Wysoka dostępność i odzyskiwanie po awarii usługi IoT Hub
Pierwszym krokiem do wdrożenia odpornego rozwiązania IoT, architektów, deweloperów i właścicieli firm musi zdefiniować cele czasu pracy dla rozwiązań, które tworzą. Te cele można zdefiniować przede wszystkim na podstawie określonych celów biznesowych dla każdego scenariusza. W tym kontekście w artykule Azure Business Continuity Technical Guidance (Wskazówki techniczne dotyczące ciągłości działania platformy Azure) opisano ogólne ramy ułatwiające przemyślenie ciągłości działania i odzyskiwania po awarii. Dokument Odzyskiwanie po awarii i wysoka dostępność aplikacji platformy Azure zawiera wskazówki dotyczące architektury strategii dla aplikacji platformy Azure w celu osiągnięcia wysokiej dostępności i odzyskiwania po awarii (DR).
W tym artykule omówiono funkcje wysokiej dostępności i odzyskiwania po awarii oferowane specjalnie przez usługę IoT Hub. Szerokie obszary omówione w tym artykule to:
- Wysoka dostępność wewnątrz regionu
- Odzyskiwanie po awarii między regionami
- Uzyskiwanie wysokiej dostępności między regionami
W zależności od celów czasu pracy zdefiniowanych dla rozwiązań IoT należy określić, które opcje opisane w tym artykule najlepiej odpowiadają celom biznesowym. Włączenie dowolnej z tych alternatyw wysokiej dostępności/odzyskiwania po awarii do rozwiązania IoT wymaga starannej oceny kompromisów między:
- Wymagany poziom odporności
- Złożoność implementacji i konserwacji
- Wpływ coGS
Wysoka dostępność wewnątrz regionu
Usługa IoT Hub zapewnia wysoką dostępność wewnątrz regionu przez zaimplementowanie nadmiarowości we wszystkich warstwach usługi. Umowa SLA opublikowana przez usługę IoT Hub jest osiągana przez zastosowanie tych nadmiarowości. Deweloperzy rozwiązania IoT nie wymagają dodatkowej pracy, aby korzystać z tych funkcji wysokiej dostępności. Mimo że usługa IoT Hub oferuje dość wysoką gwarancję czasu pracy, błędy przejściowe nadal mogą być oczekiwane zgodnie z dowolną rozproszoną platformą obliczeniową. Jeśli dopiero zaczynasz migrować rozwiązania do chmury z rozwiązania lokalnego, należy skoncentrować się na optymalizacji "średniego czasu między awariami" do "średniego czasu odzyskiwania". Innymi słowy, błędy przejściowe należy traktować jako normalne podczas pracy z chmurą w połączeniu. Odpowiednie wzorce ponawiania prób muszą być wbudowane w składniki wchodzące w interakcję z aplikacją w chmurze w celu radzenia sobie z przejściowymi awariami.
Strefy dostępności
Usługa IoT Hub obsługuje strefy dostępności platformy Azure. Strefa dostępności to oferta wysokiej dostępności, która chroni aplikacje i dane przed awariami centrum danych. Region z obsługą strefy dostępności obejmuje trzy strefy obsługujące ten region. Każda strefa zapewnia co najmniej jedno centrum danych, z których każda znajduje się w unikatowej lokalizacji fizycznej z niezależnym zasilaniem, chłodzeniem i siecią. Ta konfiguracja zapewnia replikację i nadmiarowość w regionie.
Strefy dostępności zapewniają dwie zalety: odporność danych i bezproblemowe wdrożenia.
Odporność danych pochodzi z zastępowania bazowych usług magazynu magazynem obsługiwanym przez strefy dostępności. Odporność danych jest ważna dla rozwiązań IoT, ponieważ te rozwiązania często działają w złożonych, dynamicznych i niepewnych środowiskach, w których awarie lub zakłócenia mogą mieć poważne konsekwencje. Niezależnie od tego, czy rozwiązanie IoT obsługuje środowiska produkcyjne, detaliczne lub restauracje, systemy opieki zdrowotnej lub infrastrukturę, dostępność i jakość danych jest niezbędna do odzyskania sprawności po awariach oraz zapewnienia niezawodnych i spójnych usług.
