Szybki start: interakcyjne uzdatnianie danych za pomocą platformy Apache Spark w usłudze Azure Machine Learning
Aby obsłużyć interaktywne uzdatnianie danych notesu usługi Azure Machine Learning, integracja usługi Azure Machine Learning z usługą Azure Synapse Analytics zapewnia łatwy dostęp do platformy Apache Spark. Ten dostęp umożliwia interaktywne uzdatnianie danych w notesie usługi Azure Machine Learning.
W tym przewodniku Szybki start dowiesz się, jak wykonywać interakcyjne uzdatnianie danych przy użyciu bezserwerowych obliczeń platformy Spark w usłudze Azure Machine Learning, konta magazynu usługi Azure Data Lake Storage (ADLS) Gen 2 i przekazywania tożsamości użytkownika.
Wymagania wstępne
- Subskrypcja platformy Azure; Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
- Obszar roboczy usługi Azure Machine Learning. Odwiedź stronę Tworzenie zasobów obszaru roboczego.
- Konto magazynu usługi Azure Data Lake Storage (ADLS) Gen 2. Odwiedź stronę Tworzenie konta magazynu usługi Azure Data Lake Storage (ADLS) Gen 2.
Przechowywanie poświadczeń konta usługi Azure Storage jako wpisów tajnych w usłudze Azure Key Vault
Aby przechowywać poświadczenia konta usługi Azure Storage jako wpisy tajne w usłudze Azure Key Vault, przy użyciu interfejsu użytkownika witryny Azure Portal:
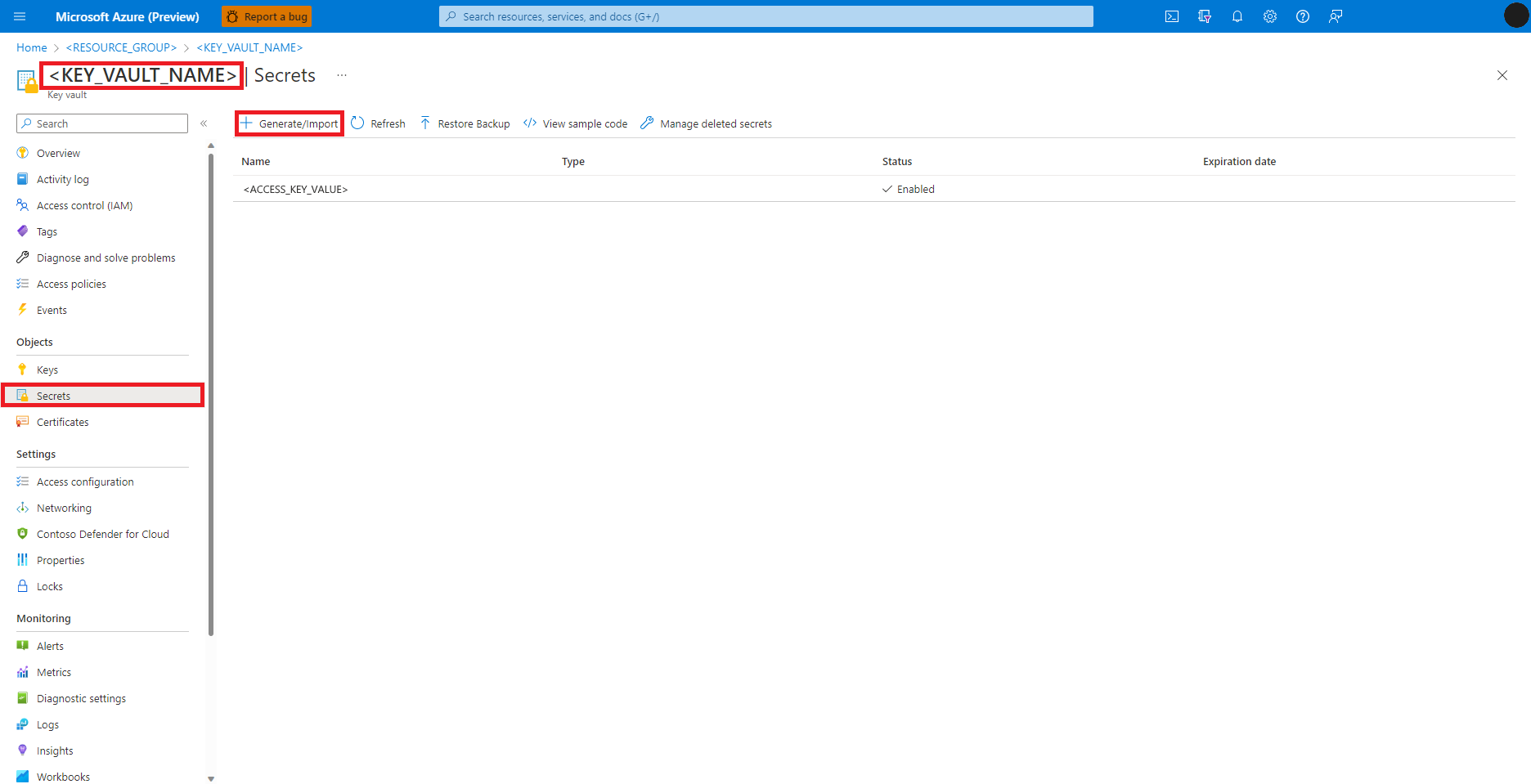
Przejdź do usługi Azure Key Vault w witrynie Azure Portal
Wybierz pozycję Wpisy tajne w panelu po lewej stronie
Wybierz pozycję + Generuj/Importuj
Na ekranie Tworzenie wpisu tajnego wprowadź nazwę wpisu tajnego, który chcesz utworzyć
Przejdź do konta usługi Azure Blob Storage w witrynie Azure Portal, jak pokazano na poniższej ilustracji:
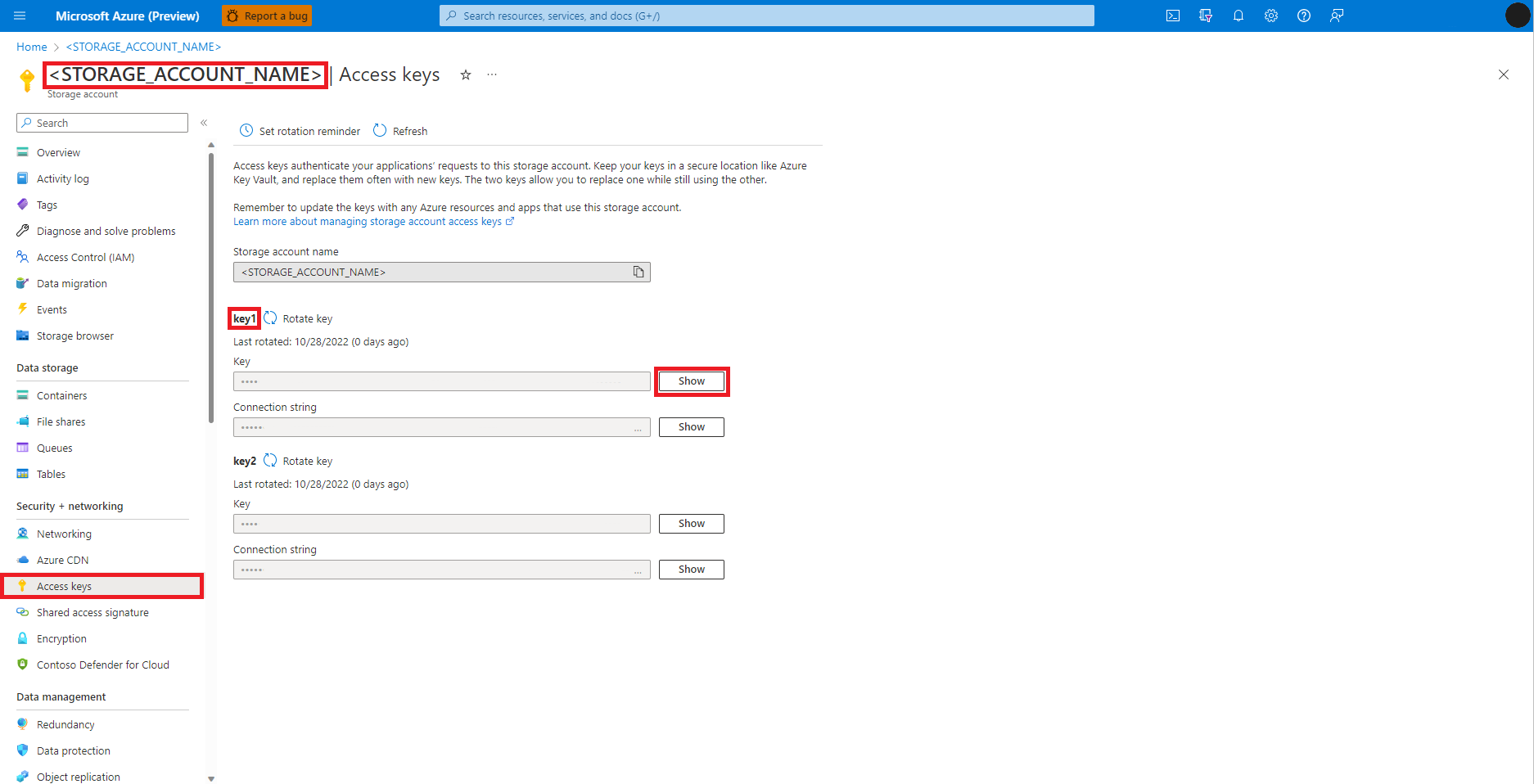
Wybierz pozycję Klucze dostępu na stronie Konta usługi Azure Blob Storage w lewym panelu
