Wykonywanie składnika skryptu języka Python
W tym artykule opisano składnik Execute Python Script w projektancie usługi Azure Machine Learning.
Użyj tego składnika, aby uruchomić kod języka Python. Aby uzyskać więcej informacji na temat architektury i zasad projektowania języka Python, zobacz jak uruchamiać kod języka Python w projektancie usługi Azure Machine Learning.
Za pomocą języka Python można wykonywać zadania, które nie obsługują istniejących składników, takich jak:
- Wizualizowanie danych przy użyciu polecenia
matplotlib. - Używanie bibliotek języka Python do wyliczania zestawów danych i modeli w obszarze roboczym.
- Odczytywanie, ładowanie i manipulowanie danymi ze źródeł, których składnik Importuj dane nie obsługuje.
- Uruchamianie własnego kodu uczenia głębokiego.
Obsługiwane pakiety języka Python
Usługa Azure Machine Learning korzysta z dystrybucji Anaconda języka Python, która obejmuje wiele typowych narzędzi do przetwarzania danych. Automatycznie zaktualizujemy wersję platformy Anaconda. Bieżąca wersja to:
- Dystrybucja anaconda 4.5+ dla języka Python 3.6
Aby uzyskać pełną listę, zobacz sekcję Preinstalowane pakiety języka Python.
Aby zainstalować pakiety, które nie znajdują się na liście preinstalowanej (na przykład scikit-misc), dodaj następujący kod do skryptu:
import os
os.system(f"pip install scikit-misc")
Użyj następującego kodu, aby zainstalować pakiety w celu uzyskania lepszej wydajności, zwłaszcza w przypadku wnioskowania:
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Uwaga
Jeśli potok zawiera wiele składników Execute Python Script, które wymagają pakietów, które nie znajdują się na liście wstępnie zainstalowanych, zainstaluj pakiety w każdym składniku.
Ostrzeżenie
Składnik excute Python Script nie obsługuje instalowania pakietów, które zależą od dodatkowych bibliotek natywnych z poleceniem takim jak "apt-get", takich jak Java, PyODBC i itp. Jest to spowodowane tym, że ten składnik jest wykonywany w prostym środowisku ze wstępnie zainstalowanym językiem Python i z uprawnieniami innych niż administrator.
Dostęp do bieżącego obszaru roboczego i zarejestrowanych zestawów danych
Aby uzyskać dostęp do zarejestrowanych zestawów danych w obszarze roboczym, możesz odwołać się do następującego przykładowego kodu:
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Przekaż pliki
