Monitorowanie wydajności klastra w usłudze Azure HDInsight
Monitorowanie kondycji i wydajności klastra usługi HDInsight jest niezbędne do utrzymania optymalnej wydajności i wykorzystania zasobów. Monitorowanie może również pomóc w wykrywaniu błędów konfiguracji klastra i rozwiązywaniu problemów z kodem użytkownika.
W poniższych sekcjach opisano sposób monitorowania i optymalizowania obciążenia klastrów, kolejek usługi Apache Hadoop YARN oraz wykrywania problemów z ograniczaniem przepustowości magazynu.
Monitorowanie obciążenia klastra
Klastry Hadoop mogą zapewnić najbardziej optymalną wydajność, gdy obciążenie klastra jest równomiernie rozłożone we wszystkich węzłach. Dzięki temu zadania przetwarzania mogą być uruchamiane bez ograniczenia pamięci RAM, procesora CPU lub zasobów dysku w poszczególnych węzłach.
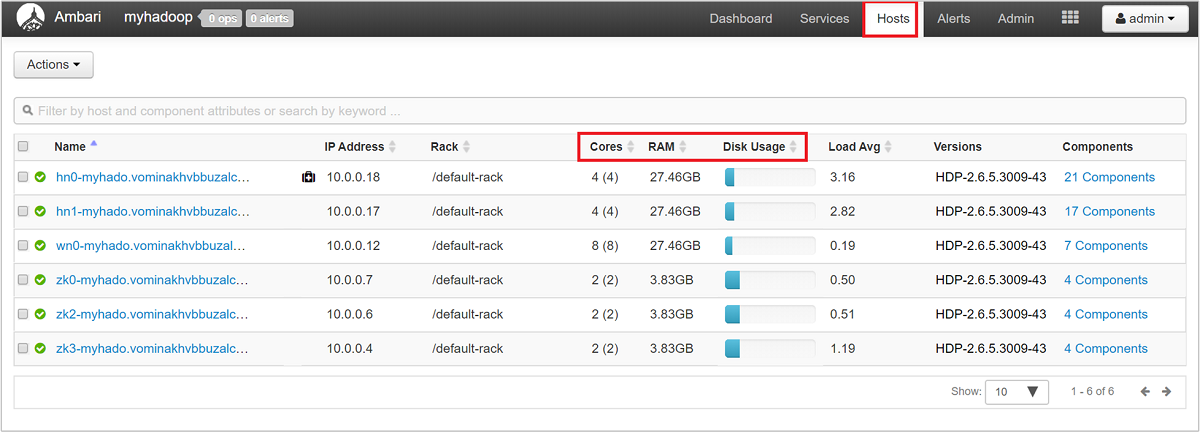
Aby uzyskać ogólne spojrzenie na węzły klastra i ich ładowanie, zaloguj się do internetowego interfejsu użytkownika systemu Ambari, a następnie wybierz kartę Hosty. Hosty są wyświetlane według ich w pełni kwalifikowanych nazw domen. Stan działania każdego hosta jest wyświetlany przez kolorowy wskaźnik kondycji:
| Color | opis |
|---|---|
| Czerwony | Co najmniej jeden składnik główny na hoście nie działa. Zatrzymaj wskaźnik myszy, aby wyświetlić etykietkę narzędzia zawierającą listę składników, których dotyczy problem. |
| Orange | Co najmniej jeden składnik pomocniczy na hoście nie działa. Zatrzymaj wskaźnik myszy, aby wyświetlić etykietkę narzędzia zawierającą listę składników, których dotyczy problem. |
| Yellow | Serwer Ambari nie otrzymał pulsu od hosta przez ponad 3 minuty. |
| Green (Zielony) | Normalny stan działania. |
Zobaczysz również kolumny przedstawiające liczbę rdzeni i ilość pamięci RAM dla każdego hosta oraz średnie użycie dysku i obciążenie.