Wybierz pozycję Pokaż obok pozycji Klucz 1, a następnie pozycję Kopiuj do schowka , aby uzyskać klucz dostępu do konta magazynu
Uwaga
Wybierz odpowiednie opcje do skopiowania
- Tokeny sygnatury dostępu współdzielonego (SAS) kontenera usługi Azure Blob Storage
- Poświadczenia jednostki usługi konta magazynu usługi Azure Data Lake Storage (ADLS) Gen 2
- Identyfikator dzierżawy
- identyfikator klienta i
- wpis tajny
w odpowiednich interfejsach użytkownika podczas tworzenia dla nich wpisów tajnych usługi Azure Key Vault
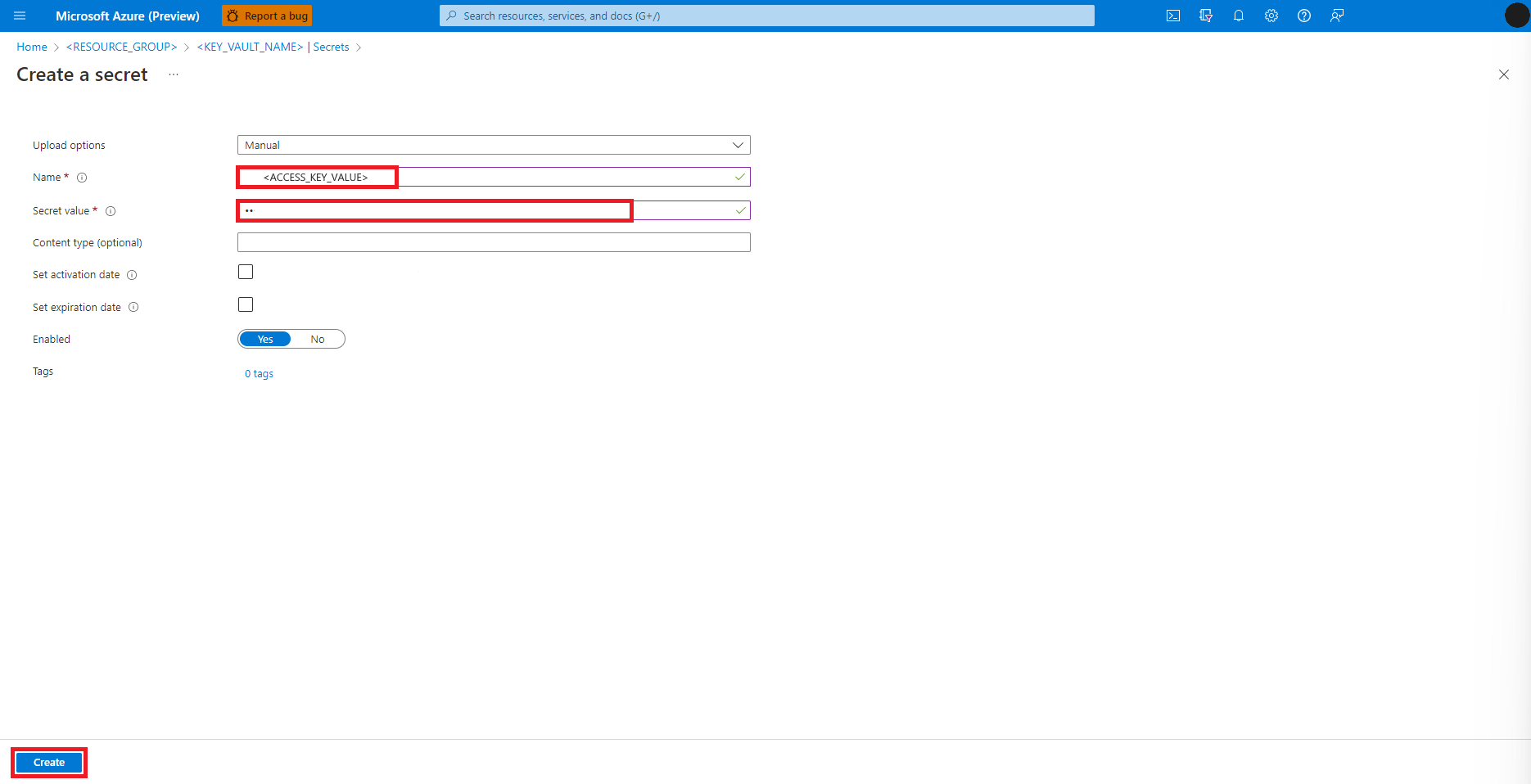
Przejdź z powrotem do ekranu Tworzenie wpisu tajnego
W polu tekstowym Wartość wpisu tajnego wprowadź poświadczenia klucza dostępu dla konta usługi Azure Storage, które zostało skopiowane do schowka we wcześniejszym kroku
Wybierz pozycję Utwórz
Napiwek
Interfejs wiersza polecenia platformy Azure i biblioteka klienta wpisu tajnego usługi Azure Key Vault dla języka Python mogą również tworzyć wpisy tajne usługi Azure Key Vault.