Składnik Execute Python Script (Wykonywanie skryptu języka Python) obsługuje przekazywanie plików przy użyciu zestawu SDK języka Python usługi Azure Machine Learning.
W poniższym przykładzie pokazano, jak przekazać plik obrazu w składniku Execute Python Script (Wykonywanie skryptu języka Python):
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Po zakończeniu przebiegu potoku możesz wyświetlić podgląd obrazu w prawym panelu składnika.
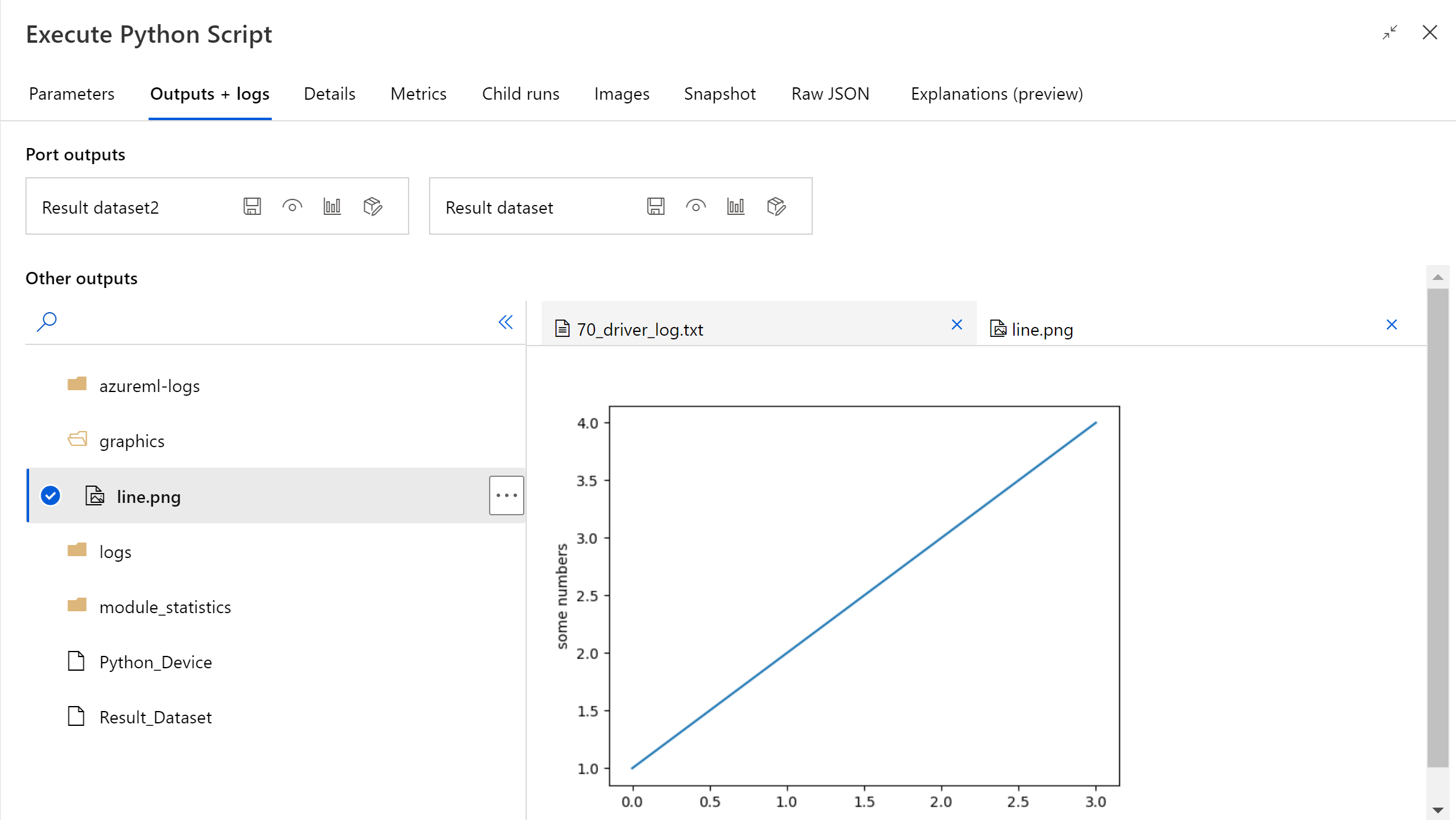
Plik można również przekazać do dowolnego magazynu danych przy użyciu następującego kodu. Możesz wyświetlić podgląd tylko pliku na koncie magazynu.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Jak skonfigurować wykonywanie skryptu języka Python
Składnik Execute Python Script (Wykonywanie skryptu języka Python) zawiera przykładowy kod języka Python, którego można użyć jako punktu początkowego. Aby skonfigurować składnik Execute Python Script (Wykonywanie skryptu języka Python), podaj zestaw danych wejściowych i kodu języka Python do uruchomienia w polu tekstowym skryptu języka Python.
Dodaj składnik Execute Python Script (Wykonywanie skryptu języka Python) do potoku.
Dodaj zestaw danych Dataset1 i nawiąż połączenie z dowolnymi zestawami danych z projektanta, których chcesz użyć do wprowadzania danych. Odwołuj się do tego zestawu danych w skrycie języka Python jako ramka danych DataFrame1.
Użycie zestawu danych jest opcjonalne. Użyj go, jeśli chcesz wygenerować dane przy użyciu języka Python lub użyć kodu języka Python, aby zaimportować dane bezpośrednio do składnika.
Ten składnik obsługuje dodanie drugiego zestawu danych w zestawie danych Dataset2. Odwołuj się do drugiego zestawu danych w skrywcie języka Python jako ramki danych DataFrame2.
Zestawy danych przechowywane w usłudze Azure Machine Learning są automatycznie konwertowane na ramki danych biblioteki pandas podczas ładowania z tym składnikiem.
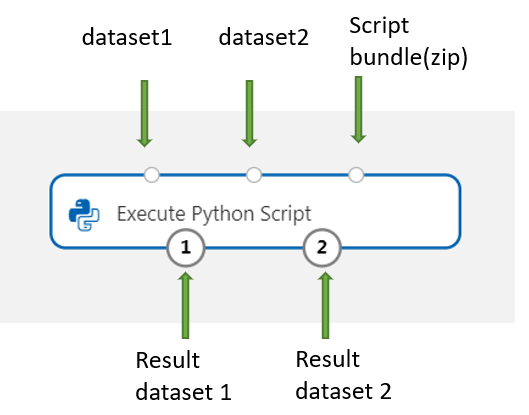
Aby dołączyć nowe pakiety języka Python lub kod, połącz spakowany plik zawierający te zasoby niestandardowe z portem pakietu skryptu. Jeśli skrypt jest większy niż 16 KB, użyj portu pakietu skryptów, aby uniknąć błędów, takich jak Wiersz polecenia przekracza limit 16597 znaków.
- Utwórz pakiet skryptu i innych zasobów niestandardowych do pliku zip.
- Przekaż plik zip jako zestaw danych plików do studia.
- Przeciągnij składnik zestawu danych z listy Zestawy danych w okienku składników po lewej stronie na stronie tworzenia projektanta.
