsługiwane w zautomatyzowanym uczeniu maszynowym.
W przypadku regresji regresja spadku gradientu w trybie online i regresji liniowej szybkiej
W przypadku klasyfikacji klasyfikator averaged Perceptron i klasyfikator svM liniowy, gdzie klasyfikator svM liniowy ma zarówno duże dane, jak i małe wersje danych.
Jeśli chcesz zastąpić te heurystyki, zastosuj następujące ustawienia:
| Zadanie | Ustawienie | Uwagi |
|---|---|---|
| Blokuj algorytmy przesyłania strumieniowego danych | blocked_modelsAutoMLConfig w obiekcie i wyświetl listę modeli, których nie chcesz używać. |
Wyniki w przypadku niepowodzenia uruchomienia lub długiego czasu wykonywania |
| Korzystanie z algorytmów przesyłania strumieniowego danych | allowed_modelsAutoMLConfig w obiekcie i wyświetl listę modeli, których chcesz użyć. |
|
| Korzystanie z algorytmów przesyłania strumieniowego danych (eksperymenty interfejsu użytkownika programu Studio) |
Blokuj wszystkie modele z wyjątkiem algorytmów danych big data, których chcesz użyć. |
Obliczenia w celu uruchomienia eksperymentu
Następnie określ, gdzie będzie trenowany model. Eksperyment zautomatyzowanego trenowania uczenia maszynowego można uruchomić w następujących opcjach obliczeniowych.
Wybierz lokalne środowisko obliczeniowe: jeśli scenariusz dotyczy początkowych eksploracji lub pokazów przy użyciu małych danych i krótkich pociągów (tj. sekund lub kilku minut na przebieg dziecka), trenowanie na komputerze lokalnym może być lepszym wyborem. Nie ma czasu konfiguracji, zasoby infrastruktury (komputer lub maszyna wirtualna) są dostępne bezpośrednio. Zapoznaj się z tym notesem zawierającym przykład obliczeń lokalnych.
Wybierz zdalny klaster obliczeniowy uczenia maszynowego: jeśli trenujesz z większymi zestawami danych, takimi jak w przypadku trenowania produkcyjnego, które wymagają dłuższych pociągów, zdalne obliczenia zapewnią znacznie lepszą wydajność czasu kompleksowego, ponieważ
AutoMLzrównają pociągi między węzłami klastra. W przypadku zdalnego przetwarzania obliczeniowego czas uruchamiania wewnętrznej infrastruktury spowoduje dodanie około 1,5 minut na przebieg podrzędny oraz dodatkowe minuty dla infrastruktury klastra, jeśli maszyny wirtualne nie są jeszcze uruchomione.Zarządzane obliczenia usługi Azure Machine Learning to usługa zarządzana, która umożliwia trenowanie modeli uczenia maszynowego w klastrach maszyn wirtualnych platformy Azure. Wystąpienie obliczeniowe jest również obsługiwane jako docelowy obiekt obliczeniowy.Klaster usługi Azure Databricks w ramach subskrypcji platformy Azure. Więcej szczegółów można znaleźć w temacie Konfigurowanie klastra usługi Azure Databricks na potrzeby zautomatyzowanego uczenia maszynowego. Zobacz tę witrynę usługi GitHub, aby zapoznać się z przykładami notesów obejmującymi usługę Azure Databricks.
Podczas wybierania docelowego obiektu obliczeniowego należy wziąć pod uwagę następujące czynniki:
| Zalety | Wady (handicapy) | |
|---|---|---|
| Lokalny docelowy obiekt obliczeniowy | ||
| Zdalne klastry obliczeniowe uczenia maszynowego |
Konfigurowanie ustawień eksperymentu
Istnieje kilka opcji, których można użyć do skonfigurowania eksperymentu zautomatyzowanego uczenia maszynowego. Te parametry są ustawiane przez utworzenie AutoMLConfig wystąpienia obiektu. Zobacz klasę AutoMLConfig, aby uzyskać pełną listę parametrów.
