Operacjonalizacja potoku analizy danych
Potoki danych w wielu rozwiązaniach do analizy danych. Jak sugeruje nazwa, potok danych pobiera nieprzetworzone dane, czyści i zmienia je zgodnie z potrzebami, a następnie zazwyczaj wykonuje obliczenia lub agregacje przed zapisaniem przetworzonych danych. Przetworzone dane są używane przez klientów, raporty lub interfejsy API. Potok danych musi dostarczać powtarzalne wyniki, zarówno zgodnie z harmonogramem, jak i po wyzwoleniu przez nowe dane.
W tym artykule opisano sposób operacjonalizacji potoków danych w celu zapewnienia powtarzalności przy użyciu usługi Oozie działającego w klastrach hadoop usługi HDInsight. Przykładowy scenariusz przeprowadzi Cię przez potok danych, który przygotowuje i przetwarza dane szeregów czasowych lotów lotniczych.
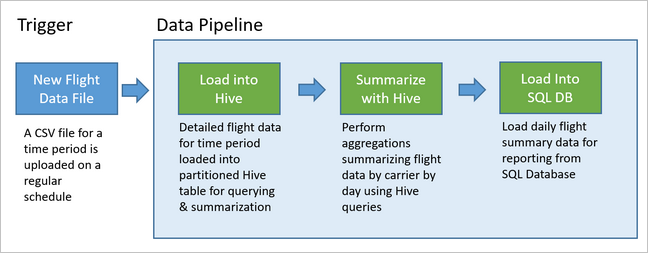
W poniższym scenariuszu dane wejściowe są plikiem płaskim zawierającym partię danych lotu przez jeden miesiąc. Te dane lotu obejmują informacje, takie jak lotnisko początkowe i docelowe, mile latane, czasy odlotu i przylotu itd. Celem tego potoku jest podsumowanie codziennych wyników linii lotniczych, gdzie każda linia lotnicza ma jeden wiersz dla każdego dnia ze średnim opóźnieniem odlotu i przylotu w minutach, a łączna liczba mil przeleciała tego dnia.
| YEAR | MONTH | DAY_OF_MONTH | PRZEWOŹNIK | AVG_DEP_DELAY | AVG_ARR_DELAY | TOTAL_DISTANCE |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
Przykładowy potok czeka na nadejście danych lotu nowego okresu, a następnie przechowuje szczegółowe informacje o locie w magazynie danych apache Hive na potrzeby długoterminowych analiz. Potok tworzy również znacznie mniejszy zestaw danych, który podsumowuje tylko codzienne dane lotu. Te codzienne dane podsumowania lotów są wysyłane do usługi SQL Database w celu dostarczania raportów, takich jak witryna internetowa.
Na poniższym diagramie przedstawiono przykładowy potok.
Omówienie rozwiązania Apache Oozie
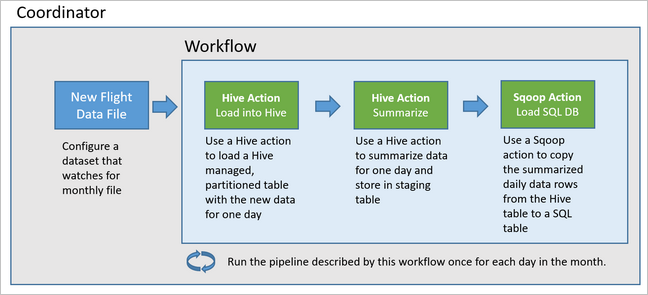
Ten potok używa systemu Apache Oozie działającego w klastrze usługi HDInsight Hadoop.
Oozie opisuje swoje potoki pod względem akcji, przepływów pracy i koordynatorów. Akcje określają rzeczywistą pracę do wykonania, taką jak uruchamianie zapytania hive. Przepływy pracy definiują sekwencję akcji. Koordynatorzy definiują harmonogram uruchamiania przepływu pracy. Koordynatorzy mogą również czekać na dostępność nowych danych przed uruchomieniem wystąpienia przepływu pracy.