Bezproblemowe wdrożenia pochodzą z zastąpienia podstawowego sprzętu centrum danych nowszym sprzętem obsługującym strefy dostępności. Te ulepszenia sprzętu minimalizują wpływ klientów z urządzeń na rozłączanie i ponowne nawiązywanie połączeń, a także inne przestoje związane z wdrażaniem. Zespół inżynierów usługi IoT Hub wdraża wiele aktualizacji w każdym centrum IoT w historii miesiąca ze względów bezpieczeństwa i zapewnia ulepszenia funkcji. Sprzęt obsługiwany przez strefy dostępności jest podzielony na 15 domen aktualizacji, aby każda aktualizacja przebiegała sprawniej, przy minimalnym wpływie na przepływy pracy. Aby uzyskać więcej informacji na temat domen aktualizacji, zobacz Zestawy dostępności.
Obsługa strefy dostępności dla usługi IoT Hub jest włączana automatycznie dla nowych zasobów usługi IoT Hub utworzonych w następujących regionach świadczenia usługi Azure:
| Region (Region) | Odporność danych | Bezproblemowe wdrożenia |
|---|---|---|
| Australia Wschodnia | ||
| Brazylia Południowa | ||
| Kanada Środkowa | ||
| Indie Środkowe | ||
| Central US | ||
| East US | ||
| Francja Środkowa | ||
| Niemcy Środkowo-Zachodnie | ||
| Japonia Wschodnia | ||
| Korea Środkowa | ||
| Europa Północna | ||
| Norwegia Wschodnia | ||
| Katar Środkowy | ||
| Południowo-środkowe stany USA | ||
| Southeast Asia | ||
| Południowe Zjednoczone Królestwo | ||
| West Europe | ||
| Zachodnie stany USA 2 | ||
| Zachodnie stany USA 3 |
Odzyskiwanie po awarii między regionami
Może wystąpić kilka rzadkich sytuacji, gdy centrum danych doświadcza rozszerzonych awarii z powodu awarii zasilania lub innych awarii obejmujących zasoby fizyczne. Takie zdarzenia są rzadkie, podczas których opisana wcześniej funkcja wysokiej dostępności w regionie wewnątrz regionu może nie zawsze pomóc. Usługa IoT Hub udostępnia wiele rozwiązań do odzyskiwania po takich rozszerzonych awariach.
Opcje odzyskiwania dostępne dla klientów w takiej sytuacji to zainicjowane przez firmę Microsoft tryb failover i ręczne przejście w tryb failover. Podstawową różnicą między nimi jest to, że firma Microsoft inicjuje ten pierwszy, a użytkownik inicjuje tę drugą. Ponadto ręczne przechodzenie w tryb failover zapewnia niższy cel czasu odzyskiwania (RTO) w porównaniu z opcją trybu failover zainicjowaną przez firmę Microsoft. Określone obiekty RTO oferowane z każdą opcją zostały omówione w poniższych sekcjach. Po wykonaniu jednej z tych opcji przejścia w tryb failover centrum IoT z regionu podstawowego centrum staje się w pełni funkcjonalne w odpowiednim regionie sparowanym geograficznie na platformie Azure.
Obie te opcje trybu failover oferują następujące cele punktu odzyskiwania (RPO):
| Typ danych | Cele punktu odzyskiwania (RPO) |
|---|---|
| Rejestr tożsamości | 0–5 minut utraty danych |
| Dane bliźniaczej reprezentacji urządzenia | 0–5 minut utraty danych |
| Komunikatyz chmury do urządzenia 1 | 0–5 minut utraty danych |
| Zadania nadrzędne1 i urządzenia | 0–5 minut utraty danych |
| Komunikaty z urządzenia do chmury | Wszystkie nieprzeczytane wiadomości zostaną utracone |
| Komunikaty zwrotne z chmury do urządzenia | Wszystkie nieprzeczytane wiadomości zostaną utracone |
1Komunikaty z chmury do urządzenia i zadania nadrzędne nie są odzyskiwane w ramach ręcznego przejścia w tryb failover.