Poniższy przykład dotyczy zadania klasyfikacji. Eksperyment używa klasy AUC ważonej jako podstawowej metryki i ma limit czasu eksperymentu ustawiony na 30 minut i 2 fałdy krzyżowej weryfikacji.
automl_classifier=AutoMLConfig(task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
blocked_models=['XGBoostClassifier'],
training_data=train_data,
label_column_name=label,
n_cross_validations=2)
Można również skonfigurować zadania prognozowania, które wymagają dodatkowej konfiguracji. Aby uzyskać więcej informacji, zobacz artykuł Konfigurowanie automatycznego uczenia maszynowego na potrzeby prognozowania szeregów czasowych.
time_series_settings = {
'time_column_name': time_column_name,
'time_series_id_column_names': time_series_id_column_names,
'forecast_horizon': n_test_periods
}
automl_config = AutoMLConfig(
task = 'forecasting',
debug_log='automl_oj_sales_errors.log',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=20,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
path=project_folder,
verbosity=logging.INFO,
**time_series_settings
)
Obsługiwane modele
Zautomatyzowane uczenie maszynowe próbuje różnych modeli i algorytmów podczas procesu automatyzacji i dostrajania. Jako użytkownik nie ma potrzeby określania algorytmu.
Trzy różne task wartości parametrów określają listę algorytmów lub modeli do zastosowania. allowed_models Użyj parametrów orblocked_models, aby dalej modyfikować iteracji przy użyciu dostępnych modeli do uwzględnienia lub wykluczenia.
Poniższa tabela zawiera podsumowanie obsługiwanych modeli według typu zadania.
Uwaga
Jeśli planujesz wyeksportować zautomatyzowane modele uczenia maszynowego do modelu ONNX, tylko te algorytmy oznaczone gwiazdką * (gwiazdka) mogą być konwertowane na format ONNX. Dowiedz się więcej o konwertowaniu modeli na ONNX.
Należy również pamiętać, że w tej chwili funkcja ONNX obsługuje tylko zadania klasyfikacji i regresji.
Metryka podstawowa
Parametr primary_metric określa metryki, która ma być używana podczas trenowania modelu na potrzeby optymalizacji. Dostępne metryki, które można wybrać, są określane przez wybrany typ zadania.
Wybór podstawowej metryki dla zautomatyzowanego uczenia maszynowego do optymalizacji zależy od wielu czynników. Zalecamy, aby główną kwestią było wybranie metryki najlepiej reprezentującej potrzeby biznesowe. Następnie zastanów się, czy metryka jest odpowiednia dla profilu zestawu danych (rozmiar danych, zakres, rozkład klas itp.). W poniższych sekcjach podsumowano zalecane podstawowe metryki na podstawie typu zadania i scenariusza biznesowego.
Dowiedz się więcej o określonych definicjach tych metryk w artykule Omówienie wyników zautomatyzowanego uczenia maszynowego.
Metryki dla scenariuszy klasyfikacji
Metryki zależne od progu, takie jak accuracy, recall_score_weighted, norm_macro_recalli precision_score_weighted mogą nie być zoptymalizowane również dla zestawów danych, które są małe, mają bardzo duże niesymetryczność klas (nierównowaga klas) lub gdy oczekiwana wartość metryki jest bardzo zbliżona do 0,0 lub 1,0. W takich przypadkach AUC_weighted może być lepszym wyborem dla podstawowej metryki. Po zakończeniu zautomatyzowanego uczenia maszynowego możesz wybrać zwycięski model na podstawie metryki najlepiej dopasowanej do potrzeb biznesowych.