Dodawanie przypisań ról na kontach usługi Azure Storage
Przed rozpoczęciem interakcyjnego rozmieszczania danych musimy upewnić się, że ścieżki danych wejściowych i wyjściowych są dostępne. Najpierw, dla
tożsamość użytkownika zalogowanego użytkownika sesji notesów
lub
jednostka usługi
przypisz role Czytelnik i Czytelnik danych obiektów blob usługi Storage do tożsamości użytkownika zalogowanego. Jednak w niektórych scenariuszach możemy chcieć zapisać rozgniewane dane z powrotem na konto usługi Azure Storage. Role Czytelnik i Czytelnik danych obiektów blob usługi Storage zapewniają dostęp tylko do odczytu tożsamości użytkownika lub jednostki usługi. Aby włączyć dostęp do odczytu i zapisu, przypisz role Współautor i Współautor danych obiektu blob usługi Storage do tożsamości użytkownika lub jednostki usługi. Aby przypisać odpowiednie role do tożsamości użytkownika:
Otwieranie witryny Microsoft Azure Portal
Wyszukaj i wybierz usługę Konta magazynu

Na stronie Konta magazynu wybierz z listy konto magazynu usługi Azure Data Lake Storage (ADLS) Gen 2. generacji. Zostanie otwarta strona przedstawiająca przegląd konta magazynu
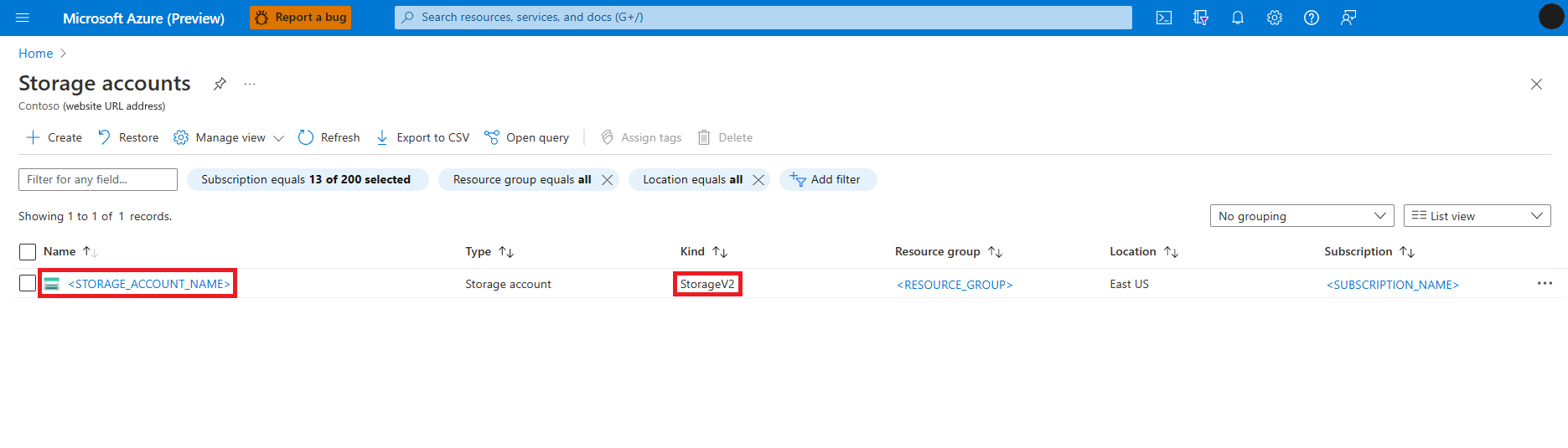
Wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami) z panelu po lewej stronie
Wybierz pozycję Dodaj przypisanie roli
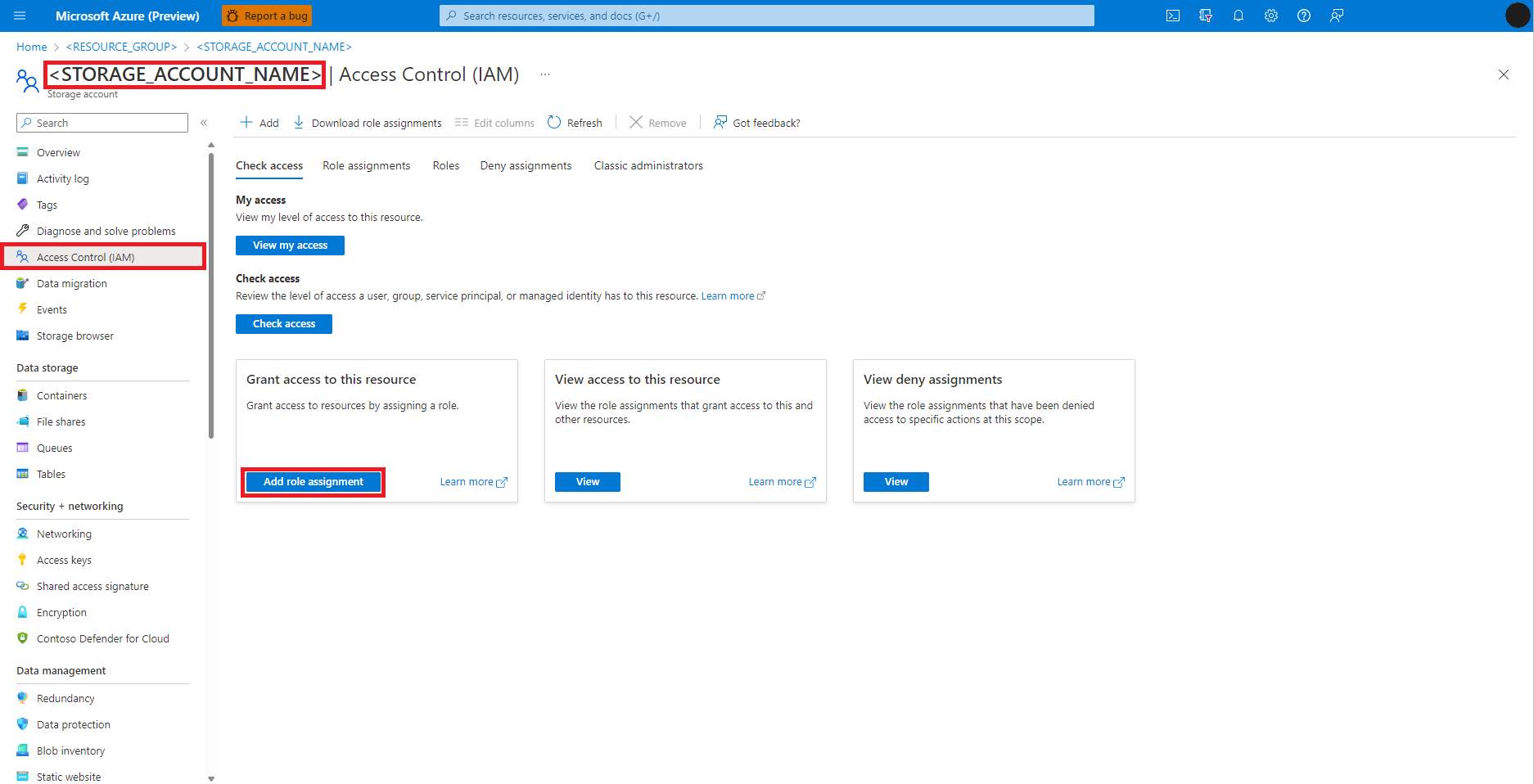
Znajdowanie i wybieranie roli Współautor danych obiektu blob usługi Storage
Wybierz Dalej
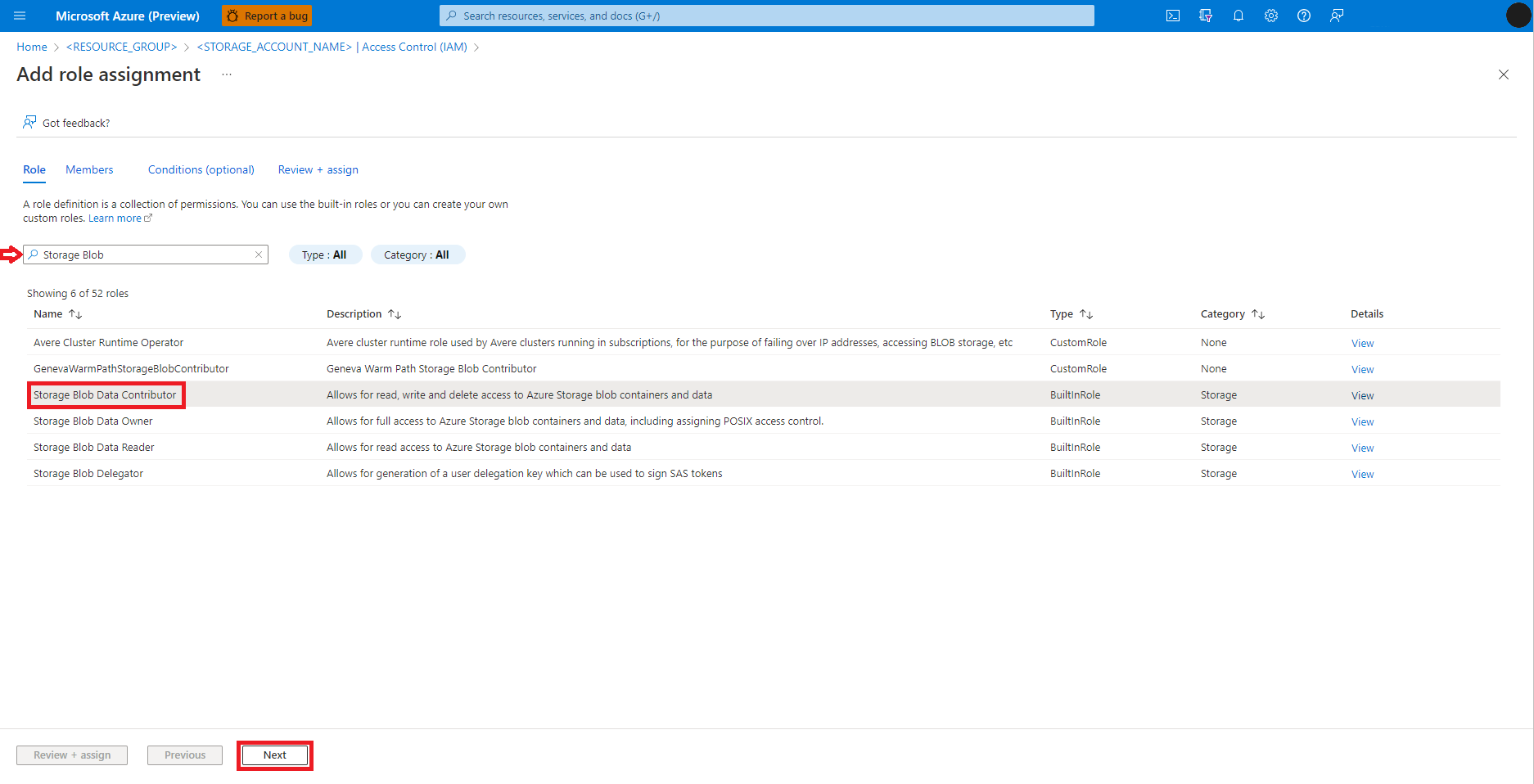
Wybierz pozycję Użytkownik, grupa lub jednostka usługi
Wybierz pozycję + Wybierz członków
Wyszukaj tożsamość użytkownika poniżej wybierz
Wybierz tożsamość użytkownika z listy, aby była wyświetlana w obszarze Wybrane elementy członkowskie
Wybierz odpowiednią tożsamość użytkownika
Wybierz Dalej
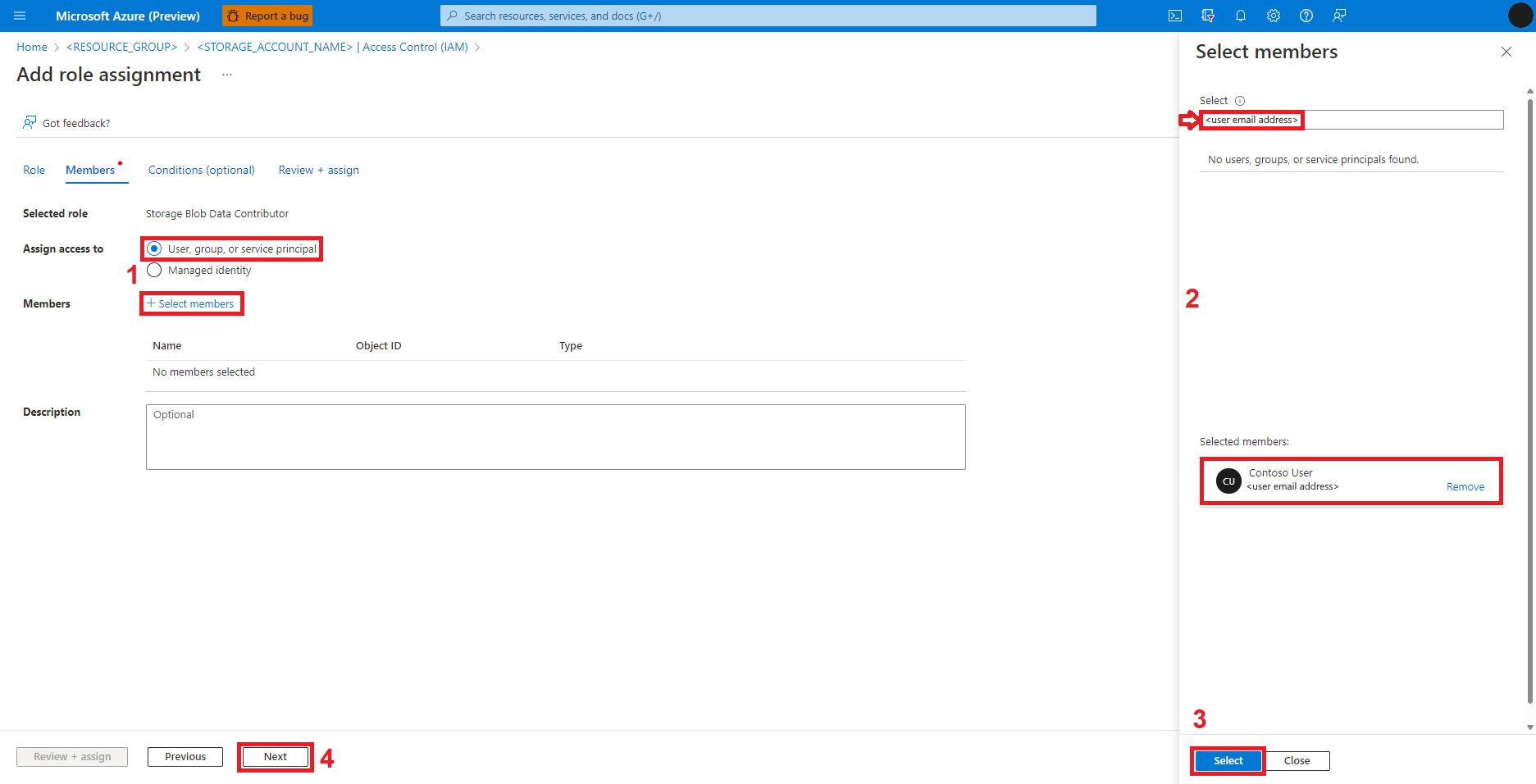
