Partycja i przykładowy składnik
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Użyj składnika Partition and Sample, aby wykonać próbkowanie na zestawie danych lub utworzyć partycje na podstawie zestawu danych.
Próbkowanie jest ważnym narzędziem w uczeniu maszynowym, ponieważ pozwala zmniejszyć rozmiar zestawu danych przy zachowaniu tego samego współczynnika wartości. Ten składnik obsługuje kilka powiązanych zadań, które są ważne w uczeniu maszynowym:
Dzielenie danych na wiele podsekcji o tym samym rozmiarze.
Partycje mogą być używane do krzyżowej weryfikacji lub do przypisywania przypadków do grup losowych.
Rozdzielenie danych na grupy, a następnie praca z danymi z określonej grupy.
Po losowym przypisaniu przypadków do różnych grup może być konieczne zmodyfikowanie funkcji skojarzonych tylko z jedną grupą.
Pobieranie próbek.
Możesz wyodrębnić procent danych, zastosować próbkowanie losowe lub wybrać kolumnę, która ma być używana do równoważenia zestawu danych i wykonywać próbkowanie warstwowe na jego wartościach.
Tworzenie mniejszego zestawu danych na potrzeby testowania.
Jeśli masz dużo danych, możesz użyć tylko pierwszych n wierszy podczas konfigurowania potoku, a następnie przełączyć się do korzystania z pełnego zestawu danych podczas kompilowania modelu. Możesz również użyć próbkowania, aby utworzyć mniejszy zestaw danych do użycia w programowania.
Konfigurowanie składnika
Ten składnik obsługuje następujące metody dzielenia danych na partycje lub próbkowania. Najpierw wybierz metodę, a następnie ustaw dodatkowe opcje wymagane przez metodę.
- Head
- Próbkowanie
- Przypisywanie do fałdów
- Wybierz fałdę
Pobieranie pierwszych N wierszy z zestawu danych
Użyj tego trybu, aby uzyskać tylko pierwsze n wierszy. Ta opcja jest przydatna, jeśli chcesz przetestować potok na małej liczbie wierszy i nie potrzebujesz danych, aby były w żaden sposób wyważone ani próbkowane.
Dodaj składnik Partition and Sample do potoku w interfejsie i połącz zestaw danych.
Tryb partycji lub próbki: ustaw tę opcję na Head.
Liczba wierszy do wybrania: wprowadź liczbę wierszy do zwrócenia.
Liczba wierszy musi być nieujemną liczbą całkowitą. Jeśli liczba wybranych wierszy jest większa niż liczba wierszy w zestawie danych, zwracany jest cały zestaw danych.
Prześlij potok.
Składnik generuje pojedynczy zestaw danych zawierający tylko określoną liczbę wierszy. Wiersze są zawsze odczytywane w górnej części zestawu danych.
Tworzenie próbki danych
Ta opcja obsługuje proste losowe próbkowanie lub warstwowe próbkowanie losowe. Jest to przydatne, jeśli chcesz utworzyć mniejszy reprezentatywny przykładowy zestaw danych na potrzeby testowania.
Dodaj składnik Partition and Sample do potoku i połącz zestaw danych.
Tryb partycji lub próbki: ustaw tę opcję na Próbkowanie.
Częstotliwość próbkowania: wprowadź wartość z zakresu od 0 do 1. ta wartość określa procent wierszy ze źródłowego zestawu danych, które powinny być uwzględnione w wyjściowym zestawie danych.
Jeśli na przykład chcesz, aby tylko połowa oryginalnego zestawu danych wskazywała,
0.5że częstotliwość próbkowania powinna wynosić 50%.Wiersze wejściowego zestawu danych są mieszania i selektywnie umieszczane w wyjściowym zestawie danych zgodnie z określonym współczynnikiem.
Losowe rozmieszczanie próbkowania: opcjonalnie wprowadź liczbę całkowitą, która ma być używana jako wartość inicjowania.
Ta opcja jest ważna, jeśli chcesz, aby wiersze zostały podzielone w taki sam sposób za każdym razem. Wartość domyślna to 0, co oznacza, że inicjator początkowy jest generowany na podstawie zegara systemowego. Ta wartość może prowadzić do nieco innych wyników przy każdym uruchomieniu potoku.