Po zakończeniu operacji trybu failover dla centrum IoT wszystkie operacje z urządzenia i aplikacji zaplecza powinny kontynuować pracę bez konieczności ręcznej interwencji. Oznacza to, że komunikaty z urządzenia do chmury powinny nadal działać, a cały rejestr urządzeń jest nienaruszony. Zdarzenia emitowane za pośrednictwem usługi Event Grid mogą być używane za pośrednictwem tych samych subskrypcji skonfigurowanych wcześniej, o ile te subskrypcje usługi Event Grid będą nadal dostępne. W przypadku niestandardowych punktów końcowych nie jest wymagana żadna dodatkowa obsługa.
Uwaga
- Nazwa zgodna z usługą Event Hubs i punkt końcowy wbudowanego punktu końcowego zdarzeń usługi IoT Hub zmieni się po przejściu w tryb failover. W przypadku odbierania komunikatów telemetrycznych z wbudowanego punktu końcowego przy użyciu klienta usługi Event Hubs lub hosta procesora zdarzeń należy użyć centrum IoT hub parametry połączenia do nawiązania połączenia. Dzięki temu aplikacje zaplecza będą nadal działać bez konieczności ręcznej interwencji po przejściu w tryb failover. Jeśli używasz bezpośrednio nazwy i punktu końcowego zgodnego z centrum zdarzeń w aplikacji, musisz pobrać nowy punkt końcowy zgodny z centrum zdarzeń po przejściu w tryb failover, aby kontynuować operacje. Aby uzyskać więcej informacji, zobacz Ręczne przechodzenie w tryb failover i centrum zdarzeń.
- Jeśli używasz usługi Azure Functions lub Azure Stream Analytics do łączenia wbudowanego punktu końcowego zdarzeń, może być konieczne ponowne uruchomienie. Dzieje się tak, ponieważ podczas poprzednich przesunięć trybu failover nie są już prawidłowe.
- Podczas routingu do magazynu zalecamy wyświetlenie listy obiektów blob lub plików, a następnie iterowanie nad nimi, aby upewnić się, że wszystkie obiekty blob lub pliki są odczytywane bez wprowadzania żadnych założeń partycji. Zakres partycji może potencjalnie ulec zmianie podczas trybu failover zainicjowanego przez firmę Microsoft lub ręcznego przejścia w tryb failover. Interfejs API list blobs umożliwia wyliczenie listy obiektów blob lub interfejsu API list ADLS Gen2 dla listy plików. Aby dowiedzieć się więcej, zobacz Azure Storage jako punkt końcowy routingu.
Tryb failover inicjowany przez firmę Microsoft
Zainicjowane przez firmę Microsoft tryb failover jest wykonywane przez firmę Microsoft w rzadkich sytuacjach przełączania w tryb failover wszystkich centrów IoT z regionu, którego dotyczy problem, do odpowiedniego regionu sparowanego geograficznie. Ten proces jest opcją domyślną i nie wymaga interwencji użytkownika. Firma Microsoft zastrzega sobie prawo do ustalenia, kiedy ta opcja zostanie wykonana. Ten mechanizm nie obejmuje zgody użytkownika, zanim centrum użytkownika zostanie przełączone w tryb failover. Tryb failover zainicjowany przez firmę Microsoft ma cel czasu odzyskiwania (RTO) 2–26 godzin.
Duży cel czasu odzyskiwania jest spowodowany tym, że firma Microsoft musi wykonać operację trybu failover w imieniu wszystkich dotkniętych klientów w tym regionie. Jeśli korzystasz z mniej krytycznego rozwiązania IoT, które może utrzymać przestój w przybliżeniu dziennie, możesz podjąć zależność od tej opcji, aby spełnić ogólne cele odzyskiwania po awarii dla rozwiązania IoT. Łączny czas wykonywania operacji w pełni operacyjny po wyzwoleniu tego procesu jest opisany w sekcji "Czas odzyskiwania".
