Wyodrębnianie funkcji N-Gram z odwołania do składnika tekstowego
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning. Wyodrębnianie funkcji N-Gram ze składnika Text umożliwia wydzielenie danych tekstowych bez struktury.
Konfiguracja funkcji wyodrębniania N-Gram ze składnika Text
Składnik obsługuje następujące scenariusze używania słownika n-gram:
Utwórz nowy słownik n-gramowy na podstawie kolumny wolnego tekstu.
Użyj istniejącego zestawu funkcji tekstowych, aby wy featurizować bezpłatną kolumnę tekstową.
Ocenianie lub wdrażanie modelu , który używa n-gramów.
Tworzenie nowego słownika n-gramowego
Dodaj składnik Wyodrębnij funkcje N-Gram ze składnika Text do potoku i połącz zestaw danych zawierający tekst, który chcesz przetworzyć.
Użyj kolumny Tekst, aby wybrać kolumnę typu ciągu zawierającą tekst, który chcesz wyodrębnić. Ponieważ wyniki są pełne, można przetworzyć tylko jedną kolumnę naraz.
Ustaw tryb słownictwa na Utwórz , aby wskazać, że tworzysz nową listę funkcji n-gramowych.
Ustaw rozmiar N-gramów, aby wskazać maksymalny rozmiar n-gramów do wyodrębnienia i przechowywania.
Jeśli na przykład wprowadzisz wartość 3, zostaną utworzone jednogramy, bigramy i trigramy.
Funkcja ważona określa sposób tworzenia wektora cech dokumentu i sposobu wyodrębniania słownictwa z dokumentów.
Waga binarna: przypisuje wartość obecności binarnej do wyodrębnionych n-gramów. Wartość dla każdego n-grama wynosi 1, gdy istnieje w dokumencie, a w przeciwnym razie 0.
Waga TF: przypisuje wynik częstotliwości terminów (TF) do wyodrębnionych n-gramów. Wartość dla każdego n-grama to jego częstotliwość występowania w dokumencie.
Waga IDF: przypisuje wynik odwrotnej częstotliwości dokumentu (IDF) do wyodrębnionych n-gramów. Wartość dla każdego n-grama to dziennik rozmiaru korpusu podzielonego przez jego częstotliwość występowania w całym korpusie.
IDF = log of corpus_size / document_frequencyWaga TF-IDF: przypisuje wynik częstotliwości/odwrotnej częstotliwości dokumentu (TF/IDF) do wyodrębnionych n-gramów. Wartość dla każdego n-grama jest współczynnik TF pomnożony przez jego wynik IDF.
Ustaw minimalną długość wyrazu na minimalną liczbę liter, które mogą być używane w dowolnym pojedynczym słowie w n-gram.
Użyj maksymalnej długości wyrazów, aby ustawić maksymalną liczbę liter, które mogą być używane w dowolnym pojedynczym słowie w n-gramie.
Domyślnie dozwolone jest maksymalnie 25 znaków na słowo lub token.
Użyj minimalnej częstotliwości bezwzględnej dokumentu n-gram, aby ustawić minimalne wystąpienia wymagane dla każdego n-grama, które mają być uwzględnione w słowniku n-gram.
Jeśli na przykład używasz wartości domyślnej 5, każdy n-gram musi pojawić się co najmniej pięć razy w korpusie, aby został uwzględniony w słowniku n-gram.
Ustaw maksymalny stosunek dokumentu n-gram do maksymalnej liczby wierszy, które zawierają określony n-gram, w stosunku do liczby wierszy w ogólnym korpusie.
Na przykład współczynnik 1 wskazuje, że nawet jeśli określony n-gram jest obecny w każdym wierszu, n-gram można dodać do słownika n-gram. Zazwyczaj słowo występujące w każdym wierszu będzie traktowane jako wyraz szumu i zostanie usunięte. Aby odfiltrować wyrazy szumu zależne od domeny, spróbuj zmniejszyć ten współczynnik.