| Metric | Przykładowe przypadki użycia |
|---|---|
accuracy |
Klasyfikacja obrazów, analiza tonacji, przewidywanie zmian |
AUC_weighted |
Wykrywanie oszustw, klasyfikacja obrazów, wykrywanie anomalii/wykrywanie spamu |
average_precision_score_weighted |
Analiza opinii |
norm_macro_recall |
Przewidywanie zmian |
precision_score_weighted |
Metryki dla scenariuszy regresji
r2_scorei normalized_mean_absolute_error normalized_root_mean_squared_error wszyscy próbują zminimalizować błędy przewidywania. r2_score i normalized_root_mean_squared_error jednocześnie minimalizują średnie błędy kwadratowe, podczas gdy normalized_mean_absolute_error mniejsza jest średnia wartość bezwzględna błędów. Wartość bezwzględna traktuje błędy zarówno wielkości, jak i błędy kwadratowe będą miały znacznie większą karę za błędy z większymi wartościami bezwzględnymi. W zależności od tego, czy większe błędy powinny być karane więcej, czy nie, można wybrać optymalizację błędu kwadratowego lub bezwzględnego błędu.
Główną różnicą między elementami r2_score i normalized_root_mean_squared_error jest sposób ich normalizacji i ich znaczenia. normalized_root_mean_squared_error jest błędem średniokwadratowym znormalizowanym według zakresu i można go interpretować jako średnią wielkość błędu dla przewidywania. r2_score to błąd średniokwadratowy znormalizowany przez oszacowanie wariancji danych. Jest to odsetek odmian, które mogą być przechwytywane przez model.
Uwaga
r2_score i normalized_root_mean_squared_error zachowują się podobnie jak metryki podstawowe. Jeśli zastosowano stały zestaw weryfikacji, te dwie metryki optymalizują ten sam cel, błąd średniokwadratowy i będą optymalizowane przez ten sam model. Gdy jest dostępny tylko zestaw treningowy i jest stosowany krzyżowa walidacja, byłyby nieco inne, ponieważ normalizator dla normalized_root_mean_squared_error parametru jest stały, ponieważ zakres zestawu treningowego, ale moduł normalizatora r2_score dla każdego fałdu będzie się różnić, ponieważ jest to wariancja dla każdego fałszu.
Jeśli ranga, zamiast dokładnej wartości jest interesująca, może być lepszym wyborem, spearman_correlation ponieważ mierzy korelację rangi między rzeczywistymi wartościami i przewidywaniami.
Jednak obecnie żadne podstawowe metryki regresji nie dotyczą względnej różnicy. Wszystkie elementy r2_score, normalized_mean_absolute_errori normalized_root_mean_squared_error traktują błąd przewidywania w wysokości 20 tys. USD taki sam dla procesu roboczego z wynagrodzeniem w wysokości 30 tys. USD jako pracownik wykonujący 20 mln USD, jeśli te dwa punkty danych należą do tego samego zestawu danych na potrzeby regresji lub tej samej serii czasowej określonej przez identyfikator szeregów czasowych. Chociaż w rzeczywistości przewidywanie tylko 20 tys. USD od wynagrodzenia w wysokości 20 mln USD jest bardzo bliskie (niewielka różnica względna 0,1%), podczas gdy 20 tys. USD z 30 tys. USD nie jest blisko (duża różnica względna 67%. Aby rozwiązać problem względnej różnicy, można wytrenować model z dostępnymi podstawowymi metrykami, a następnie wybrać model z najlepszym mean_absolute_percentage_error rozwiązaniem lub root_mean_squared_log_error.
| Metric | Przykładowe przypadki użycia |
|---|---|
spearman_correlation |
|
normalized_root_mean_squared_error |
Przewidywanie cen (dom/produkt/porada), Przeglądanie przewidywania wyników |
r2_score |
Opóźnienie linii lotniczych, Szacowanie wynagrodzenia, Czas rozwiązywania usterek |
normalized_mean_absolute_error |
Metryki scenariuszy prognozowania szeregów czasowych
Zalecenia są podobne do tych, które zostały zanotowane w scenariuszach regresji.
| Metric | Przykładowe przypadki użycia |
|---|---|
normalized_root_mean_squared_error |
Przewidywanie cen (prognozowanie), optymalizacja zapasów, prognozowanie zapotrzebowania |
r2_score |
Przewidywanie cen (prognozowanie), optymalizacja zapasów, prognozowanie zapotrzebowania |
normalized_mean_absolute_error |
Cechowanie danych
W każdym zautomatyzowanym eksperymencie uczenia maszynowego dane są automatycznie skalowane i znormalizowane, aby ułatwić niektórym algorytmom, które są wrażliwe na funkcje w różnych skalach. To skalowanie i normalizacja jest określane jako cechowanie. Aby uzyskać więcej szczegółów i przykładów kodu, zobacz Cechowanie w rozwiązaniu AutoML .