- Połącz składnik zestawu danych z portem pakietu skryptów składnika Execute Python Script .
Podczas wykonywania potoku można użyć dowolnego pliku zawartego w przekazanym spakowanym archiwum. Jeśli archiwum zawiera strukturę katalogów, struktura zostanie zachowana.
Ważne
Użyj unikatowej i znaczącej nazwy plików w pakiecie skryptów, ponieważ niektóre typowe słowa (takie jak
testiappitp.) są zarezerwowane dla wbudowanych usług.Poniżej przedstawiono przykład pakietu skryptów, który zawiera plik skryptu języka Python i plik txt:
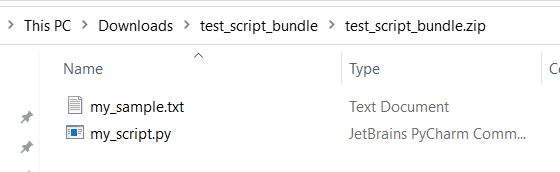
Poniżej znajduje się zawartość elementu
my_script.py:def my_func(dataframe1): return dataframe1Poniżej przedstawiono przykładowy kod pokazujący sposób korzystania z plików w pakiecie skryptów:
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])W polu tekstowym Skrypt języka Python wpisz lub wklej prawidłowy skrypt języka Python.
Uwaga
Podczas pisania skryptu należy zachować ostrożność. Upewnij się, że nie ma błędów składniowych, takich jak używanie niezdecydowanych zmiennych lub nieimportowanych składników lub funkcji. Zwróć szczególną uwagę na listę wstępnie zainstalowanych składników. Aby zaimportować składniki, których nie ma na liście, zainstaluj odpowiednie pakiety w skry skrycie, takie jak:
import os os.system(f"pip install scikit-misc")Pole tekstowe skryptu języka Python jest wstępnie wypełniane instrukcjami w komentarzach i przykładowym kodem umożliwiającym dostęp do danych i dane wyjściowe. Musisz edytować lub zastąpić ten kod. Postępuj zgodnie z konwencjami języka Python dotyczącymi wcięcia i wielkości liter:
- Skrypt musi zawierać funkcję o nazwie
azureml_mainjako punkt wejścia dla tego składnika. - Funkcja punktu wejścia musi mieć dwa argumenty wejściowe, a
Param<dataframe2>nawet wtedy,Param<dataframe1>gdy te argumenty nie są używane w skrycie. - Spakowane pliki połączone z trzecim portem wejściowym są rozpakowane i przechowywane w katalogu
.\Script Bundle, który jest również dodawany do języka Pythonsys.path.
Jeśli plik .zip zawiera
mymodule.pyplik , zaimportuj go przy użyciu poleceniaimport mymodule.Do projektanta można zwrócić dwa zestawy danych, które muszą być sekwencją typu
pandas.DataFrame. Możesz utworzyć inne dane wyjściowe w kodzie języka Python i napisać je bezpośrednio w usłudze Azure Storage.Ostrzeżenie
Nie zaleca się nawiązywania połączenia z bazą danych lub innymi magazynami zewnętrznymi w składniku Wykonywanie skryptu języka Python. Możesz użyć składnika Importuj dane i składnika Eksportuj dane
- Skrypt musi zawierać funkcję o nazwie
Prześlij potok.
Jeśli składnik zostanie ukończony, sprawdź dane wyjściowe, jeśli są zgodnie z oczekiwaniami.
Jeśli składnik nie powiedzie się, należy wykonać pewne kroki rozwiązywania problemów. Wybierz składnik, a następnie otwórz pozycję Dane wyjściowe i dzienniki w okienku po prawej stronie. Otwórz 70_driver_log.txt i wyszukaj w azureml_main, a następnie możesz znaleźć wiersz, który spowodował błąd. Na przykład "Plik "/tmp/tmp01_ID/user_script.py", wiersz 17 w azureml_main" wskazuje, że błąd wystąpił w 17 wierszu skryptu języka Python.
Wyniki
Wyniki wszystkich obliczeń za pomocą osadzonego kodu w języku Python muszą być podane jako pandas.DataFrame, która jest automatycznie konwertowana na format zestawu danych usługi Azure Machine Learning. Następnie możesz użyć wyników z innymi składnikami w potoku.
Składnik zwraca dwa zestawy danych:
Wyniki Zestaw danych 1 zdefiniowany przez pierwszą zwróconą ramkę danych biblioteki pandas w skryscie języka Python.
Result Dataset 2 ( Zestaw danych 2) zdefiniowany przez drugą zwróconą ramkę danych biblioteki pandas w skryscie języka Python.
Wstępnie zainstalowane pakiety języka Python
Wstępnie zainstalowane pakiety to:
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- kryptografia==2.8
- cycler==0.10.0
- koper==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- niezrównoważony-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- ==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.