Na poniższym diagramie przedstawiono ogólny projekt tego przykładowego potoku Oozie.
Aprowizuj zasoby platformy Azure
Ten potok wymaga usługi Azure SQL Database i klastra usługi HDInsight Hadoop w tej samej lokalizacji. Usługa Azure SQL Database przechowuje zarówno dane podsumowania utworzone przez potok, jak i magazyn metadanych Oozie.
Aprowizuj usługę Azure SQL Database
Tworzenie bazy danych Azure SQL Database. Zobacz Tworzenie bazy danych Azure SQL Database w witrynie Azure Portal.
Aby upewnić się, że klaster usługi HDInsight może uzyskać dostęp do połączonej usługi Azure SQL Database, skonfiguruj reguły zapory usługi Azure SQL Database, aby zezwolić usługom i zasobom platformy Azure na dostęp do serwera. Tę opcję można włączyć w witrynie Azure Portal, wybierając pozycję Ustaw zaporę serwera i wybierając pozycję WŁĄCZONE poniżej pozycji Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera dla usługi Azure SQL Database. Aby uzyskać więcej informacji, zobacz Tworzenie reguł zapory bazujących na adresach IP i zarządzanie nimi.
Użyj edytora zapytań, aby wykonać następujące instrukcje SQL, aby utworzyć tabelę
dailyflights, która będzie przechowywać podsumowane dane z każdego uruchomienia potoku.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Usługa Azure SQL Database jest teraz gotowa.
Aprowizuj klaster Apache Hadoop
Utwórz klaster Apache Hadoop z niestandardowym magazynem metadanych. Podczas tworzenia klastra z poziomu portalu na karcie Magazyn upewnij się, że wybrano bazę danych SQL Database w obszarze Ustawienia magazynu metadanych. Aby uzyskać więcej informacji na temat wybierania magazynu metadanych, zobacz Wybieranie niestandardowego magazynu metadanych podczas tworzenia klastra. Aby uzyskać więcej informacji na temat tworzenia klastra, zobacz Wprowadzenie do usługi HDInsight w systemie Linux.
Weryfikowanie konfiguracji tunelowania SSH
Aby wyświetlić stan wystąpień koordynatora i przepływu pracy za pomocą konsoli sieci Web Oozie, skonfiguruj tunel SSH w klastrze usługi HDInsight. Aby uzyskać więcej informacji, zobacz Tunel SSH.
Uwaga
Możesz również użyć przeglądarki Chrome z rozszerzeniem Foxy Proxy , aby przeglądać zasoby internetowe klastra w tunelu SSH. Skonfiguruj go do serwera proxy wszystkich żądań za pośrednictwem hosta localhost na porcie 9876 tunelu. Takie podejście jest zgodne z Podsystem Windows dla systemu Linux, znanym również jako Bash w systemie Windows 10.
Uruchom następujące polecenie, aby otworzyć tunel SSH w klastrze, gdzie
CLUSTERNAMEjest nazwą klastra:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netSprawdź, czy tunel działa, przechodząc do narzędzia Ambari w węźle głównym, przechodząc do:
http://headnodehost:8080Aby uzyskać dostęp do konsoli sieci Web Oozie z poziomu systemu Ambari, przejdź do pozycji Oozie>Quick Links> [Aktywny serwer]> Oozie Web UI.
Konfigurowanie programu Hive
Przekazywanie danych
Pobierz przykładowy plik CSV zawierający dane lotu przez jeden miesiąc. Pobierz plik
2017-01-FlightData.zipZIP z repozytorium GitHub usługi HDInsight i rozpakuj go do pliku2017-01-FlightData.csvCSV .Skopiuj ten plik CSV do konta usługi Azure Storage dołączonego do klastra usługi HDInsight i umieść go w folderze
/example/data/flights.Użyj punktu połączenia usługi , aby skopiować pliki z komputera lokalnego do lokalnego magazynu węzła głównego klastra usługi HDInsight.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvUżyj polecenia ssh, aby nawiązać połączenie z klastrem. Zmodyfikuj poniższe polecenie, zastępując
CLUSTERNAMEciąg nazwą klastra, a następnie wprowadź polecenie:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netZ poziomu sesji SSH użyj polecenia HDFS, aby skopiować plik z magazynu lokalnego węzła głównego do usługi Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Utwórz tabele
Przykładowe dane są teraz dostępne. Jednak potok wymaga dwóch tabel hive do przetwarzania, jeden dla danych przychodzących (rawFlights) i jeden dla podsumowanych danych (flights). Utwórz te tabele w narzędziu Ambari w następujący sposób.
Zaloguj się do systemu Ambari, przechodząc do
http://headnodehost:8080.Z listy usług wybierz pozycję Hive.
Wybierz pozycję Przejdź do widoku obok etykiety Widok hive 2.0.
W obszarze tekstowym zapytania wklej następujące instrukcje, aby utworzyć tabelę
rawFlights. TabelarawFlightszawiera schemat do odczytu plików CSV w folderze/example/data/flightsw usłudze Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Wybierz pozycję Wykonaj , aby utworzyć tabelę.
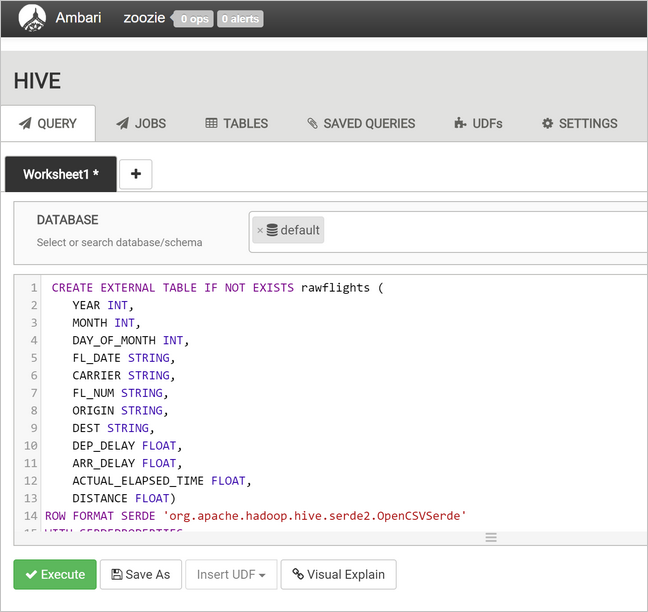
Aby utworzyć tabelę
flights, zastąp tekst w obszarze tekstu zapytania następującymi instrukcjami. Tabelaflightsjest tabelą zarządzaną przez program Hive, która partycjonuje dane załadowane do niej według roku, miesiąca i dnia miesiąca. Ta tabela będzie zawierać wszystkie dane historyczne dotyczące lotów, z najniższym poziomem szczegółowości w danych źródłowych jednego wiersza na lot.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Wybierz pozycję Wykonaj , aby utworzyć tabelę.
Tworzenie przepływu pracy Oozie
Potoki zwykle przetwarzają dane w partiach według danego interwału czasu. W takim przypadku potok przetwarza dane lotu codziennie. Takie podejście umożliwia pobieranie wejściowych plików CSV codziennie, co tydzień, co miesiąc lub co rok.
Przykładowy przepływ pracy przetwarza dane lotu dziennie w trzech głównych krokach:
- Uruchom zapytanie programu Hive, aby wyodrębnić dane z zakresu dat tego dnia z źródłowego pliku CSV reprezentowanego przez
rawFlightstabelę i wstawić dane doflightstabeli. - Uruchom zapytanie programu Hive, aby dynamicznie utworzyć tabelę przemieszczania w programie Hive dla dnia, która zawiera kopię danych lotu podsumowanych według dnia i operatora.
- Użyj narzędzia Apache Sqoop, aby skopiować wszystkie dane z dziennej tabeli przejściowej w programie Hive do tabeli docelowej
dailyflightsw usłudze Azure SQL Database. Narzędzie Sqoop odczytuje wiersze źródłowe z danych znajdujących się w tabeli Hive znajdującej się w usłudze Azure Storage i ładuje je do usługi SQL Database przy użyciu połączenia JDBC.
Te trzy kroki są koordynowane przez przepływ pracy Oozie.
Na lokalnej stacji roboczej utwórz plik o nazwie
job.properties. Użyj poniższego tekstu jako zawartości początkowej pliku. Następnie zaktualizuj wartości dla określonego środowiska. Poniższa tabela zawiera podsumowanie każdej właściwości i wskazuje, gdzie można znaleźć wartości dla własnego środowiska.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Właściwości Źródło wartości nameNode Pełna ścieżka do kontenera usługi Azure Storage dołączonego do klastra usługi HDInsight. jobTracker Wewnętrzna nazwa hosta do węzła głównego YARN aktywnego klastra. Na stronie głównej systemu Ambari wybierz pozycję YARN z listy usług, a następnie wybierz pozycję Active Resource Manager. Identyfikator URI nazwy hosta jest wyświetlany w górnej części strony. Dołącz port 8050. queueName Nazwa kolejki YARN używana podczas planowania akcji programu Hive. Pozostaw wartość domyślną. oozie.use.system.libpath Pozostaw wartość true. appBase Ścieżka do podfolderu w usłudze Azure Storage, w którym wdrażasz przepływ pracy Oozie i pliki pomocnicze. oozie.wf.application.path Lokalizacja przepływu pracy workflow.xmlOozie do uruchomienia.hiveScriptLoadPartition Ścieżka w usłudze Azure Storage do pliku hive-load-flights-partition.hqlzapytania hive .hiveScriptCreateDailyTable Ścieżka w usłudze Azure Storage do pliku hive-create-daily-summary-table.hqlzapytania hive .hiveDailyTableName Generowana dynamicznie nazwa do użycia dla tabeli przejściowej. hiveDataFolder Ścieżka w usłudze Azure Storage do danych zawartych w tabeli przejściowej. sqlDatabaseConnectionString Składnia JDBC parametry połączenia do usługi Azure SQL Database. sqlDatabaseTableName Nazwa tabeli w usłudze Azure SQL Database, do której są wstawione wiersze podsumowania. Pozostaw wartość dailyflights.rok Składnik roku dnia, dla którego są obliczane podsumowania lotów. Pozostaw w takiej postaci, w jakiej jest. miesiąca Składnik miesiąca dnia, dla którego są obliczane podsumowania lotów. Pozostaw w takiej postaci, w jakiej jest. dzień Składnik dnia miesiąca, dla którego są obliczane podsumowania lotów. Pozostaw w takiej postaci, w jakiej jest. Na lokalnej stacji roboczej utwórz plik o nazwie
hive-load-flights-partition.hql. Użyj poniższego kodu jako zawartości pliku.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Zmienne Oozie używają składni
${variableName}. Te zmienne są ustawiane wjob.propertiespliku. Oozie zastępuje rzeczywiste wartości w czasie wykonywania.Na lokalnej stacji roboczej utwórz plik o nazwie
hive-create-daily-summary-table.hql. Użyj poniższego kodu jako zawartości pliku.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};To zapytanie tworzy tabelę przejściową, która będzie przechowywać tylko podsumowane dane przez jeden dzień. Zanotuj instrukcję SELECT, która oblicza średnie opóźnienia i łączną odległość przepływaną przez operatora według dnia. Dane wstawione do tej tabeli przechowywane w znanej lokalizacji (ścieżka wskazywana przez zmienną hiveDataFolder), dzięki czemu mogą być używane jako źródło sqoop w następnym kroku.
Na lokalnej stacji roboczej utwórz plik o nazwie
workflow.xml. Użyj poniższego kodu jako zawartości pliku. Powyższe kroki są wyrażane jako oddzielne akcje w pliku przepływu pracy Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Do dwóch zapytań hive uzyskuje się dostęp przez ich ścieżkę w usłudze Azure Storage, a pozostałe wartości zmiennych są udostępniane przez job.properties plik. Ten plik konfiguruje przepływ pracy do uruchomienia dla daty 3 stycznia 2017 r.
Wdrażanie i uruchamianie przepływu pracy Oozie
Użyj usługi SCP z sesji powłoki bash, aby wdrożyć przepływ pracy Oozie (workflow.xml), zapytania Programu Hive (hive-load-flights-partition.hql i hive-create-daily-summary-table.hql) oraz konfigurację zadania (job.properties). W usłudze Oozie tylko job.properties plik może istnieć w lokalnym magazynie węzła głównego. Wszystkie inne pliki muszą być przechowywane w systemie plików HDFS, w tym przypadku w usłudze Azure Storage. Akcja Sqoop używana przez przepływ pracy zależy od sterownika JDBC do komunikacji z usługą SQL Database, który musi zostać skopiowany z węzła głównego do systemu plików HDFS.
load_flights_by_dayUtwórz podfolder pod ścieżką użytkownika w lokalnym magazynie węzła głównego. W otwartej sesji SSH wykonaj następujące polecenie:mkdir load_flights_by_daySkopiuj wszystkie pliki w bieżącym katalogu (pliki
workflow.xmlijob.properties) do podfolderuload_flights_by_day. Na lokalnej stacji roboczej wykonaj następujące polecenie:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_daySkopiuj pliki przepływu pracy do systemu plików HDFS. W otwartej sesji SSH wykonaj następujące polecenia:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_daySkopiuj
mssql-jdbc-7.0.0.jre8.jarz lokalnego węzła głównego do folderu przepływu pracy w systemie plików HDFS. Popraw polecenie zgodnie z potrzebami, jeśli klaster zawiera inny plik jar. Popraw wworkflow.xmlrazie potrzeby, aby odzwierciedlić inny plik jar. W otwartej sesji SSH wykonaj następujące polecenie:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayUruchom przepływ pracy. W otwartej sesji SSH wykonaj następujące polecenie:
oozie job -config job.properties -runObserwuj stan przy użyciu konsoli sieci Web Oozie. W aplikacji Ambari wybierz pozycję Oozie, Szybkie linki, a następnie konsolę sieci Web Oozie. Na karcie Zadania przepływu pracy wybierz pozycję Wszystkie zadania.
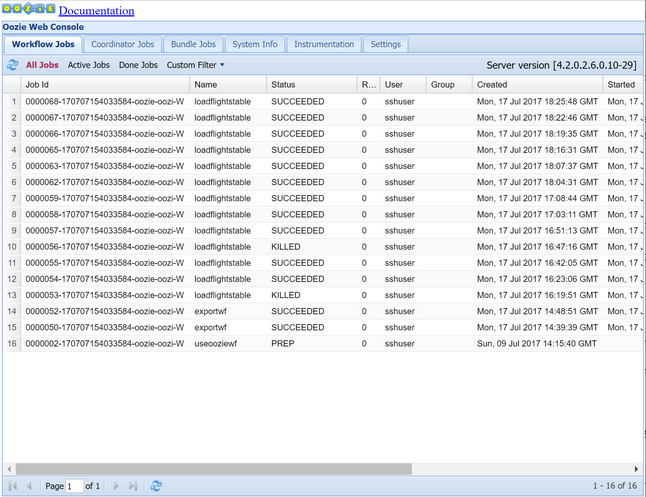
Gdy stan to POWODZENIE, wykonaj zapytanie względem tabeli usługi SQL Database, aby wyświetlić wstawione wiersze. W witrynie Azure Portal przejdź do okienka usługi SQL Database, wybierz pozycję Narzędzia i otwórz Edytor Power Query.
SELECT * FROM dailyflights
Teraz, gdy przepływ pracy jest uruchomiony dla pojedynczego dnia testu, możesz opakować ten przepływ pracy za pomocą koordynatora, który planuje przepływ pracy, aby był uruchamiany codziennie.
Uruchamianie przepływu pracy z koordynatorem
Aby zaplanować ten przepływ pracy tak, aby był uruchamiany codziennie (lub wszystkie dni w zakresie dat), możesz użyć koordynatora. Koordynator jest definiowany przez plik XML, na przykład coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Jak widać, większość koordynatora przekazuje tylko informacje o konfiguracji do wystąpienia przepływu pracy. Istnieje jednak kilka ważnych elementów, które należy wywołać.
Punkt 1:
startatrybuty iendnacoordinator-appsamym elemecie kontrolują interwał czasu, w którym działa koordynator.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Koordynator jest odpowiedzialny za planowanie akcji w zakresie
startdat iendzgodnie z interwałemfrequencyokreślonym przez atrybut . Każda zaplanowana akcja z kolei uruchamia przepływ pracy zgodnie z konfiguracją. W powyższej definicji koordynatora jest skonfigurowany do uruchamiania akcji od 1 stycznia 2017 r. do 5 stycznia 2017 r. Częstotliwość jest ustawiana na jeden dzień przez wyrażenie${coord:days(1)}częstotliwości języka Wyrażeń Oozie . Powoduje to zaplanowanie akcji koordynatora (a tym samym przepływu pracy) raz dziennie. W przypadku zakresów dat, które znajdują się w przeszłości, tak jak w tym przykładzie, akcja zostanie zaplanowana do uruchomienia bez opóźnień. Początek daty, od której zaplanowano uruchomienie akcji, jest nazywany godziną nominalną. Na przykład w celu przetworzenia danych z 1 stycznia 2017 r. koordynator zaplanuje akcję z nominalnym czasem 2017-01-01T00:00:00 GMT.Punkt 2: W zakresie dat przepływu pracy element określa,
datasetgdzie szukać w systemie plików HDFS dla danych dla określonego zakresu dat, i konfiguruje sposób, w jaki Oozie określa, czy dane są jeszcze dostępne do przetworzenia.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Ścieżka do danych w systemie plików HDFS jest tworzona dynamicznie zgodnie z wyrażeniem podanym w elemecie
uri-template. W tym koordynatorze częstotliwość jednego dnia jest również używana z zestawem danych. Podczas gdy daty rozpoczęcia i zakończenia kontrolki elementu koordynatora, gdy akcje są zaplanowane (i definiują ich nominalne czasy), kontrolkainitial-instanceifrequencyw zestawie danych kontroluje obliczenie daty używanej podczas konstruowaniauri-templateelementu . W takim przypadku ustaw początkowe wystąpienie na dzień przed rozpoczęciem koordynatora, aby upewnić się, że pobiera dane z pierwszego dnia (1 stycznia 2017 r.). Obliczanie daty zestawu danych przechodzi do przodu z wartościinitial-instance(12/31/2016) postępu w przyrostach częstotliwości zestawu danych (jeden dzień), dopóki nie znajdzie najnowszej daty, która nie przejdzie nominalnego czasu ustawionego przez koordynatora (2017-01-01T00:00:00 GMT dla pierwszej akcji).done-flagPusty element wskazuje, że gdy Oozie sprawdza obecność danych wejściowych w wyznaczonym czasie, Oozie określa dane, czy są dostępne przez obecność katalogu lub pliku. W takim przypadku jest to obecność pliku CSV. Jeśli plik CSV jest obecny, Oozie zakłada, że dane są gotowe i uruchamia wystąpienie przepływu pracy w celu przetworzenia pliku. Jeśli nie ma pliku CSV, firma Oozie zakłada, że dane nie są jeszcze gotowe i uruchomienie przepływu pracy przechodzi w stan oczekiwania.Punkt 3. Element
data-inokreśla określony znacznik czasu, który ma być używany jako nominalny czas podczas zastępowania wartości wuri-templateskojarzonym zestawie danych.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>W takim przypadku ustaw wystąpienie na wyrażenie
${coord:current(0)}, które przekłada się na użycie nominalnego czasu akcji zgodnie z harmonogramem koordynatora. Innymi słowy, gdy koordynator planuje uruchomienie akcji z nominalnym czasem 01.01.01.2017, wówczas 01.01.01.2017 jest używany do zastąpienia zmiennych YEAR (2017) i MONTH (01) w szablonie identyfikatora URI. Po obliczeniu szablonu identyfikatora URI dla tego wystąpienia usługa Oozie sprawdza, czy oczekiwany katalog lub plik jest dostępny i odpowiednio planuje następny przebieg przepływu pracy.
Trzy poprzednie punkty łączą się w celu uzyskania sytuacji, w której koordynator planuje przetwarzanie danych źródłowych w sposób codzienny.
Punkt 1: Koordynator rozpoczyna się od nominalnej daty 2017-01-01.
Punkt 2. Oozie szuka danych dostępnych w programie
sourceDataFolder/2017-01-FlightData.csv.Punkt 3. Gdy Oozie wykryje ten plik, planuje wystąpienie przepływu pracy, które będzie przetwarzać dane z 1 stycznia 2017 r. Oozie kontynuuje przetwarzanie dla 2017-01-02. Ta ocena jest powtarzana do 2017-01-05.
Podobnie jak w przypadku przepływów pracy, konfiguracja koordynatora jest definiowana w job.properties pliku, który ma nadzbiór ustawień używanych przez przepływ pracy.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Jedyne nowe właściwości wprowadzone w tym job.properties pliku to:
| Właściwości | Źródło wartości |
|---|---|
| oozie.coord.application.path | Wskazuje lokalizację coordinator.xml pliku zawierającego koordynatora Oozie do uruchomienia. |
| hiveDailyTableNamePrefix | Prefiks używany podczas dynamicznego tworzenia nazwy tabeli przejściowej. |
| hiveDataFolderPrefix | Prefiks ścieżki, w której będą przechowywane wszystkie tabele przejściowe. |
Wdrażanie i uruchamianie koordynatora Oozie
Aby uruchomić potok z koordynatorem, postępuj podobnie jak w przypadku przepływu pracy, z wyjątkiem pracy z folderu o jeden poziom powyżej folderu zawierającego przepływ pracy. Ta konwencja folderów oddziela koordynatorów od przepływów pracy na dysku, dzięki czemu można skojarzyć jednego koordynatora z różnymi podrzędnymi przepływami pracy.
Użyj usługi SCP z komputera lokalnego, aby skopiować pliki koordynatora do lokalnego magazynu węzła głównego klastra.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~Połączenie SSH z węzłem głównym.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSkopiuj pliki koordynatora do systemu plików HDFS.
hdfs dfs -put ./* /oozie/Uruchom koordynatora.
oozie job -config job.properties -runSprawdź stan przy użyciu konsoli sieci Web Oozie, tym razem wybierając kartę Zadania koordynatora, a następnie pozycję Wszystkie zadania.
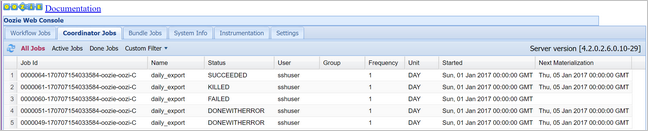
Wybierz wystąpienie koordynatora, aby wyświetlić listę zaplanowanych akcji. W takim przypadku powinny zostać wyświetlone cztery akcje z nominalnymi czasami w zakresie od 1 stycznia 2017 r. do 4 stycznia 2017 r.
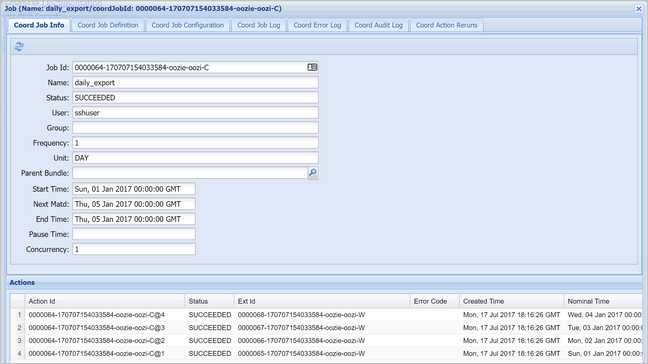
Każda akcja na tej liście odpowiada wystąpieniu przepływu pracy, które przetwarza dane o wartości jednego dnia, gdzie początek tego dnia jest wskazywany przez nominalny czas.