Uwaga
Zautomatyzowane kroki cechowania uczenia maszynowego (normalizacja cech, obsługa brakujących danych, konwertowanie tekstu na liczbowe itp.) stają się częścią modelu bazowego. W przypadku korzystania z modelu do przewidywania te same kroki cechowania stosowane podczas trenowania są stosowane automatycznie do danych wejściowych.
Podczas konfigurowania eksperymentów w AutoMLConfig obiekcie można włączyć/wyłączyć ustawienie featurization. W poniższej tabeli przedstawiono zaakceptowane ustawienia cechowania w obiekcie AutoMLConfig.
| Konfiguracja cechowania | opis |
|---|---|
"featurization": 'auto' |
Wskazuje, że w ramach wstępnego przetwarzania wykonywane są automatycznie zabezpieczenia danych i kroki cechowania. Ustawienie domyślne. |
"featurization": 'off' |
Wskazuje, że krok cechowania nie powinien być wykonywany automatycznie. |
"featurization": 'FeaturizationConfig' |
Wskazuje, że należy użyć dostosowanego kroku cechowania. Dowiedz się, jak dostosować cechowanie. |
Konfiguracja zespołu
Modele zespołowe są domyślnie włączone i są wyświetlane jako końcowe iteracji uruchamiania w przebiegu rozwiązania AutoML. Obecnie obsługiwane są rozwiązania VotingEnsemble i StackEnsemble .
Głosowanie implementuje nietrwałe głosowanie, które wykorzystuje średnie ważone. Implementacja stosu używa implementacji dwóch warstw, gdzie pierwsza warstwa ma te same modele co zespół głosujący, a drugi model warstwy służy do znajdowania optymalnej kombinacji modeli z pierwszej warstwy.
Jeśli używasz modeli ONNX lub masz włączoną możliwość wyjaśnienia modelu, tworzenie stosu jest wyłączone i używane jest tylko głosowanie.
Trenowanie zespołu można wyłączyć przy użyciu parametrów logicznych enable_voting_ensemble i enable_stack_ensemble .
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=data_train,
label_column_name=label,
n_cross_validations=5,
enable_voting_ensemble=False,
enable_stack_ensemble=False
)
Aby zmienić domyślne zachowanie zespołu, istnieje wiele domyślnych argumentów, które można podać jak kwargs w AutoMLConfig obiekcie.
Ważne
Następujące parametry nie są jawnymi parametrami klasy AutoMLConfig.