Tylko użytkownicy wdrażający centra IoT w regionach Brazylii Południowej i Azji Południowo-Wschodniej (Singapur) mogą zrezygnować z tej funkcji. Aby uzyskać więcej informacji, zobacz Wyłączanie odzyskiwania po awarii.
Uwaga
Usługa Azure IoT Hub nie przechowuje ani nie przetwarza danych klientów poza lokalizacją geograficzną, w której wdrażasz wystąpienie usługi. Aby uzyskać więcej informacji, zobacz Replikacja między regionami na platformie Azure.
Ręczne przełączenie w tryb failover
Jeśli cele czasu pracy twojej firmy nie są spełnione przez cel czasu odzyskiwania zapewniany przez firmę Microsoft zainicjowany tryb failover, rozważ użycie ręcznego przejścia w tryb failover w celu samodzielnego wyzwolenia procesu pracy w trybie failover. Cel czasu odzyskiwania przy użyciu tej opcji może być w dowolnym miejscu od 10 minut do kilku godzin. Cel czasu odzyskiwania jest obecnie funkcją liczby urządzeń zarejestrowanych w wystąpieniu centrum IoT w trybie failover. Cel czasu odzyskiwania dla centrum hostujące około 100 000 urządzeń będzie w ballpark 15 minut. Łączny czas wykonywania operacji w pełni operacyjny po wyzwoleniu tego procesu jest opisany w sekcji "Czas odzyskiwania".
Opcja ręcznego przejścia w tryb failover jest zawsze dostępna do użycia niezależnie od tego, czy w regionie podstawowym występuje przestój, czy nie. W związku z tym ta opcja może być potencjalnie używana do przeprowadzania planowanych przełączeń w tryb failover. Przykładem użycia planowanych trybów failover jest wykonanie okresowych przechodzenia w tryb failover. Słowem ostrożności jest to, że planowana operacja trybu failover powoduje przestój centrum przez okres zdefiniowany przez cel czasu odzyskiwania dla tej opcji, a także powoduje utratę danych zgodnie z definicją w powyższej tabeli celu punktu odzyskiwania. Możesz rozważyć skonfigurowanie testowego wystąpienia usługi IoT Hub w celu okresowego wykonywania planowanej opcji trybu failover, aby mieć pewność, że masz możliwość uzyskania kompleksowego rozwiązania i uruchomienia w przypadku wystąpienia rzeczywistej awarii.
Ręczne przechodzenie w tryb failover jest dostępne bez dodatkowych kosztów dla centrów IoT utworzonych po 18 maja 2017 r.
Aby uzyskać instrukcje krok po kroku, zobacz Samouczek: ręczne przechodzenie w tryb failover dla centrum IoT
Ręczne przechodzenie w tryb failover i usługa Event Hubs
Nazwa zgodna z usługą Event Hubs i punkt końcowy wbudowanego punktu końcowego zdarzeń usługi IoT Hub zmienia się po ręcznym przejściu w tryb failover. Dzieje się tak, ponieważ klient usługi Event Hubs nie ma wglądu w zdarzenia usługi IoT Hub. To samo dotyczy innych klientów opartych na chmurze, takich jak funkcje i usługa Azure Stream Analytics. Aby pobrać punkt końcowy i nazwę, możesz użyć witryny Azure Portal lub zestawu .NET SDK.
Używanie portalu
Aby uzyskać więcej informacji na temat pobierania punktu końcowego zgodnego z centrum zdarzeń i nazwy zgodnej z centrum zdarzeń, zobacz Nawiązywanie połączenia z wbudowanym punktem końcowym.
Korzystanie z zestawu SDK dla platformy .NET
Aby użyć usługi IoT Hub parametry połączenia do odzyskania punktu końcowego zgodnego z usługą Event Hubs, użyj przykładu znajdującego się w https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubslokalizacji . W przykładzie kodu użyto parametry połączenia, aby uzyskać nowy punkt końcowy usługi Event Hubs i ponownie ustanowić połączenie. Musisz mieć zainstalowany program Visual Studio.
Uruchamianie próbnych testów
Nie należy wykonywać próbnych testów w centrach IoT, które są używane w środowiskach produkcyjnych.
Nie używaj ręcznego trybu failover do migrowania centrum IoT Hub do innego regionu
Ręczne przechodzenie w tryb failover nie powinno być używane jako mechanizm trwałej migracji centrum między sparowanymi regionami geograficznymi platformy Azure. Zakładając, że urządzenia znajdowały się najbliżej regionu podstawowego centrum, opóźnienie operacji wykonywanych względem centrum IoT Hub zwiększy się, gdy centrum przejdzie w tryb failover do regionu pomocniczego.
Powrót po awarii
Możesz wrócić po awarii do starego regionu podstawowego, wyzwalając akcję trybu failover po raz drugi. Jeśli oryginalna operacja przejścia w tryb failover została wykonana w celu odzyskania po rozszerzonej awarii w oryginalnym regionie podstawowym, zalecamy, aby centrum zostało przywrócone do oryginalnej lokalizacji po odzyskaniu tej lokalizacji po awarii.
Ważne
- Użytkownicy mogą wykonywać tylko 2 pomyślne operacje pracy w trybie failover i 2 pomyślne operacje powrotu po awarii dziennie.
- Operacje powrotu do trybu failover/powrotu po awarii są niedozwolone. Musisz odczekać 1 godzinę między tymi operacjami.
Czas odzyskiwania sprawności
Chociaż nazwa FQDN (i w związku z tym parametry połączenia) wystąpienia usługi IoT Hub pozostaje taka sama po przejściu w tryb failover, podstawowy adres IP ulegnie zmianie. Czas wykonywania operacji wykonywanych względem wystąpienia usługi IoT Hub w celu pełnego działania po zakończeniu procesu pracy w trybie failover można wyrazić przy użyciu następującej funkcji:
Czas odzyskiwania = cel czasu odzyskiwania [10 minut - 2 godziny ręcznego przejścia w tryb failover | 2– 26 godzin dla trybu failover zainicjowanego przez firmę Microsoft] + opóźnienie propagacji DNS i czas potrzebny aplikacji klienckiej na odświeżenie dowolnego buforowanego adresu IP usługi IoT Hub.
Ważne
Zestawy SDK IoT nie buforują adresu IP centrum IoT. Zalecamy, aby kod użytkownika współdziałał z zestawami SDK, nie powinien buforować adresu IP centrum IoT.
Wyłączanie odzyskiwania po awarii
Usługa IoT Hub udostępnia tryb failover zainicjowany przez firmę Microsoft i ręczne przejście w tryb failover przez replikowanie danych do sparowanego regionu dla każdego centrum IoT. W przypadku niektórych regionów można uniknąć replikacji danych poza regionem, wyłączając odzyskiwanie po awarii podczas tworzenia centrum IoT. Następujące regiony obsługują tę funkcję:
- Brazylia Południowa; sparowany region, Południowo-środkowe stany USA.
- Azja Południowo-Wschodnia (Singapur); sparowany region, Azja Wschodnia (Hongkong SAR).