Wybierz pozycję Przejrzyj i przypisz
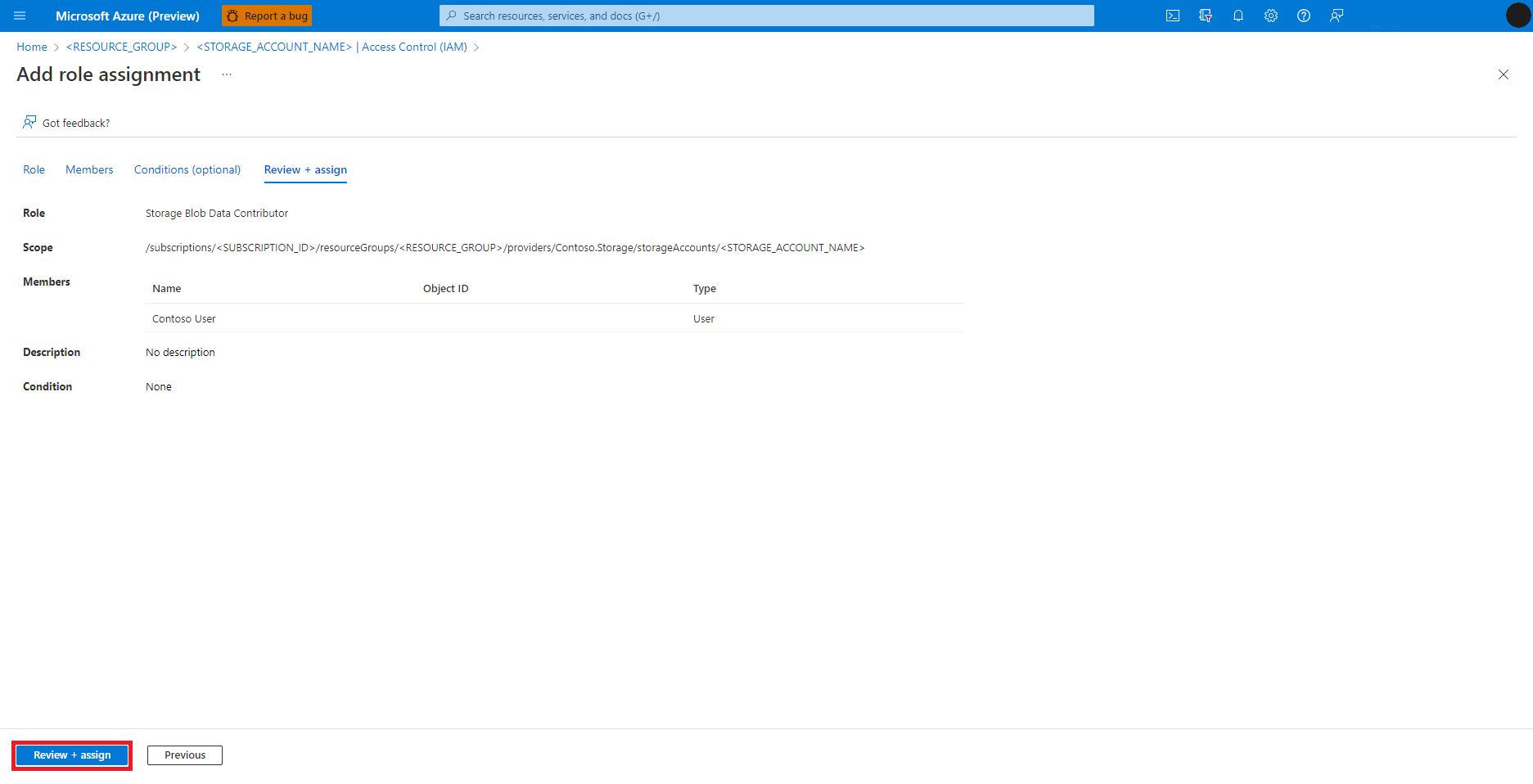
Powtórz kroki 2–13 dla przypisania roli Współautor






Gdy tożsamość użytkownika ma przypisane odpowiednie role, dane na koncie usługi Azure Storage powinny stać się dostępne.
Uwaga
Jeśli dołączona pula usługi Synapse Spark wskazuje pulę usługi Synapse Spark w obszarze roboczym usługi Azure Synapse, z którą jest skojarzona zarządzana sieć wirtualna, należy skonfigurować zarządzany prywatny punkt końcowy na koncie magazynu w celu zapewnienia dostępu do danych.
Zapewnianie dostępu do zasobów dla zadań platformy Spark
Aby uzyskać dostęp do danych i innych zasobów, zadania platformy Spark mogą używać tożsamości zarządzanej lub przekazywania tożsamości użytkownika. Poniższa tabela zawiera podsumowanie różnych mechanizmów dostępu do zasobów podczas korzystania z bezserwerowych obliczeń platformy Spark w usłudze Azure Machine Learning i dołączonej puli platformy Synapse Spark.