ensemble_download_models_timeout_sec: Podczas generowania modeli VotingEnsemble i StackEnsemble pobiera się wiele dopasowanych modeli z poprzednich przebiegów podrzędnych. Jeśli wystąpi ten błąd:AutoMLEnsembleException: Could not find any models for running ensembling, może być konieczne dostarczenie więcej czasu na pobranie modeli. Wartość domyślna to 300 sekund na równoległe pobieranie tych modeli i nie ma maksymalnego limitu czasu. Skonfiguruj ten parametr z wyższą wartością niż 300 sekund, jeśli jest potrzebny więcej czasu.Uwaga
Jeśli zostanie osiągnięty limit czasu i zostaną pobrane modele, to przestępstwo będzie kontynuowane z jak najwięcej modeli, które pobrano. Nie jest wymagane, aby wszystkie modele musiały zostać pobrane, aby zakończyć w tym przedziale czasu. Następujące parametry dotyczą tylko modeli StackEnsemble :
stack_meta_learner_type: metauczeń to model wyszkolony na podstawie danych wyjściowych poszczególnych modeli heterogenicznych. Domyślne metauczeń sąLogisticRegressionprzeznaczone dla zadań klasyfikacji (lubLogisticRegressionCVjeśli włączono krzyżową walidację) orazElasticNetdla zadań regresji/prognozowania (lubElasticNetCVjeśli włączono krzyżową walidację). Ten parametr może być jednym z następujących ciągów:LogisticRegression, ,LogisticRegressionCV,LightGBMClassifierElasticNet,ElasticNetCV, ,LightGBMRegressorlubLinearRegression.stack_meta_learner_train_percentage: określa proporcję zestawu treningowego (podczas wybierania typu trenowania i sprawdzania poprawności trenowania) do trenowania metauczeń. Wartość domyślna to0.2.stack_meta_learner_kwargs: opcjonalne parametry, które mają być przekazywane do inicjatora metauczeń. Te parametry i typy parametrów dublują parametry i typy parametrów z odpowiedniego konstruktora modelu i są przekazywane do konstruktora modelu.
Poniższy kod przedstawia przykład określania niestandardowego zachowania zespołu w AutoMLConfig obiekcie.
ensemble_settings = {
"ensemble_download_models_timeout_sec": 600
"stack_meta_learner_type": "LogisticRegressionCV",
"stack_meta_learner_train_percentage": 0.3,
"stack_meta_learner_kwargs": {
"refit": True,
"fit_intercept": False,
"class_weight": "balanced",
"multi_class": "auto",
"n_jobs": -1
}
}
automl_classifier = AutoMLConfig(
task='classification',
primary_metric='AUC_weighted',
experiment_timeout_minutes=30,
training_data=train_data,
label_column_name=label,
n_cross_validations=5,
**ensemble_settings
)
Kryteria zakończenia
Istnieje kilka opcji, które można zdefiniować w konfiguracji AutoML, aby zakończyć eksperyment.
| Kryterium | opis |
|---|---|
| Brak kryteriów | Jeśli nie zdefiniujesz żadnych parametrów zakończenia, eksperyment będzie kontynuowany, dopóki nie zostaną wykonane żadne dalsze postępy w podstawowej metryce. |
| Po upływie czasu | Użyj experiment_timeout_minutes w ustawieniach, aby zdefiniować, jak długo, w minutach, eksperyment powinien być nadal uruchamiany. Aby uniknąć błędów przekroczenia limitu czasu eksperymentu, istnieje co najmniej 15 minut lub 60 minut, jeśli wiersz według rozmiaru kolumny przekroczy 10 milionów. |
| Osiągnięto wynik | Użycie experiment_exit_score kończy eksperyment po osiągnięciu określonego podstawowego wyniku metryki. |
Uruchom eksperyment
Ostrzeżenie
Jeśli wielokrotnie uruchamiasz eksperyment z tymi samymi ustawieniami konfiguracji i metrykami podstawowymi, prawdopodobnie zobaczysz różnice w poszczególnych eksperymentach końcowych metryk i wygenerowanych modelach. Algorytmy zautomatyzowanego uczenia maszynowego mają nieodłączną losowość, która może spowodować niewielkie różnice w danych wyjściowych modeli w wyniku eksperymentu i wynik końcowych metryk zalecanego modelu, na przykład dokładność. Prawdopodobnie zobaczysz również wyniki o tej samej nazwie modelu, ale są używane różne hiperparametry.
W przypadku zautomatyzowanego uczenia maszynowego Experiment utworzysz obiekt, który jest obiektem nazwanym w obiekcie używanym Workspace do uruchamiania eksperymentów.
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
# Choose a name for the experiment and specify the project folder.
experiment_name = 'Tutorial-automl'
project_folder = './sample_projects/automl-classification'
experiment = Experiment(ws, experiment_name)
Prześlij eksperyment, aby uruchomić i wygenerować model. Przekaż metodę AutoMLConfig submit do metody , aby wygenerować model.
run = experiment.submit(automl_config, show_output=True)
Uwaga
Zależności są najpierw instalowane na nowej maszynie. Zanim zostanie wyświetlone dane wyjściowe, może upłynąć do 10 minut.