Aby wyłączyć odzyskiwanie po awarii w obsługiwanych regionach, upewnij się, że włączone odzyskiwanie po awarii jest niezaznaczone podczas tworzenia centrum IoT:
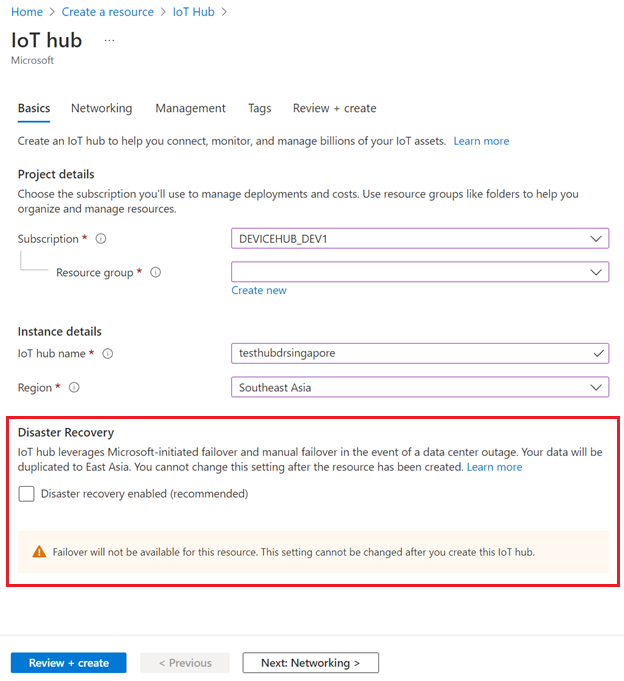
Odzyskiwanie po awarii można również wyłączyć podczas tworzenia centrum IoT Hub przy użyciu szablonu usługi ARM.
Funkcja trybu failover nie będzie dostępna, jeśli wyłączysz odzyskiwanie po awarii dla centrum IoT.
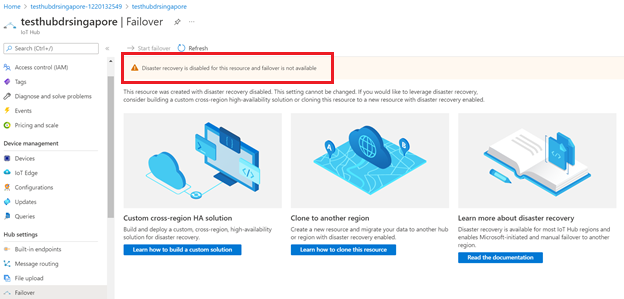
Odzyskiwanie po awarii można wyłączyć tylko w celu uniknięcia replikacji danych poza sparowanym regionem w Brazylii Południowej lub Azji Południowo-Wschodniej podczas tworzenia centrum IoT. Jeśli chcesz skonfigurować istniejące centrum IoT w celu wyłączenia odzyskiwania po awarii, musisz utworzyć nowe centrum IoT z wyłączonym odzyskiwaniem po awarii i ręcznie przeprowadzić migrację istniejącego centrum IoT. Aby uzyskać wskazówki, zobacz Jak przeprowadzić migrację centrum IoT Hub.
Uzyskiwanie wysokiej dostępności między regionami
Jeśli cele czasu pracy w firmie nie są spełnione przez cel czasu odzyskiwania, który zapewnia zainicjowany przez firmę Microsoft tryb failover lub ręczne przejście w tryb failover, należy rozważyć zaimplementowanie automatycznego mechanizmu trybu failover dla poszczególnych urządzeń. Pełne traktowanie topologii wdrażania w rozwiązaniach IoT wykracza poza zakres tego artykułu. W tym artykule omówiono regionalny model wdrażania trybu failover na potrzeby wysokiej dostępności i odzyskiwania po awarii.
W regionalnym modelu trybu failover zaplecze rozwiązania działa głównie w jednej lokalizacji centrum danych. Pomocnicze centrum IoT i zaplecze są wdrażane w innej lokalizacji centrum danych. Jeśli centrum IoT w regionie podstawowym ulegnie awarii lub połączenie sieciowe z urządzenia do regionu podstawowego zostanie przerwane, urządzenia używają pomocniczego punktu końcowego usługi. Dostępność rozwiązania można poprawić, implementując model trybu failover między regionami zamiast pozostawać w jednym regionie.