Wybierz dowolną z nazw hostów, aby uzyskać szczegółowy przegląd składników uruchomionych na tym hoście i ich metrykach. Metryki są wyświetlane jako wybrana oś czasu użycia procesora CPU, obciążenia, użycia dysku, użycia pamięci, użycia sieci i liczby procesów.
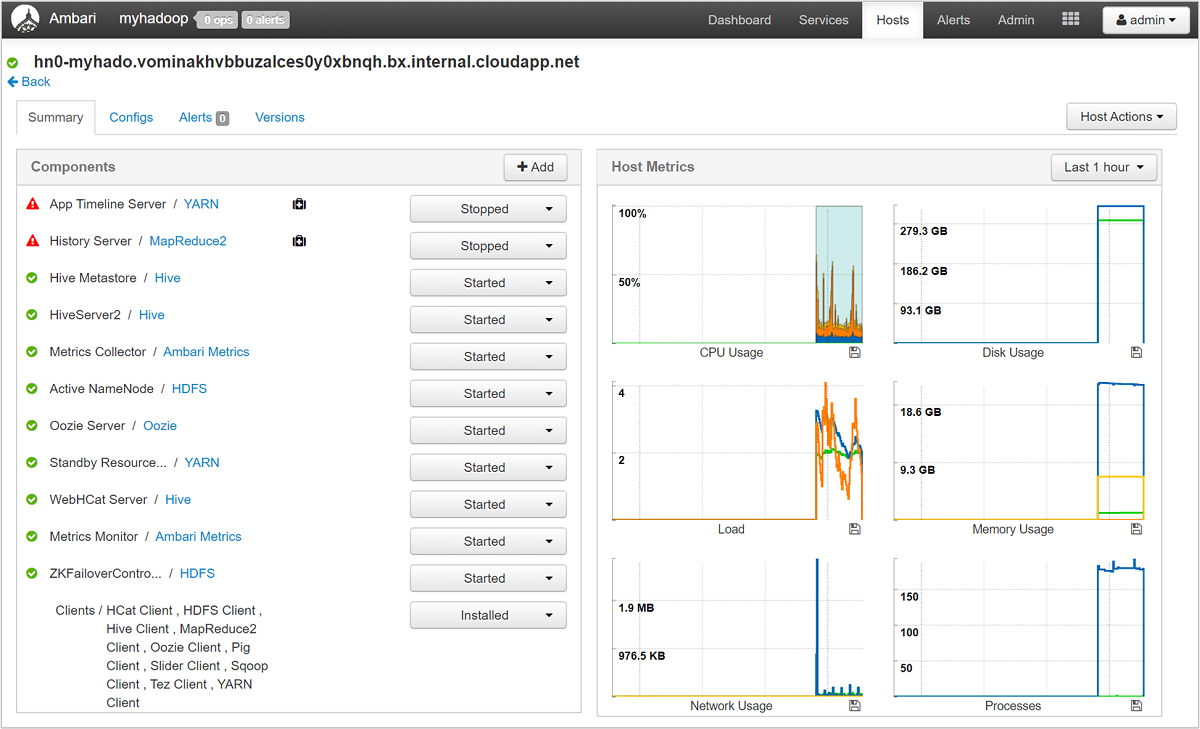
Aby uzyskać szczegółowe informacje na temat ustawiania alertów i wyświetlania metryk, zobacz Manage HDInsight clusters by using the Apache Ambari Web UI (Zarządzanie klastrami usługi HDInsight przy użyciu internetowego interfejsu użytkownika platformy Apache Ambari).
Konfiguracja kolejki usługi YARN
Usługa Hadoop ma różne usługi działające na swojej platformie rozproszonej. Usługa YARN (Jeszcze inny negocjator zasobów) koordynuje te usługi i przydziela zasoby klastra w celu zapewnienia równomiernego rozłożenia obciążenia w klastrze.
Usługa YARN dzieli dwie obowiązki usługi JobTracker, zarządzanie zasobami i planowanie/monitorowanie zadań, na dwa demony: globalnego menedżera zasobów i aplikację ApplicationMaster (AM).