| Pula platformy Spark | Obsługiwane tożsamości | Tożsamość domyślna |
|---|---|---|
| Bezserwerowe obliczenia platformy Spark | Tożsamość użytkownika, tożsamość zarządzana przypisana przez użytkownika dołączona do obszaru roboczego | Tożsamość użytkownika |
| Dołączona pula platformy Synapse Spark | Tożsamość użytkownika, tożsamość zarządzana przypisana przez użytkownika dołączona do dołączonej puli platformy Synapse Spark, przypisana przez system tożsamość zarządzana dołączonej puli usługi Synapse Spark | Tożsamość zarządzana przypisana przez system dołączonej puli usługi Synapse Spark |
Jeśli interfejs wiersza polecenia lub kod zestawu SDK definiuje opcję używania tożsamości zarządzanej, przetwarzanie bezserwerowe platformy Spark w usłudze Azure Machine Learning opiera się na tożsamości zarządzanej przypisanej przez użytkownika dołączonej do obszaru roboczego. Tożsamość zarządzaną przypisaną przez użytkownika można dołączyć do istniejącego obszaru roboczego usługi Azure Machine Learning przy użyciu interfejsu wiersza polecenia usługi Azure Machine Learning w wersji 2 lub za pomocą polecenia ARMClient.
Następne kroki
- Platforma Apache Spark w usłudze Azure Machine Learning
- Dołączanie puli platformy Spark usługi Synapse Spark i zarządzanie nią w usłudze Azure Machine Learning
- Interakcyjne rozmieszczanie danych za pomocą platformy Apache Spark w usłudze Azure Machine Learning
- Przesyłanie zadań platformy Spark w usłudze Azure Machine Learning
- Przykłady kodu dla zadań platformy Spark przy użyciu interfejsu wiersza polecenia usługi Azure Machine Learning
- Przykłady kodu dla zadań platformy Spark przy użyciu zestawu SDK języka Python usługi Azure Machine Learning