Podział warstwowy na potrzeby próbkowania: wybierz tę opcję, jeśli ważne jest, aby wiersze w zestawie danych zostały równomiernie podzielone przez kolumnę klucza przed próbkowaniem.
W przypadku kolumny klucza stratification na potrzeby próbkowania wybierz pojedynczą kolumnę warstwy do użycia podczas dzielenia zestawu danych. Wiersze w zestawie danych są następnie podzielone w następujący sposób:
Wszystkie wiersze wejściowe są pogrupowane (stratified) według wartości w określonej kolumnie strata.
Wiersze są potasowane w każdej grupie.
Każda grupa jest selektywnie dodawana do wyjściowego zestawu danych w celu spełnienia określonego współczynnika.
Prześlij potok.
Dzięki tej opcji składnik generuje pojedynczy zestaw danych, który zawiera reprezentatywne próbkowanie danych. Pozostała, nieprzykładowana część zestawu danych nie jest wyjściowa.
Dzielenie danych na partycje
Użyj tej opcji, jeśli chcesz podzielić zestaw danych na podzestawy danych. Ta opcja jest również przydatna, gdy chcesz utworzyć niestandardową liczbę fałdów na potrzeby krzyżowej weryfikacji lub podzielić wiersze na kilka grup.
Dodaj składnik Partition and Sample do potoku i połącz zestaw danych.
W obszarze Partition or sample mode (Tryb partycji lub przykładu) wybierz pozycję Assign to Folds (Przypisz do fałdów).
Użyj zamiany w partycjonowaniu: wybierz tę opcję, jeśli chcesz, aby przykładowany wiersz został umieszczony z powrotem w puli wierszy w celu potencjalnego ponownego użycia. W związku z tym ten sam wiersz może zostać przypisany do kilku fałd.
Jeśli nie używasz zamiany (opcja domyślna), przykładowy wiersz nie zostanie ponownie umieszczony w puli wierszy w celu potencjalnego ponownego użycia. W związku z tym każdy wiersz można przypisać tylko do jednego składania.
Podział losowy: wybierz tę opcję, jeśli chcesz, aby wiersze zostały losowo przypisane do składanych.
Jeśli nie wybierzesz tej opcji, wiersze są przypisywane do składanych za pomocą metody działania okrężnego.
Inicjator losowy: opcjonalnie wprowadź liczbę całkowitą, która ma być używana jako wartość inicjatora. Ta opcja jest ważna, jeśli chcesz, aby wiersze zostały podzielone w taki sam sposób za każdym razem. W przeciwnym razie wartość domyślna 0 oznacza, że zostanie użyty losowy inicjator początkowy.
Określ metodę partycjonatora: wskaż, w jaki sposób dane mają być rozdzielone do każdej partycji, korzystając z następujących opcji:
Partycja równomiernie: użyj tej opcji, aby umieścić taką samą liczbę wierszy w każdej partycji. Aby określić liczbę partycji wyjściowych, wprowadź liczbę całkowitą w polu Określ liczbę składanych .
Partycja z dostosowanymi proporcjami: użyj tej opcji, aby określić rozmiar każdej partycji jako listę rozdzielaną przecinkami.
Załóżmy na przykład, że chcesz utworzyć trzy partycje. Pierwsza partycja będzie zawierać 50 procent danych. Pozostałe dwie partycje będą zawierać 25 procent danych. W polu Lista proporcji rozdzielonych przecinkami wprowadź następujące liczby: .5, .25, .25.
Suma wszystkich rozmiarów partycji musi zawierać dokładnie 1.
Jeśli wprowadzisz liczby, które sumują się do mniej niż 1, zostanie utworzona dodatkowa partycja do przechowywania pozostałych wierszy. Jeśli na przykład wprowadzisz wartości .2 i .3, zostanie utworzona trzecia partycja do przechowywania pozostałych 50 procent wszystkich wierszy.
Jeśli wprowadzisz liczby, które sumujesz do więcej niż 1, podczas uruchamiania potoku zostanie zgłoszony błąd.
Podział warstwowy: wybierz tę opcję, jeśli chcesz, aby wiersze mają być stratyfikowane podczas dzielenia, a następnie wybierz kolumnę strata.
Prześlij potok.
Dzięki tej opcji składnik generuje wiele zestawów danych. Zestawy danych są partycjonowane zgodnie z określonymi regułami.