Ważne
Szybkość występowania określonych wyrazów nie jest jednolita. Różni się on od dokumentu do dokumentu. Jeśli na przykład analizujesz komentarze klientów dotyczące określonego produktu, nazwa produktu może być bardzo wysoka i zbliżona do wyrazu szumu, ale może być znaczącym terminem w innych kontekstach.
Wybierz opcję Normalizuj wektory cech n-gram, aby znormalizować wektory funkcji. Jeśli ta opcja jest włączona, każdy wektor funkcji n-gram jest podzielony przez normę L2.
Prześlij potok.
Używanie istniejącego słownika n-gram
Dodaj składnik Wyodrębnij funkcje N-Gram ze składnika Text do potoku i połącz zestaw danych zawierający tekst, który chcesz przetworzyć z portem zestawu danych .
Użyj kolumny Tekst, aby wybrać kolumnę tekstowa zawierającą tekst, który chcesz wyczyszwić. Domyślnie składnik wybiera wszystkie kolumny typu string. Aby uzyskać najlepsze wyniki, należy przetworzyć pojedynczą kolumnę naraz.
Dodaj zapisany zestaw danych zawierający wcześniej wygenerowany słownik n-gram i połącz go z portem słownictwa wejściowego. Możesz również połączyć wynikowe dane wyjściowe słownictwa nadrzędnego funkcji wyodrębniania N gramów ze składnika Text.
W obszarze Tryb słownictwa wybierz opcję ReadOnly update z listy rozwijanej.
Opcja ReadOnly reprezentuje korpus wejściowy słownictwa wejściowego. Zamiast obliczania częstotliwości terminów z nowego zestawu danych tekstowych (po lewej stronie), wagi n-gramowe ze słownictwa wejściowego są stosowane w następujący sposób.
Napiwek
Użyj tej opcji podczas oceniania klasyfikatora tekstu.
Wszystkie inne opcje można znaleźć w opisach właściwości w poprzedniej sekcji.