Usługa Resource Manager to czysty harmonogram i wyłącznie arbitruje dostępne zasoby między wszystkimi konkurencyjnymi aplikacjami. Usługa Resource Manager zapewnia, że wszystkie zasoby są zawsze używane, optymalizując pod kątem różnych stałych, takich jak umowy SLA, gwarancje wydajności itd. Usługa ApplicationMaster negocjuje zasoby z usługi Resource Manager i współpracuje z menedżerami węzłów w celu wykonywania i monitorowania kontenerów oraz ich zużycia zasobów.
Gdy wiele dzierżaw współużytkuje duży klaster, istnieje konkurencja dla zasobów klastra. CapacityScheduler to podłączony harmonogram, który pomaga w udostępnianiu zasobów przez kolejkowanie żądań. Usługa CapacityScheduler obsługuje również kolejki hierarchiczne, aby upewnić się, że zasoby są współdzielone między kolejkami organizacji, zanim kolejki innych aplikacji będą mogły korzystać z bezpłatnych zasobów.
Usługa YARN umożliwia przydzielanie zasobów do tych kolejek i pokazuje, czy wszystkie dostępne zasoby są przypisane. Aby wyświetlić informacje o kolejkach, zaloguj się do internetowego interfejsu użytkownika systemu Ambari, a następnie wybierz pozycję Menedżer kolejek usługi YARN z górnego menu.
Na stronie Menedżera kolejek usługi YARN jest wyświetlana lista kolejek po lewej stronie wraz z procentem pojemności przypisanej do każdej z nich.
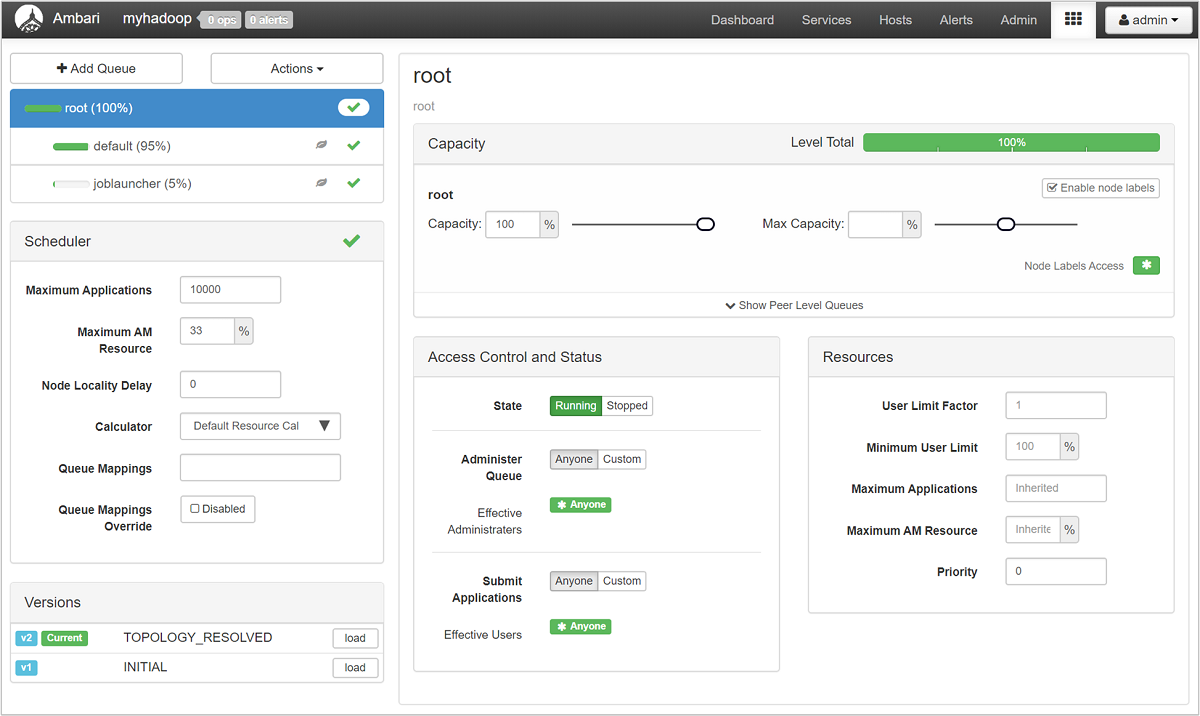
Aby uzyskać bardziej szczegółowe informacje na temat kolejek, na pulpicie nawigacyjnym systemu Ambari wybierz usługę YARN z listy po lewej stronie. Następnie w menu rozwijanym Szybkie linki wybierz pozycję Interfejs użytkownika usługi Resource Manager poniżej aktywnego węzła.
