Rozwiązywanie problemów z platformą YARN usługi Apache Hadoop za pomocą usługi Azure HDInsight
Dowiedz się więcej o najważniejszych problemach i ich rozwiązaniach podczas pracy z ładunkami apache Hadoop YARN w systemie Apache Ambari.
Jak mogę utworzyć nową kolejkę usługi YARN w klastrze?
Kroki umożliwiające rozwiązanie problemów
Wykonaj następujące kroki w narzędziu Ambari, aby utworzyć nową kolejkę usługi YARN, a następnie zrównoważyć alokację pojemności między wszystkimi kolejkami.
W tym przykładzie dwie istniejące kolejki (domyślne i thriftsvr) są zmieniane z 50% pojemności na 25%, co daje nową kolejkę (spark) 50% pojemności.
| Queue | Wydajność | Maksymalna pojemność |
|---|---|---|
| domyślna | 25% | 50% |
| thrftsvr | 25% | 50% |
| spark | 50% | 50% |
Wybierz ikonę Widoki ambari, a następnie wybierz wzorzec siatki. Następnie wybierz pozycję Menedżer kolejek usługi YARN.
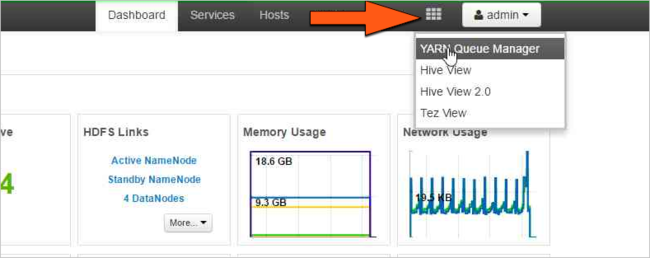
Wybierz kolejkę domyślną.
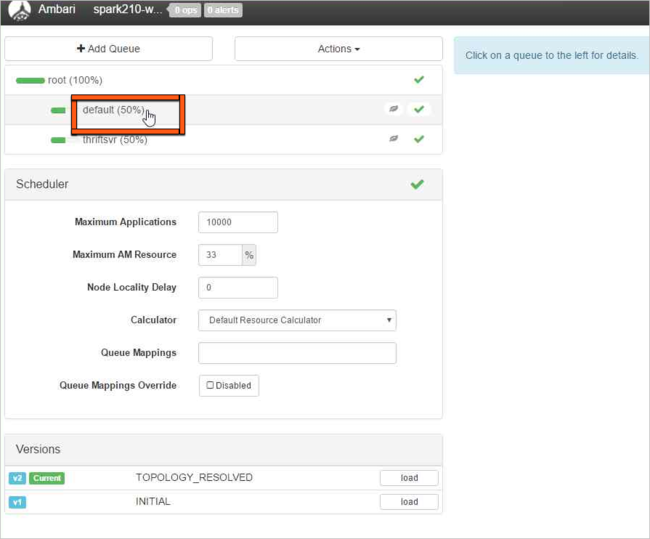
W przypadku kolejki domyślnej zmień pojemność z 50% na 25%. W przypadku kolejki thriftsvr zmień pojemność na 25%.
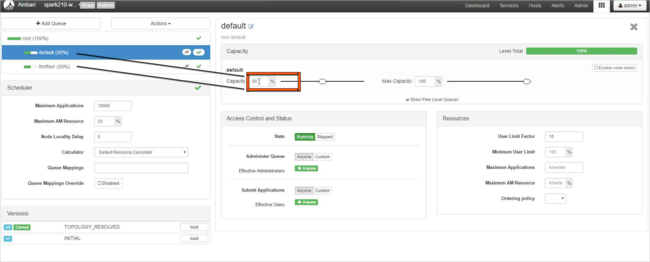
Aby utworzyć nową kolejkę, wybierz pozycję Dodaj kolejkę.