Ustawienie show_output powoduje True wyświetlenie danych wyjściowych w konsoli programu .
Wiele podrzędnych przebiegów w klastrach
Przebiegi podrzędne eksperymentu zautomatyzowanego uczenia maszynowego można wykonać w klastrze, który już uruchamia kolejny eksperyment. Jednak czas zależy od liczby węzłów, które ma klaster, a jeśli te węzły są dostępne do uruchomienia innego eksperymentu.
Każdy węzeł w klastrze działa jako pojedyncza maszyna wirtualna, która może wykonać pojedynczy przebieg trenowania; w przypadku zautomatyzowanego uczenia maszynowego oznacza to uruchomienie podrzędne. Jeśli wszystkie węzły są zajęte, nowy eksperyment jest w kolejce. Jeśli jednak istnieją wolne węzły, nowy eksperyment uruchomi automatyczne podrzędne uczenia maszynowego równolegle w dostępnych węzłach/maszynach wirtualnych.
Aby ułatwić zarządzanie przebiegami podrzędnym i ich wykonywaniem, zalecamy utworzenie dedykowanego klastra na eksperyment i dopasowanie liczby max_concurrent_iterations eksperymentu do liczby węzłów w klastrze. W ten sposób wszystkie węzły klastra są używane w tym samym czasie z liczbą współbieżnych przebiegów podrzędnych/iteracji.
Skonfiguruj max_concurrent_iterations w AutoMLConfig obiekcie. Jeśli nie jest skonfigurowany, domyślnie na eksperyment dozwolony jest tylko jeden współbieżny przebieg podrzędny/iteracja.
W przypadku wystąpienia max_concurrent_iterations obliczeniowego można ustawić wartość taką samą jak liczba rdzeni na maszynie wirtualnej wystąpienia obliczeniowego.
Eksplorowanie modeli i metryk
Zautomatyzowane uczenie maszynowe oferuje opcje monitorowania i oceniania wyników trenowania.
Wyniki trenowania można wyświetlić w widżecie lub wbudowanym, jeśli jesteś w notesie. Aby uzyskać więcej informacji, zobacz Monitorowanie przebiegów zautomatyzowanego uczenia maszynowego.
Aby zapoznać się z definicjami i przykładami wykresów wydajności i metryk dostępnych dla każdego przebiegu, zobacz Ocena wyników eksperymentu zautomatyzowanego uczenia maszynowego.
Aby uzyskać podsumowanie cechowania i zrozumieć, jakie funkcje zostały dodane do określonego modelu, zobacz Przejrzystość cechowania.
Możesz wyświetlić hiperparametry, techniki skalowania i normalizacji oraz algorytm zastosowany do określonego zautomatyzowanego przebiegu uczenia maszynowego przy użyciu niestandardowego rozwiązania kodu, print_model().