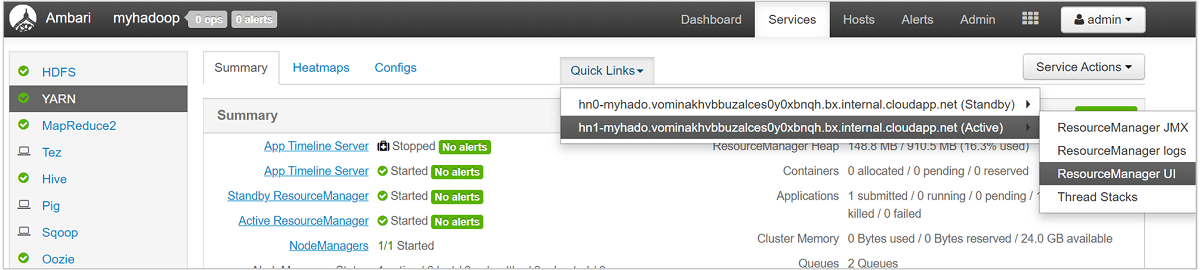
W interfejsie użytkownika usługi Resource Manager wybierz pozycję Harmonogram z menu po lewej stronie. Zostanie wyświetlona lista kolejek poniżej kolejek aplikacji. W tym miejscu można zobaczyć pojemność używaną dla każdej kolejki, jak dobrze zadania są rozdzielane między nimi i czy jakiekolwiek zadania są ograniczone do zasobów.
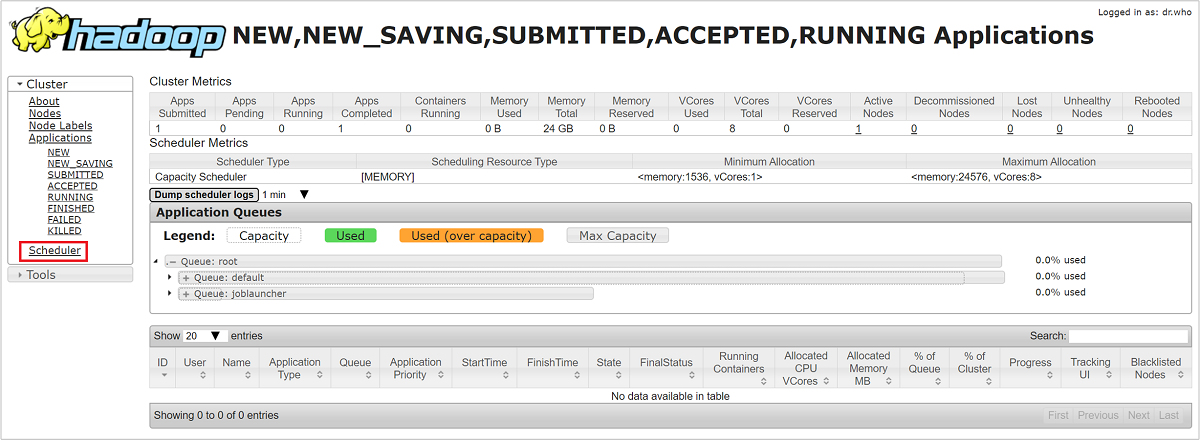
Ograniczanie przepustowości magazynu
Wąskie gardło wydajności klastra może wystąpić na poziomie magazynu. Ten typ wąskiego gardła jest najczęściej spowodowany blokowaniem operacji wejścia/wyjścia (we/wy), które występują, gdy uruchomione zadania wysyłają więcej operacji we/wy niż usługa magazynu może obsłużyć. To blokowanie powoduje utworzenie kolejki żądań we/wy oczekujących na przetworzenie do momentu przetworzenia bieżących operacji we/wy. Bloki są spowodowane ograniczaniem przepustowości magazynu, który nie jest limitem fizycznym, ale raczej limitem nałożonym przez usługę magazynu przez umowę dotyczącą poziomu usług (SLA). Ten limit gwarantuje, że żaden pojedynczy klient lub dzierżawa nie może monopolizować usługi. Umowa SLA ogranicza liczbę operacji we/wy na sekundę (IOPS) dla usługi Azure Storage — aby uzyskać szczegółowe informacje, zobacz Cele skalowalności i wydajności dla kont magazynu w warstwie Standardowa.