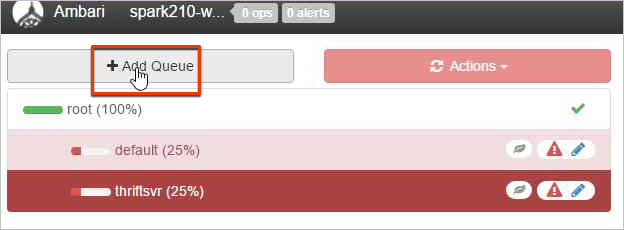
Nadaj nowej kolejce nazwę.
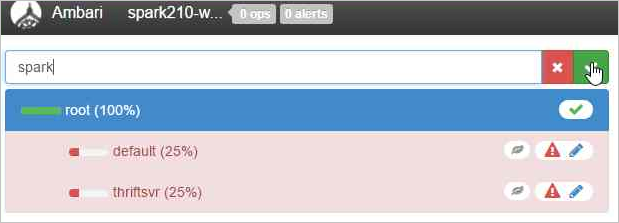
Pozostaw wartości pojemności na poziomie 50%, a następnie wybierz przycisk Akcje.
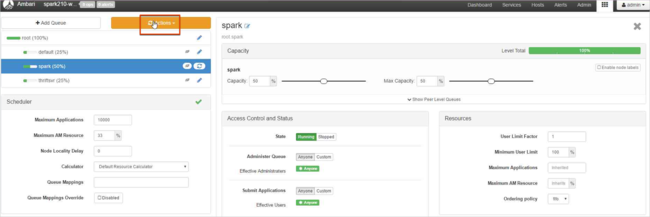
Wybierz pozycję Zapisz i odśwież kolejki.
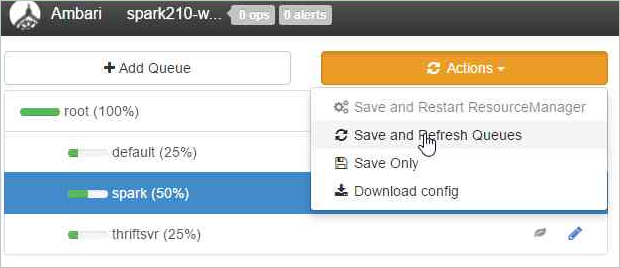
Te zmiany są widoczne natychmiast w interfejsie użytkownika harmonogramu usługi YARN.
Dalsze informacje
Jak mogę pobrać dzienniki usługi YARN z klastra?
Kroki umożliwiające rozwiązanie problemów
Nawiąż połączenie z klastrem usługi HDInsight przy użyciu klienta protokołu Secure Shell (SSH). Aby uzyskać więcej informacji, zobacz Dalsze informacje.
Aby wyświetlić listę wszystkich identyfikatorów aplikacji usługi YARN, które są aktualnie uruchomione, uruchom następujące polecenie:
yarn topIdentyfikatory są wyświetlane w kolumnie APPLICATIONID . Dzienniki można pobrać z kolumny APPLICATIONID .
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerAby pobrać dzienniki kontenera usługi YARN dla wszystkich wzorców aplikacji, użyj następującego polecenia:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtTo polecenie tworzy plik dziennika o nazwie amlogs.txt.
Aby pobrać dzienniki kontenera usługi YARN tylko dla najnowszego wzorca aplikacji, użyj następującego polecenia:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtTo polecenie tworzy plik dziennika o nazwie latestamlogs.txt.
Aby pobrać dzienniki kontenera usługi YARN dla dwóch pierwszych wzorców aplikacji, użyj następującego polecenia:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtTo polecenie tworzy plik dziennika o nazwie first2amlogs.txt.
Aby pobrać wszystkie dzienniki kontenerów usługi YARN, użyj następującego polecenia:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtTo polecenie tworzy plik dziennika o nazwie logs.txt.
Aby pobrać dziennik kontenera YARN dla określonego kontenera, użyj następującego polecenia:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtTo polecenie tworzy plik dziennika o nazwie containerlogs.txt.