Aby zaimplementować regionalny model trybu failover za pomocą usługi IoT Hub, należy wykonać następujące czynności:
Pomocnicza usługa IoT Hub i logika routingu urządzeń: jeśli usługa w regionie podstawowym zostanie przerwana, urządzenia muszą zacząć łączyć się z regionem pomocniczym. Ze względu na stanową naturę większości zaangażowanych usług często administratorzy rozwiązań mogą wyzwolić proces pracy w trybie failover między regionami. Najlepszym sposobem komunikowania nowego punktu końcowego z urządzeniami przy zachowaniu kontroli nad procesem jest regularne sprawdzanie usługi concierge dla bieżącego aktywnego punktu końcowego. Usługa concierge może być aplikacją internetową, która jest replikowana i osiągalna przy użyciu technik przekierowania DNS (na przykład przy użyciu usługi Azure Traffic Manager).
Uwaga
Usługa IoT Hub nie jest obsługiwanym typem punktu końcowego w usłudze Azure Traffic Manager. Zaleceniem jest zintegrowanie proponowanej usługi concierge z usługą Azure Traffic Manager przez zaimplementowanie interfejsu API sondy kondycji punktu końcowego.
Replikacja rejestru tożsamości: aby można było używać, pomocnicze centrum IoT musi zawierać wszystkie tożsamości urządzeń, które mogą łączyć się z rozwiązaniem. Rozwiązanie powinno przechowywać geograficznie replikowane kopie zapasowe tożsamości urządzeń i przekazywać je do pomocniczego centrum IoT przed przełączeniem aktywnego punktu końcowego dla urządzeń. Funkcja eksportowania tożsamości urządzenia usługi IoT Hub jest przydatna w tym kontekście. Aby uzyskać więcej informacji, zobacz Przewodnik dewelopera usługi IoT Hub — rejestr tożsamości.
Logika scalania: gdy region podstawowy stanie się ponownie dostępny, wszystkie stany i dane utworzone w lokacji dodatkowej muszą zostać zmigrowane z powrotem do regionu podstawowego. Ten stan i dane dotyczą głównie tożsamości urządzeń i metadanych aplikacji, które muszą zostać scalone z podstawowym centrum IoT i innymi magazynami specyficznymi dla aplikacji w regionie podstawowym.
Aby uprościć ten krok, należy użyć operacji idempotentnych. Operacje idempotentne minimalizują skutki uboczne z ostatecznej spójnej dystrybucji zdarzeń oraz z duplikatów lub dostarczania zdarzeń poza kolejnością. Ponadto logika aplikacji powinna być zaprojektowana tak, aby tolerowała potencjalne niespójności lub nieco nieaktualny stan. Taka sytuacja może wystąpić z powodu dodatkowego czasu potrzebny na uzdrowienie systemu na podstawie celów punktu odzyskiwania (RPO).
Wybieranie odpowiedniej opcji wysokiej dostępności/odzyskiwania po awarii
Poniżej przedstawiono podsumowanie opcji wysokiej dostępności/odzyskiwania po awarii przedstawionych w tym artykule, które mogą służyć jako ramka odwołania do wyboru odpowiedniej opcji, która działa dla twojego rozwiązania.
| Opcja wysokiej dostępności/odzyskiwania po awarii | RTO | RPO | Wymaga interwencji ręcznej? | Złożoność implementacji | Wpływ na koszty |
|---|---|---|---|---|---|
| Tryb failover inicjowany przez firmę Microsoft | 2 – 26 godzin | Zapoznaj się z tabelą celu punktu odzyskiwania powyżej | Nie. | Brak | Brak |
| Ręczne przełączenie w tryb failover | 10 min - 2 godziny | Zapoznaj się z tabelą celu punktu odzyskiwania powyżej | Tak | Bardzo niskie. Tę operację należy wyzwolić tylko z poziomu portalu. | Brak |
| Wysoka dostępność między regionami | < 1 min | Zależy od częstotliwości replikacji niestandardowego rozwiązania wysokiej dostępności | Nie. | Wys. | > 1x koszt 1 centrum IoT Hub |