Prześlij potok.
Tworzenie potoku wnioskowania, który używa n-gramów do wdrożenia punktu końcowego w czasie rzeczywistym
Potok trenowania, który zawiera funkcję wyodrębniania N-gramów z tekstu i modelu generowania wyników w celu przewidywania na testowym zestawie danych, jest wbudowany w następującą strukturę:
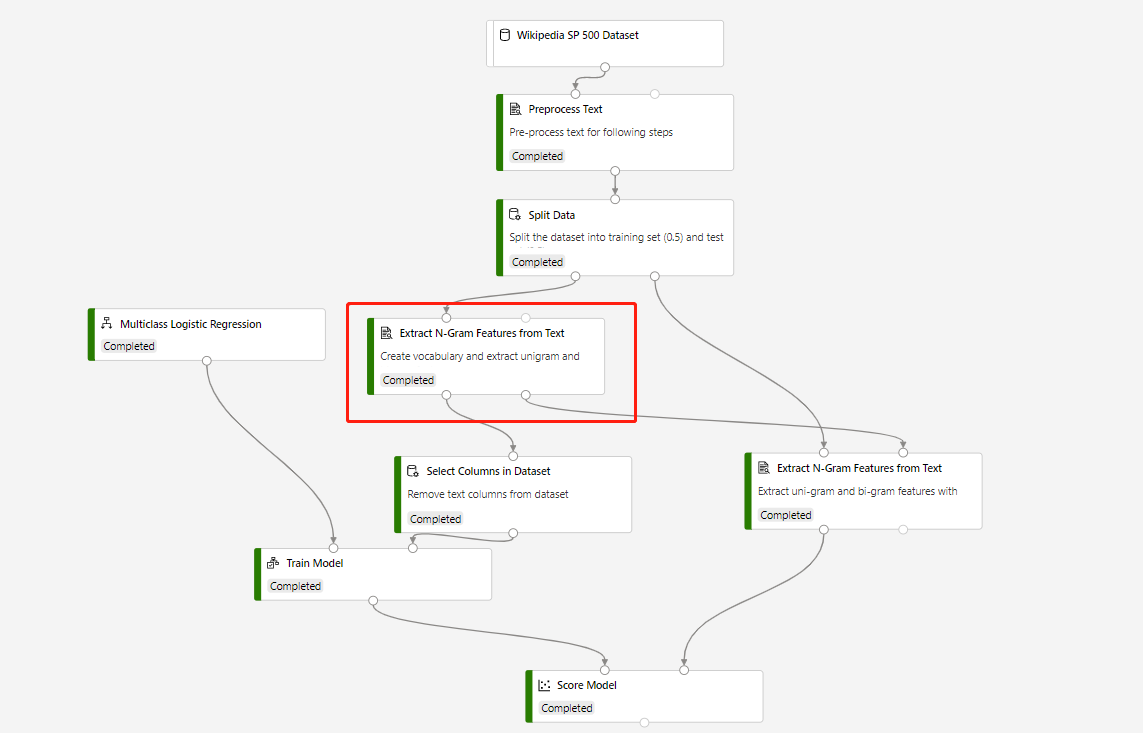
Tryb słownictwa funkcji wyodrębniania N-gramów z elementu tekstowego to Tworzenie, a tryb słownictwa składnika, który łączy się ze składnikiem Score Model (Generowanie wyników dla modelu) jest ReadOnly.
Po pomyślnym przesłaniu powyższego potoku trenowania możesz zarejestrować dane wyjściowe składnika okręgowego jako zestaw danych.
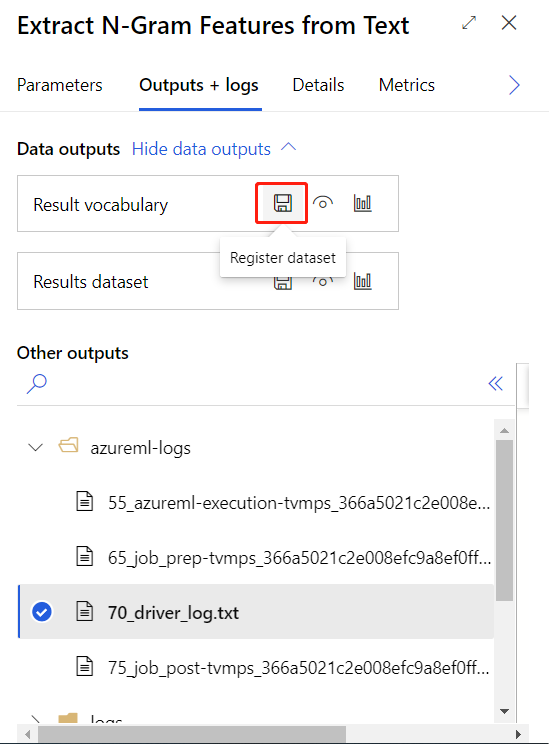
Następnie możesz utworzyć potok wnioskowania w czasie rzeczywistym. Po utworzeniu potoku wnioskowania należy ręcznie dostosować potok wnioskowania w następujący sposób:
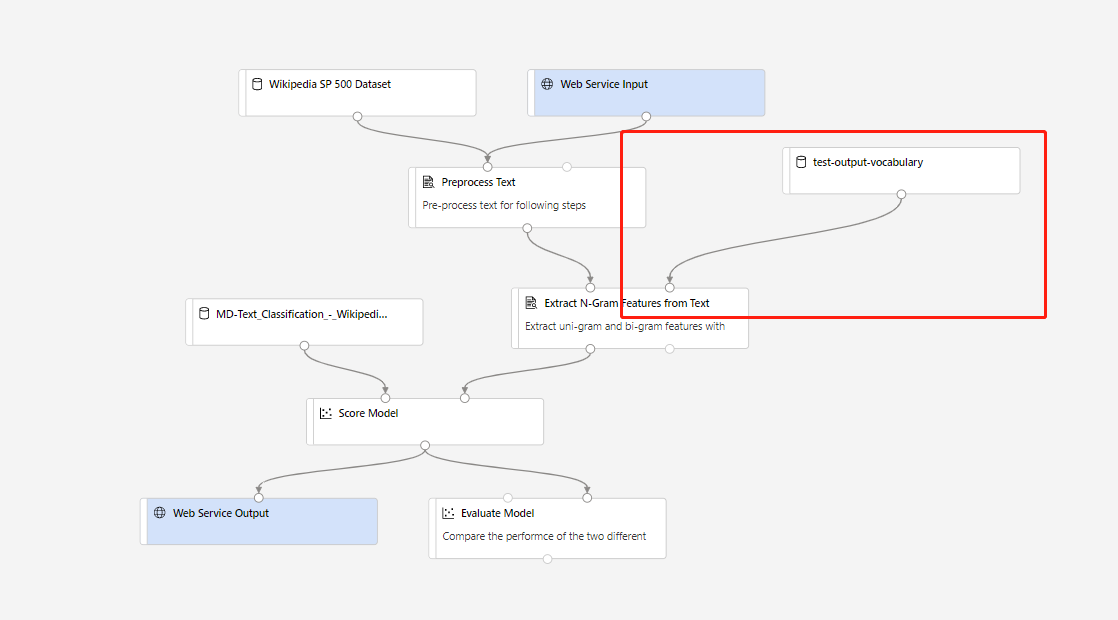
Następnie prześlij potok wnioskowania i wdróż punkt końcowy w czasie rzeczywistym.
Wyniki
Składnik Extract N-Gram Features from Text tworzy dwa typy danych wyjściowych:
Zestaw danych wynikowych: te dane wyjściowe są podsumowaniem analizowanego tekstu połączonego z wyodrębnionym n-gramami. Kolumny, które nie zostały wybrane w opcji Kolumna tekstowa, są przekazywane do danych wyjściowych. Dla każdej kolumny tekstu, którą analizujesz, składnik generuje następujące kolumny:
- Macierz wystąpień n-gram: składnik generuje kolumnę dla każdego n-grama znalezionego w łącznym korpusie i dodaje wynik w każdej kolumnie, aby wskazać wagę n-gram dla tego wiersza.