Jeśli używasz usługi Azure Storage, aby uzyskać informacje na temat monitorowania problemów związanych z magazynem, w tym ograniczania przepustowości, zobacz Monitorowanie, diagnozowanie i rozwiązywanie problemów z usługą Microsoft Azure Storage.
Jeśli magazynem zapasowym klastra jest usługa Azure Data Lake Storage (ADLS), ograniczanie przepustowości jest najprawdopodobniej spowodowane limitami przepustowości. Ograniczanie przepustowości w tym przypadku można zidentyfikować, obserwując błędy ograniczania przepustowości w dziennikach zadań. W przypadku usługi ADLS zobacz sekcję ograniczania przepustowości dla odpowiedniej usługi w następujących artykułach:
- Wskazówki dotyczące dostrajania wydajności oprogramowania Apache Hive w usługach HDInsight i Azure Data Lake Storage
- Wskazówki dotyczące dostrajania wydajności w usłudze MapReduce w usługach HDInsight i Azure Data Lake Storage
Rozwiązywanie problemów z powolnym działaniem węzłów
W niektórych przypadkach może wystąpić spowolnienie z powodu małej ilości miejsca na dysku w klastrze. Zbadaj problem, wykonując następujące kroki:
Użyj polecenia SSH, aby nawiązać połączenie z każdym z węzłów.
Sprawdź użycie dysku, uruchamiając jedno z następujących poleceń:
df -h du -h --max-depth=1 / | sort -hPrzejrzyj dane wyjściowe i sprawdź obecność wszelkich dużych plików w
mntfolderze lub innych folderach.usercacheZazwyczaj foldery , iappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) zawierają duże pliki.Jeśli istnieją duże pliki, bieżące zadanie powoduje wzrost pliku lub poprzednie zadanie, które zakończyło się niepowodzeniem, mogło przyczynić się do tego problemu. Aby sprawdzić, czy to zachowanie jest spowodowane przez bieżące zadanie, uruchom następujące polecenie:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Jeśli to polecenie wskazuje określone zadanie, możesz przerwać zadanie przy użyciu polecenia podobnego do następującego:
yarn application -kill -applicationId <application_id>Zastąp
application_idelement identyfikatorem aplikacji. Jeśli nie określono konkretnych zadań, przejdź do następnego kroku.Po zakończeniu powyższego polecenia lub w przypadku braku określonych zadań usuń duże pliki zidentyfikowane, uruchamiając polecenie podobne do następującego:
rm -rf filecache usercache
Aby uzyskać więcej informacji na temat problemów z miejscem na dysku, zobacz Brak miejsca na dysku.
Uwaga
Jeśli masz duże pliki, które chcesz zachować, ale przyczyniają się do problemu z małą ilością miejsca na dysku, musisz skalować klaster usługi HDInsight w górę i ponownie uruchomić usługi. Po wykonaniu tej procedury i zaczekaniu kilku minut zauważysz, że magazyn zostanie zwolniony, a zwykle przywrócona wydajność węzła.
Następne kroki
Aby uzyskać więcej informacji na temat rozwiązywania problemów i monitorowania klastrów, odwiedź następujące linki: