Samouczek: ładowanie danych i uruchamianie zapytań w klastrze Apache Spark w usłudze Azure HDInsight
W tym samouczku dowiesz się, jak utworzyć ramkę danych na podstawie pliku CSV i uruchamiać interakcyjne zapytania Spark SQL względem klastra Apache Spark w usłudze Azure HDInsight. Na platformie Spark ramka danych jest rozproszoną kolekcją danych zorganizowanych w nazwanych kolumnach. Jest równoważna tabeli w relacyjnej bazie danych lub ramce danych w języku R/Python.
Z tego samouczka dowiesz się, jak wykonywać następujące czynności:
- Tworzenie ramki danych z pliku csv
- Uruchamianie zapytań na ramce danych
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Zobacz Tworzenie klastra Apache Spark.
Tworzenie notesu Jupyter
Jupyter Notebook to interakcyjne środowisko notesu, które obsługuje różne języki programowania. Notes pozwala na interakcję z danymi, łączenie kodu z tekstem markdown i wykonywanie prostych wizualizacji.
Edytuj adres URL
https://SPARKCLUSTER.azurehdinsight.net/jupyter, zastępującSPARKCLUSTERciąg nazwą klastra Spark. Następnie wprowadź edytowany adres URL w przeglądarce internetowej. Jeśli zostanie wyświetlony monit, wprowadź poświadczenia logowania dla klastra.Na stronie internetowej jupyter w przypadku klastrów Spark 2.4 wybierz pozycję Nowy>PySpark, aby utworzyć notes. W wersji Spark 3.1 wybierz pozycję Nowy>PySpark3, aby utworzyć notes, ponieważ jądro PySpark nie jest już dostępne na platformie Spark 3.1.
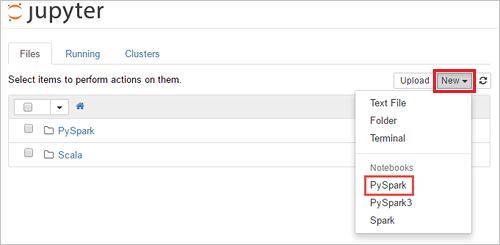
Zostanie utworzony i otwarty nowy notes o nazwie Untitled(
Untitled.ipynb).Uwaga
Korzystając z jądra PySpark lub PySpark3 w celu utworzenia notesu, sesja
sparkjest tworzona automatycznie podczas uruchamiania pierwszej komórki kodu. Nie jest konieczne jawne tworzenie sesji.
Tworzenie ramki danych z pliku csv
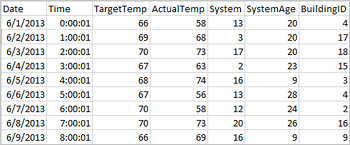
Aplikacje mogą tworzyć ramki danych bezpośrednio z plików lub folderów w magazynie zdalnym, takim jak Azure Storage lub Azure Data Lake Storage; z tabeli Programu Hive; lub z innych źródeł danych obsługiwanych przez platformę Spark, takich jak Azure Cosmos DB, Azure SQL DB, DW itd. Poniższy zrzut ekranu przedstawia migawkę pliku HVAC.csv używanego w tym samouczku. Plik csv jest zainstalowany na wszystkich klastrach HDInsight Spark. Dane dotyczą zmian temperatury w niektórych budynkach.
Wklej następujący kod w pustej komórce notesu Jupyter Notebook, a następnie naciśnij SHIFT + ENTER , aby uruchomić kod. Kod importuje typy wymagane w tym scenariuszu:
from pyspark.sql import * from pyspark.sql.types import *Po uruchomieniu interakcyjnego zapytania w programie Jupyter w oknie przeglądarki internetowej lub podpisie karty jest wyświetlany stan (Zajęty) wraz z tytułem notesu. Widoczne jest także pełne kółko obok tekstu PySpark w prawym górnym rogu. Po zakończeniu zadania zmienia się ono w pusty okrąg.
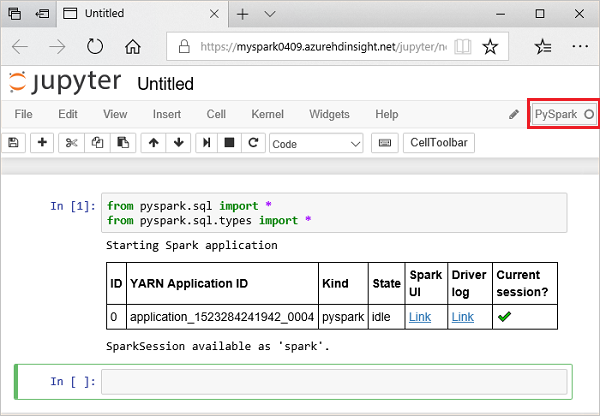
Zwróć uwagę na zwrócony identyfikator sesji. Na powyższym obrazie identyfikator sesji to 0. W razie potrzeby możesz pobrać szczegóły sesji, przechodząc do
https://CLUSTERNAME.azurehdinsight.net/livy/sessions/ID/statementslokalizacji, w której nazwa KLASTRA to nazwa klastra Spark, a identyfikator to numer identyfikatora sesji.Uruchom następujący kod, aby utworzyć ramkę danych i tabelę tymczasową (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write.saveAsTable("hvac")
Uruchamianie zapytań dotyczących elementu datanami
Po utworzeniu tabeli możesz uruchomić interakcyjne zapytanie na danych.
W pustej komórce notesu uruchom następujący kod:
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Zostanie wyświetlona następująca tabela danych wyjściowych.
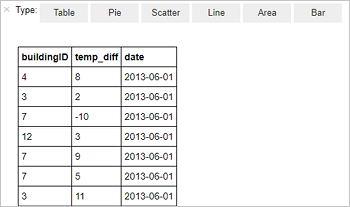
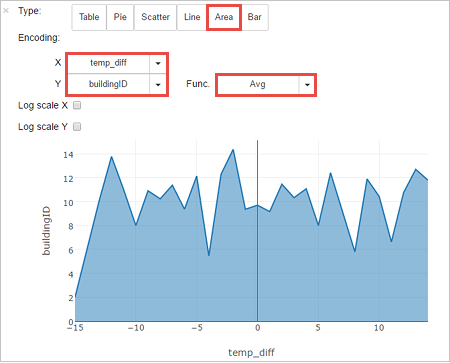
Wyniki można również przeglądać w postaci innych wizualizacji. Aby wyświetlić wykres warstwowy dla tych samych danych wyjściowych, wybierz pozycję Area (Obszar), a następnie ustaw inne wartości, jak pokazano poniżej.
Na pasku menu notesu przejdź do pozycji Plik>Zapisz i Punkt kontrolny.
Jeśli zamierzasz teraz otworzyć następny samouczek, pozostaw notes otwarty. Jeśli nie, zamknij notes, aby zwolnić zasoby klastra: na pasku menu notesu przejdź do pozycji Zamknij plik>i zatrzymaj.
Czyszczenie zasobów
W usłudze HDInsight dane i notesy Jupyter Notebook są przechowywane w usłudze Azure Storage lub Azure Data Lake Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane. Jeśli planujesz natychmiastowe rozpoczęcie pracy z następnym samouczkiem, warto zachować klaster.
Otwórz klaster w witrynie Azure Portal, a następnie wybierz pozycję Usuń.
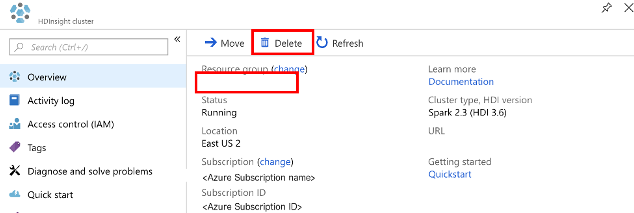
Dodatkowo możesz wybrać nazwę grupy zasobów, aby otworzyć stronę grupy zasobów, a następnie wybrać pozycję Usuń grupę zasobów. Usunięcie grupy zasobów powoduje usunięcie zarówno klastra Spark w usłudze HDInsight, jak i domyślnego konta magazynu.
Następne kroki
W tym samouczku przedstawiono sposób tworzenia ramki danych na podstawie pliku CSV oraz uruchamiania interakcyjnych zapytań Spark SQL względem klastra Apache Spark w usłudze Azure HDInsight. Przejdź do następnego artykułu, aby dowiedzieć się, w jaki sposób można ściągnąć dane zarejestrowane na platformie Apache Spark do narzędzia analizy biznesowej, takiego jak usługa Power BI.