Napiwek
Zautomatyzowane uczenie maszynowe umożliwia również wyświetlenie wygenerowanego kodu trenowania modelu dla wytrenowanych modeli automatycznego uczenia maszynowego. Ta funkcja jest dostępna w publicznej wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Monitorowanie przebiegów zautomatyzowanego uczenia maszynowego
W przypadku przebiegów zautomatyzowanego uczenia maszynowego, aby uzyskać dostęp do wykresów z poprzedniego przebiegu, zastąp <<experiment_name>> element odpowiednią nazwą eksperymentu:
from azureml.widgets import RunDetails
from azureml.core.run import Run
experiment = Experiment (workspace, <<experiment_name>>)
run_id = 'autoML_my_runID' #replace with run_ID
run = Run(experiment, run_id)
RunDetails(run).show()
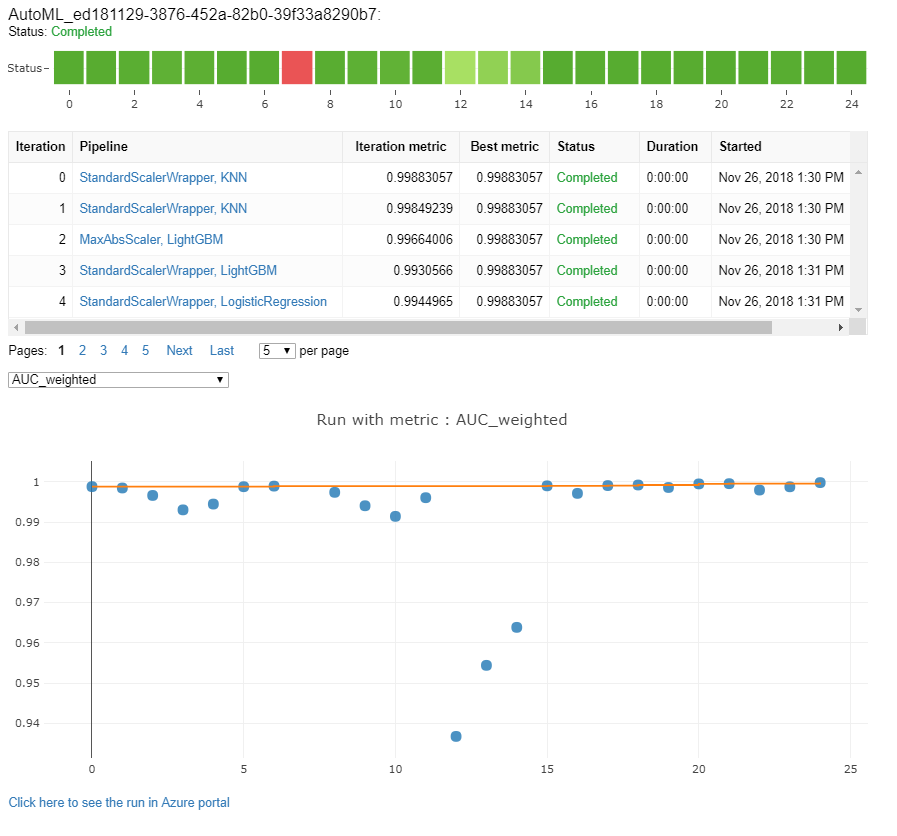
Modele testowe (wersja zapoznawcza)
Ważne
Testowanie modeli przy użyciu testowego zestawu danych w celu oceny zautomatyzowanych modeli generowanych przez uczenie maszynowe jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Ostrzeżenie
Ta funkcja nie jest dostępna w następujących scenariuszach zautomatyzowanego uczenia maszynowego
Przekazanie test_data parametrów lub test_size do AutoMLConfigelementu powoduje automatyczne wyzwolenie zdalnego przebiegu testu, który używa podanych danych testowych do oceny najlepszego modelu zalecanego przez zautomatyzowane uczenie maszynowe po zakończeniu eksperymentu. Ten przebieg testu zdalnego odbywa się na końcu eksperymentu, gdy zostanie określony najlepszy model. Zobacz, jak przekazać dane testowe do pliku AutoMLConfig.
Pobieranie wyników zadania testowego
Przewidywania i metryki można uzyskać z zadania testu zdalnego z usługi Azure Machine Learning Studio lub przy użyciu następującego kodu.
best_run, fitted_model = remote_run.get_output()
test_run = next(best_run.get_children(type='automl.model_test'))
test_run.wait_for_completion(show_output=False, wait_post_processing=True)
# Get test metrics
test_run_metrics = test_run.get_metrics()
for name, value in test_run_metrics.items():
print(f"{name}: {value}")
# Get test predictions as a Dataset
test_run_details = test_run.get_details()
dataset_id = test_run_details['outputDatasets'][0]['identifier']['savedId']
test_run_predictions = Dataset.get_by_id(workspace, dataset_id)
predictions_df = test_run_predictions.to_pandas_dataframe()
# Alternatively, the test predictions can be retrieved via the run outputs.
test_run.download_file("predictions/predictions.csv")
predictions_df = pd.read_csv("predictions.csv")
Zadanie testowania modelu generuje plik predictions.csv przechowywany w domyślnym magazynie danych utworzonym za pomocą obszaru roboczego. Ten magazyn danych jest widoczny dla wszystkich użytkowników z tą samą subskrypcją. Zadania testowe nie są zalecane w scenariuszach, jeśli którekolwiek z informacji używanych przez zadanie testowe lub utworzone przez zadanie testowe musi pozostać prywatne.