Słownictwo wynikowe: słownictwo zawiera rzeczywisty słownik n-gram wraz z ocenami częstotliwości terminów generowanymi w ramach analizy. Zestaw danych można zapisać do ponownego użycia przy użyciu innego zestawu danych wejściowych lub do późniejszej aktualizacji. Możesz również ponownie użyć słownictwa do modelowania i oceniania.
Słownictwo wynikowe
Słownictwo zawiera słownik n-gram z ocenami częstotliwości terminów generowanymi w ramach analizy. Wyniki systemu plików DF i IDF są generowane niezależnie od innych opcji.
- IDENTYFIKATOR: identyfikator wygenerowany dla każdego unikatowego n-grama.
- NGram: n-gram. Spacje lub inne separatory wyrazów są zastępowane znakiem podkreślenia.
- DF: wynik częstotliwości terminu n-gram w oryginalnym korpusie.
- IDF: odwrotny wynik częstotliwości dokumentu dla n-gram w oryginalnym korpusie.
Możesz ręcznie zaktualizować ten zestaw danych, ale mogą wystąpić błędy. Na przykład:
- Błąd jest zgłaszany, jeśli składnik znajdzie zduplikowane wiersze z tym samym kluczem w słownictwie wejściowym. Upewnij się, że żadne dwa wiersze w słownictwie nie mają tego samego słowa.
- Schemat wejściowy zestawów danych słownictwa musi być dokładnie zgodny, w tym nazwy kolumn i typy kolumn.
- Kolumna ID i kolumna DF muszą być typu liczba całkowita.
- Kolumna IDF musi być typu zmiennoprzecinkowego.
Uwaga
Nie łącz danych wyjściowych bezpośrednio ze składnikiem Train Model (Trenowanie modelu). Należy usunąć wolne kolumny tekstowe, zanim zostaną wprowadzone do modelu trenowania. W przeciwnym razie bezpłatne kolumny tekstowe będą traktowane jako funkcje kategorii.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.