Materiały uzupełniające
- Nawiązywanie połączenia z usługą HDInsight (Apache Hadoop) przy użyciu protokołu SSH
- Pojęcia i aplikacje usługi Apache Hadoop YARN
Jak mogę sprawdzić informacje diagnostyczne aplikacji usługi Yarn?
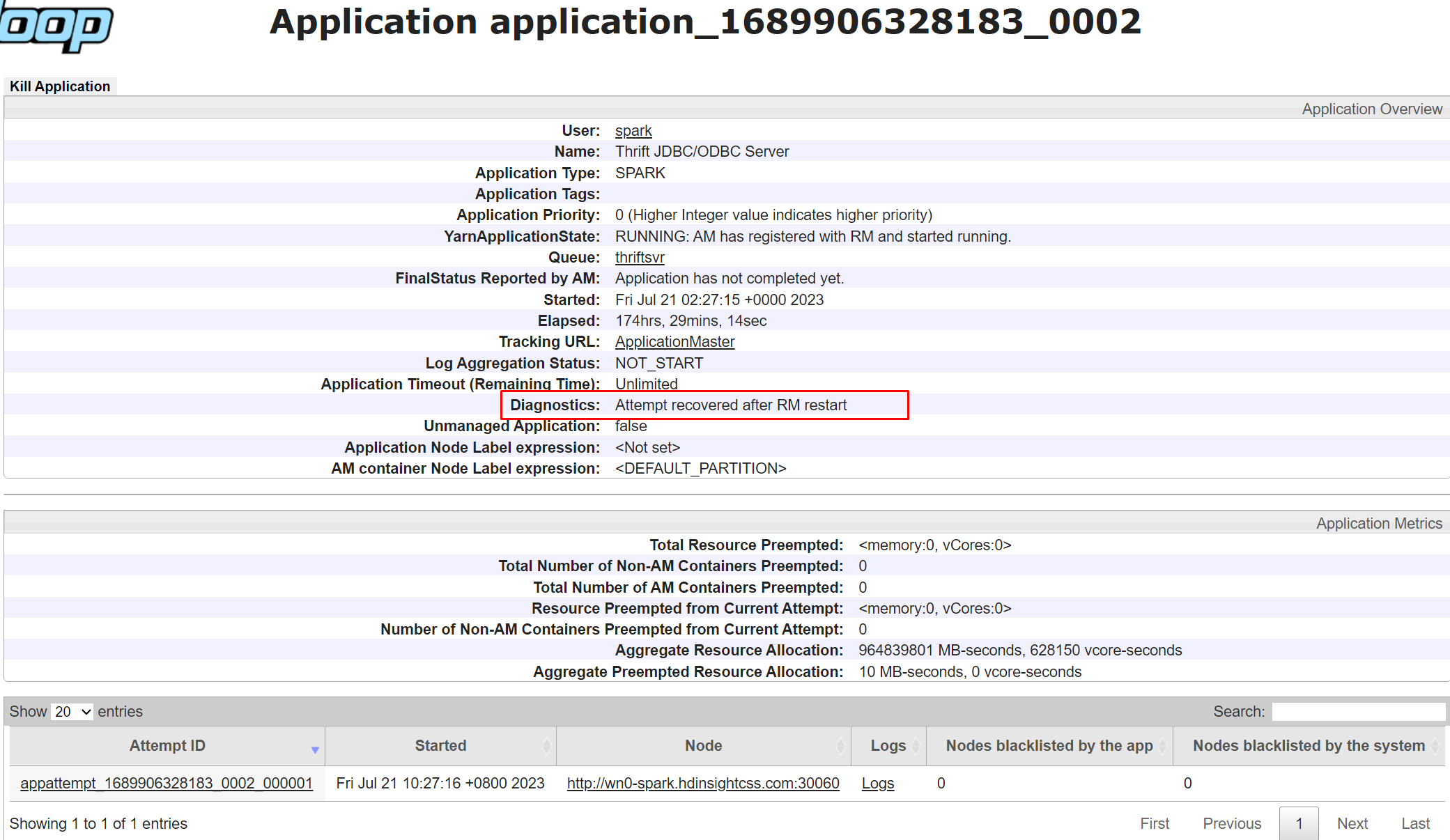
Diagnostyka w interfejsie użytkownika usługi Yarn to funkcja, która umożliwia wyświetlanie stanu i dzienników aplikacji uruchomionych w usłudze Yarn. Diagnostyka może ułatwić rozwiązywanie problemów i debugowanie aplikacji, a także monitorowanie ich wydajności i użycia zasobów.
Aby wyświetlić diagnostykę określonej aplikacji, możesz kliknąć identyfikator aplikacji na liście aplikacji. Na stronie szczegółów aplikacji można również wyświetlić listę wszystkich prób uruchomienia aplikacji. Możesz kliknąć dowolną próbę wyświetlenia dodatkowych szczegółów, takich jak identyfikator próby, identyfikator kontenera, identyfikator węzła, godzina rozpoczęcia, godzina zakończenia i diagnostyka
Jak mogę rozwiązać typowe problemy z usługą YARN?
Interfejs użytkownika usługi Yarn nie jest ładowany
Jeśli interfejs użytkownika usługi YARN nie jest ładowany lub nie jest osiągalny i zwraca komunikat "Błąd HTTP 502.3 — zła brama", oznacza to, że usługa Resource Manager jest w złej kondycji. Aby zminimalizować ten problem, wykonaj poniższe kroki:
- Przejdź do pozycji Ambari UI YARN SUMMARY (Podsumowanie YARN>interfejsu>użytkownika systemu Ambari) i sprawdź, czy tylko aktywna usługa Resource Manager jest w stanie Uruchomione. Jeśli nie, spróbuj rozwiązać ten problem, uruchamiając ponownie usługę Resource Manager w złej kondycji lub zatrzymając ją.
- Jeśli krok 1 nie rozwiąże problemu, SSH aktywny węzeł główny usługi Resource Manager i sprawdź stan odzyskiwania pamięci przy użyciu polecenia
jstat -gcutil <Resource Manager pid> 1000 100. Jeśli zobaczysz znaczny wzrost FGCT w ciągu zaledwie kilku sekund, oznacza to, że usługa Resource Manager jest zajęta w pełnej GC i nie może przetworzyć innych żądań. - Wybierz kolejno interfejs użytkownika systemu Ambari>YARN>KONFIGURACJE>Zaawansowane i zwiększ
Resource Manager java heap size. - Uruchom ponownie wymagane usługi w interfejsie użytkownika systemu Ambari.
Oba narzędzia Menedżer zasobów są zablokowane w trybie czuwania
- Sprawdź dziennik usługi Resource Manager, aby sprawdzić, czy istnieje podobny błąd.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Jeśli błąd istnieje, sprawdź, czy niektóre pliki są w trakcie replikacji lub czy brakuje bloków w systemie plików HDFS. Możesz uruchomić polecenie
hdfs fsck hdfs://mycluster/Uruchom
hdfs fsck hdfs://mycluster/ -deletezbyt wymuszone czyszczenie systemu plików HDFS i aby pozbyć się problemu z rezerwowym modułem RM. Alternatywnie uruchom polecenie PatchYarnNodeLabel w jednym z węzłów głównych, aby zastosować poprawkę klastra.
Następne kroki
Jeśli problem nie został wyświetlony lub nie możesz go rozwiązać, odwiedź jeden z następujących kanałów, aby uzyskać więcej pomocy technicznej:
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Nawiąż połączenie z @AzureSupport — oficjalnym kontem platformy Microsoft Azure, aby ulepszyć środowisko klienta. Łączenie społeczności platformy Azure z odpowiednimi zasobami: odpowiedziami, pomocą techniczną i ekspertami.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.