Testowanie istniejącego zautomatyzowanego modelu uczenia maszynowego
Aby przetestować inne istniejące zautomatyzowane modele uczenia maszynowego utworzone, najlepsze zadanie lub zadanie podrzędne, użyj polecenia ModelProxy() , aby przetestować model po zakończeniu głównego przebiegu automatycznego uczenia maszynowego. ModelProxy() Zwraca już przewidywania i metryki i nie wymaga dalszego przetwarzania w celu pobrania danych wyjściowych.
Uwaga
ModelProxy to eksperymentalna klasa w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Poniższy kod pokazuje, jak przetestować model z dowolnego przebiegu przy użyciu metody ModelProxy.test(). W metodzie test() możesz określić, czy chcesz zobaczyć tylko przewidywania przebiegu testu z parametrem include_predictions_only .
from azureml.train.automl.model_proxy import ModelProxy
model_proxy = ModelProxy(child_run=my_run, compute_target=cpu_cluster)
predictions, metrics = model_proxy.test(test_data, include_predictions_only= True
)
Rejestrowanie i wdrażanie modeli
Po przetestowaniu modelu i potwierdzeniu, że chcesz go używać w środowisku produkcyjnym, możesz zarejestrować go do późniejszego użycia i
Aby zarejestrować model na podstawie zautomatyzowanego przebiegu uczenia maszynowego, użyj register_model() metody .
best_run = run.get_best_child()
print(fitted_model.steps)
model_name = best_run.properties['model_name']
description = 'AutoML forecast example'
tags = None
model = run.register_model(model_name = model_name,
description = description,
tags = tags)
Aby uzyskać szczegółowe informacje na temat tworzenia konfiguracji wdrożenia i wdrażania zarejestrowanego modelu w usłudze internetowej, zobacz , jak i gdzie wdrożyć model.
Napiwek
W przypadku zarejestrowanych modeli wdrożenie jednym kliknięciem jest dostępne za pośrednictwem usługi Azure Machine Learning Studio. Zobacz , jak wdrażać zarejestrowane modele ze studia.
Możliwość interpretowania modelu
Możliwość interpretacji modelu pozwala zrozumieć, dlaczego modele przewidywały i podstawowe wartości ważności funkcji. Zestaw SDK zawiera różne pakiety umożliwiające funkcje interpretacji modelu, zarówno w czasie trenowania, jak i wnioskowania, dla modeli lokalnych i wdrożonych.
Zobacz, jak włączyć funkcje interpretowania w szczególności w ramach eksperymentów zautomatyzowanego uczenia maszynowego.
Aby uzyskać ogólne informacje na temat sposobu włączania wyjaśnień modelu i znaczenia funkcji w innych obszarach zestawu SDK poza automatycznym uczeniem maszynowym, zobacz artykuł dotyczący możliwości interpretacji.
Uwaga
Model ForecastTCN nie jest obecnie obsługiwany przez klienta wyjaśnień. Ten model nie zwróci pulpitu nawigacyjnego wyjaśnienia, jeśli zostanie zwrócony jako najlepszy model i nie obsługuje przebiegów wyjaśnień na żądanie.
Następne kroki
Dowiedz się więcej o tym, jak i gdzie wdrożyć model.
Dowiedz się więcej na temat trenowania modelu regresji za pomocą zautomatyzowanego uczenia maszynowego.
Rozwiązywanie problemów z eksperymentami zautomatyzowanego uczenia maszynowego.