Używanie danych ze wstępnie zdefiniowanej partycji
Użyj tej opcji, gdy zestaw danych został podzielony na wiele partycji, a teraz chcesz załadować każdą partycję z kolei w celu dalszej analizy lub przetwarzania.
Dodaj składnik Partition and Sample do potoku.
Połącz składnik z danymi wyjściowymi poprzedniego wystąpienia partycji i przykładu. To wystąpienie musi użyć opcji Przypisz do składania , aby wygenerować pewną liczbę partycji.
Tryb partycji lub próbki: wybierz pozycję Wybierz fałsz.
Określ fałd do próbkowania: wybierz partycję do użycia, wprowadzając jej indeks. Indeksy partycji są oparte na 1. Jeśli na przykład zestaw danych został podzielony na trzy części, partycje będą miały indeksy 1, 2 i 3.
Jeśli wprowadzisz nieprawidłową wartość indeksu, zostanie zgłoszony błąd czasu projektowania: "Błąd 0018: Zestaw danych zawiera nieprawidłowe dane".
Oprócz grupowania zestawu danych według fałdów można rozdzielić zestaw danych na dwie grupy: fałsz docelowy i wszystko inne. Aby to zrobić, wprowadź indeks pojedynczej ramki, a następnie wybierz opcję Wybierz uzupełnienie wybranej złożonej, aby pobrać wszystko, ale dane w określonym fałszowaniu .
Jeśli pracujesz z wieloma partycjami, musisz dodać więcej wystąpień składnika Partition and Sample , aby obsłużyć każdą partycję.
Na przykład składnik Partition (Partycja) i Sample (Przykład) w drugim wierszu ma wartość Assign to Folds (Przypisywanie do fałdów), a składnik w trzecim wierszu ma wartość Pick Fold (Wybierz fałsz).
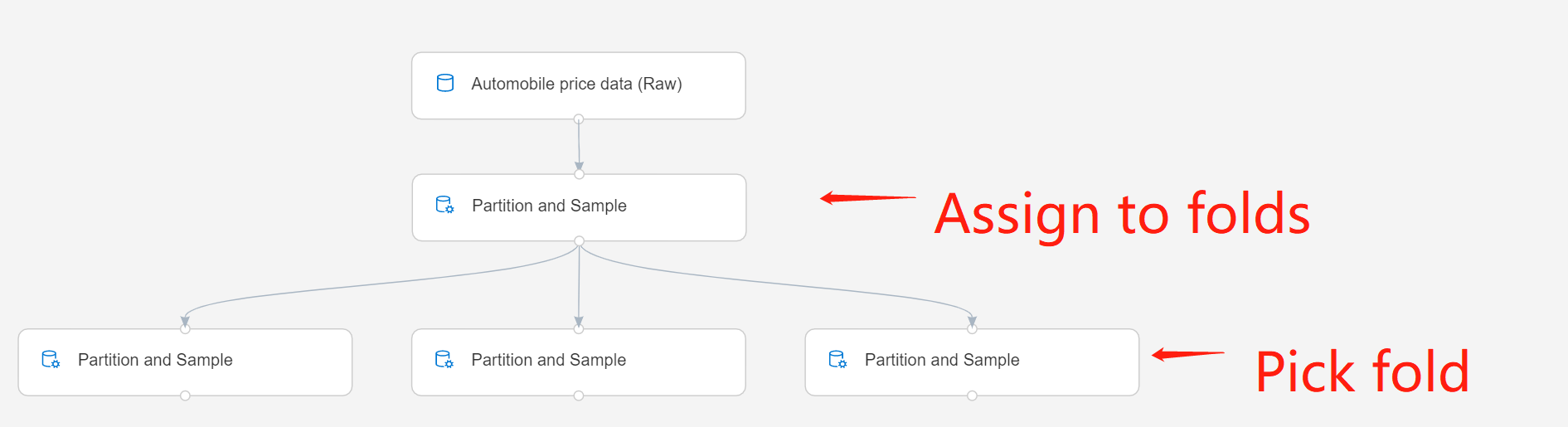
Prześlij potok.
Dzięki tej opcji składnik generuje pojedynczy zestaw danych zawierający tylko wiersze przypisane do tej jednostki.
Uwaga
Nie można wyświetlić oznaczeń składanych bezpośrednio. Są one obecne tylko w metadanych.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.